收藏必备!大模型预训练数据选择6大高效策略,从入门到精通,性能提升50%+!
本文系统综述了大语言模型预训练数据选择的前沿方法,包括模型影响力驱动、质量与多样性平衡、多策略集成、结构化知识评估、任务相关性匹配及后训练数据选择等创新策略。这些方法通过优化数据选择,显著提升训练效率,减少计算成本,同时增强模型性能与泛化能力,为高效大模型训练提供实用指导。
预训练的数据选择
模型影响力驱动(Influence / Importance-based Selection)
MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models
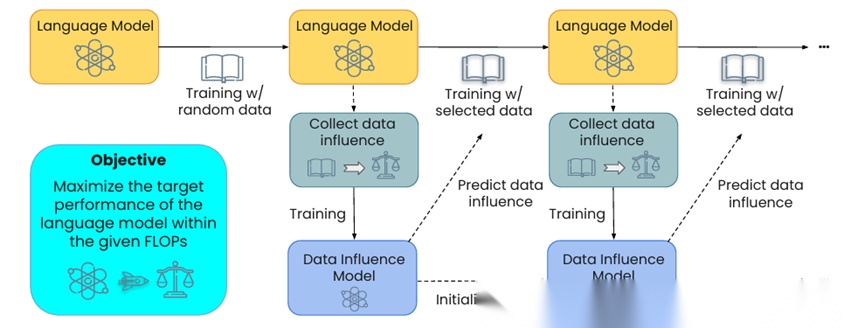
MATES 提出一种动态、模型感知的数据选择策略。与传统静态过滤方法不同,MATES 认为模型在训练不同阶段对各种类型数据的“偏好”实际是不断变化的,因此数据选择策略也应随训练进展动态调整。
其核心是构建一个“数据影响力模型”。具体流程是:在训练过程中定期对模型进行少量探测(probe),测量不同数据对模型性能的实际影响,并将这些影响作为标签,训练一个轻量模型预测大规模语料中每条数据的潜在影响力。然后在下一阶段预训练中,优先选择预测影响力高的数据。
实验覆盖多个规模的语言模型。结果表明,相比随机采样或静态规则数据过滤,MATES 在多个任务上的平均性能提升显著,同时达到相同性能所需要的计算量大约减少一半。该方法证明:动态、模型状态驱动的数据选择优于固定、一次性的规则,是未来预训练数据管理的方向。
质量 + 多样性平衡(Quality–Diversity Joint Methods)
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
这篇论文关注一个经典但常被忽视的问题:只根据“重要性”(如影响力或质量)挑选数据,很容易导致所选数据在语言风格、知识类型、语义分布上高度集中,最终损害模型的泛化能力。作者提出 Quad 方法,通过在数据选择中同时优化重要性与多样性来解决这一问题。
Quad 首先通过高效的反向 Hessian 计算方法,为每条数据估计其对模型的影响力。然后将整个语料按语义表示聚类成多个簇,每个簇被视为多臂赌博机问题中的一个“臂”。在选择训练数据时,算法不仅根据影响力选取强数据,也刻意探索那些被选得较少、但有潜在价值的簇,以保证整体的多样性。
实验表明,Quad 在多个基准任务上超过其他数据选择方法,并显著提升模型的零样本能力。这项工作展示多样性在预训练数据选择中与质量同等重要,提出了一个可扩展且实际可用的解决方案。
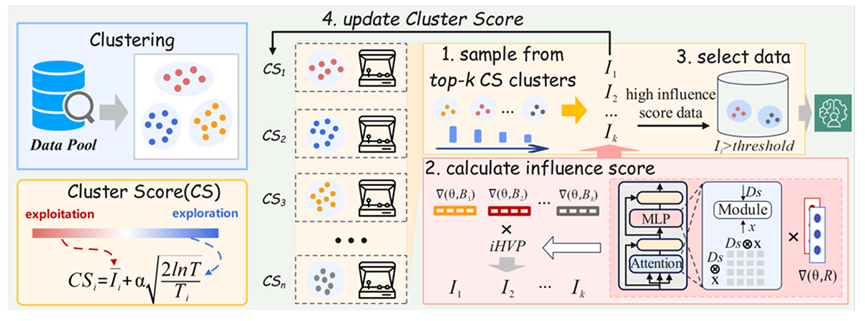
QuaDMix: Quality–Diversity Balanced Data Selection for Efficient LLM Pretraining
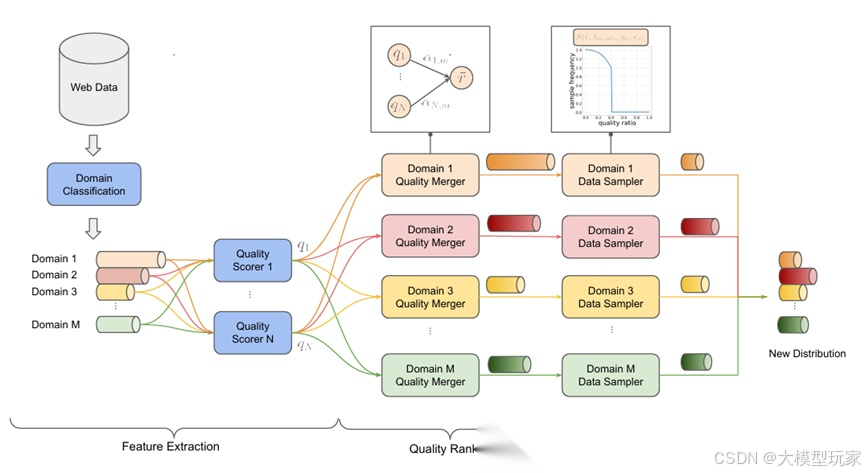
QuaDMix 指出:预训练数据选择中的“质量”和“多样性”往往被分开处理,实际容易带来不平衡,例如高质量数据过于集中于少数领域。为此,QuaDMix 构建一个统一的框架,将这两个因素纳入一个参数化的采样分布中。
