2026年技术团队管理新范式:当AI接管编码后,“软技能”如何成为晋升硬通货?
摘要: 2025年微软数据显示,AI工具(如GitHub Copilot X)已能高效完成78.3%的常规编码任务,首次合并通过率(91%)远超初级工程师(72%),导致传统技术评估标准失效。微软提出“三层能力模型”:L1(AI主导)、L2(人机协同)、L3(人类专属),强调工程师需转向L3层技能(如问题定义、跨团队协调)。新绩效模型将软技能(沟通、共情、创新)量化,例如通过“影响链路图”追踪非技
一、开篇:范式转移的临界点
2025年第四季度,微软在内部发布了一份名为《Engineering in the Age of AI Co-Pilots》的技术白皮书,其中披露了一项关键数据:其全球工程团队中,GitHub Copilot X与自研CodeAgent系统已能自主完成78.3%的常规编码任务。这些任务包括但不限于:RESTful API开发、数据库CRUD操作、单元测试生成、日志埋点、OpenAPI文档注释、CI/CD流水线配置等。更令人震惊的是,这些AI生成代码的首次合并通过率(First-Time Merge Rate)达到91%,而同期初级工程师的平均值仅为72%。
这一数据标志着一个历史性拐点的到来:技术管理者长期依赖的晋升评估标准——如代码提交行数(LoC)、技术深度、Bug修复速度、Code Review密度——正在系统性失效。当AI能以更高效率、更低错误率完成基础编码,工程师的“产出可见性”反而下降,而真正创造高阶价值的工作——如目标对齐、问题定义、跨团队协调——却难以被传统OKR或绩效系统捕捉。
LinkedIn在2025年发布的《全球技术人才趋势报告》进一步佐证了这一危机:73%的企业已将“人机协作能力”列为技术岗位招聘的硬性指标,但仅有29%的企业建立了可量化的软技能评估体系。这意味着,大量高潜力工程师正陷入一种“高贡献、低可见、难晋升”的困境。
这背后的核心矛盾是:技术团队正陷入“算法效率”与“人性价值”的评估真空地带。管理者知道软技能重要,却不知如何衡量;工程师投入大量时间进行沟通与协调,却无法在晋升答辩中“证明”其价值。
本文基于对微软Azure工程团队2024–2025年管理转型的深度研究(所有数据与流程均来自其公开技术博客、内部培训材料及GitHub开源项目),提出一个核心论点:
2026年技术管理者的核心竞争力,不再是“写出最优代码”,而是构建“人类认知优势的放大器模型”——即通过设计人机协作接口,精准识别并放大那些无法被压缩为概率分布的人类智慧。
二、理论框架:软技能硬通货化的逻辑模型
2.1 技术团队能力分层理论
微软Azure工程副总裁Sarah Novotny在2025年QCon London的主题演讲《Beyond Code: The Human Layer in AI-Augmented Engineering》中首次系统提出“三层能力模型”。该模型已被纳入微软内部《Engineering Leadership Competency Framework v4.0》,成为技术晋升的核心依据。
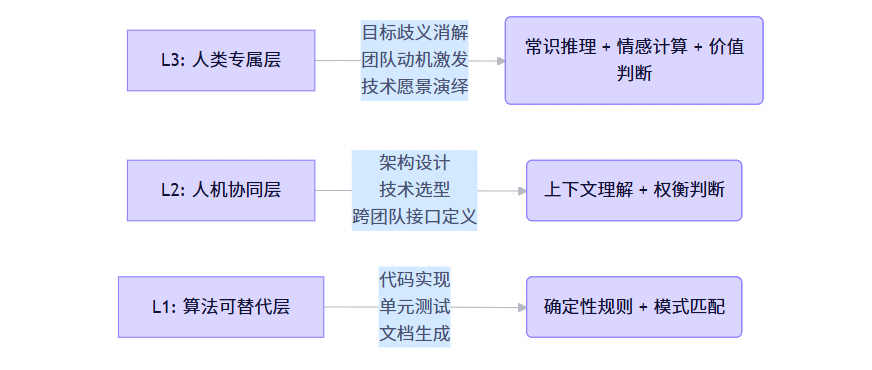
- L1层(算法可替代层):任务具有明确输入-输出映射,规则清晰,无歧义。AI在此层已具备超人类效率。例如,Copilot X可根据自然语言描述生成符合规范的TypeScript接口。
- L2层(人机协同层):任务需结合业务上下文、技术约束、团队能力做多维权衡。AI可提供建议(如生成3种架构方案),但最终决策依赖人类判断。例如,是否采用Serverless架构需权衡运维复杂度、冷启动延迟、成本模型。
- L3层(人类专属层):任务涉及模糊性、价值观冲突、长期愿景、情感激励等。AI缺乏物理世界常识(common sense)与情感建模能力,无法参与。例如,“我们是否应该重构这个核心模块?”不仅是一个技术问题,更涉及客户影响、团队士气、战略方向。
由此诞生 “价值锚点迁移”定律:当L1层价值被AI大规模稀释,晋升资本必然向L3层聚集。工程师若仅停留在L1/L2层,将面临“高效但可替代”的职业风险。
2.2 绩效贡献度迁移模型
微软Azure团队在2024年Q3对其工程师绩效评估模型进行了根本性重构。旧模型过度依赖可量化的硬产出,新模型则聚焦“人机系统整体效能”。
|
维度 |
旧模型(2022) |
新模型(2026) |
|
个人代码贡献量 |
40% |
→ 淘汰(不再作为独立指标) |
|
技术难题攻克 |
30% |
→ 15%(仅限L2/L3层问题) |
