FlashLabs开源Chroma 1.0:实时、高保真语音克隆与对话的端到端模型
标题:FlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning链接:https://arxiv.org/pdf/2601.11141作者单位:FlashLabs发表日期:2026年1月16日开源地址:https://github.com/FlashLabs-A

标题:FlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning
链接:https://arxiv.org/pdf/2601.11141
作者单位:FlashLabs
发表日期:2026年1月16日
开源地址:https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma‘
先一句话概括这篇论文的核心:来自FlashLabs的团队搞出了Chroma 1.0——这是首个开源、实时端到端的语音对话模型,既能实现低延迟交互,又能做到高保真的个性化语音克隆,还兼顾了推理和对话能力。(论文说代码和模型已经放GitHub和HuggingFace上了,但是刚刚看了一眼还没有,得再等等。。。)
01
引言:现有语音对话系统的“痛点”
现在主流的语音对话系统大多是“ASR→LLM→TTS”的级联 pipeline:先把语音转文字,再让大模型处理文字(LLM),最后把文字转语音。但这路子问题不少:
-
延迟高:三步下来,实时对话时会有明显卡顿;
-
误差传递:前一步错了,后面全歪,比如ASR转错字,LLM理解就错了;
-
丢“副语言信息”:像说话人的音色、语速、情绪这些关键信息,转文字时就丢了,没法做个性化交互。
后来也有端到端的语音模型(比如GPT-4o、Spirit LM),能直接处理离散语音表示,不用中间转文字,但要么抓不住副语言信息(比如GLM4-Voice只对齐语义,不管音色),要么能克隆语音却没实时性(比如VALL-E、ElevenLabs),要么实时了却丢了 speaker 控制(比如Moshi)。
所以Chroma 1.0就是来解决这些矛盾的——要实时、要高保真语音克隆、还要强对话能力,三者都要。

02
模型架构:四个核心组件,还有个“神操作”调度
Chroma的架构是把“语音理解”和“语音生成”绑得很死,以此降低延迟,还能保住语音克隆的质量。整体分四个核心部分,还有个关键的token调度策略,咱们一个个说:
2.1 核心组件:各司其职,互相配合
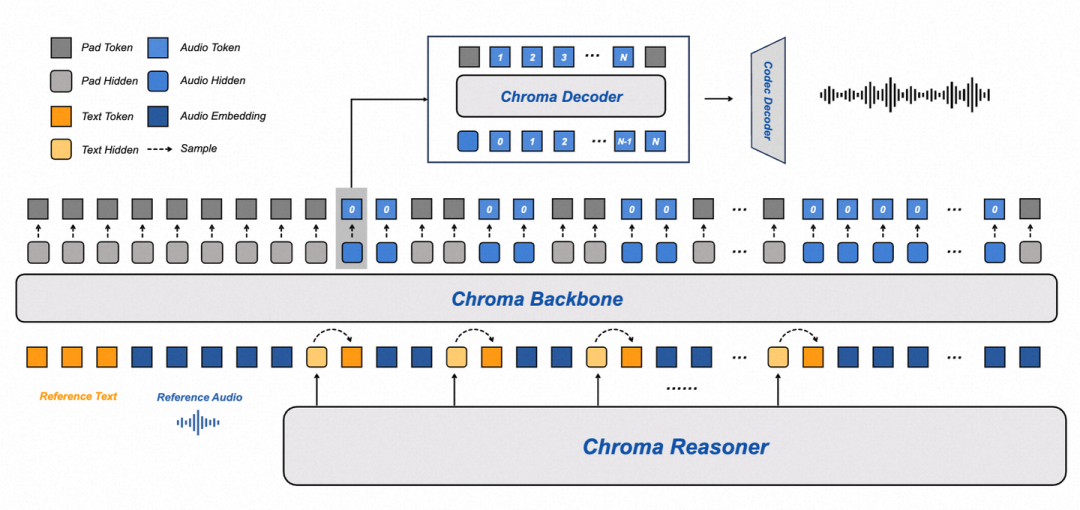
-
Chroma Reasoner(理解模块):基于Qwen2-Audio的编码 pipeline 改的,负责处理文本和音频输入,输出高层语义表示——不只是文字意思,还包含语音的节奏、语调这些副语言信息。它用了个“跨模态注意力”和“时间对齐的多模态旋转位置编码(TM-RoPE)”,确保文字和语音的时间能对上,为后面生成匹配的语音打基础。训练时这部分是冻住的,只当“特征提取器”。
-
Chroma Backbone(声学建模模块):用了1B参数的LLaMA架构变体,核心任务是“照着参考语音的音色生成粗粒度音频码本(c⁰)”。怎么保证音色一致?它会把参考音频和对应的文字转成embedding,加在输入序列前面,相当于“告诉模型:就按这个speaker的声音来”。这里有个关键设计:和Reasoner配合时,用“1:2的文本-音频token交错调度”——1个文本token配2个音频码本token。这样不用等Reasoner把所有文字都生成完,Backbone就能同步生成音频,大大降低延迟。
