小白也能学会的RAG:企业智能问答系统构建指南(18篇系列,建议收藏)
本文系统介绍了企业知识库智能问答系统的三种RAG(检索增强生成)实现方案。针对不同业务场景,提出模块化解决方案:简单RAG适用于小规模知识库快速验证;标准RAG采用向量+关键词混合检索提升召回稳定性;进阶RAG通过预处理和后处理优化信息相关性。文章从场景适配、实现方式、价值优势等维度详细解析各方案特点,旨在帮助企业根据知识库规模、查询复杂度等需求选择合适的RAG组合,构建高性能智能问答系统。三种方
本文介绍了企业知识库智能问答系统的三种RAG方案:简单RAG适用于小规模知识库或MVP阶段;标准RAG结合向量与关键词检索,提升召回稳定性;进阶RAG通过预处理和后处理优化信息相关性。文章采用模块化方式,按场景、实现方式和价值进行说明,旨在帮助开发者根据业务需求选择合适的RAG组合,构建高性能、高准确率的问答智能体。
背景
知识库建设后,企业智能问答应用效果却不理想的情况经常发生,导致很多企业在RAG选型决策时产生偏误。市场上出现了很多所谓“N 种 RAG”解决方案,本质是对同一条链路中不同模块(Query、Retriever、Ranker、Context、Generator、Verifier)的优化。本文用模块化方式整理:每个模块按【场景】、【实现方式】、【价值】说明,便于直接落到企业知识库与智能体工作流中。
目标
根据业务场景选择合适的 RAG 组合拳,提升可答率与引用一致性。问答智能体需要结合知识库能力+智能体RAG工程实现,在实际使用过程中,RAG工程(或上下文工程)不是全部由【知识库】实现,更多是依赖工程能力达成智能问答的目的。
【知识库】作为RAG工程的内容提供方,可以面向Context Relevance(上下文相关性)、Context Precision(上下文精确率)、Context Recall(上下文召回率)三大指标进行多种RAG方案的组合。
本文提出RAG的实现方案,期望根据这个方案,知识库产品可以提供智能体RAG工程构建的必要信息(原子能力),支持在开发平台中构建高性能、高准确率的问答智能体。
本系列内容分18篇完成,逐步展开对RAG方案的深入探索,有志之士可以收藏跟踪。因为工作较忙,更新速度会比较慢。
方案1:简单RAG(Simple RAG)
💡热度:⭐⭐⭐⭐⭐
场景&价值
【场景】
- 知识库规模较小或处于 MVP 阶段,需要快速跑通“有引用的问答”。
- FAQ、制度、产品手册、售前资料等“答案在文档里且相对直接”的问题。
【价值】
- 最快形成闭环,后续所有高级方案都可视为在其上叠加。
- 便于建立“评测集 + 日志审计 + 反馈闭环”的工程基础。
实现方式
【知识库】
- 提供切片,chunk 元信息,来源文档、章节标题路径、有效性。
- 常见参数:TopK=3~8;上下文长度受模型窗口限制。
