LLM智能体架构设计与评估体系详解:从理论到实践,建议收藏
本文系统阐述了混合智能体架构的三层设计原理(反应式模块、协调层、深思熟虑模块),通过投顾AI助手案例展示了如何平衡效率与智能。详细介绍了LangSmith和DeepEval评估工具的使用方法,构建了"离线测试+线上监控"的完整评估体系,并提出三大方法论:架构适配场景、评估贯穿全生命周期、数据驱动优化,为LLM Agent应用落地提供了实用指导。文章特别强调了混合智能体通过动态模
文章深入解析混合智能体架构三层设计(反应式模块、协调层、深思熟虑模块),通过投顾AI助手案例展示如何平衡效率与智能。系统介绍LangSmith与DeepEval评估工具,构建"离线测试+线上监控"完整评估体系,并提出架构适配场景、评估贯穿全生命周期、数据驱动优化三大方法论,为LLM Agent应用落地提供实用指导。
在大语言模型(LLM)应用落地过程中,智能体(Agent)的“决策效率”与“输出质量”是两大核心痛点。纯反应式智能体响应快但缺乏规划能力,纯深思熟虑式智能体擅长复杂任务但延迟高,而混合智能体架构通过分层设计实现了两者的平衡。同时,缺乏系统化的评估工具会导致Agent效果不可控,LangSmith与DeepEval等框架则构建了全流程评估体系。本文将结合投顾AI助手案例,从架构设计、流程落地到效果评估,拆解Agent能力优化的完整路径。
一、混合智能体架构:平衡效率与智能的核心设计
混合智能体架构(Hybrid Agent Architecture)的核心思想的是融合“反应式架构”的即时性与“深思熟虑架构”的规划性,通过协调机制动态切换工作模式,本质是模拟人类“本能反应+理性思考”的决策逻辑。该架构最早源于机器人学,后被迁移至LLM Agent领域,解决了单一架构在复杂场景中的适配缺陷。
1.1****核心三层设计与技术原理
混合智能体采用模块化分层设计,各层级独立承担功能,通过仲裁系统实现协同,具体架构如下:
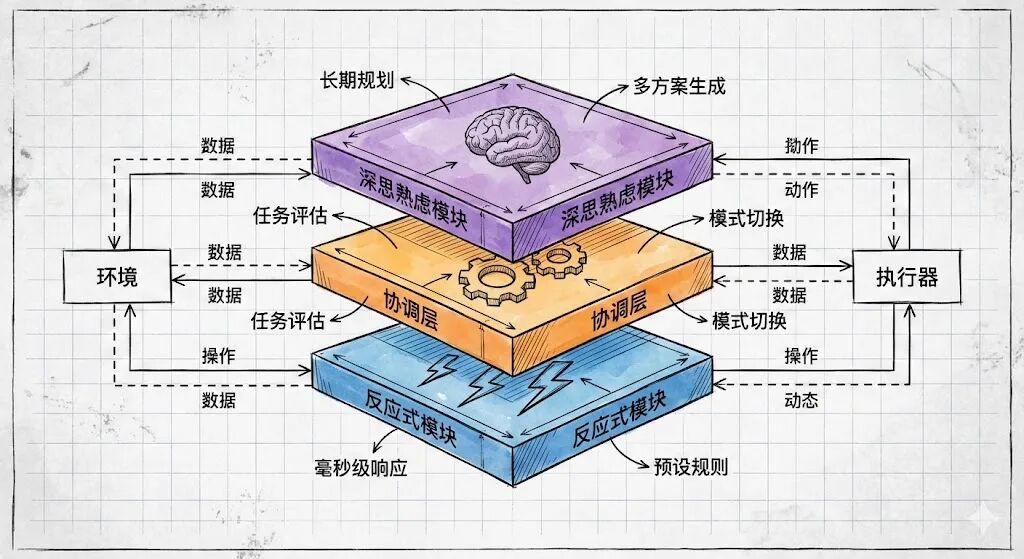
•底层(反应式模块):对应人类“本能反应”,基于预设规则和模式匹配实现即时响应,无需复杂计算。技术上采用“条件-动作”(Condition-Action)规则引擎,支持毫秒级处理简单任务,适用于时效性强、逻辑单一的场景。例如投顾AI中查询上证指数、账户持仓占比等需求,直接调用预设数据接口并返回标准化结果,避免LLM推理带来的延迟。
•中层(协调层):架构的“中枢神经”,核心功能是任务分类、优先级评估与模式调度。通过LLM或规则引擎分析输入特征(如查询复杂度、时效性、资源需求),判定任务类型(紧急型/信息型/分析型),并选择对应处理模式。协调层还需管理系统资源分配,避免深思熟虑模块占用过多资源导致反应式任务阻塞,常用策略包括资源配额、任务队列排序等。
•顶层(深思熟虑模块):对应人类“理性思考”,基于规划器(Planner)和世界模型(World Model)实现复杂任务拆解与多步推理。技术上集成符号规划(如STRIPS算法)、强化学习或多轮LLM推理,能够整合多源数据(用户画像、市场数据、历史记录)构建内部模型,生成多个备选方案并评估最优解。适用于投资组合优化、长期财务规划等需要深度分析的场景。
1.2****运作机制:动态模式切换逻辑
混合智能体通过仲裁系统(如监督器模块)实现模式动态切换,核心逻辑为“优先级判定+资源适配”:当接收到输入后,协调层先提取关键特征,若判定为紧急任务(如实时市场数据查询),则直接激活反应式模块,跳过深思熟虑流程以缩短延迟;若为复杂分析任务(如应对经济衰退的持仓调整),则启动深思熟虑模块,同时暂停低优先级反应式任务;若任务兼具时效性与复杂性(如紧急风险提示+应对建议),则采用“反应式先响应+深思熟虑补全”的混合流程。