方法首先为数据计算多个质量指标,例如语言流畅性、复杂度、干净度等;同时通过领域分类确定其所属领域。然后构建一个依赖“质量向量 + 领域标签”的采样函数,对每条数据分配采样概率。该函数的参数通过轻量实验优化,最终用于完整预训练过程。
结果显示,与只优化质量或多样性的单一策略不同,QuaDMix 的联合策略在多个任务上平均提升超过 7%。该工作证明,平衡质量与多样性的统一框架是更高效的数据选择方式。
Learning from the Best, Differently: A Diversity-Driven Rethinking on Data Selection

这篇论文对数据选择的传统思路 — “根据评分排序,然后取 top-k (最高分数据)” — 发起挑战。作者认为,这种方法的问题在于:评分通常混合了多个相关的维度 (例如语言质量、知识含量、语义复杂度等),这样 top-scored 数据虽然在整体评分上很高,但可能在多个维度上都过于集中,导致数据多样性严重欠缺。更糟糕的是,这种缺乏多样性的选择有时反而使下游性能下降。
为了解决这一问题,他们提出 ODiS (Orthogonal Diversity-Aware Selection)。首先,对数据进行多维评价,至少包括语言质量 (language quality)、知识/事实质量 (knowledge quality)、语义 / 理解难度 (comprehension difficulty) 等多个维度。然后通过PCA将这些维度 “正交” 化 —— 即将不同维度间的相关性移除,使得不同方面真正成为彼此独立的特征维度。对每个正交维度,训练一个打分器,将该维度上的得分 (PCA 投影得分) 回归到数据上,以便于大规模语料上快速打分。最终构造训练集时,不是只从总体评分最高的数据抽,而是从每个正交维度分别选取 top-scored 的数据 (或按比例抽样),从而保证训练集既覆盖多个维度,又保持多样性 (因为不同维度上 top-scored 的数据往往彼此不同)。 实验证明,用 ODiS 选择的数 据训练出的模型,在多个下游任务上显著优于使用传统 基于打分单一指标的 baseline。作者报告,当维度之间的重叠被有效避免(inter-dimension overlap < 2%)时,模型表现更稳定、更优秀。 这篇论文的贡献在于:挑战“高分 = 好训练数据”的直觉,并展示了为什么为了更好泛化,我们需要在数据选择中更细粒度地分解质量指标,并主动保证多样性,而不是简单地选总分最高的数据。
多策略集成驱动(Collaborative / Ensemble Methods)
Efficient Pretraining Data Selection via Multi-Actor Collaboration
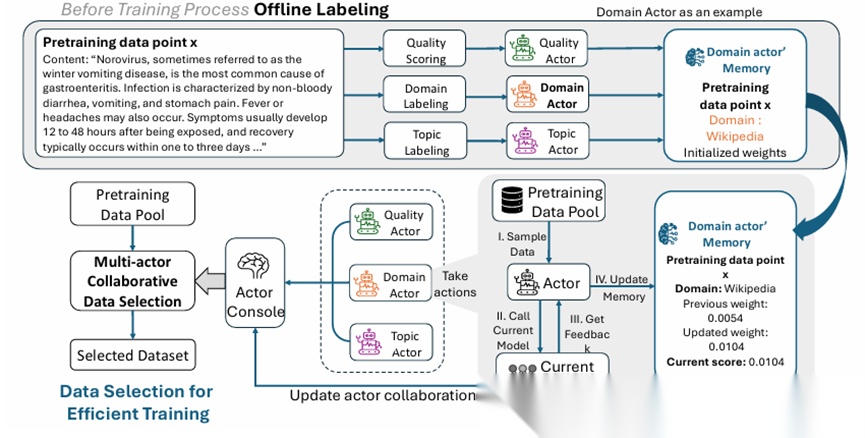
既然已有许多先进的数据选择方法 (quality-based / influence-based / diversity-aware / domain-mixing 等),那么是否可以将它们组合起來,以发挥各自优势,同时避开它们之间潜在的冲突?
