用MCP+MindsDB+Ollama打造本地RAG系统:200+数据源统一查询,小白也能轻松上手
本文介绍了一种完全本地化的RAG系统构建方案,通过MindsDB、MCP客户端和Ollama技术实现多数据源查询。系统采用六步实施流程:1)运行MindsDB容器;2)访问本地图形界面;3)连接200+数据源;4)配置MCP服务器;5)设置本地客户端与LLM;6)创建Streamlit聊天界面。该方案无需云服务,保障数据安全,支持灵活组件替换,为开发者提供了学习大模型应用的实用教程,实现从单一界面
本文详细介绍如何构建本地RAG系统,通过MCP客户端、MindsDB和Ollama技术,实现单一聊天界面查询200+数据源。文章提供六步实操指南:运行MindsDB、获取图形界面、连接数据源、配置MCP服务器、设置本地MCP客户端和Ollama,以及创建Streamlit界面。整个方案完全本地化,不依赖云服务,保护敏感数据,同时支持灵活组件更换,是程序员学习大模型应用的实用教程。
字数 5130,阅读大约需 17 分钟
大多数公司都面临同样的现实:数据无处不在。您的邮箱里有邮件,Slack里有对话,GitHub里有代码,Google Drive里有报表,甚至可能还有一些没人记得密码的随机分析仪表板。
如果您想构建一个检索增强生成(RAG)系统,那简直是一场噩梦。您不能只连接一个数据源就万事大吉,除非您对半生不熟的答案感到满意。
各大厂商早已深谙此道:
- • 微软将RAG集成到M365产品中
- • 谷歌将其融入Vertex AI Search
- • AWS在Amazon Q Business中推出了自己的解决方案
如果您完全投入某个生态系统,这确实很美好。但如果您想按自己的方式来做,在本地运行,完全不依赖云服务呢?
那么……让我们构建一个吧。
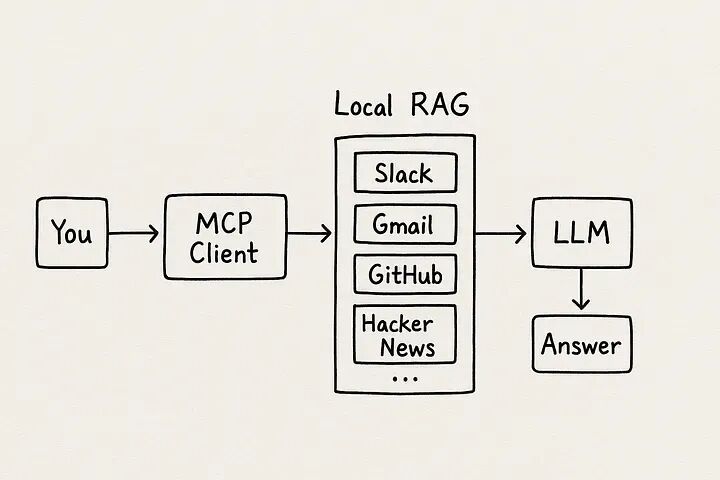
通过AI生成的粗略手绘风格工作流程图
我们要构建什么
我们将构建一个本地AI设置,可以通过单一的聊天界面查询200多个不同的数据源,使用以下技术:
- • mcp-use(来自YC S25的便捷工具)用于本地MCP客户端
- • MindsDB 用于连接所有这些数据源
- • Ollama 用于在本地运行开源大语言模型
一旦您理解了,整个流程就相当简单:
-
- 您在聊天框中输入问题
-
- MCP客户端将其传递给MindsDB MCP服务器
-
- MindsDB确定您实际要查询的数据源
-
- 它对数据源进行查询,将结果发送给您的LLM,然后——瞧——您得到了一个有实际上下文支撑的答案
如果您更喜欢图片而非文字,本质上就是这样:
您 → MCP客户端 → MindsDB MCP服务器 → 您的数据源 → LLM → 答案
步骤1——本地运行MindsDB
我们将使用Docker运行MindsDB。
打开终端并运行:
docker run -it -p 47334:47334 mindsdb/mindsdb
就是这样,无需注册,无需云服务。您现在正在自己的机器上运行MindsDB。
步骤2——获取MindsDB图形界面
打开浏览器并访问:
http://localhost:47334
您应该能看到MindsDB编辑器——有点像SQL工作台,但内置了魔法。从这里,您可以连接数百个不同的数据源:Slack、Gmail、Salesforce、MySQL,应有尽有。
步骤3——连接一些数据
这里是我连接的几个示例,向您展示这有多简单:
-- SlackCREATE DATABASE slack_dbWITH ENGINE = "slack",PARAMETERS = { "token": "your-slack-api-token"};-- GmailCREATE DATABASE gmail_dbWITH ENGINE = "gmail",PARAMETERS = { "credentials": "gmail_credentials.json"};-- GitHubCREATE DATABASE github_dbWITH ENGINE = "github",PARAMETERS = { "token": "your-github-token"};-- Hacker NewsCREATE DATABASE hn_dbWITH ENGINE = "hacker_news";
之后,您可以运行常规的SQL查询,例如:
SELECT * FROM gmail_db.inbox WHERE is_unread = true;
相当疯狂吧。
步骤4——MCP服务器配置
好了,MindsDB可以与我们的数据通信,但现在我们希望它支持MCP协议,以便我们的AI智能体可以使用它。
我们为此创建一个小的JSON文件:
{ "servers": { "mindsdb": { "url": "http://localhost:47334", "tools": ["list_databases", "query"] } }}
现在我们的MCP客户端知道了MindsDB服务器的位置及其提供的工具。
步骤5——本地MCP客户端+Ollama
这部分实际上很有趣——只需要几行Python代码。
from mcp_use import MCPClientfrom ollama import ChatModel# 1. 加载MCP客户端配置client = MCPClient.from_config("mcp_config.json")# 2. 连接本地LLMllm = ChatModel("llama3")# 3. 创建智能体agent = llm.bind(client)# 4. 运行查询response = agent.ask("Show me all unread Slack messages from this week.")print(response)
这简直太简单了。您只需将"llama3"改为"mistral"或"gemma2"就可以轻松切换LLM。
步骤6——Streamlit中的快速界面
如果您想要一个不错的基于浏览器的聊天框(谁不想要呢):
import streamlit as stst.title("MCP驱动的RAG")query = st.text_input("问我任何问题:")if st.button("运行"): answer = agent.ask(query) st.write(answer)
运行它:
streamlit run app.py
输入"列出分配给我的所有GitHub问题",然后见证魔法的发生。
这是一个单一的Python文件(app.py),它将整个本地RAG工作流程整合在一个地方——从MCP客户端,通过MindsDB工具,到本地LLM(Ollama),全部封装在Streamlit界面中。
安装(一次性):