二、实操案例:投顾AI助手的混合架构落地
财富管理场景对“响应速度”与“专业深度”的双重需求,使其成为混合智能体的典型应用场景。以下基于PDF案例,拆解投顾AI助手的架构实现、处理流程与状态管理细节。
2.1****场景适配:分层功能落地
投顾AI助手针对不同用户需求,实现三层架构的功能适配,具体分工如下:
| 架构层级 | 核心功能 | 处理场景 | 技术特性 |
| 反应式层 | 基础查询响应、数据快速返回 | 指数表现、账户持仓、投资术语解释 | 预设规则引擎、数据接口直连、低延迟 |
| 协调层 | 查询分类、模式选择、资源调度 | 所有用户输入的前置处理 | LLM评估器、优先级队列、动态资源分配 |
| 深思熟虑层 | 组合优化、风险评估、长期规划 | 经济周期应对、退休规划、子女教育金配置 | 多源数据整合、场景建模、多方案生成 |
2.2****完整处理流程拆解
投顾AI助手的处理流程分为三个阶段,实现从输入到输出的全链路管控:
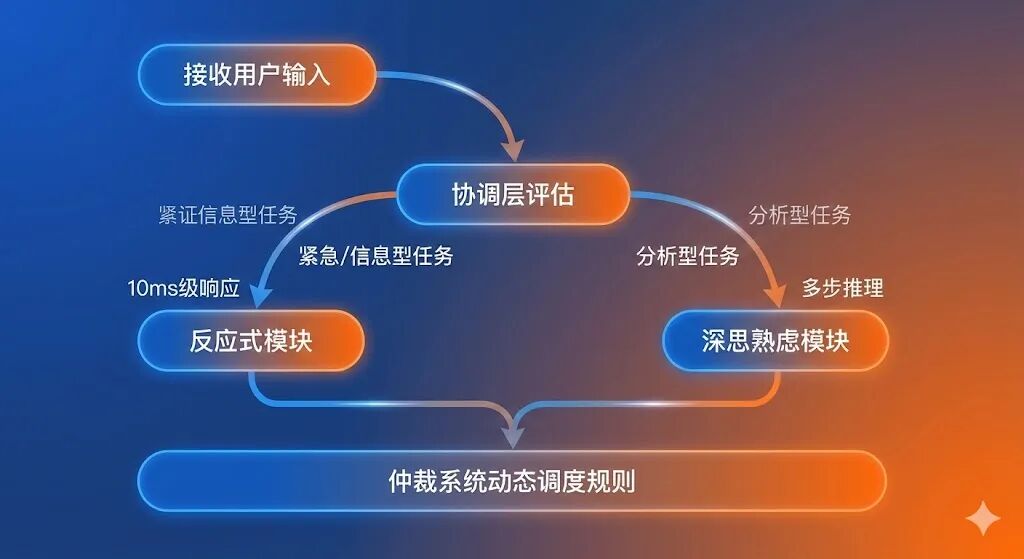
阶段1:查询评估(协调层核心工作)
协调层通过LLM评估用户查询,输出三大核心结果:查询类型(紧急型/信息型/分析型)、处理模式(反应式/深思熟虑)、推理依据。评估维度包括:查询复杂度(是否需要多步分析)、时效性需求(是否需实时数据)、资源消耗(是否需调用多接口)、用户期望(历史交互中对响应速度的偏好)。例如用户询问“今天上证指数表现如何”,评估为紧急型查询,启用反应式模式。
阶段2:分模式处理
•反应式流程:针对简单查询,采用“接口调用+标准化输出”流程。技术上通过预定义的数据映射关系,直接调用证券行情接口(如Tushare、Wind)获取数据,经格式标准化后返回用户,处理耗时通常控制在1-20秒。例如查询ETF定义时,直接返回预设的专业解释+案例,无需LLM推理。
•深思熟虑流程:针对复杂查询,分为三步执行:①数据收集:整合用户画像(风险承受能力、投资期限)、市场数据(行业趋势、利率水平)、历史记录(持仓变化、收益情况);②深度分析:构建市场情景模型(如经济衰退、通胀升温),模拟不同持仓调整方案的收益与风险;③生成建议:基于用户风险偏好筛选最优方案,补充执行步骤与风险提示。例如应对经济衰退的持仓调整建议,需耗时1-2分钟完成全流程。
2.3****状态管理:WealthAdvisorState设计
为确保流程连贯性与可追溯性,投顾AI助手通过WealthAdvisorState(基于Python TypedDict实现)维护全链路状态,涵盖输入、处理、输出三大维度,核心字段设计如下:
| python class WealthAdvisorState(TypedDict): # 输入字段 user_query: str # 原始用户查询 customer_profile: Optional[Dict[str, Any]] # 客户画像(风险偏好、投资目标等) # 处理状态字段 query_type: Optional[Literal[“emergency”, “informational”, “analytical”]] # 查询类型 processing_mode: Optional[Literal[“reactive”, “deliberative”]] # 处理模式 market_data: Optional[Dict[str, Any]] # 调用的市场数据 analysis_results: Optional[Dict[str, Any]] # 深度分析结果 # 输出与控制流字段 final_response: Optional[str] # 最终响应内容 current_phase: Literal[“assess”, “reactive”, “collect_data”, “analyze”, “recommend”, “respond”] # 当前流程节点 error: Optional[str] # 错误信息(异常处理) |
