多智能体大模型实战打造技术雷达与研发深度助手
本文提出一种多智能体协同的技术溯源与盲点发现系统,采用Master-Worker架构和Steerable ToDo机制解决传统研发工具在长时程规划、人机交互和技术盲点识别方面的不足。系统整合学术、代码和专利分析智能体,通过知识缺口反思算子主动发现企业技术盲点,并引入TRIZ理论生成专利规避方案。实验表明,该系统可缩短技术溯源耗时50%以上,提升任务成功率30%,为企业提供战略洞察和工程创新支持。
本文提出基于多智能体的技术溯源与盲点发现系统,采用Master-Worker架构和Steerable ToDo机制实现长时程规划。系统整合学术、代码和专利分析智能体,通过知识缺口反思算子主动发现企业技术盲点,提升研发效率50%以上,提供战略洞察和工程创新方案,助力企业技术竞争。
(多智能体协同技术溯源与盲点发现系统:基于可调控待办事项与知识缺口反思的深度研发助手)
标题 (Title)
多智能体协同的技术溯源与盲点发现系统:基于Steerable ToDo与知识缺口反思的深度研发辅助平台
问题陈述 (Problem Statement)
2.1 研发情报的复杂性与挑战
在现代企业研发(R&D)环境中,技术情报的获取已从单纯的“信息匮乏”转变为严峻的“信息过载”与“认知对齐”挑战。研发人员面临着海量的非结构化数据,包括每天涌现的学术论文 (arXiv)、开源代码 (GitHub)、复杂的专利法律文本以及职场动态 (LinkedIn)。传统的文献调研方法和现有的检索增强生成 (RAG) 系统在应对深层研发任务时存在显著缺陷:
长时程规划的迷失 (Long-Horizon Planning Failure):复杂的技术溯源任务(如“从零构建固态电池电解质配方”)通常涉及数十甚至上百个推理步骤。现有的单体 Agent 或简单的 Chain-of-Thought (CoT) 方法容易在长路径中累积误差,导致“迷航”,无法维持全局目标的一致性 (P228 )(P232 )。
黑盒不可控 (Lack of Steerability):目前的自主 Agent 多为“发射后不管”的黑盒系统。当 Agent 在调研中途出现理解偏差(例如过分关注理论而忽略工程实现)时,人类专家无法实时干预或纠正,只能等待任务失败后重新开始。这种缺乏“人机回环 (Human-in-the-loop)”交互的设计严重降低了研发效率 (P17 )(P234 )。
无法识别“未知的未知” (Blind Spot Discovery):现有的 RAG 系统擅长回答“已知问题”,即基于用户明确的查询进行检索。然而,企业战略中最关键的往往是竞争对手已布局但本司尚未察觉的“技术空白区 (White Space)” (P260 )(P267 )。现有工具缺乏将外部技术趋势与企业内部资产进行语义差分分析的能力,导致关键机遇或侵权风险被遗漏。
2.2 现有方法的局限性对比
| 维度 | 传统搜索引擎 (Search Engines) | 基础 RAG 系统 (Standard RAG) | 现有深度研究 Agent (e.g., DeepResearch) | 拟提出的 Cognitive Tech Radar |
| 推理深度 | 单次查询,无推理 | 单步或少步推理 | 多步推理,但易迷失 | 长时程规划 (Master Planner + ToDo) |
| 人机交互 | 关键词调整 | Prompt 工程 | 结果反馈 | 实时过程干预 (Steerable Context) |
| 知识发现 | 仅检索显性信息 | 总结显性信息 | 深度摘要 | 挖掘隐性盲点 (Gap Reflection) |
| 专利分析 | 关键词匹配 | 文本相似度 | 简单总结 | TRIZ 矛盾解析与规避设计 |
动机 (Motivation)
本研究的动机源于填补当前自动化研发工具在认知深度与战略洞察方面的空白。
首先,长时程任务的稳定性亟待提升。Salesforce 的研究表明,通过引入明确的规划工件(如 todo.md),可以显著提高 Agent 在复杂环境下的任务完成率 (P2 )(P234 )。然而,现有的多智能体框架往往缺乏将这种规划能力与特定领域的垂直搜索(如专利、代码)深度结合的机制。