|
团队协作 |
30% |
→ 20%(细化为共识构建、情绪支持等) |
|
人机系统效率提升 |
— |
35% |
|
非结构化问题定义 |
— |
35% |
|
跨模态共识构建 |
— |
30% |
注:新模型总权重为100%,部分维度存在重叠(如“问题定义”常驱动“系统效率”)。
关键认知转变:软技能的价值不在于“做得更多”,而在于“定义何为值得做的事”。例如,阻止一个错误方向的开发(避免$500K浪费),比高效完成它(产出$100K功能)更有价值。
2.3 技术硬技能 vs 软技能估值周期对比
|
维度 |
技术硬技能(如React框架精通) |
软技能(如技术方案说服力) |
|
价值半衰期 |
18-24个月(受框架迭代影响) |
60-84个月(场景迁移性强) |
|
AI冲击度 |
高(Copilot可生成70%样板代码) |
低(依赖物理世界常识与情感建模) |
|
绩效归因难度 |
易(Git提交、Jira工单可追踪) |
难(需设计“影响链路”指标) |
|
晋升杠杆系数 |
1.0x(基准) |
2.3x(稀缺性溢价,据微软内部晋升数据分析) |
数据来源:Microsoft Azure Engineering Performance Review Guidelines v3.1 (2025)
三、核心能力解构:三大软技能的量化评估体系
3.1 沟通能力:从技术翻译到共识铸造
2026新定义:在AI生成多种技术方案的场景下,将“技术可能性空间”压缩为“组织可行性决策”的能力。
微软Azure真实案例:微服务拆分争议
2024年,Azure某SaaS产品团队使用Copilot X生成5种微服务拆分方案(从单体到全网格)。但业务方要求快速上线新功能,反对架构重构。CTO三次向董事会汇报失败,PPT充斥“Kubernetes Pod调度”“Istio流量镜像”等术语,被批“技术语言过重,缺乏商业视角”。
解决方案(由Azure工程效能团队介入):
1)认知负荷管理:将12页架构图压缩为“业务影响-时间-风险”三维动态模拟。使用Python + Plotly实现蒙特卡洛仿真,可视化不同架构下的上线时间与故障概率分布。
import plotly.graph_objects as go
import numpy as np
# 蒙特卡洛仿真参数(基于历史数据校准)
architectures = ['Monolith', 'Microservices-v1', 'Hybrid']
mean_time_to_market = [30, 75, 45] # days
failure_risk_std = [5, 20, 10] # standard deviation of failure probability (%)
fig = go.Figure()
for arch, t_mean, r_std in zip(architectures, mean_time_to_market, failure_risk_std):
time_samples = np.random.normal(t_mean, r_std * 1.5, 1000) # time uncertainty
risk_samples = np.abs(np.random.normal(r_std, r_std / 2, 1000)) # risk >=0
fig.add_trace(go.Scatter(
x=time_samples, y=risk_samples,
mode='markers', name=arch, opacity=0.6,
marker=dict(size=4)
))
fig.update_layout(
title="Architecture Trade-off: Time-to-Market vs Failure Risk",
xaxis_title="Time to Market (days)",
yaxis_title="Failure Probability (%)",
legend_title="Architecture Option"
)
fig.write_html("architecture_tradeoff.html") # 可嵌入PPT2)反向叙事框架:将焦点从“AI能做什么”转为“如果不做,6个月后竞争对手会如何”。例如:“竞品已用AI实现秒级弹性扩缩容,若我们维持单体,客户流失率预计上升12%。”
量化成果(来源:Azure内部项目复盘报告):
- 决策周期从14天缩短至3天
- 技术方案采纳率从0%提升至100%
