DeepSeek-R1技术革命:从开源突破到推理优化,大模型开发者的进阶之路
DeepSeek-R1发布一周年之际,其开源项目FlashMLA更新中多次提及"MODEL1",暗示新一代R2模型即将推出。R1通过降低技术、采用和心理三重壁垒,将高级推理能力转化为可复用工程资产,采用推理优先训练目标聚焦数学与逻辑推导,形成稳定推理结构。它重新定义了"对齐"概念,拓展了开源模型的想象空间,改变了人机协作方式。尽管推理能力仍有提升空间,但De
DeepSeek-R1发布一周年之际,其开源项目FlashMLA更新暗示MODEL1(可能是R2)即将推出。R1通过降低技术、采用和心理三重壁垒,将高级推理能力转变为可复用工程资产,采用推理优先训练目标聚焦数学与逻辑推导,形成稳定推理结构。它改变了人们对"对齐"的理解、开源模型的想象空间及人机协作方式,但推理能力仍有提升空间,故事仍在继续。
2025年1月20日,DeepSeek-R1正式发布。从此,国产大模型第一次走到了全球舞台的核心位置,开启了开源时代。
而就在今天深夜,开发者社区沸腾了:DeepSeek的一个存储库进行更新,引用了一个全新的「model 1」模型。
DeepSeek-R1一年了,但DeepSeek-R2还没来。
而这个被爆出的MODEL1,极有可能就是R2!
在DeepSeek的开源项目FlashMLA库代码片段明确引用了「MODEL1」,并且伴随针对KV缓存的新优化,和576B步幅的稀疏FP8解码支持。
FlashMLA是DeepSeek的优化注意力内核库,为DeepSeek-V3和DeepSeek-V3.2-Exp模型提供支持。

项目里,大约有28处提到model 1。
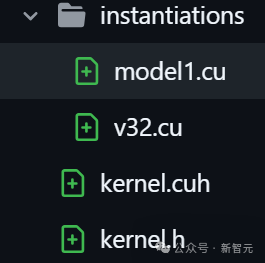
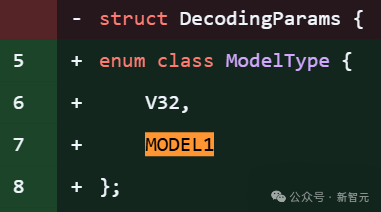
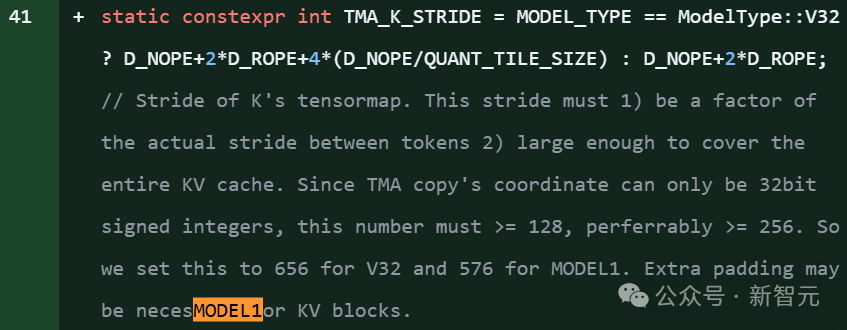





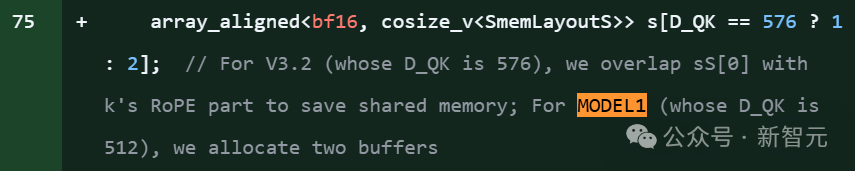

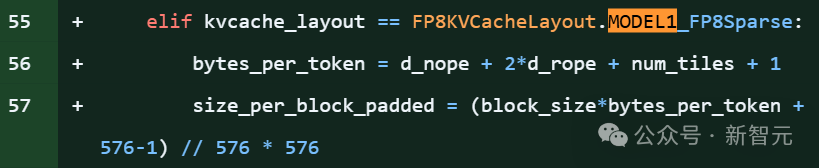
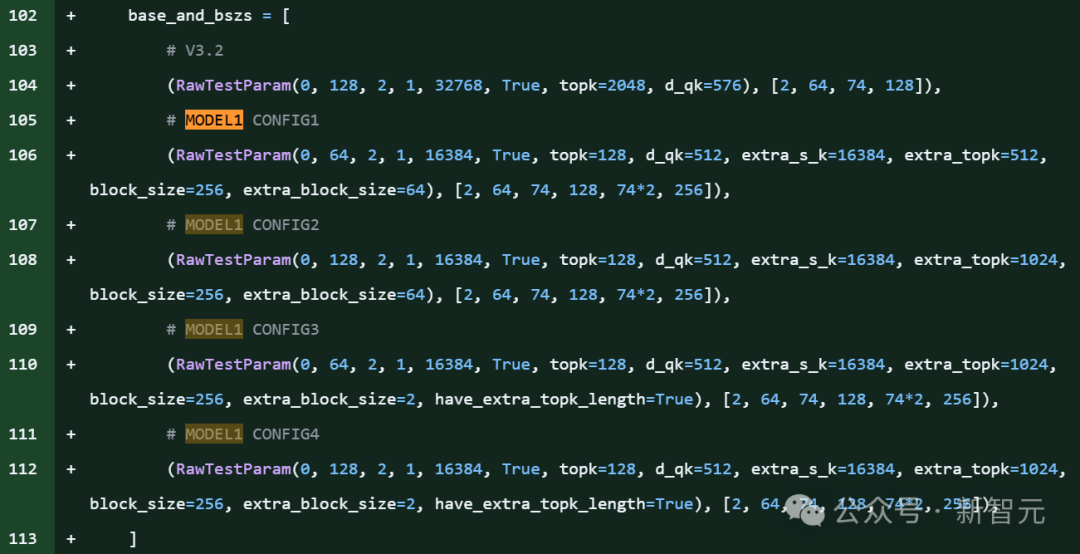
上下滑动查看
这可以被解读为新模型即将发布的明确信号。
巧的是,这个爆料正好赶在DeepSeek-R1发布一周年(2025年1月20日)。
R1作为开源推理模型,曾匹敌OpenAI o1并登顶iOS App Store,此后彻底改变了开源AI社区。
MODEL1即便不是R2,也意义非凡,毕竟FlashMLA是DeepSeek优化的注意力核心算法库。
FlashMLA是DeepSeek为Hopper架构GPU(如H800)优化的MLA(Multi-head Latent Attention)解码内核。
在推理层代码中提及新模型ID,往往意味着该新模型(代号为Model1)将继续复用或改进现有的MLA架构。
这表明 DeepSeek 团队正紧锣密鼓地推进新模型的推理适配工作,FlashMLA 作为其核心推理优化的地位依然稳固。
过去,DeepSeek的确遇到了一些麻烦。
本月15日,国外媒体报道,去年在研发其新一代旗舰模型时,DeepSeek在算力上碰到了一点麻烦。但DeepSeek及时调整了策略,取得了进展,并正准备在「未来几周内」推出这款新模型。