其次,专利挖掘需要工程与创新理论的结合。传统的专利分析工具仅停留在法律文本层面,与工程实现(GitHub 代码)脱节 (P3 )(P44 )。通过引入 TRIZ(发明问题解决理论),我们可以将专利中的“权利要求”转化为具体的“工程矛盾”(如重量与强度的冲突),从而利用 LLM 的推理能力自动生成规避方案 (P43 )(P45 )。
最后,从“被动检索”转向“主动雷达”。企业需要一个能够主动反思“我们需要什么但还不知道”的系统。通过引入反思机制(Reflection Mechanisms),系统可以对比外部前沿与内部知识库,主动提示“技术缺口”,这对于维持企业的技术竞争优势至关重要 (P290 )(P375 )。
拟提出的方法 (Proposed Method)
本提案构建一个认知驱动型技术雷达 (Cognitive Tech Radar),其核心是一个支持人类实时引导的多智能体协作系统。
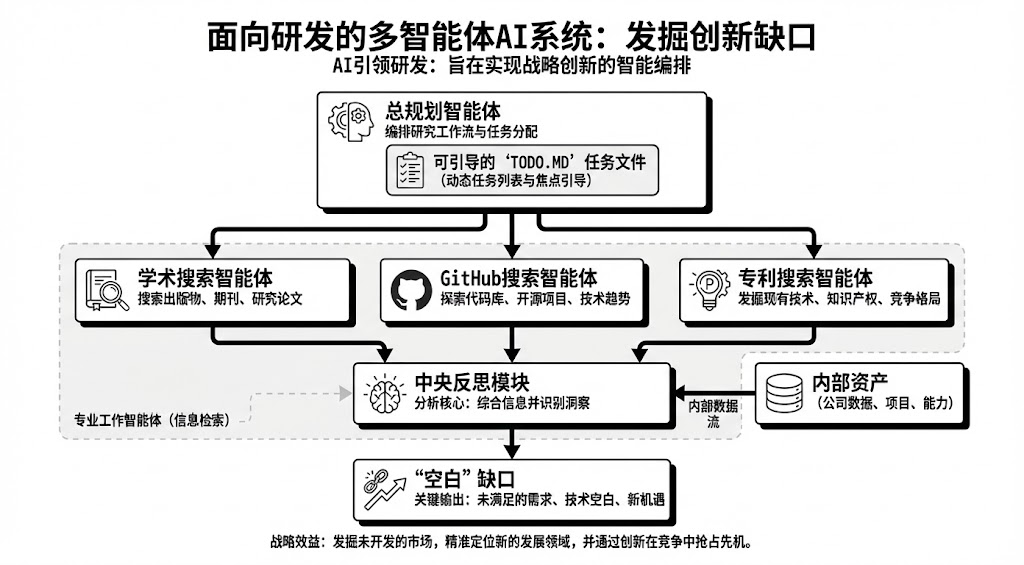
Figure: System Architecture 图:系统架构
4.1 核心架构:Master-Worker 协同与 Steerable ToDo
系统采用分层多智能体架构,由MasterPlanning Agent统一指挥,多个Specialized Worker Agents协同工作。
MasterPlanning Agent (MPA):作为系统的“大脑”,MPA 负责接收高层研发目标(例如“调研用于无人机的抗干扰雷达技术”),并将其分解为细粒度的任务树。
Steerable ToDo 机制:系统的核心创新在于引入了一个共享的、动态的 todo.md 文件作为状态管理中心 (P2 )(G1 )。
4.2 专项搜索智能体 (Specialized Worker Agents)
针对不同数据源的异构性,系统部署了具备特定领域知识 (Domain Knowledge) 的 Worker Agents:
Academic Agent: 专精于 arXiv 和各类学术数据库。它不仅检索论文,还利用 CoT 提取论文中的Methodology(方法论)和Evaluation Metrics(评估指标),过滤掉无关的背景描述 (P234 )。
GitHubAgent: 专注于代码实现。它能够分析 README.md、依赖树和核心算法片段,评估技术的成熟度(如 Stars, Forks,最近更新时间)(P1 )(G1 )。
TRIZ/Patent Agent: 集成 TRIZ 创新理论的专利分析专家 (P43 )(P302 )。它利用 LLM 将晦涩的专利 Claims 映射为 39 个 TRIZ 工程参数,识别技术矛盾,并结合 TRIZ 的 40 个发明原理(如分割、非对称、预先作用)推荐规避设计方案 (P45 )(P47 )。
4.3 知识缺口反思算子 (Knowledge Gap Reflection Operator)
这是本系统的“雷达”功能核心。在每一轮调研结束后,Reflection Agent会执行以下逻辑:
资产对齐 (Alignment): 向量化读取企业内部的产品文档和现有专利库,构建“内部知识流形”。
差分计算 (Difference Calculation): 将外部检索到的高频技术特征与内部知识进行语义对比。
盲点标注 (Blind Spot Labeling): 识别出外部热度高但内部缺失的技术点,标记为“空白区 (White Space)”或“潜在威胁”,并反向更新到 todo.md 中,触发新一轮的针对性补全调研 (P290 )(P376 )。
验证计划 (Validation Plan)
5.1 实验数据集与基准
为了全面评估系统的性能,我们将采用公开基准与自建数据集相结合的方式:
EDR-200: 使用 Salesforce 开源的 200 个企业级深度研究任务集,涵盖金融、医疗、科技等领域的复杂查询 (P2 )(G1 )。