作者提出一个multi-actor协同的数据选择机制。将不同的数据选择方法看作独立的 “actor”。例如,一个 actor 可能专注于质量 (quality filtering),另一个 actor 专注于多样性 (diversity),还有 actor 可能关注数据对模型影响 (influence)、domain 混合 (domain mixing) 等。在 pretraining 的不同阶段,这些 actor 根据当前模型状态各自更新其优先级规则 (i.e. 根据当前模型表现调整对不同数据的偏好)。一个控制台负责动态调整各个 actor 的权重 (即决定当前由哪些 actor 主导数据选择),从而将多个信号整合起來。
结果表明,与单一方法或静态组合相比,这种 multi-actor 协同机制能 显著加速预训练收敛,并在数据效率上大幅提升。这篇论文展示了一条更加灵活、综合的数据选择路线:不必拘泥于单一策略,而是把多个策略当作专家协同,让系统自身根据模型状态动态选择最合适的方法。
结构化知识/技能驱动(Skill- or Structure-aware Selection)
MASS: Mathematical Data Selection via Skill Graphs
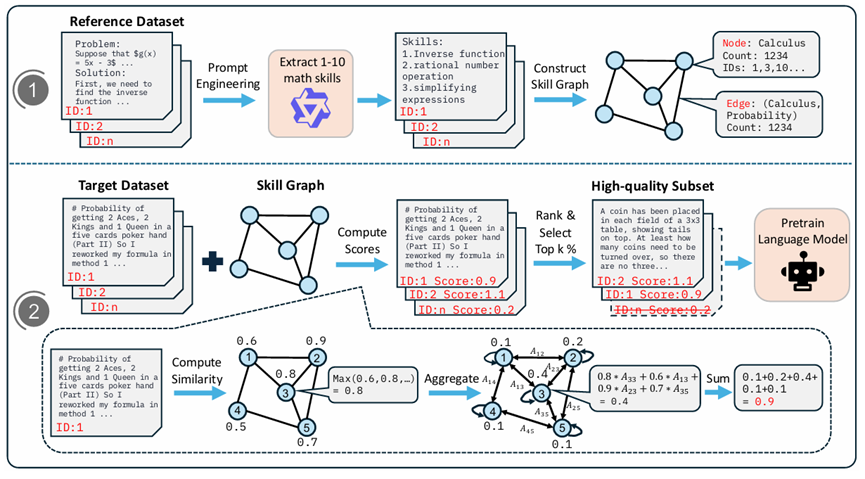
MASS 专注于数学与推理相关数据的预训练数据选择。作者认为,数学语料具有独特的结构与技能依赖,通用的数据过滤方式往往无法有效捕捉这些特性。因此,MASS 提出通过“技能图谱”(skill graph)来建模数学能力之间的关系,并利用其评估训练数据的价值。