HuggingFace:
DeepSeek如何改变开源AI
HuggingFace在DeepSeek R1发布一周年之际,发文解释了DeepSeek如何改变了开源AI。
R1并不是当时最强的模型,真正意义而在于它如何降低了三重壁垒。
首先是技术壁垒。
通过公开分享其推理路径和后训练方法,R1将曾经封闭在API背后的高级推理能力,转变为可下载、可蒸馏、可微调的工程资产。
许多团队不再需要从头训练大模型就能获得强大的推理能力。推理开始表现得像一个可复用的模块,在不同的系统中反复应用。这也推动行业重新思考模型能力与计算成本之间的关系,这种转变在中国这样算力受限的环境中尤为有意义。
其次是采用壁垒。
R1以MIT许可证发布,使其使用、修改和再分发变得简单直接。原本依赖闭源模型的公司开始直接将R1投入生产。蒸馏、二次训练和领域适应变成了常规的工程工作,而非特殊项目。
随着分发限制的解除,模型迅速扩散到云平台和工具链中,社区讨论的重点也从「哪个模型分数更高」转向了「如何部署它、降低成本并将其集成到实际系统中」。
久而久之,R1超越了研究产物的范畴,成为了可复用的工程基础。
第三个变化是心理层面的。
当问题从「我们能做这个吗?」转变为「我们如何做好这个?」时,许多公司的决策都发生了变化。
对中国AI社区而言,这也是一个难得的、获得全球持续关注的时刻,对于一个长期被视为跟随者的生态系统来说,这一点至关重要。
这三个壁垒的降低共同意味着,生态系统开始获得了自我复制的能力。

DeepSeek-R1一周年
今天,让我们回到原点,回顾DeepSeek-R1诞生的一年。
在R1之前,大模型的进化方向几乎只有一个,更大的参数规模、更多的数据……
但是,模型真的在思考吗?
这个问题,就是DeepSeek-R1的起点。
它不是让让模型回答得更快,而是刻意让它**慢下来,**慢在推理链条的展开,慢在中间状态的显式表达。
从技术上看,DeepSeek-R1的关键突破,并不在某一个单点技巧,而在一整套系统性设计。

推理优先的训练目标
在传统SFT/RLHF体系中,最终答案的「正确性」是唯一目标。R1 则引入了更细粒度的信号。这也是第一次,模型
高密度推理数据,而非高密度知识
R1的训练数据,不追求百科全书式的覆盖,而是高度聚焦在数学与逻辑推导、可验证的复杂任务。
总之,答案不重要,过程才重要。因此,R1才在数学、代码、复杂推理上,呈现出「跨尺度跃迁」。
推理过程的**「内化」,而不是复读****模板**
一个常见误解是:R1只是「更会写CoT」。
但真正的变化在于:模型并不是在复读训练中见过的推理模板,而是在内部形成了稳定的推理状态转移结构。
从此,推理不再是外挂,而是内生能力。
一年之后:R1改变了什么?
首先,它改变了对「对齐」的理解。
R1之后,我们开始意识到,对齐不仅是价值对齐,也是认知过程的对齐。
第二,它改变了我们对开源模型的想象空间。
R1证明:在推理维度,开源模型不是追随者,而可以成为范式定义者。这极大激活了社区对「Reasoning LLM」的探索热情。
第三,它改变了工程师与模型的协作方式。
当模型开始「展示思路」,人类就不再是提问者,而是合作者。
回到今天:R1仍然是一条未走完的路。
一周年,并不是终点。
我们仍然清楚地知道:推理能力还有明显上限,长链路思考仍然昂贵
但正如一年前做出 R1 的那个选择一样——真正重要的,不是已经解决了什么,而是方向是否正确。
DeepSeek-R1的故事,还在继续。
而这一年,只是序章。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献732条内容
已为社区贡献732条内容

所有评论(0)