DeepResearch Bench: 包含 214 个专家策划的博士级难度问题,用于评估多跳推理和长篇报告生成的质量 (P285 )(G3 )。
Patent White Space Set (自建): 选取过去 5 年内著名的“技术突袭”案例(即某公司发布突破性技术前,市场上已有的早期信号),测试系统能否基于历史数据“提前发现”这些当时的技术空白。
5.2 评估指标 (Metrics)
| 指标类别 | 指标名称 | 定义与说明 |
| 任务执行 | Steerability Index 可引导性指数 | 衡量 Agent 在 todo.md 被人为修改后,成功切换上下文并执行新指令的成功率。 |
| 洞察质量 | Gap Recall (GR) 缺口召回率(GR) | 系统识别出的“技术盲点”与专家人工审计发现的盲点的重合度。 |
| 内容可信度 | Factuality Score 真实性分数 | 报告中每一个技术主张(Claim)是否有对应且正确的引用源(PDF/URL)支持。 |
| 创新辅助 | TRIZ Effectiveness TRIZ有效性 | 生成的专利规避方案在工程上的可行性(由人类专家评分 1-5)。 |
5.3 实验流程与基线对比
实验将对比以下几种配置:
Baseline 1 (Standard RAG): 基于 GPT-4o 的单次检索生成系统,无任务规划。
Baseline 2 (VanillaEDR): 标准的企业深度研究系统(Salesforce EDR),无 TRIZ 和 反思算子增强 (P2 )。
Proposed System: 完整的 Cognitive Tech Radar。拟议系统:完整的认知技术雷达。
实验步骤:
Phase 1 (Infrastructure): 搭建基于 LangGraph 的多智能体编排环境,集成 todo.md 读写接口 (G1 )。
Phase 2 (Integration): 接入 arXiv, GitHub API 及专利数据库,训练 TRIZ Agent 的矛盾提取能力。
Phase 3 (A/B Testing): 在 EDR-200 数据集上运行对比实验,记录任务完成时间、Token 消耗及 Steerability Index。
Phase 4 (Qualitative Evaluation): 邀请资深研发工程师对 Patent White Space Set 的输出报告进行盲测评分。
预期成果与风险 (Expected Outcomes and Risks)
6.1 预期成果
效率提升: 预计相比人工调研,长时程技术溯源的耗时将缩短 50% 以上,同时相比传统 Agent,任务成功率提升 30% (P2 )(P232 )。
战略洞察: 系统不仅能生成“总结报告”,还能输出可视化的“技术雷达图”,明确指出企业在特定领域的 IP 布局薄弱点。
工程化创新: 通过 TRIZ Agent,能够自动化生成 3-5 个具有专利规避潜力的技术方案,直接辅助研发立项。
6.2 风险与缓解策略
幻觉风险 (Hallucination): LLM 可能编造不存在的技术参数。缓解: 强制要求所有事实性陈述必须附带可验证的引用链接 (Citation Enforcement) (P285 ),并引入 Critiquer Agent 进行自我审查。
专利法律边界: Agent 生成的规避方案可能存在法律风险。缓解: 在报告中明确标注“仅供工程参考,需法律复核”,并微调模型以理解基本的专利权利要求结构 (P312 )。
计算成本: 多智能体多轮迭代可能导致 Token 消耗巨大。缓解: 优化 todo.md 的更新频率,并在非关键推理步骤使用轻量级模型。
本提案旨在通过结构化的认知架构,将 AI 从简单的“搜索助理”升级为具备战略眼光的“研发参谋”,真正赋能企业的技术创新与风险防御。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献614条内容
已为社区贡献614条内容

所有评论(0)