大模型微调终极指南:SFT会遗忘,RFT会记住,不看后悔系列
本文研究发现,大模型持续训练中存在灾难性遗忘问题:监督微调(SFT)会系统性损害旧任务表现和通用能力,而基于奖励的微调(RFT)则几乎无遗忘且能增强通用性。实验表明,RFT通过"隐式正则化"机制自动调节梯度更新方向,本能避开破坏旧知识的更新。作者还提出RIF-RFT方法过滤无效样本提升效率。研究表明,在持续学习场景下,RFT比SFT更具优势,未来可结合两者特点:SFT注入新知识
本文揭示大模型持续训练中的灾难性遗忘问题,对比实验证明SFT会系统性遗忘旧任务并损害通用能力,而RFT几乎无遗忘且能增强通用能力。RFT的抗遗忘源于其"隐式正则化"机制——奖励方差自动调节梯度更新方向,使模型本能避开破坏旧知识的更新。作者还提出RIF-RFT方法过滤无效样本提高效率。研究表明,在持续训练场景下,RFT比SFT更合理,未来可结合两者优势:SFT注入知识,RFT守住能力。
如果你做过大模型微调,大概率遇到过一个诡异现象:
模型学会了新任务,但老能力却悄悄消失了。
比如:
- 医疗 VQA 训完,数学推理掉分
- 多模态任务越训,通用能力越弱
- 看起来指标都在涨,但一上通用 benchmark 全线崩盘
我们通常把锅甩给三样东西:
- ❌ 数据不够
- ❌ replay 没做好
- ❌ 正则化不够强
而近期减轻MLLM灾难性遗忘的努力主要集中在参数高效学习和动态数据选择上。如任务特定的LoRA扩展,多模态路由机制选择性激活专业参数,基于梯度表示动态选择高影响样本并剪枝冗余数据等。
但这篇论文给了一个更扎心的结论:
你不是“没防遗忘”,而是一开始就选错了训练范式。

论文链接:https://arxiv.org/pdf/2507.05386
结论只有一句:
在持续后训练(Continual Post-Training)场景下,
SFT 天生会遗忘,RFT 天生会记住。
而且不是靠 replay、不是靠参数冻结,
是“天生机制层面”就不一样。
作者做了一件非常“朴素但致命”的事:
把 SFT 和 RFT,放到完全公平的持续学习场景里,正面对打。
实验设置一句话版:
- 基座模型:Qwen2.5-VL-7B-Instruct
- 连续学习 7 个多模态任务
- 不使用 replay、不扩模型、不加复杂 CL trick
- 对比:
- 传统 SFT
- 多种 RFT(GRPO / ReMax / RLOO)
然后看两件事:
- 旧任务会不会忘?
- 通用能力会不会塌?