# 如果您愿意,创建一个虚拟环境,然后:pip install streamlit requests# 以下两个是按原样提供的;如果您有它们就安装pip install mcp_use ollama# 如果这些包在您的pip环境中不可用,# 请遵循mcp_use / ollama的安装文档并调整下面的导入。
app.py(单文件RAG,集成在一个框架中)
"""app.py单文件Streamlit应用,演示本地RAG流程:您(界面)→ MCP客户端 → MindsDB(list_databases / query)→ Ollama LLM → 答案注意:- 需要在http://localhost:47334运行MindsDB(MindsDB Docker)。- 需要本地Ollama / LLM可通过ollama Python绑定访问。- 假设有mcp_use Python客户端;如果您的环境不同, 请调整下面的小包装函数以调用正确的方法。运行:streamlit run app.py"""import jsonimport timeimport tracebackfrom typing import Any, Dict, List, Optionalimport streamlit as stimport requests# 尝试导入mcp_use和ollama。如果缺失,应用仍会启动并显示说明。try: from mcp_use import MCPClient # 根据前面的示例,期望在您的环境中 _HAS_MCP_USE = Trueexcept Exception: MCPClient = None _HAS_MCP_USE = Falsetry: # Ollama python客户端的形状因版本而异;这反映了早期的用法:ChatModel(...) from ollama import ChatModel _HAS_OLLAMA = Trueexcept Exception: ChatModel = None _HAS_OLLAMA = False# ---------------------------# 工具函数 / 包装器# ---------------------------DEFAULT_MCP_CONFIG = { "servers": { "mindsdb": { "url": "http://localhost:47334", "tools": ["list_databases", "query"] } }}def ensure_mcp_config_file(path: str = "mcp_config.json"): """如果文件不存在,写入默认的MCP配置。""" try: with open(path, "x") as f: json.dump(DEFAULT_MCP_CONFIG, f, indent=2) print(f"在{path}创建了默认MCP配置") except FileExistsError: passclass SimpleMCPWrapper: """ 对mcp_use.MCPClient的小型兼容包装器,以提供 list_databases()和query()调用,采用容错方式。 """ def __init__(self, config_path: str = "mcp_config.json"): self.config_path = config_path self.client = None if _HAS_MCP_USE and MCPClient is not None: try: self.client = MCPClient.from_config(config_path) except Exception as e: # 某些版本可能有不同的构造函数——尝试备选方案 try: self.client = MCPClient(config_path) except Exception as e2: print("从库初始化MCPClient失败。将在可能的情况下回退到HTTP。") print("mcp_use错误:", e, e2) # 还存储MindsDB基本URL用于HTTP回退 with open(config_path, "r") as f: cfg = json.load(f) try: self.mindsdb_url = cfg["servers"]["mindsdb"]["url"].rstrip("/") except Exception: self.mindsdb_url = "http://localhost:47334" def list_databases(self) -> List[str]: """返回数据库/数据源列表。尝试客户端,然后回退到HTTP。""" # 尝试MCP客户端调用 if self.client: # 尝试常见的函数名 for name in ("list_databases", "list_databases_tool", "list_tools", "tools"): fn = getattr(self.client, name, None) if callable(fn): try: out = fn() # 如果返回的是带有'databases'或类似的字典,进行标准化 if isinstance(out, dict): if "databases" in out: return out["databases"] # 尝试解析其他形状 return list(out.keys()) if isinstance(out, (list, tuple)): return list(out) except Exception: pass # 如果存在,尝试通用的'call'或'invoke'接口 for name in ("call_tool", "invoke_tool", "call"): fn = getattr(self.client, name, None) if callable(fn): try: # 某些MCP客户端期望服务器/工具名称 try: out = fn("mindsdb", "list_databases", {}) except TypeError: out = fn("list_databases") if isinstance(out, (list, tuple)): return list(out) if isinstance(out, dict) and "databases" in out: return out["databases"] except Exception: pass # HTTP回退到MindsDB REST(尽力而为) # MindsDB在不同版本中没有单一的标准化公共"列出数据库"端点, # 但我们可以尝试调用模式或连接器端点。 