AI学习笔记整理(68)——AI大模型与物理AI
用户通过语言交互界面与后端交互,无需或者少量通过图形界面与后端交互,最终呈现GUI(图形用户界面)和LUI(语言用户界面)混合的交互形式,以实现用户从有限的输入跃迁到无限的输入,既提供高频、固定的功能,也具备对低频、定制化需求的理解与处理能力。物理仿真引擎则负责实时计算物理交互,这不是简单的预设规则,而是基于偏微分方程求解器的动态计算系统,需要处理刚体动力学、流体力学、软体变形等复杂物理现象,系统
AI大模型与物理AI区别
AI大模型与物理AI的核心区别在于其对世界的理解方式、学习路径和输出能力,前者主要处理符号与文本,后者则致力于理解并干预物理现实。
AI大模型与物理AI在本质、能力边界和应用方式上存在根本性差异,可概括为“符号概率预测”与“物理规律建模”的区分。
核心区别
- 本质与认知维度
- AI大模型:本质上是“文本概率预测器”。它通过分析海量的文本和图像数据,学习词语、概念之间的统计关联(例如,“玻璃杯”常与“易碎”一同出现),但无法理解这些现象背后的物理机制(如重力、材料的脆性、动量守恒)。例如,知道“玻璃杯易碎”,但不理解重力和材料脆性如何导致其破碎。
- 物理AI:目标是构建“世界模型”。它通过多模态数据(如视频、传感器读数)学习物理世界的基本规律,具备对三维空间、物体状态和物理定律的隐式理解,如空间关系、力学、摩擦力、能量守恒等,并能基于这些规律预测动态结果(如物体下落轨迹、碰撞后的运动状态)。
- 学习与训练方式
- AI大模型:主要依赖静态的、历史积累的互联网文本和图像数据进行训练。输出是基于模式匹配的文本或图像。
- 物理AI:需要虚实融合的训练。它首先在高精度的仿真环境(如英伟达Omniverse)中进行数百万次的物理交互模拟,学习物理规律,然后将这些知识迁移到现实世界的机器人或自动驾驶系统中进行验证和优化。
- 输出与能力
- AI大模型:输出是描述性的。它能生成关于“雨天路滑”的文字解释,或回答“如何开车”这类问题,但无法直接控制物理设备。
- 物理AI:输出是可执行的指令。它能直接生成控制信号,例如让汽车实时调整悬架硬度以应对冰面,或指挥机械臂以特定力度抓取易碎物品,实现从“感知”到“行动”的闭环。
- 应用场景
- AI大模型:主要应用于虚拟服务,如智能客服、文案生成、代码辅助、信息检索等。
- 物理AI:是具身智能的核心,赋能机器人、自动驾驶、智能制造等实体产业,使机器能与物理世界进行大规模、高精度的协作,例如:
- 小鹏的VLA大模型实现“视觉信号→动作指令”的端到端控制,复杂道路接管率提升13倍。
- 工业机器人通过物理仿真预判机械振动,抓取效率提升40%。
- 技术基础
- AI大模型:基于大规模神经网络和语言模型(如Transformer)
- 物理AI:建立在世界模型、物理仿真引擎和具身智能控制器三大组件之上。
简而言之,AI大模型是“懂文字的智者”,而物理AI是“懂物理的行动者”。AI大模型是“数字世界的语言专家”,而物理AI是“物理世界的共治者”——它不仅理解世界,更能像人类一样通过“具身体验”去感知、推理并行动。物理AI的出现,标志着AI从“拟合数据”向“发现规律”迈进,是实现通用人工智能(AGI)的关键跃迁。
AI原生、物理AI
源链接:https://baijiahao.baidu.com/s?id=1850544954707042051&wfr=spider&for=pc
AI原生
如果说“AI+”是在现有系统上“打补丁”或“外挂”AI功能,那么AI原生则意味着以AI为系统设计的底层逻辑与能力中枢,这套系统为AI而生、因AI而长,驱动从技术架构、业务流程、组织角色到价值创造方式的全方位重塑。
这种变革并非简单的功能叠加,而是以生成式AI为核心重构开发范式,让智能成为应用的原生属性而非附加能力。从“AI+”走向“AI原生”,正成为AI未来发展的关键方向。
一个真正的AI原生系统或应用,通常具备以下三个显著特征:
首先,以自然语言交互为基础。用户通过语言交互界面与后端交互,无需或者少量通过图形界面与后端交互,最终呈现GUI(图形用户界面)和LUI(语言用户界面)混合的交互形式,以实现用户从有限的输入跃迁到无限的输入,既提供高频、固定的功能,也具备对低频、定制化需求的理解与处理能力。