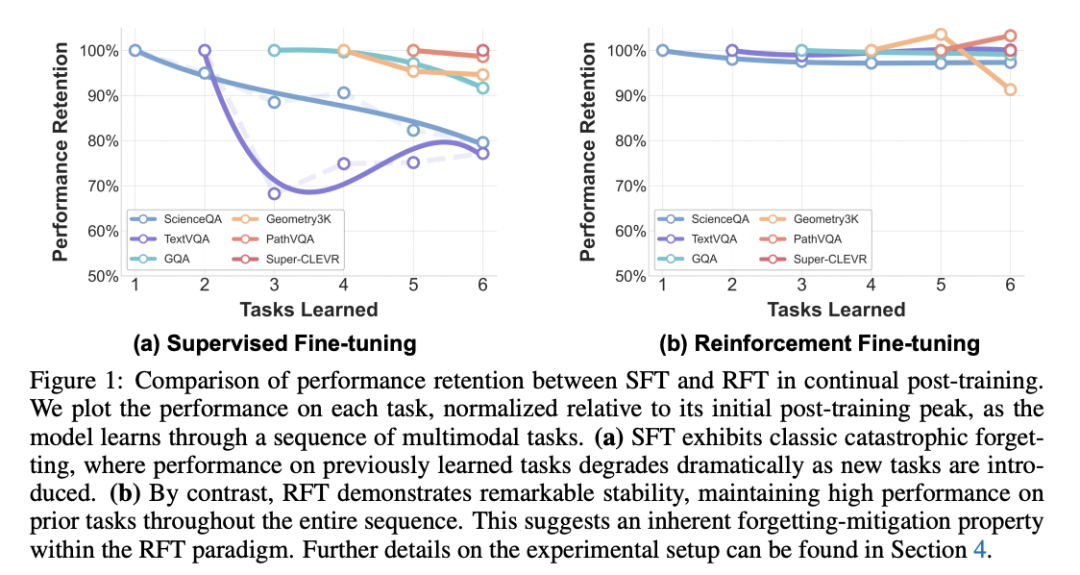
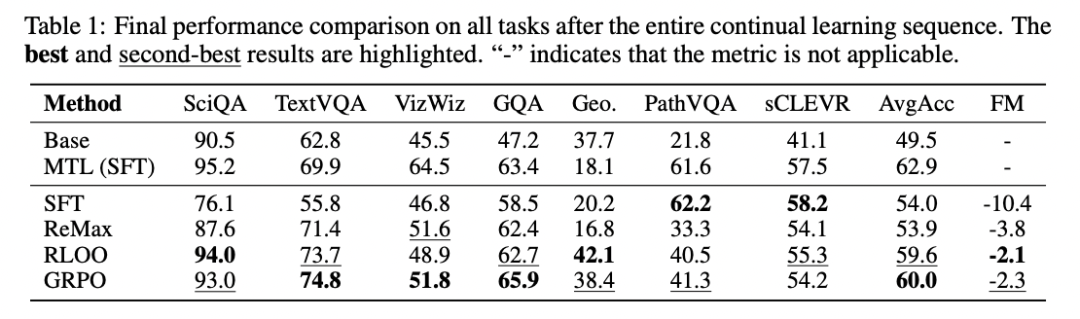
👉 结果一:SFT 的“灾难性遗忘”是系统性的
先看最直观的结果。
📉 SFT:越学越忘
- ScienceQA:95% → 76%
- Forgetting Measure:-10.4%
- AvgAcc 明显低于多任务上限
注意一个细节:
即使你把所有任务一起训(Multi-task SFT),
通用能力依然在掉。
也就是说:
- ❌ 不是“顺序问题”
- ❌ 不是“数据分布问题”
- 👉 是 SFT 本身的问题
👉 结果二:RFT 几乎“不会忘”
换成 RFT,画风突变:
📈 RFT:旧能力稳如老狗
- Forgetting Measure:≈ -2%
- 老任务性能几乎保持峰值
- 最终效果 ≈ 多任务训练上限
更离谱的是:
完全没用 replay,效果却接近 Offline Multi-task Training