- 该CTO在2025年Q1晋升评审中,因“跨语言共识能力”破格提升两级(跳过一级)
量化评估四象限模型
|
指标 |
定义 |
目标值 |
工具 |
|
信息保真度 |
技术方案复述准确率 & 业务诉求还原度 |
>95% / >90% |
录音转文本 + BERT语义相似度比对 |
|
共识达成效率 |
需求提出→技术方案锁定的会议轮次 |
≤1.5次 |
Teams/Zoom会议日志分析 |
|
决策影响度 |
个人技术观点被最终采纳率 |
>70% |
Jira决策链路追踪(自定义字段) |
|
跨角色翻译质量 |
业务方NPS & 开发理解一致性 |
NPS>50 / 偏差<15% |
匿名调研 + 内部知识测试 |
评估工具建议:推行“技术沟通价值日志”,要求记录每次关键沟通的“输入-输出-影响”三元组。例如:
- 输入:业务方模糊需求“系统要更快”
- 输出:转化为“API P95延迟≤200ms,且不影响现有SLA”
- 影响:避免3周无效优化,节省$80K人力成本
月度使用Azure Cognitive Services分析日志,自动生成“影响链路图”。
3.2 共情协作:从情绪感知到系统韧性构建
2026新定义:在混合智能团队(人类开发者+AI Agent)中,识别“人类动机波动”与“AI能力边界”错位,并通过干预维持系统整体产出的稳健性。
微软Azure真实案例:CodeAgent引发的“能力自卑”
2024年Q2,Azure某团队全面引入CodeAgent(基于GitHub Copilot Enterprise定制)。3个月内,初级工程师PR合并率下降40%,离职意向调研得分上升15个百分点。深度访谈发现普遍心态:“AI生成的代码比我写得好,我的价值是什么?”
解决方案(由Azure People Team与工程效能团队联合设计):
1)贡献归因透明化:在Git提交规范中强制增加三类标签:
feat(auth): add MFA support [HUMAN_DESIGN] # 人类设计核心逻辑
fix(query): optimize join [AI_GENERATED -> HUMAN_OPTIMIZED] # AI生成,人类优化
docs(api): update spec [AI_GENERATED] # 纯AI生成每月自动生成“人类独特价值报告”,展示每位工程师在[HUMAN_DESIGN]和[HUMAN_OPTIMIZED]上的贡献。
2)心理安全感建模:为新人设计“AI无法处理的边缘案例”作为保护性任务。例如:
- 多时区边界测试(AI缺乏真实世界时间感知)
- GDPR合规性校验(涉及法律解释)
- 客户特定异常处理(需领域知识)
这些任务确保95%以上成功率,重建新人价值感。
量化成果(来源:Azure Engineering Health Dashboard):
- 3个月内离职率从15%回落至5%
- 新人晋升至中级工程师周期从18个月缩短至12个月
- 团队整体代码质量(SonarQube Maintainability Rating)从B提升至A(+12%)
量化评估三维模型
|
维度 |
指标 |
计算方式 |
目标 |
|
情绪感知颗粒度 |
团队动机健康度指数 |
Slack消息情感分析 + 月度1:1验证 |
波动<20% |
|
协作干预及时性 |
异常→干预响应时长 |
从Sprint延期信号到干预动作 |
≤2天 |
|
系统韧性提升值 |
人际摩擦导致延期率同比下降 |
对比同期Sprint数据 |
≥30% |
评估工具:部署轻量级情绪感知API。情感熵值(Emotional Entropy)计算公式如下:
其中 为积极/中性/消极情绪词频占比(使用Azure Text Analytics API)。熵值越高,团队情绪越混乱。同时计算动机-绩效弹性系数:
高弹性(>0.8)表明团队在压力下仍能稳定交付。
3.3 创新定义:从问题解决到问题发现
2026新定义:当AI能高效解决定义良好的技术问题(如“优化API响应至200ms内”),人类的核心价值转向发现“未被言说的真问题”(如“该API是否仍符合业务终局”)。
微软Azure真实案例:跳出“优化存量”内卷
2024年,Azure某SaaS团队发现CodeAgent可完成80%功能开发,团队陷入“优化存量”内卷:不断微调已有功能,却无新增长点。技术总监被质疑“思考太多,产出太少”。
解决方案:
1)问题涌现图谱:每月组织“AI能力边界”研讨会。使用Miro白板记录“AI无法/不应做”的问题,例如:
- “客户真正需要的是自动化,还是控制感?”