其次,具备自主学习和适应能力。在人机交互过程中,能够集成理解、记忆、适应多模态数据,并进行自我学习,能根据上下文、任务环境、交互对象的变化,对输出结果进行更准确、更个性化的调整。
第三,具备自主完成任务的能力:有能力基于大语言模型和知识库执行精确任务,实现端到端闭环,集获取任务到完成任务全流程于一体。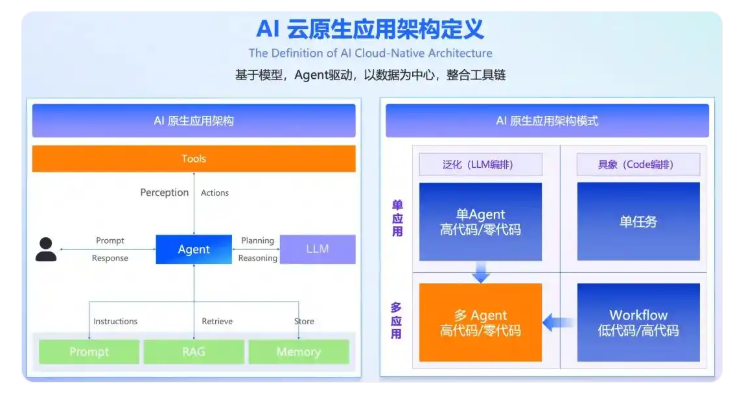
当前,AI原生开发平台已形成明确趋势,低代码/无代码工具让普通人无需编程即可打造专属AI工具,催生大量“一人公司”模式;微软、字节跳动等巨头正将AI智能体深度嵌入办公套件,实现“邮件摘要-日程规划-任务执行”的端到端闭环。
AI原生应用的发展需要各类工具应用的产品化,比如部署和管理大模型的Hub平台、产品化的大模型自动化微调工具、高精确度低成本的知识图谱生成管理工具、Agent高效编程的集成开发环境等等。大规模普及AI原生应用以解决各种问题的前提是具备完善的工具和框架体系,而非任一场景下都需要全流程自研。所谓“磨刀不误砍柴工”,产品化工具和框架的积累将是AI原生应用快速普及的关键成功因素。
落地价值在办公场景尤为突出,AI原生邮件工具可自动识别会议邀约并同步至日程,智能生成参会预案;设计类应用能根据用户草图实时生成多版方案并匹配市场数据。这种“需求直达结果”的模式,将知识工作者的重复劳动时间减少40%以上。
AI原生是2026年To C端最确定的增量市场,其核心竞争力不在于技术本身,而在于对用户习惯的重构——当AI从“需要召唤”变为“主动服务”,新的生态壁垒便已形成。
AI原生应用的技术架构、工具产品以及方法论会在1~2年内不断演进,积累量变因素,最终达到成熟、可大规模复用的程度,之后AI原生应用将全面爆发。而在短期内,“AI原生应用”与“传统应用+AI”仍将共存。
物理AI
2026年的AI不再局限于屏幕,而是以物理实体的形态渗透到城市、工厂、医院、家庭等场景,这便是物理AI的核心——通过嵌入式智能连接数字世界与物理环境,实现从“感知”到“行动”的跨越。
AI的发展经历了三个清晰的阶段:
最初是感知AI(Perceptual AI),能够理解图像、文字和声音,这个阶段的代表是计算机视觉和语音识别技术。
之后是生成式AI(Generative AI),能够创造文本、图像和声音,以ChatGPT、DALL-E等为代表。
现在我们正进入物理AI(Physical AI)时代,AI不仅能够理解世界,还能够像人一样进行推理、计划和行动。
物理AI的技术基础建立在三个关键组件之上:世界模型、物理仿真引擎和具身智能控制器。
世界模型
世界模型是物理AI的认知核心,它不同于传统的语言模型或图像模型,需要构建对三维空间的完整理解,包括物体的几何形状、材质属性、运动状态和相互关系。这通常通过神经辐射场(NeRF)、3D高斯溅射(3D Gaussian Splatting)或体素网格(Voxel Grid)等方法来实现空间表征,模型需要学习物理定律的隐式表示,比如重力加速度、摩擦系数、弹性模量等参数,并能够根据当前状态预测未来的物理演化。
物理仿真引擎
物理仿真引擎则负责实时计算物理交互,这不是简单的预设规则,而是基于偏微分方程求解器的动态计算系统,需要处理刚体动力学、流体力学、软体变形等复杂物理现象,系统需要在毫秒级时间内完成复杂的物理计算,同时保证足够的精度来支持准确的决策。
具身智能控制器
具身智能控制器是连接虚拟推理和物理执行的桥梁,它接收来自世界模型的预测结果和物理仿真的计算输出,生成具体的控制指令。技术上,通常基于模型预测控制(MPC)或深度强化学习(DRL)算法,控制器需要处理高维的状态空间和动作空间,同时考虑执行器的物理限制、延迟和噪声。
多模态将成为AI基础能力
随着AI技术的飞速发展,单一模态的AI模型已难以满足现实世界的复杂需求。2025年,多模态大模型(Multimodal Large Models,MLLMs)以强大的跨模态理解和推理能力,成为推动产业智能化升级和社会数字化转型的中坚力量。
多模态大模型不仅能同时处理文本、图像、音频、视频、3D模型等多种数据类型,还能实现信息的深度融合与推理,极大拓展了Al的应用边界。