该状态设计的核心价值在于:①支持流程断点续跑,若某环节失败可基于当前状态重试;②便于问题排查,通过状态快照定位延迟或错误节点;③实现个性化适配,基于customer_profile动态调整分析维度。
三、LLM Agent效果评估:LangSmith全流程工具链
Agent效果评估的核心目标是“量化性能、定位问题、持续优化”,LangSmith作为LangChain生态的评估工具,提供了从调试追踪、性能监控到自动化测试的全链路能力,解决了LLM应用“黑盒难评估”的痛点。
3.1 LangSmith****核心功能模块
LangSmith的工具链覆盖Agent生命周期各阶段,四大核心功能如下:
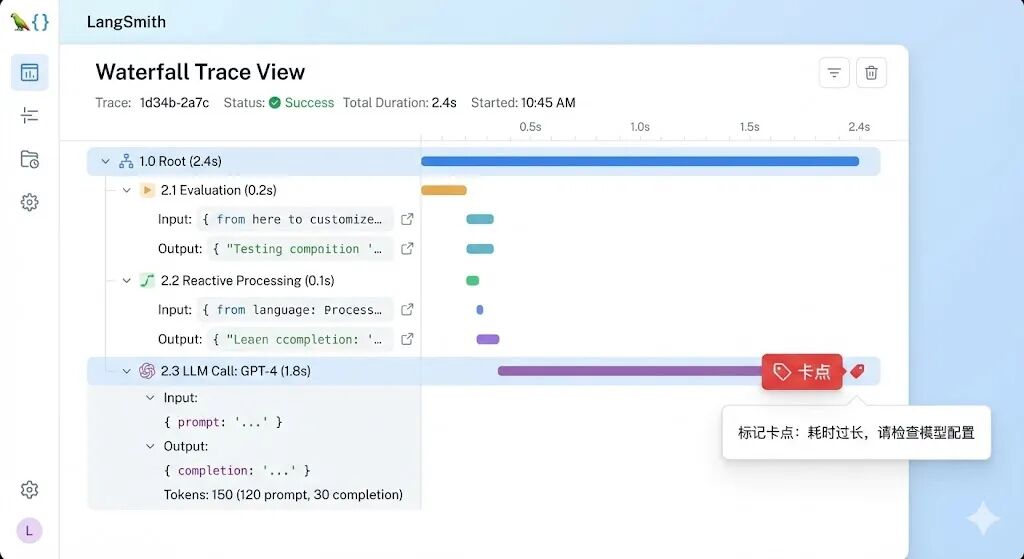
•调试与追踪:实时记录Agent的决策链路,包括LLM调用、工具使用、状态转换、输入输出等细节。支持瀑布式可视化展示各节点耗时,快速定位“卡点”(如LLM推理延迟、工具调用失败)。例如投顾AI的深思熟虑流程中,可通过追踪发现数据收集环节耗时过长,优化接口调用策略。
•性能监控:量化核心指标,包括响应时间、Token消耗、成本(API调用费用)、错误率、成功率等。支持按任务类型(反应式/深思熟虑)、用户群体拆分指标,为资源优化提供数据支撑。例如发现深思熟虑任务Token消耗过高,可通过精简Prompt、优化模型选型降低成本。
•测试与评估:支持创建自定义测试数据集,搭配评估器实现自动化测试。可将线上真实案例(好案例/坏案例)加入数据集,形成“黄金测试集”,用于后续版本的回归测试,确保优化过程中效果不退化。
•数据分析:挖掘用户查询模式(如高频问题、需求分布)、Agent决策规律,为产品优化提供方向。例如发现大量用户询问ESG投资建议,可针对性强化深思熟虑层的ESG维度分析能力。
3.2 LangSmith****实操:从配置到自动化测试
步骤1:环境配置与追踪启用
首先需完成LangSmith的API密钥配置与环境变量设置,实现Agent调用的自动追踪:
| bash # 1. 安装依赖 pip install --pre -U langchain langchain-openai langsmith # 2. 设置环境变量 export LANGSMITH_API_KEY=“你的API密钥” # 从LangSmith控制台获取 export LANGCHAIN_TRACING_V2=true # 启用V2版本追踪 export LANGCHAIN_PROJECT=“wealth-advisor-hybrid-agent” # 项目名称(用于分类追踪记录) export OPENAI_API_KEY=“你的OpenAI密钥” # 关联LLM API密钥 |
在Agent执行函数中添加配置,实现状态与元数据的全量追踪:
| python def run_wealth_advisor(user_query: str, customer_id: str): # 加载客户画像 customer_profile = load_customer_profile(customer_id) # 配置LangSmith追踪元数据 config = { “metadata”: { “risk_tolerance”: customer_profile.get(“risk_tolerance”), “investment_horizon”: customer_profile.get(“investment_horizon”), “user_query”: user_query[:100], “timestamp”: datetime.now().isoformat() }, “run_name”: f"wealth-advisor-{customer_id}-{datetime.now().strftime(‘%Y%m%d%H%M%S’)}" } # 执行Agent并自动追踪 initial_state = {“user_query”: user_query, “customer_profile”: customer_profile} result = agent.invoke(initial_state, config=config) return result |
步骤2:自动化测试体系搭建
LangSmith自动化测试需完成“测试集定义-评估器创建-评估执行”三步流程,确保Agent效果可控。
1.定义测试数据集:按任务类型分类构建测试用例,涵盖反应式、深思熟虑、边界情况(如空查询、模糊查询),每个用例包含输入与期望输出:
| python # 反应式查询测试用例 REACTIVE_TEST_CASES = [ { “inputs”: {“user_query”: “今天上证指数表现如何?”, “customer_id”: “customer1”}, “expected_outputs”: { “processing_mode”: “reactive”, “should_contain”: [“上证指数”, “收盘点位”, “涨幅”, “投资需谨慎”] } } ] # 深思熟虑查询测试用例 DELIBERATIVE_TEST_CASES = [ { “inputs”: {“user_query”: “如何调整投资组合应对经济衰退?”, “customer_id”: “customer1”}, “expected_outputs”: { “processing_mode”: “deliberative”, “should_contain”: [“资产配置”, “防御性行业”, “债券比例”, “现金储备”] } } ] # 边界情况测试用例 EDGE_CASE_TEST_CASES = [ { “inputs”: {“user_query”: “”, “customer_id”: “customer1”}, “expected_outputs”: {“should_handle_error”: True, “error_msg”: “请输入具体查询内容”} } ] # 合并测试用例 ALL_TEST_CASES = REACTIVE_TEST_CASES + DELIBERATIVE_TEST_CASES + EDGE_CASE_TEST_CASES |
1.创建评估器:评估器用于量化Agent输出质量,LangSmith支持内置评估器与自定义评估器,常用两类评估器如下:
•处理模式评估器(自定义):评估Agent是否正确选择处理模式,输出0-1分(1分为正确):
| python from langsmith.evaluation import RunEvaluator, EvaluationResult class ProcessingModeEvaluator(RunEvaluator): def evaluate_run(self, run, example): expected_mode = example.expected_outputs.get(“processing_mode”) actual_mode = run.outputs.get(“processing_mode”) score = 1.0 if expected_mode == actual_mode else 0.0 comment = “处理模式正确” if score == 1.0 else f"处理模式不匹配,期望{expected_mode},实际{actual_mode}" return EvaluationResult(key=“processing_mode”, score=score, comment=comment) |