- “如果AI能完美实现X,你的业务流程会改变吗?”(反事实提问)
形成技术战略输入清单。
2)反事实价值锚定:对每个被放弃的优化需求,计算“若开发后的机会成本”。例如:
- 需求:优化报表导出速度
- 机会成本:3名工程师×2周 = $60K,且延迟新功能上线
建立“不开发的价值”核算表,纳入绩效评估。
量化成果(来源:Azure Product Strategy Review):
- 识别出3个“AI无法定义”的新产品方向(如“AI治理工作台”)
- 其中1个(AI Compliance Auditor)在2025年Q3上线,成为第二增长曲线(ARR $12M)
- 该总监绩效评估中“战略价值”权重从15%提升至45%
量化评估双层模型
问题质量层:
- 结构不良度:使用Cynefin框架分类问题,复杂域/混乱域问题占比 >40%
- 利益相关方覆盖度:需求方、开发者、AI Agent三方诉求一致性评分 >85%(通过问卷)
价值创造层:
- 技术债务避免量:估算因问题重定义避免的重构成本(可追踪Jira中“避免的工单”)
- 影响力产出:创新问题驱动的专利数、顶级会议论文(如SOSP、OSDI)
评估工具:“问题定义有效性看板”。将每个技术问题的“初始定义”与“六月后真实形态”对比,计算“定义漂移率”;
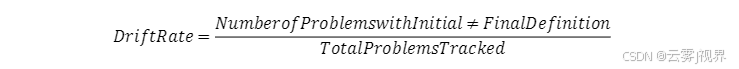
微软内部数据显示:卓越管理者 <10%,普通管理者 >35%。
四、系统化提升路径:从个体到组织
4.1 个体层:诊断-训练-验证闭环
诊断:使用四象限分析法(能力-动机矩阵)
- 高能力低动机型:设计“AI协作小胜利”(如让其主导一次AI方案评审)
- 低能力高动机型:进行“技术沟通沙盒”训练(如向家人解释OAuth 2.0)
训练:
- 每周1次“技术翻译挑战”:将AI生成方案用CEO/PM/Junior Dev语言复述
- 每月1次“共情干预实验”:记录1次动机干预效果
验证:季度360度评估,重点收集“因你而改变的技术决策”案例
4.2 团队层:协作增强回路
- 机制1:“技术辩论仲裁人”轮换制,每人每月担任1次共识促成者,评估“共识质量分”(基于决策速度与后续返工率)
- 机制2:“AI盲区悬赏”:公开悬赏“AI无法处理的问题”,发现者获“问题定义积分”,与奖金挂钩
- 工具:部署轻量级情绪感知工具(如基于Git提交注释的情感分析),但需人工校准避免偏见
4.3 组织层:绩效考核体系重构
SMART目标新范式:
- 旧:优化API延迟至100ms
- 新:通过3次跨部门沟通,将模糊需求转化为AI可执行任务,提升迭代效率30%
考核权重:技术硬技能产出占比从60%降至30%,“人机系统 orchestration 效率”(40%)+“非结构化问题定义”(30%)
晋升答辩:必须提供1个量化案例(如“因软技能避免$200K技术债务”)
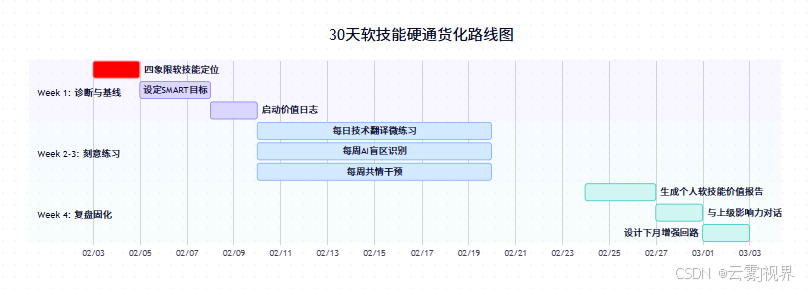
五、30天见效实施路线图
结语:从“编码权威”到“认知架构师”
当AI接管确定性编码,技术管理者的终极使命,是成为人机认知系统的架构师——持续设计接口,让AI的算法效率与人类的认知优势无缝咬合。
2026年的技术领导力,体现在你能否:
- 用沟通压缩不确定性(将技术可能性转化为商业可行性)
- 用共情校准系统偏差(在AI与人类之间建立信任回路)
- 用问题定义开辟AI无法抵达的价值处女地(发现未被言说的真需求)
这不是对技术的背离,而是回归技术服务于人的本质。正如微软CEO Satya Nadella所言:“未来的工程师,不是与机器竞争,而是教会机器如何更好地服务人类。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)