当前的语言大模型、拼接式的多模态大模型对人类思维过程的模拟存在天然的局限性。从训练之初就打通多模态数据,实现端到端输入和输出的原生多模态技术路线给出了多模态发展的新可能。
基于此,训练阶段即对齐视觉、音频、3D等模态的数据实现多模态统一,构建原生多模态大模型,成为多模态大模型进化的重要方向。
所谓“原生”,是指模型在底层设计上就将图像、语音、文本乃至视频等多种模态嵌入同一个共享的向量表示空间,从而使不同模态间能够自然对齐、无缝切换,无须经过文本中转,以实现更高效、更一致的理解与生成。
世界模型与大模型
世界模型(World Model)与大模型(通常指大语言模型,LLM)的核心区别在于:世界模型旨在理解和模拟物理世界的运行规律,侧重因果推理与状态预测;而大语言模型则专注于理解和生成人类语言,基于海量文本数据进行统计关联与模式匹配。
世界模型并没有一个标准的定义,这一概念源于认知科学和机器人学,它强调AI系统需要具备对物理世界的直观理解,而不仅仅是处理离散的符号或数据。
世界模型的价值在于“泛化能力”——能够将已知场景的认知迁移到未知场景,例如在未见过的乡村道路上,基于对物理规律的理解,依然能安全行驶。
行业普遍认为,世界模型是一种能够对现实世界环境进行仿真,并基于文本、图像、视频和运动等输入数据来生成视频、预测未来状态的生成式Al模型。它整合了多种语义信息,如视觉、听觉、语言等,通过机器学习、深度学习和其他数学模型来理解和预测现实世界中的现象、行为和因果关系。
简单来说,世界模型就像是AI系统对现实世界的“内在理解”和“心理模拟”。它不仅能够处理输入的数据,还能估计未直接感知的状态,并预测未来状态的变化。
这个模型的核心目标是让AI系统能够像人类一样,在内部构建一个对外部物理环境的模拟和理解。通过这种方式,AI可以在“脑海”中模拟和预测不同行为可能导致的后果,从而进行有效的规划和决策。
例如,一个具备世界模型的自动驾驶系统,可以在遇到湿滑路面时,预判到如果车速过快可能会导致刹车距离延长,从而提前减速,避免危险。这种能力源于AI内部对物理规律(如摩擦力、惯性)的模拟,而不是简单地记忆“湿滑路面要减速”这条规则。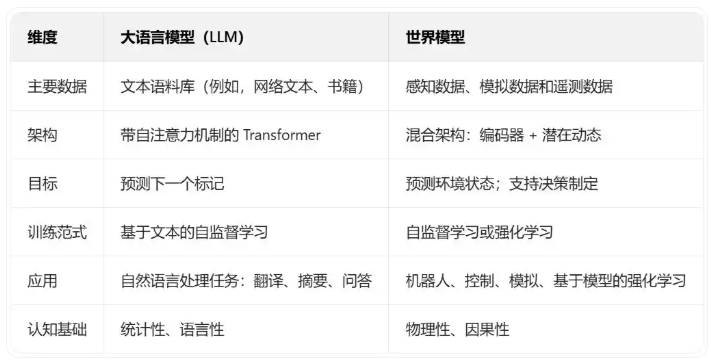
世界模型具有三大核心特点:
其一,内在表征与预测。世界模型可以将高维的原始观测数据(如图像、声音、文本等)编码为低维的潜在状态,形成对世界的简洁而有效的表征。在此基础上,它能够预测在给定当前状态和动作的情况下,下一个时刻的状态分布,从而实现对未来事件的前瞻性预测。
其二,物理认知与因果关系。世界模型具备基本的物理认知能力,能够理解和模拟物理世界的规律,如重力、摩擦力、运动轨迹等。这使得它在处理与物理世界相关的问题时,能够提供更准确、更符合现实的预测和决策支持。
其三,反事实推理能力。世界模型不仅能够基于已有的数据进行预测,还能够进行假设性思考,即反事实推理。例如,它可以回答“如果环境条件改变,结果会怎样”这类问题,从而为复杂问题的解决提供更多的可能性和思路。
技术层面,世界模型关键技术包括因果推理、场景重建时空一致性、多模数据物理规则描述、执行与实时反馈。全球主流模型如谷歌Genie3、英伟达COSMOS等,国内华为盘古、蔚来NWM等模型在不同应用场景展现优势。
数据依赖与应用场景
1. 数据来源:
- 世界模型依赖多模态时序交互数据,如视频、传感器反馈、动作序列等。
- 大语言模型依赖超大规模静态文本数据,如书籍、网页、代码等。
2.典型应用:
- 世界模型主要用于需要与物理世界交互的领域,如自动驾驶(模拟极端场景、轨迹规划)、机器人(动作预演)、游戏AI和工业仿真。
- 大语言模型主要用于纯数字空间任务,如智能对话、文本创作、代码生成、翻译和知识问答。
世界模型是智能体(如AI、动物或人)在内心构建的、关于外部环境如何运行的一套“心理模型”,用于理解因果、预测变化和规划行动。
- 大模型,核心是 “懂文字”。它活在由语言和信息构成的“二手世界”里。
- 世界模型,核心是 “懂规律”。它活在由物理和因果构成的“一手世界”里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)