-
Chroma Decoder(码本细化模块):很轻量,只有100M参数,负责把Backbone生成的粗码本(c⁰)细化成剩下的7个RVQ码本(c¹到c⁷)。它不用看全部历史输入,只需要当前步Backbone的输出,计算量小,进一步降延迟。而且细化过程能补全音色细节,比如说话人的细微语调变化。
-
Chroma Codec Decoder(波形重建模块):最后一步,把所有8个码本(c⁰到c⁷)拼成完整的离散声学表示,再转成连续的语音波形。用了因果CNN(Causal CNN),保证生成时符合时间顺序,支持流式输出。选8个码本是为了平衡质量和效率——少了质量差,多了延迟高。
2.2 训练数据:自己造的“语音对话数据”
公开数据集没有足够好的“高质量语音对话数据”,所以团队自己搞了个 pipeline 生成训练数据:
-
先用类似Reasoner的LLM,根据用户问题生成文字回答;
-
再用TTS把文字回答合成语音,而且让合成语音的音色和参考音频一致;
-
最后用“文字回答+合成语音”当训练对,让Backbone和Decoder学“怎么克隆音色+生成语音”。
03
核心创新点:这四个点是Chroma的“杀手锏”
-
Streaming架构,亚秒级延迟:通过语义状态表示把“语音理解”和“生成”紧耦合,不用等全流程跑完,就能流式输出,端到端延迟低于1秒。
-
高保真语音克隆,几秒钟参考就够:只需要几秒参考音频的embedding,就能让模型学习speaker的音色,最后speaker相似度(SIM)比人类基线还高10.96%。
-
1:2文本-音频token调度:1个文本token配2个音频码本,让音频和文字同步生成,不用等文字全出来再做TTS,大幅降低“首token时间(TTFT)”。
-
4B参数兼顾强能力:模型总共才4B参数,却在理解、推理、口语对话任务上表现能打,不像有的模型要么参数大(比如GLM-4-Voice 9B),要么能力弱(比如0.5B的Mini-Omni)。
04
实验部分:从客观到主观,把性能说透了
实验做得很全面,从语音克隆质量、延迟、到推理对话能力都测了,用的是NVIDIA H200 GPU,训练用了8张卡,跑100K步大概6小时收敛,优化器是AdamW,学习率5e-5,这些基础设置先交代下。
4.1 评估指标:客观+主观,双管齐下
-
客观指标:speaker相似度(SIM,用WavLM-Large算余弦相似度)、首token时间(TTFT,从输入到出第一个音频token的时间)、实时因子(RTF,生成时间/音频时长,小于1就是比实时快);
-
主观指标:比较平均意见分(CMOS),分“自然度(NCMOS)”和“speaker相似度(SCMOS)”,让 evaluator 二选一或者说“差不多”。
4.2 关键实验结果&图表分析
(1)零样本语音克隆的SIM对比——Chroma相似度最高
这个表测的是“给模型几秒参考音频,它生成的语音和原speaker像不像”,结果很明显:
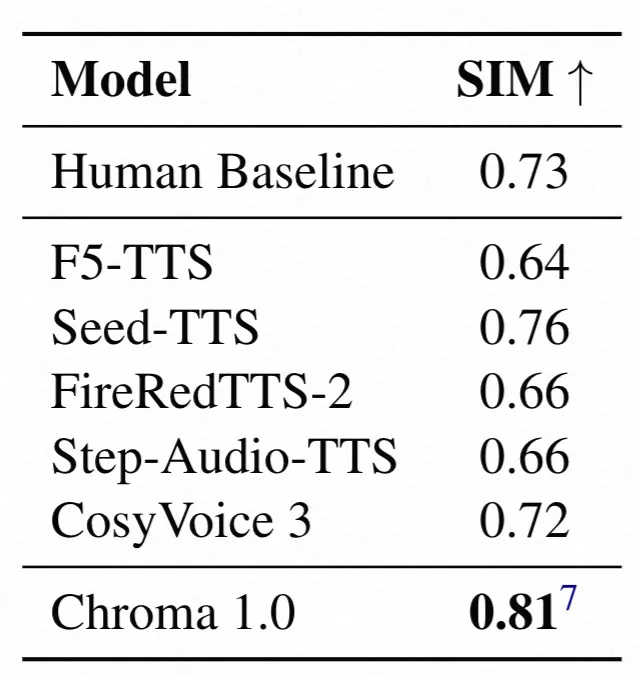
-
人类基线(真人说话的相似度参考)是0.73;
-
其他模型比如F5-TTS 0.64、CosyVoice 3 0.72,就算是Seed-TTS也才0.76;
-
而Chroma直接冲到0.81,相对人类基线提升了10.96%!而且要注意,Chroma用的是24kHz采样率,比其他模型的16kHz更能保音色,这也是它分数高的一个原因。