方法首先从高质量数学语料中抽取核心数学技能,例如代数、几何、微积分、证明推理等,并构建其图结构。每个节点代表一种技能,边表示技能之间的依赖。然后,针对候选数学语料,系统分析其涉及的技能组合,并将其映射到技能图中,根据覆盖技能的数量、深度和重要性生成质量分数。最后,根据该分数对数据排序,选出最能提升模型数学能力的数据子集。
实验显示,使用 MASS 数据的模型在数学推理任务中表现显著优于使用原始数据的模型,并且在大幅减少 token 数量(通常减少 50%–70%)的情况下,性能仍可提升约 4%–6%。这说明面向特定领域构建结构化技能图,并据此选择训练数据,是提升模型专业能力的一种极为有效的方法。
任务相关性驱动(Task-aware Data Selection)
Language Models Improve When Pretraining Data Matches Target Tasks
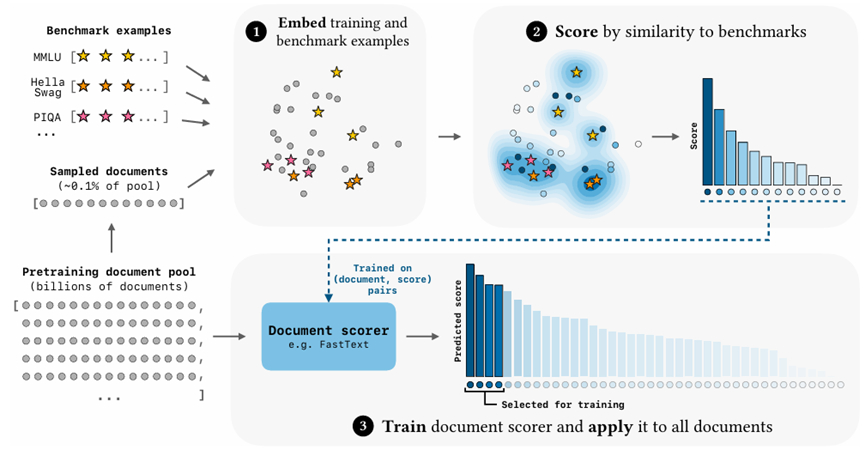
这篇论文系统研究了一个关键问题:预训练语言模型时,如果训练数据的分布与目标任务更为一致,模型性能是否会显著提升。作者提出了一种简单而高效的数据选择方法 BETR(Benchmark-Targeted Ranking)。它的基本思想是:将目标任务的样本与预训练语料的一个子集映射到同一向量空间中,计算相似度排序,再用轻量分类器把这种排序推广到整个大规模语料库。如此就能提取出最符合目标任务分布的预训练数据。
