RAG基础概念:一篇带你入门,看这一篇就够了
大语言模型存在幻觉、信息过时、专业不足和推理薄弱等问题。RAG(检索增强生成)技术通过构建"专属智能图书馆"来解决这些问题。其工作流程分为离线准备(数据切分和向量化建库)和在线问答(检索相似资料并生成答案)两个阶段。RAG让AI在回答前先检索相关最新或专属资料,确保答案准确有依据,避免胡编乱造。该技术可应用于需要时效性、专业性或私密性的场景,显著提升AI回答质量。
一、RAG引入
1.大语言模型(LLMS)的缺点以及对应样例
幻觉问题:凭空捏造数据
当你问 “2026 年诺贝尔物理学奖得主是谁?”,而这个信息还未公布时,LLM 可能会编造一个不存在的人名和研究成果来回答你或者说不清楚。
另一个例子是,你问 “《三体》中章北海的出生日期是哪天?”,原著里根本没有这个信息,但 LLM 可能会给出一个具体的日期。
信息过时:训练的数据过时
如果你问 “现在的中国首富是谁?”,LLM 的训练数据截止到 2024 年,它可能会告诉你是钟睒睒,但如果 2025 年首富已经换人,它就会给出过时的信息。
再比如,你问 “最新的 iPhone 型号是什么?”,如果 LLM 的知识库没有更新到 2025 年,它可能还停留在 iPhone 16。
专业知识不足:私密数据不会加入训练
当你咨询 “晚期肺癌的最新靶向药有哪些?” 时,LLM 可能会给出一些常见药名,但无法提供 2025 年刚获批的新药,也无法像专业医生那样结合基因检测结果给出精准建议。
如果你问 “某个最新的财务会计准则变更对我们公司的具体影响”,LLM 可能只能泛泛而谈,无法像专业会计师那样结合你的公司业务和财报数据进行分析。
推理能力薄弱:逻辑能力薄弱
面对复杂的数学题,比如 “有一个蓄水池,单开甲管 10 小时注满,单开乙管 15 小时注满。如果两管同时开,中途甲管关闭,结果一共用了 9 小时注满。问甲管开了几小时?”,LLM 很可能会算错。
在一些需要多步逻辑推理的案件分析或编程调试中,LLM 也常常会在关键步骤上出错。
2.什么是 RAG?
RAG 是Retrieval-Augmented Generation的缩写,中文叫检索增强生成,是目前 AI 领域超实用的技术,核心作用就是让 AI 回答更准确、更贴合最新信息、更符合你的专属需求,还能减少 AI “胡说八道”。
你可以把它理解成:给 AI 配了一个 **“专属智能图书馆 + 快速检索员”,AI 回答问题前,不会只靠自己脑子里原本的 “旧知识” 瞎猜,而是先去这个图书馆里翻找和问题相关的精准、最新、专属 ** 资料,再结合这些资料组织语言给出答案 —— 全程像学霸答题,先翻书找依据,再写答案,而不是凭记忆硬答。
同样的也可以把自己的一些私密的数据建一个图书馆方便AI检索,保证了数据的私密性,安全性。
RAG 的出现,就是把大语言模型(LLMS)的缺点全解决了:让 AI 能答最新信息、能答专属信息、答的内容有依据。
对于新手来说,不用纠结复杂的技术原理,核心先搞懂它解决什么问题、怎么工作、有啥用、常见怎么用这 4 点就够了,下面全程用大白话讲,无专业术语堆砌。
3.RAG的简单流程
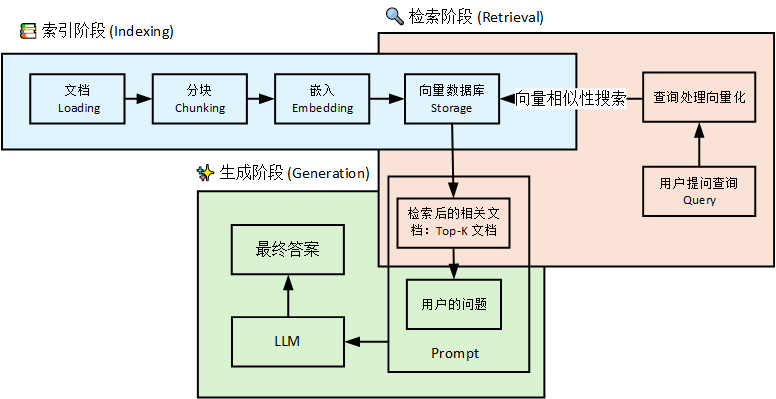
RAG 的工作过程分离线准备和在线问答两步,核心就 3 个关键动作:建库→检索→生成,全程像你查资料写答案的过程,对应下来特别好理解:
第一步:离线准备 —— 给 AI 建 “专属图书馆”(建库 / 向量化)
这一步是提前做的,相当于把你想要 AI 掌握的资料(比如你的小说手稿、行业资料、最新资讯)整理成 AI 能看懂的 “图书馆”,分 2 个小步骤:
-
切分资料:把长文档切成一个个短片段(比如把 1 万字的小说大纲切成每段 200 字的小片段),因为 AI 一次看不了太长的内容,切短后方便快速查找;
-
向量化转码:AI 看不懂文字本身,会通过嵌入模型(Embedding)把每个文字片段转换成一串数字(叫向量),就像给每本书贴一个 “专属条形码”,这个条形码能代表文字的核心含义(比如 “修仙小说金丹期修炼方法” 和 “金丹期突破技巧” 的条形码会很相似,方便 AI 关联查找)。最后把这些带 “条形码” 的文字片段存起来,就是 AI 的 “专属图书馆”(叫向量数据库)。
作者有话说:
关于建专属图书馆后是否需要必须向量化,这个我只能说都可以,建库可以选择数据库量化后检索,也可以选择全文关键字检索,也可以选择两者进行结合。
第二步:在线问答 ——AI 查资料答问题(检索 + 生成)
这一步是你实际问问题时,AI 实时做的,分 2 个小步骤:
-
检索资料:你提出问题后,AI 先把你的问题也转换成向量(贴条形码),然后去向量数据库里快速找和问题条形码最相似的文字片段(比如你问 “我的小说里金丹期怎么突破”,AI 就会找到你存的小说手稿里关于金丹期突破的片段),这个过程就是检索,只会找和问题相关的资料,无关的一概不看;
-
生成答案:AI 把检索到的相关资料片段,和你的问题一起交给大模型,让大模型基于这些资料组织语言回答问题,同时会标注答案的来源(比如 “来自你的小说手稿第 3 章”),保证答案有依据。
总结核心流程:你给资料→AI 建向量库(贴条形码)→你问问题→AI 检索相似资料→AI 结合资料写答案。
全程没有复杂操作,核心就是让 AI“先查资料,再答问题”。
问答有出处,避免胡编乱造。
RAG 的三个核心阶段图解:
二、索引阶段(如何构建知识库)
三、检索阶段(用户问答流程)
稍后补充
四、代码实战
稍后补充

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)