try: # 尝试MindsDB的常见API端点 resp = requests.get(f"{self.mindsdb_url}/api/databases", timeout=6) if resp.ok: payload = resp.json() # 尝试常见的形状 if isinstance(payload, dict): if "data" in payload and isinstance(payload["data"], list): return [d.get("name") or d.get("database") or str(d) for d in payload["data"]] return list(payload.keys()) if isinstance(payload, list): return [p.get("name") if isinstance(p, dict) else str(p) for p in payload] except Exception: pass # 如果到达这里,返回一条有帮助的消息 return ["(无法枚举——检查MCP客户端或MindsDB)"] def query(self, query_text: str, max_rows: int = 50) -> Dict[str, Any]: """ 让MindsDB运行联合查询(尽力而为)。 此包装器首先尝试MCP客户端;否则尝试MindsDB SQL端点。 """ # 尝试MCP客户端 if self.client: for name in ("query", "run_query", "invoke_query", "call_tool"): fn = getattr(self.client, name, None) if callable(fn): try: # 尝试几种参数形状 try: out = fn("mindsdb", "query", {"query": query_text, "max_rows": max_rows}) except TypeError: out = fn(query_text) return {"source": "mcp_client", "result": out} except Exception: # 继续尝试其他函数名 pass # 回退:尝试MindsDB查询HTTP端点(尽力而为使用/api/sql) try: # 某些MindsDB版本公开/api/sql或/api查询;尝试两者 for endpoint in ("/api/sql", "/api/query", "/api/query/execute", "/api/sql/execute"): try: resp = requests.post(self.mindsdb_url + endpoint, json={"query": query_text}, timeout=15) except Exception: continue if not resp.ok: continue try: data = resp.json() except Exception: data = resp.text return {"source": "mindsdb_http", "result": data} except Exception: pass # 如果全部失败: return {"source": "error", "error": "无法运行查询。检查MCP客户端或MindsDB HTTP API。"}class OllamaWrapper: """向Ollama发送提示的最小包装器(本地LLM)。""" def __init__(self, model_name: str = "llama3"): self.model_name = model_name self.model = None if _HAS_OLLAMA and ChatModel is not None: try: # API各不相同——有些库是ChatModel(name=...),其他使用client.chat(...) try: self.model = ChatModel(model_name) except Exception: # 尝试不同的构造方式 self.model = ChatModel(model=model_name) except Exception as e: print("初始化ollama.ChatModel失败:", e) self.model = None def chat(self, prompt: str, max_tokens: int = 512) -> str: # 尝试python绑定 if self.model: for fnname in ("chat", "generate", "complete", "__call__"): fn = getattr(self.model, fnname, None) if callable(fn): try: out = fn(prompt) # 许多包装器返回复杂对象;标准化为字符串 if isinstance(out, (str,)): return out if isinstance(out, dict) and "text" in out: return out["text"] # 尝试字符串化 return str(out) except Exception: continue # 回退:尝试本地Ollama HTTP(如果Ollama守护进程在11434上监听) try: ollama_url = "http://localhost:11434/api/generate" payload = {"model": self.model_name, "prompt": prompt} resp = requests.post(ollama_url, json=payload, timeout=20) if resp.ok: data = resp.json() # 形状会不同;尝试提取常见字段 if isinstance(data, dict): if "text" in data: return data["text"] if "response" in data: return str(data["response"]) return str(data) except Exception: pass return "(LLM不可用:无法与Ollama Python客户端或HTTP端点通信。)"