【智能体工程】
- 实现智能体构建,选择向量检索。
- 输出要求:答案后附引用(chunk 引用/链接)。
优点
简单有效,能够提升 LLM 的生成效果,输出结果耗时短。
缺点
存在检索到很多与 query 无关的片段,增加噪声输入,与 query 关联的信息比较稀疏,需要 LLM 本身去提炼或挖掘利用。仅考虑一个外部知识源,是一次性解决方案,上下文只检索一次,没有对检索到的上下文质量进行推理或验证。
流程
Query → 向量检索 TopK → 拼接上下文 → LLM 生成。
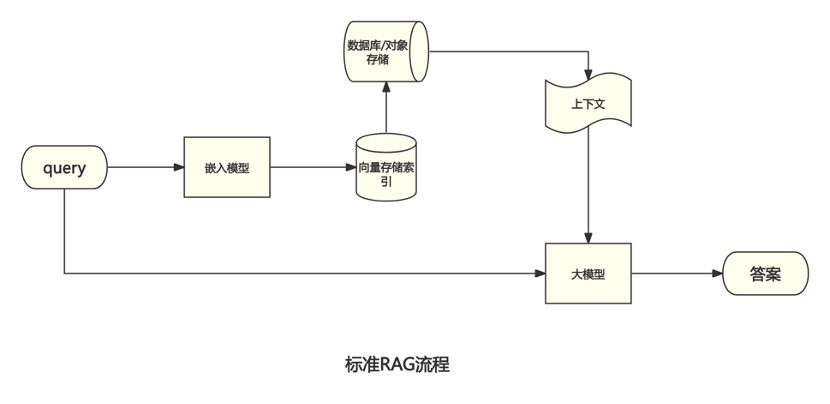
方案2:标准RAG-向量+关键词混合RAG策略
(Dense / Sparse / Hybrid Retrieval)
💡热度:⭐⭐⭐⭐⭐
场景&价值
【场景】
- 既有自然语言问题,也有大量编号/术语/字段名(如“TR-1024”“SLA”“工单号”)。
- 理解提问者意思,并在海量不规则的文档中找到意思相近的片段,不要求强制匹配。
【价值】
- 召回更稳、更抗“同义表达”和“关键词缺失”。
- 对企业知识库(编号/制度/表格字段)几乎是默认选项。
实现方式
【知识库】
- Dense:向量召回;
- Sparse:BM25/倒排;
- Hybrid:两路召回后融合(常用 RRF),或拼接候选再 rerank。
- 先召回更大候选集(如 BM25 Top50 + 向量 Top50),再进入重排。
【智能体工程】
- 智能体构建时选择混合检索。
- 输出要求:答案后附引用(chunk 引用/链接)
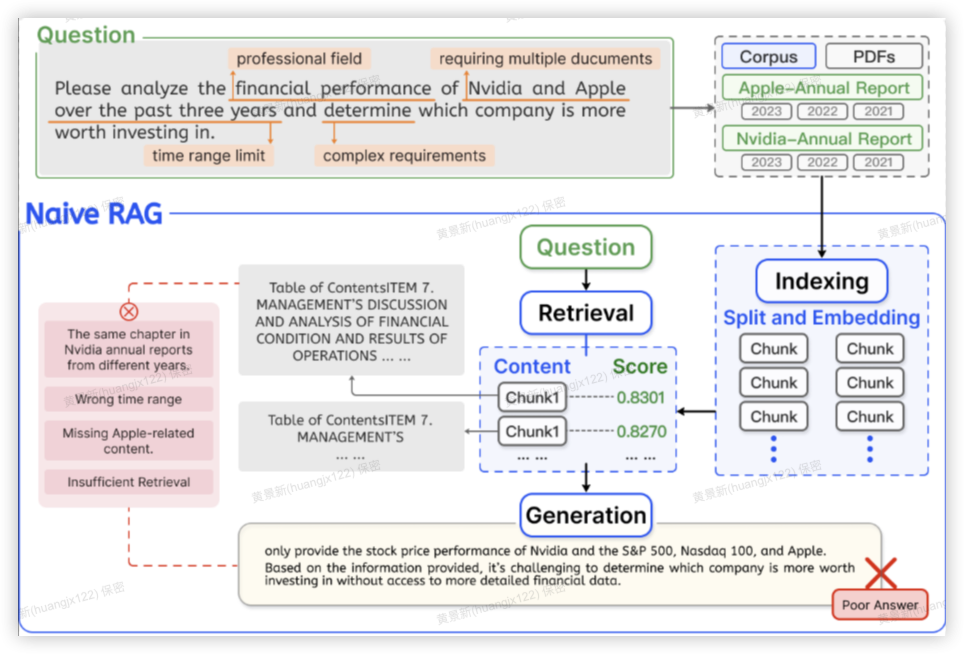
方案3:进阶RAG
💡热度:⭐⭐⭐⭐⭐
场景&价值
【场景】
- 用户问题比较随意,不能通过直接匹配知识库内容进行回答。
- 对召回的内容的相关性要求高于完整性。
【价值】
- 召回更多的内容,扩展提问者思路。
实现方式
【知识库】
- Dense:向量召回;
- Sparse:BM25/倒排;
- Hybrid:两路召回后融合(常用 RRF),或拼接候选再 rerank。
- 先召回更大候选集(如 BM25 Top50 + 向量 Top50),再进入重排。
【智能体工程】
- 实现智能体构建。
- 输出要求:答案后附引用(chunk 引用/链接)。
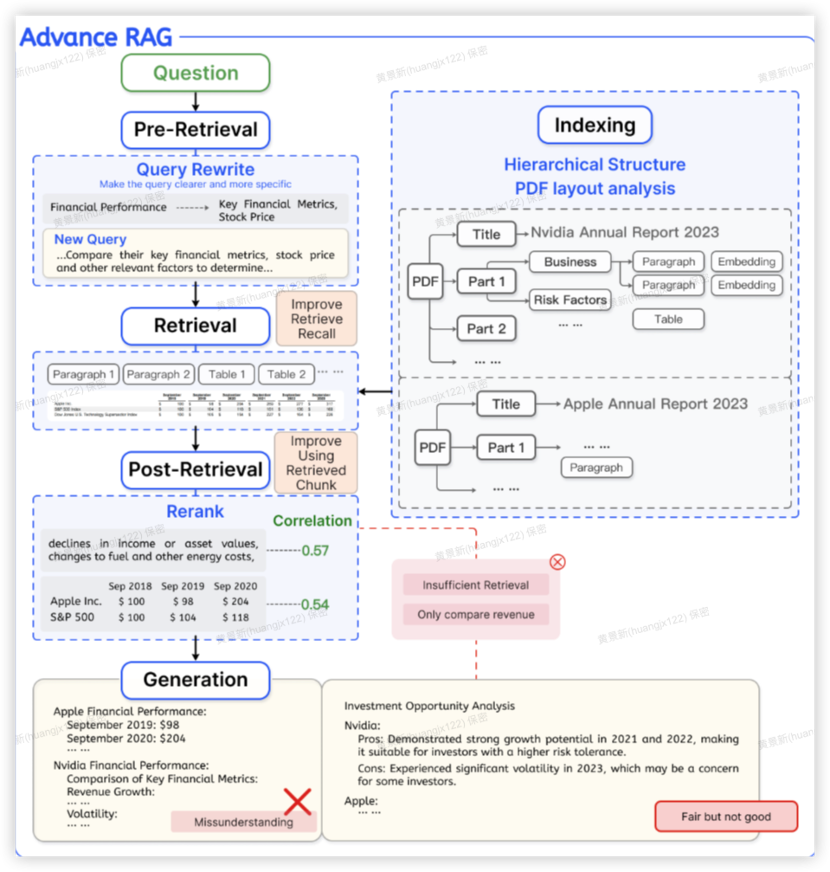
创新点
在检索前后增加预处理(如查询重写)和后处理(如结果重排),提升信息相关性。
优点
减少噪声干扰,优化生成质量。
缺点
流程复杂度增加,实时性受限。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献742条内容
已为社区贡献742条内容

所有评论(0)