这说明Chroma抓副语言信息的能力是真的强,能把speaker的音色细节还原得很到位。
(2)和ElevenLabs的主观对比——相似度接近,自然度稍逊
ElevenLabs是商用语音克隆的标杆,所以拿它来比:
-
Table 2:

NCMOS(自然度)上,ElevenLabs 57.2% vs Chroma 24.4%,差距挺大,说明ElevenLabs生成的语音听着更“自然流畅”;但SCMOS(speaker相似度)上,两者几乎打平——ElevenLabs 42.4%,Chroma 40.6%,只差1.8个百分点,说明Chroma的语音克隆能力和商用标杆差不多。
-
Table 3:

更有意思的是,把ElevenLabs和“真实参考音频”比,evaluator 92%更喜欢ElevenLabs!这说明“主观觉得好听”和“是不是真像原speaker”不是一回事——ElevenLabs优化的是“自然度”,甚至比真人还“顺耳”,但Chroma更专注于“还原原speaker的特征”,哪怕这些特征里有自然的小瑕疵(比如轻微卡顿、语速变化),所以相似度反而很能打。
(3)延迟分析——实时性拉满,比实时快2.3倍
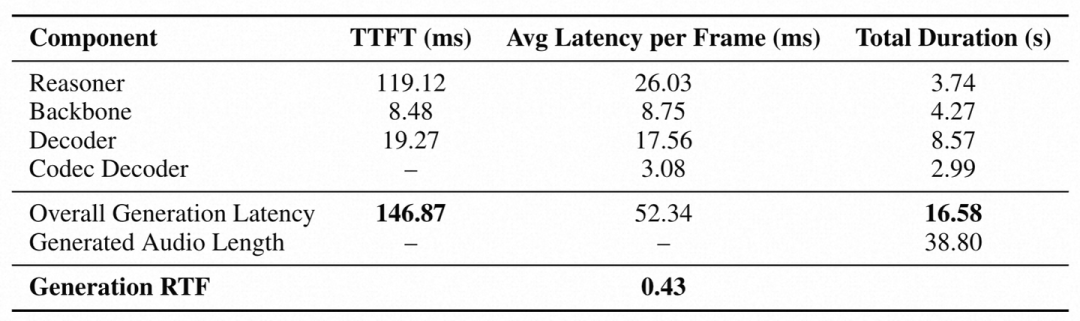
-
整体TTFT(首token时间)是146.87ms,远低于1秒,对话时几乎感觉不到卡顿;
-
RTF是0.43,也就是生成38.8秒的音频,只需要16.58秒,比实时快2.3倍;
-
各组件延迟:Reasoner的TTFT最长(119.12ms,毕竟要处理多模态输入),Backbone很快(8.48ms),Decoder每帧平均17.56ms,Codec Decoder每帧3.08ms,整体配合下来延迟控制得很好。
(4)推理&对话能力——4B参数干翻小模型,接近大模型
这个表测的是模型在“理解(重复、总结、高考题)”、“推理(故事逻辑、事实判断、数学题)”、“口语对话(日常、通用、真实场景)”上的表现,重点看Chroma:
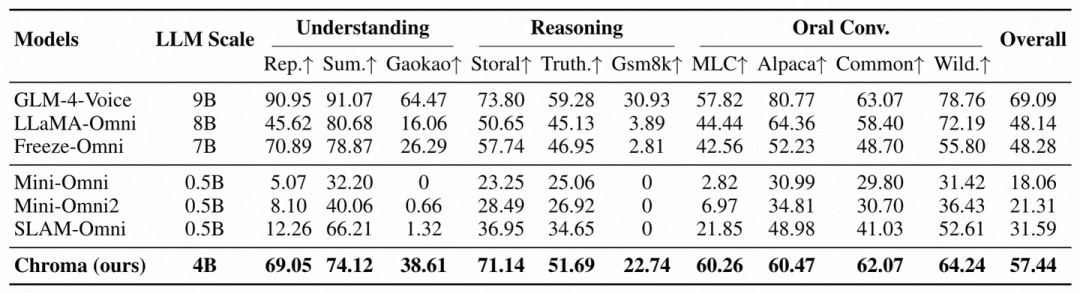
-
参数只有4B,比GLM-4-Voice(9B)小一半多,但推理能力比如Storal(故事逻辑)71.14%,只比GLM-4-Voice的73.80%低一点;事实判断51.69%,也接近GLM-4-Voice的59.28%;
-
口语对话里,MLC(日常对话)60.26%、CommonVoice(通用场景)62.07%,都是不错的分数;
-
最关键的是: 它是这些模型里唯一能做个性化语音克隆的 !其他模型要么只抓对话,要么只抓语音,Chroma是两者都占了,还兼顾了效率(4B参数比7B/9B模型省资源)。
05
结论&未来方向
Chroma 1.0的最大贡献就是:把“实时端到端”“高保真语音克隆”“强推理对话”这三个之前很难兼顾的点捏到了一起,还开源了,能给后续研究当基础。
不过它也有局限:目前只生成英文语音,没加RLHF(人类反馈强化学习)或DPO(直接偏好优化)来提升对话自然度,也没支持多轮对话里更细的控制。未来可以搞多语言生成、加MTP(多码本预测)进一步降延迟,或者试试编码器-解码器架构提升可控性。
另外团队也提了伦理问题——语音克隆容易被用来冒充、造假,所以建议加 consent 验证、合成语音检测、音频水印这些防护措施,确保技术用在正地方。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)