这在 Continual Learning 里,几乎是“犯规级别”的表现。
👉 更狠的一刀:SFT 会“毁掉”通用能力
如果你觉得“任务不忘就够了”,那还有更恐怖的。
作者额外测了:
- MMMU
- MMLU-Pro
- POPE(幻觉)
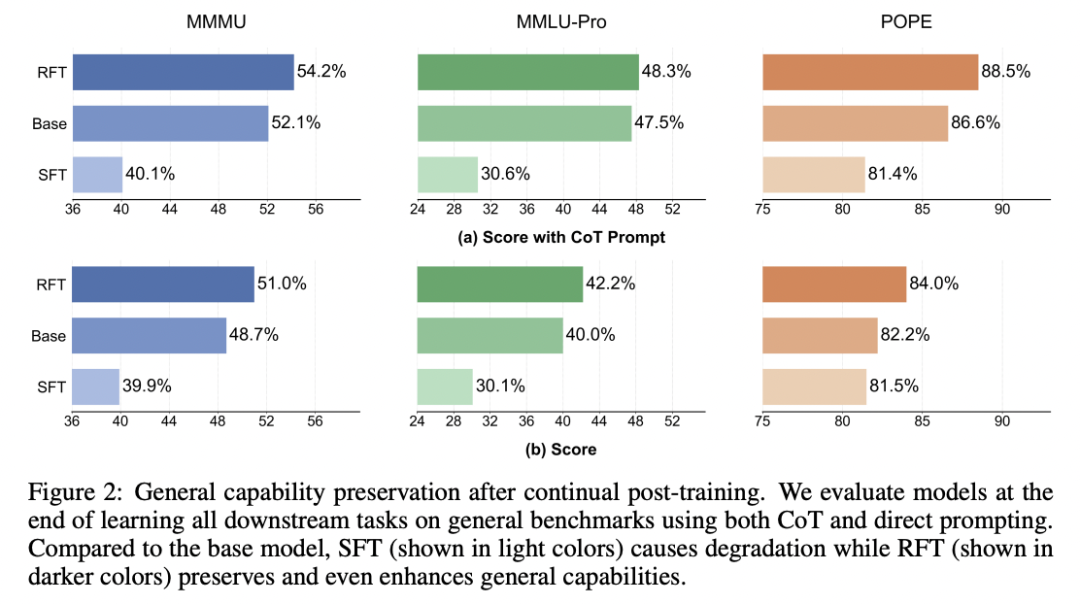
结果直接封神:
| 方法 | 通用能力变化 |
|---|---|
| SFT | -12% ~ -17% |
| 多任务 SFT | 依然下降 |
| RFT(GRPO) | +2% ~ +3% |
一句话总结:
SFT 在“持续微调”中,会系统性腐蚀 base model。
RFT 反而在“越训越通用”。
👉 关键问题:为什么 RFT 天生不容易忘?
这才是论文最有价值的部分。
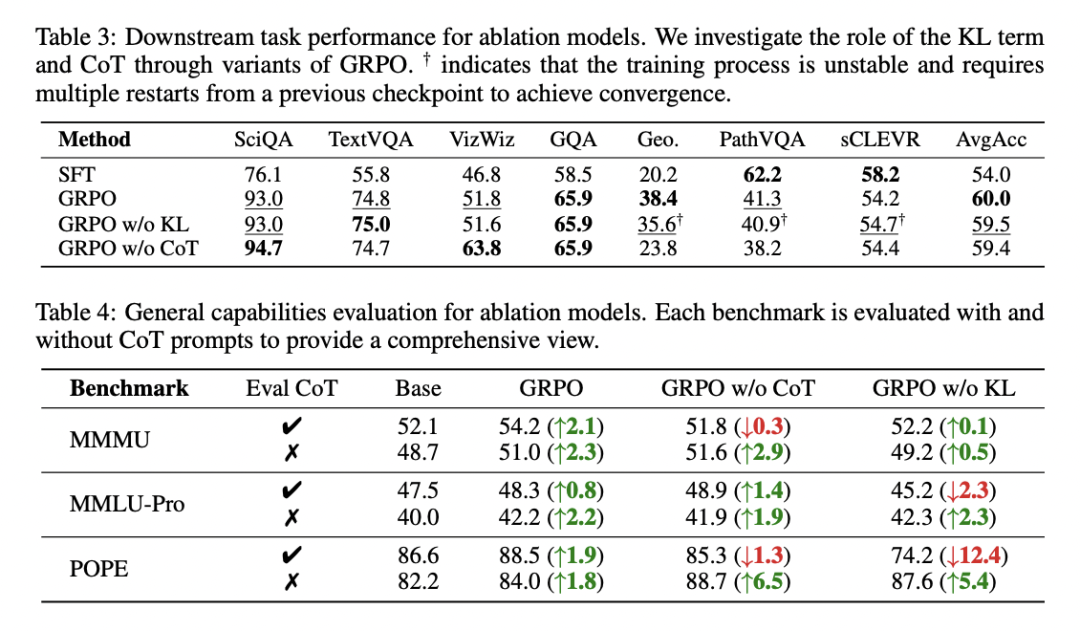
❌ 先排除两个“常见误解”
误解 1:是 KL 正则在保护?