作者训练了数百个模型,并拟合了不同数据规模下的 scaling law。结果显示,BETR 选择的数据可带来约 2 倍以上的计算效率提升,模型性能也显著超过使用原始数据或者简单过滤后的数据。特别重要的是,即使目标 benchmark 与下游评测任务并不重叠,在存在分布偏移的情况下,BETR 依然能取得与默认数据相当甚至更好的表现。
文章得出了一个明确结论:预训练数据的分布与任务需求的匹配程度比数据量更重要。通过一种可扩展的轻量方法对预训练语料进行任务相关性排序,可以在不提高计算成本的情况下获得更高质量的模型。
后训练的数据选择
在线和离线数据选择结合
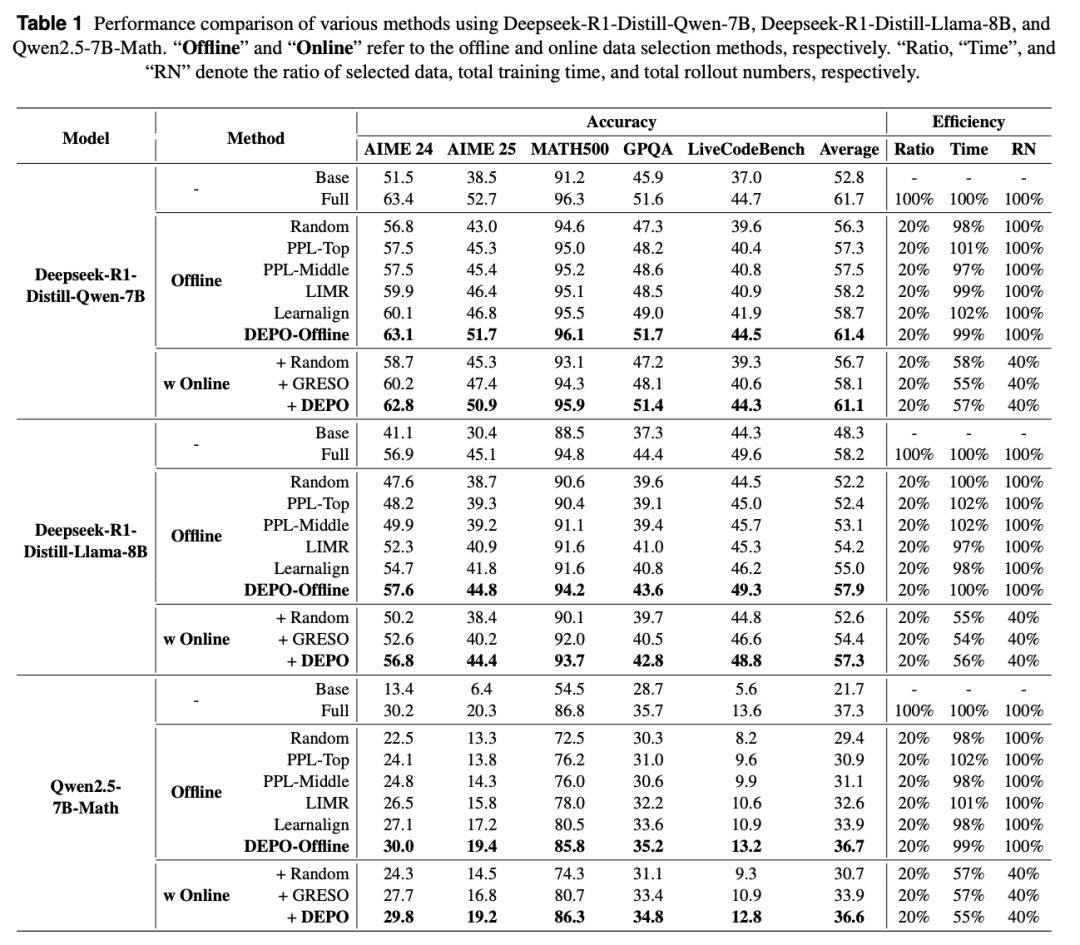
Towards High Data Efficiency in Reinforcement Learning with Verifiable Reward
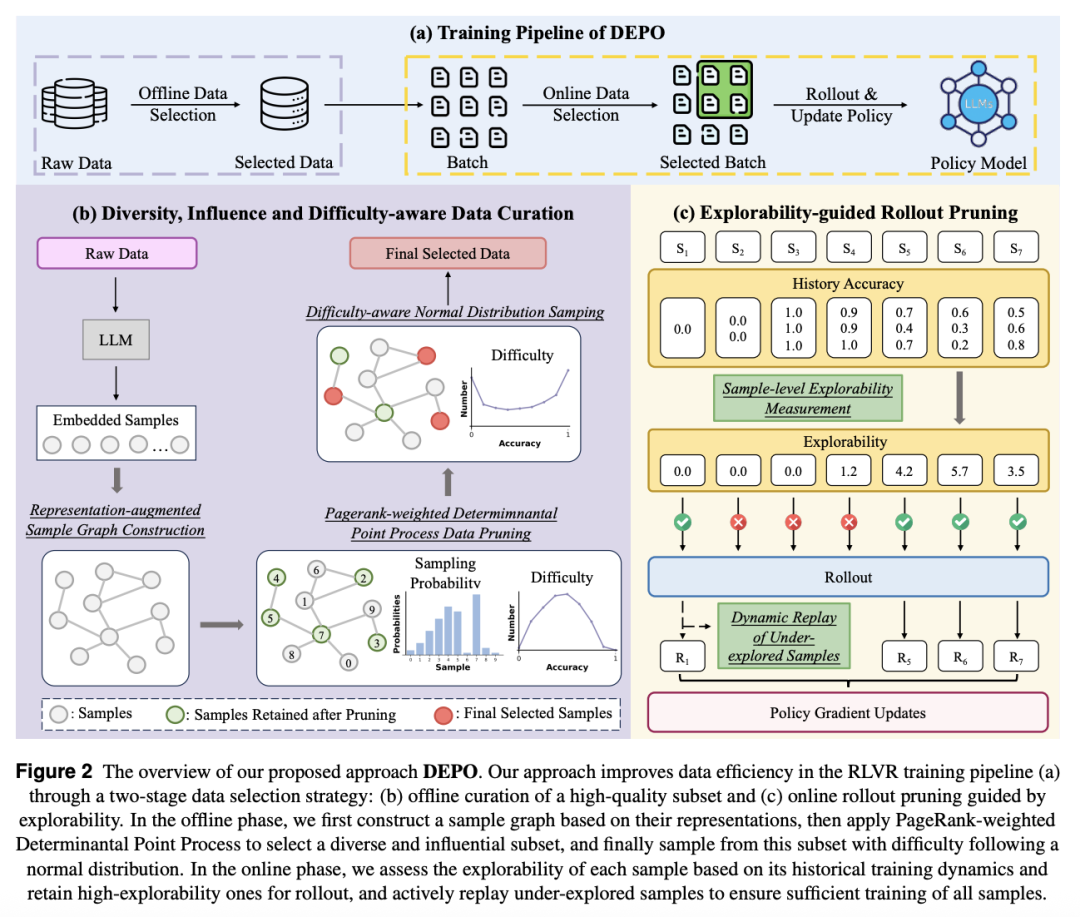
动机:
现有 RLVR 方法、通过扩大训练数据量和 rollout 数量来提升模型推理能力,但这导致训练成本激增(计算资源、时间)且数据利用率低。
离线数据选择:传统方法需在全集上训练以计算数据选择指标(如奖励趋势、梯度对齐),计算开销大;或忽略样本间关联性(如仅基于难度过滤)。
在线 rollout 效率:大量样本需昂贵 rollout 却对策略更新贡献微小,现有方法(如 GRESO)仅粗粒度过滤零方差样本,未区分样本的探索潜力。
方法:
1. 多维度的离线数据选择