# ---------------------------# 构建Streamlit界面# ---------------------------st.set_page_config(page_title="本地RAG(MCP + MindsDB + Ollama)", layout="wide")st.title("本地RAG——单帧演示(MCP → MindsDB → Ollama)")st.markdown( """此演示期望:- 在本地运行MindsDB(Docker),地址为`http://localhost:47334`- 本地Ollama LLM(或Ollama HTTP端点,地址为http://localhost:11434)- 如果您想要直接绑定,则需要`mcp_use`和`ollama` python库。如果缺少任何部分,界面仍将在可能的情况下通过HTTP回退运行查询。""")# 确保默认配置存在ensure_mcp_config_file("mcp_config.json")col1, col2 = st.columns([1, 2])with col1: st.subheader("MCP / MindsDB") st.write("编辑MCP配置(JSON):") mcp_config_text = st.text_area("mcp_config.json", value=json.dumps(DEFAULT_MCP_CONFIG, indent=2), height=220) if st.button("保存MCP配置"): with open("mcp_config.json", "w") as f: f.write(mcp_config_text) st.success("已保存mcp_config.json") time.sleep(0.2) if st.button("列出数据源"): wrapper = SimpleMCPWrapper("mcp_config.json") try: dbs = wrapper.list_databases() st.write("数据源 / 数据库:") st.json(dbs) except Exception as e: st.error("列出数据库失败:" + str(e)) st.text(traceback.format_exc()) st.markdown("---") st.write("针对MindsDB运行原始联合SQL查询(尽力而为):") raw_query = st.text_area("原始SQL(示例):", value="SELECT * FROM gmail_db.inbox WHERE is_unread = true LIMIT 20;", height=140) if st.button("运行原始查询"): wrapper = SimpleMCPWrapper("mcp_config.json") res = wrapper.query(raw_query) if res.get("source") == "error": st.error(res.get("error")) else: st.write("结果(来源 = %s)" % res.get("source")) st.json(res.get("result"))with col2: st.subheader("聊天 + RAG(查询 → MindsDB工具 → Ollama)") st.write("高级查询(纯英文)。应用将:通过MCP包装器识别数据源,运行查询,并使用本地LLM进行总结。") user_q = st.text_input("询问(例如,'显示过去7天未读的Slack消息'):") model_name = st.text_input("Ollama模型名称:", value="llama3") max_rows = st.slider("要获取的最大行数(联合查询)", 1, 500, 50) if st.button("运行RAG查询") and user_q.strip(): st.info("正在运行RAG流程...") # 1) 调用MCP包装器运行mindsdb 'query'工具(尽力而为) wrapper = SimpleMCPWrapper("mcp_config.json") # 非常简单的启发式——在实践中您会调用MCP "query"工具来将 # 用户文本翻译成SQL或询问MindsDB的SQL转换器。这里我们只是转发用户文本。 try: mindsdb_resp = wrapper.query(user_q, max_rows=max_rows) except Exception as e: st.error("MindsDB查询步骤失败:" + str(e)) mindsdb_resp = {"source": "error", "error": str(e)} if mindsdb_resp.get("source") == "error": st.error("MindsDB步骤无法运行。请参阅下面的详细信息。") st.json(mindsdb_resp) else: st.success("MindsDB返回了结果(尽力而为)。") st.subheader("来自MindsDB的原始数据") st.json(mindsdb_resp.get("result")) # 2) 使用本地LLM进行总结/生成答案 st.subheader("LLM总结 / 答案") ollama = OllamaWrapper(model_name=model_name) # 制作总结提示:包含用户问题 + 原始输出(字符串化) # 保持提示简短以避免令牌爆炸——如果结果很大,则进行采样或总结模式 raw_text = mindsdb_resp.get("result") # 将复杂负载转换为紧凑字符串 try: raw_preview = json.dumps(raw_text, indent=2)[:4000] except Exception: raw_preview = str(raw_text)[:4000] prompt = ( "您是一个有用的助手。用户询问:\n\n" f"\"{user_q}\"\n\n" "以下是从联合数据源检索的结果(截断):\n" f"{raw_preview}\n\n" "请提供简洁、清晰且可操作的答案,引用数据中的相关事实。" ) # 调用聊天模型 llm_response = ollama.chat(prompt) st.write(llm_response)st.markdown("---")st.caption("此示例故意采取防御性策略:首先尝试Python绑定,然后尝试HTTP回退。\ 调整小包装器以匹配您安装的确切mcp_use / ollama API。")
这让我们处于什么位置
- • 200+数据源。一个界面。
- • 100%本地化。敏感数据不会离开您的机器。
- • 易于更换组件——您可以更改LLM、添加/删除数据源,甚至更改MCP客户端,而不会破坏一切。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献737条内容
已为社区贡献737条内容

所有评论(0)