👉 不是
- 去掉 KL,RFT 依然不怎么忘
- KL 更多是稳定训练,不是防遗忘核心
误解 2:是 CoT 让表示更稳?
👉 也不是
- 不用 CoT,RFT 依然抗遗忘
- CoT 是 performance booster,不是根因
👉 真正的原因:RFT 有“隐式正则化”
论文给了一个非常漂亮的解释:
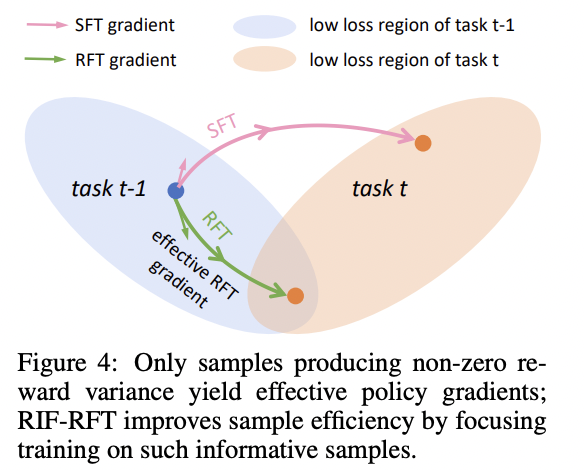
🔑 核心机制:奖励方差调制梯度
在 SFT 中:
- 每个样本 → 同等强度梯度
- 不管它是否会破坏旧知识
在 RFT 中:
- 梯度 ≈ reward variance × log-prob gradient
- 奖励不稳定 → 更新自动变小
- 模型不确定的地方 → 不乱改参数
换句话说:
RFT 会“本能地”避开那些容易破坏旧知识的更新方向。
这相当于一种:
- 数据自适应
- 无需显式约束
- 天然保护旧能力的正则化
👉 一个极妙的类比(工程直觉版)
你可以这样理解:
-
SFT:
老板说一句“照着答案背”,
不管你懂不懂,强行覆盖记忆。 -
RFT:
老板只给你一个“结果反馈”,
你只在“有把握的地方”慢慢调整。
所以:
- SFT:学得快,但记不住
- RFT:学得慢,但越学越稳
👉 作者还顺手送了一个工程技巧(RIF-RFT)
作者还发现一个现实问题:
很多样本,模型根本学不了,却在浪费 RFT 的算力。
于是提出了一个简单但实用的方法:
🧹 Rollout-based Instance Filtering(RIF-RFT)
做法一句话:
- 先 rollout 几次
- 完全拿不到 reward 的样本,直接扔掉

结果:
- 数据量 ↓ 40%~60%
- 抗遗忘能力几乎不变
- 稳定性反而更好
非常适合工业级 RFT pipeline。
👉 这篇论文对我们意味着什么?
我给你 3 条真正能落地的结论:
1️⃣ Continual Training 场景,SFT ≈ 结构性缺陷
不是“技巧不够”,是 范式选错。
2️⃣ 想要模型“长期进化”,RFT 是更合理的默认选项
尤其适合:
- 多任务持续迭代
- 产品长期在线更新
- 不允许 base 能力退化的场景
3️⃣ 未来不是“SFT vs RFT”,而是:
SFT 负责注入知识,
RFT 负责守住能力。
👉 最后一句话
灾难性遗忘不是大模型的宿命,
而是我们长期误用 SFT 的代价。
如果你在做持续训练、Agent、长生命周期模型,
这篇论文,值得你反复读三遍。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献787条内容
已为社区贡献787条内容

所有评论(0)