1.1 用 LLM 最后一层 token 嵌入作为样本表征,构建相似度图,其中边权为余弦相似度。
1.2 利用PageRank加权的行列式点过程联合最大化子集多样性与影响力。
1.3 在剪枝后的子集上,用当前策略离线rollout,计算样本准确率作为难度指标。然后按正态分布采样,优先选择中等难度样本。
2. 熵驱动的在线 rollout 剪枝
2.1 基于滑动窗口内历史熵与优势的加权指标获得模型的探索能力,并选择高探索潜力的样本进行在线rollout。
2.2 动态重放历史最少训练的样本,保证所有样本都能得到充分的训练
实验
实验结果表明,本文章的方法仅用20%的数据能逼近全量训练性能,并且训练时间缩短40%,rollout数量减少60%。
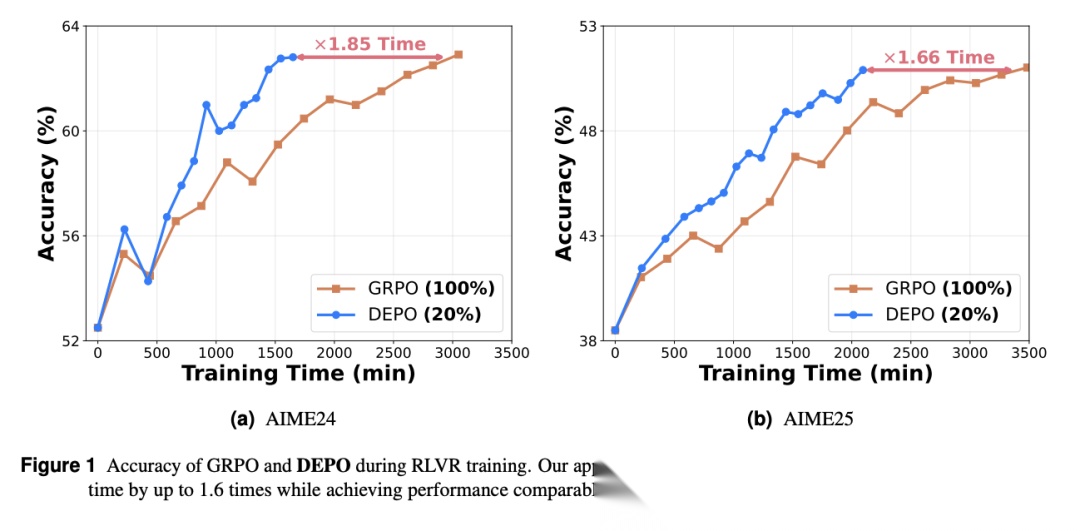
本文在三个模型和五个推理数据集上都进行了详细的实验,实验结果表明 DEPO 在各个数据集上都展现出强大的性能和效率优势。
在线数据选择
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts
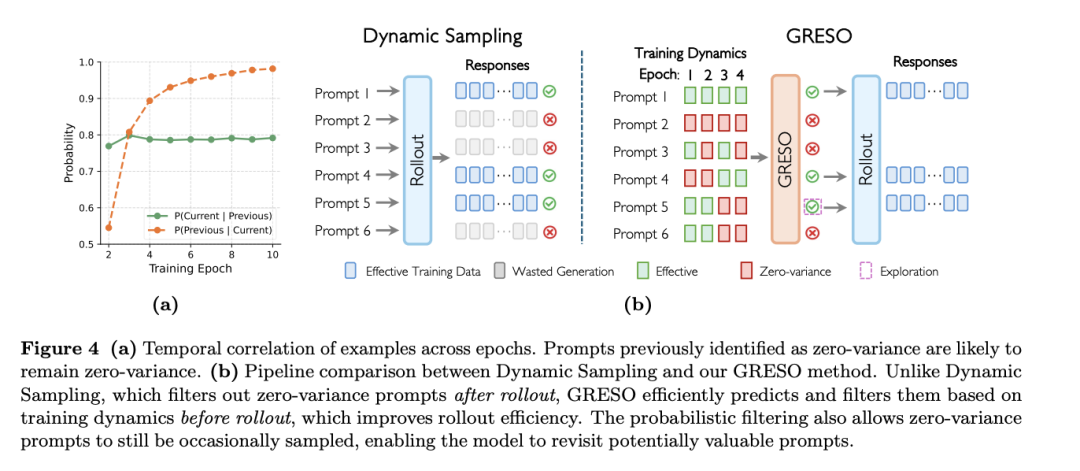
论文分析了提示在不同训练epoch中的奖励动态,发现零方差提示(即所有响应的奖励都相同的提示)在训练过程中具有很强的时间一致性。
自适应调整探索概率:采用了一种自适应机制来自动调整探索概率,根据目标零方差比例和实际观察到的零方差比例动态调整探索概率。