•响应完整性评估器(自定义):评估输出是否包含期望关键词,得分=命中关键词数/总关键词数:
| python class ResponseCompletenessEvaluator(RunEvaluator): def evaluate_run(self, run, example): expected_keywords = example.expected_outputs.get(“should_contain”, []) actual_response = run.outputs.get(“final_response”, “”).lower() hit_count = sum(1 for keyword in expected_keywords if keyword.lower() in actual_response) score = hit_count / len(expected_keywords) if expected_keywords else 1.0 comment = f"找到{hit_count}/{len(expected_keywords)}个期望关键词" return EvaluationResult(key=“response_completeness”, score=score, comment=comment) |
此外,LangSmith提供内置评估器(如Correctness、Relevance、Harmfulness),可直接调用评估输出的正确性、相关性与安全性。
1.执行评估与结果分析:通过LangSmith的evaluate函数批量执行测试用例,收集评估结果并优化Agent:
| python from langsmith.evaluation import evaluate # 初始化评估器列表 evaluators = [ProcessingModeEvaluator(), ResponseCompletenessEvaluator()] # 执行评估 results = evaluate( test_function=run_wealth_advisor, # Agent执行函数 data=ALL_TEST_CASES, # 测试数据集 evaluators=evaluators, # 评估器 experiment_prefix=“wealth-advisor-v1”, # 实验版本标识 max_concurrency=1 # 并发数 ) # 输出评估结果 for result in results: print(f"测试用例:{result.example.inputs[‘user_query’]}“) print(f"处理模式得分:{result.evaluations[‘processing_mode’].score}”) print(f"完整性得分:{result.evaluations[‘response_completeness’].score}\n") |
3.3 LangSmith与Prompt Ops****的协同
Prompt Ops(提示工程运维)是LLM应用持续优化的核心方法论,通过系统化管理Prompt的版本、测试、监控与优化,确保输出质量的一致性。LangSmith为Prompt Ops提供全流程支撑:
•Prompt****版本管理:通过experiment_prefix、tags等标识不同Prompt版本,在LangSmith控制台按版本过滤运行记录,对比不同版本的性能指标(得分、延迟、成本)。例如标记“prompt-v2”与“prompt-v3”,分析Prompt优化对响应完整性的提升效果。
•Prompt****测试评估:基于黄金测试集,对不同版本Prompt进行批量评估,量化优化效果。例如优化协调层Prompt后,通过测试集验证查询分类准确率是否提升。
•持续优化闭环:通过LangSmith收集线上bad-case(如处理模式错误、输出不完整),补充至测试集,迭代优化Prompt与Agent逻辑,形成“测试-评估-优化”的闭环。
四、开源互补:DeepEval与LangSmith的协同评估体系
DeepEval是一款开源LLM评估框架,专注于离线质量测试,与LangSmith的线上监控能力形成互补,构建“离线质检+线上监控”的完整评估体系。
4.1 DeepEval****核心特性与指标
DeepEval类比传统软件开发中的Pytest/JUnit,为LLM应用提供标准化的离线测试能力,核心特性包括:
•丰富的内置指标:涵盖40+评估指标,覆盖幻觉检测(Hallucination)、忠实度(Faithfulness)、答案相关性(Answer Relevancy)、偏见检测(Bias)等核心维度,可直接调用无需自定义。例如幻觉检测通过交叉验证输入上下文与输出的一致性,识别Agent编造的信息。
•多场景适配:支持RAG、Agent、对话系统等多种LLM应用场景,可针对投顾AI的深思熟虑流程,评估分析结果的忠实度(是否基于输入数据)与建议的合理性。
•CI/CD****集成:可集成至CI/CD流水线,在Agent版本迭代时自动运行测试,若评估指标不达标则阻止合并,确保上线质量。
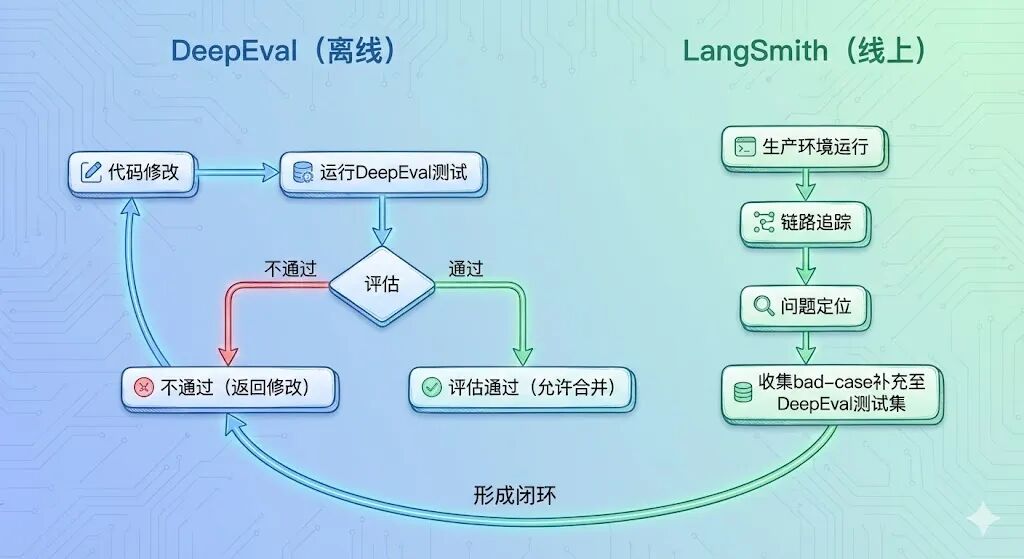
4.2****两大工具的协同逻辑
DeepEval与LangSmith的协同分工明确,形成全生命周期评估闭环:
| 工具 | 类比工具 | 核心场景 | 核心价值 | 协同点 |
| DeepEval | Pytest/JUnit | 离线测试、CI/CD流水线 | 上线前质量把关,避免效果退化 | 接收LangSmith收集的bad-case,扩充测试集 |
| LangSmith | Datadog/Sentry | 线上监控、调试追踪 | 上线后问题定位、性能优化 | 将线上问题反馈至DeepEval,驱动迭代 |
五、总结:Agent能力优化的核心方法论
混合智能体架构通过分层设计解决了“效率与智能”的平衡问题,而LangSmith与DeepEval构建的评估体系则实现了Agent效果的可量化、可优化。结合投顾AI助手案例,Agent能力优化的核心方法论可总结为三点:
1.架构适配场景:根据任务特性设计混合架构,简单任务用反应式模块保障效率,复杂任务用深思熟虑模块保障深度,协调层实现动态调度。
2.评估贯穿全生命周期:离线用DeepEval构建质量门禁,线上用LangSmith监控性能与问题,形成“离线测试-线上监控-迭代优化”的闭环。
3.数据驱动优化:通过LangSmith挖掘用户需求与Agent缺陷,补充至测试集,结合Prompt Ops持续优化Prompt与模型逻辑,提升Agent的适配能力与输出质量。
随着LLM技术的发展,Agent的架构设计与评估体系将持续迭代,但“场景适配”与“数据驱动”的核心逻辑将始终是落地的关键。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献717条内容
已为社区贡献717条内容

所有评论(0)