自适应采样批次大小:如果当前批次中有效提示的数量不足,算法会根据需要动态调整采样批次大小。
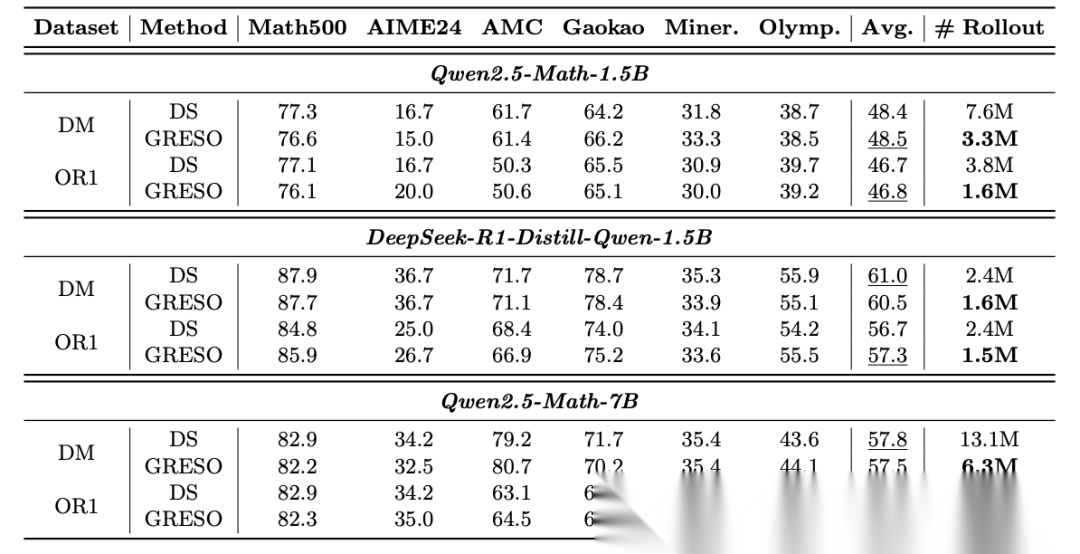
离线数据选择
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
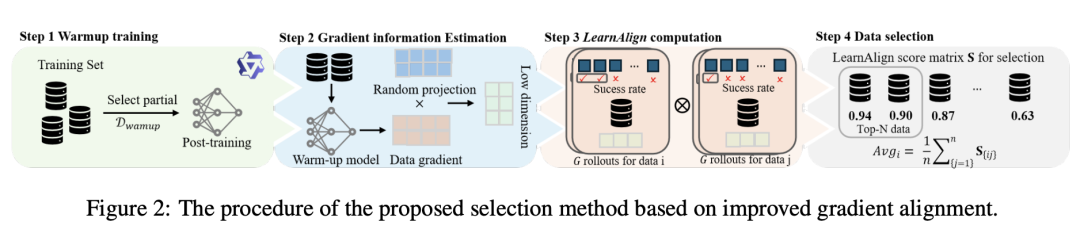
梯度对齐:论文利用一阶泰勒展开近似模型参数更新对损失函数的影响,定义了数据点之间的影响力为两个数据点的梯度内积。
可学性: 基于成功概率来衡量数据点的可学性,该指标反映了数据点对模型性能提升的潜在价值。
Learnalign分数:结合数据可学性和梯度对齐,计算LearnAlign分数,用于评估数据点之间的相似性和可学性。
数据选择方法
预热训练:从训练数据集中随机选择一个小子集进行预热训练,以确保更稳定和准确的梯度估计。
梯度信息估计:在预热阶段,计算每个数据点的梯度信息,并通过随机投影将其降维。
LearnAlign分数矩阵计算:基于降维后的梯度信息,计算所有数据点之间的LearnAlign分数,形成一个分数矩阵。
数据选择:根据LearnAlign分数矩阵,选择平均分数最高的前N个数据点,作为最具代表性和可学性的数据子集。
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
论文提出了“1-shot RLVR”的概念,旨在探究仅使用一个训练样本是否能够实现与使用大规模数据集相当的性能提升。
通过分析训练样本的历史方差得分,选择具有最高方差的样本作为训练数据。这种方法基于假设高方差样本在训练过程中可能提供更丰富的信息。
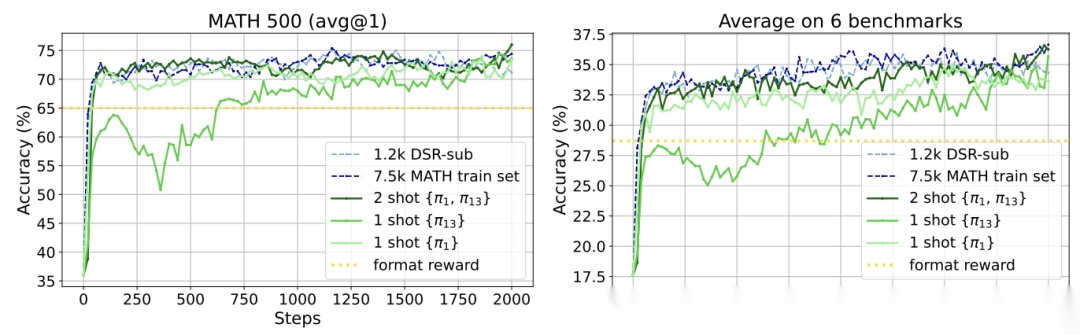
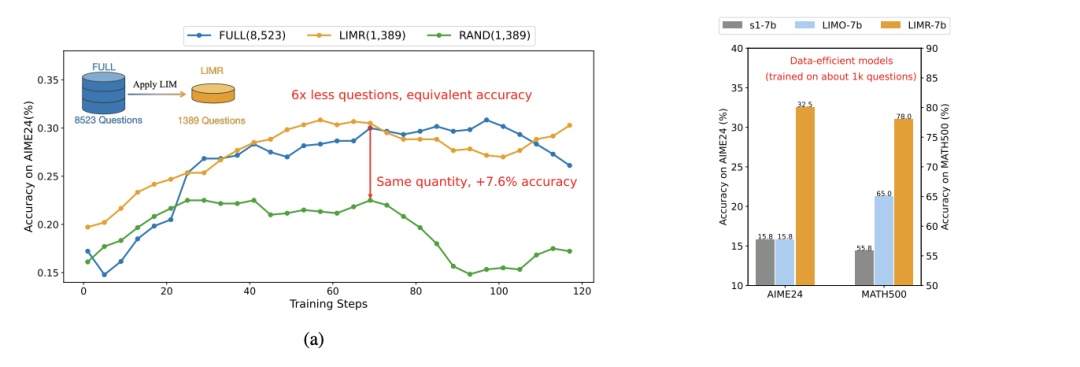
LIMR: Less is More for RL Scaling
使用模型的平均奖励曲线作为参考,计算每个样本的学习轨迹与模型整体学习轨迹的对齐程度。通过计算一个归一化的对齐分数来量化样本对模型学习的贡献,分数越高表示样本与模型学习轨迹的对齐程度越好,对模型优化的价值也越大。
Data-Efficient RLVR via Off-Policy Influence Guidance
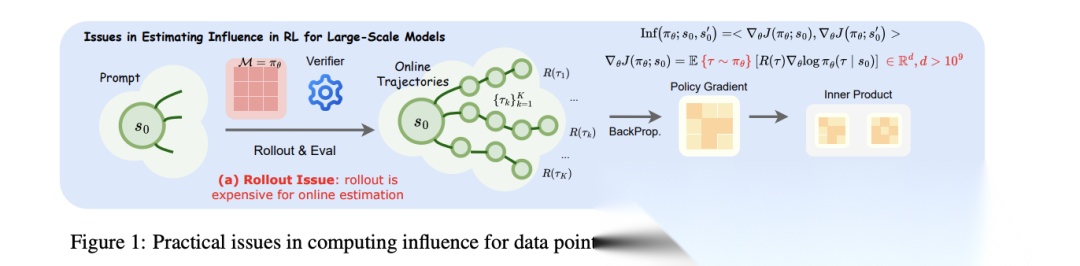
将监督学习中的影响函数理论扩展到 RLVR,给出训练样本对策略性能变化的一阶近似贡献度量。
提出离策略影响力估计,用行为策略预先采集的离线轨迹近似当前策略梯度,彻底避免在线采样。
引入稀疏随机投影,在梯度计算前随机丢弃大部分维度,再执行低维投影,降低存储与计算成本,并意外提升内积排序保持精度。
基于上述估计构建多阶段课程强化学习框架 CROPI,每阶段仅选用对验证集影响力最高的小部分数据进行 GRPO 更新。
DRIVE: Data Curation Best Practices for Reinforcement Learning with Verifiable Reward in Competitive Code Generation
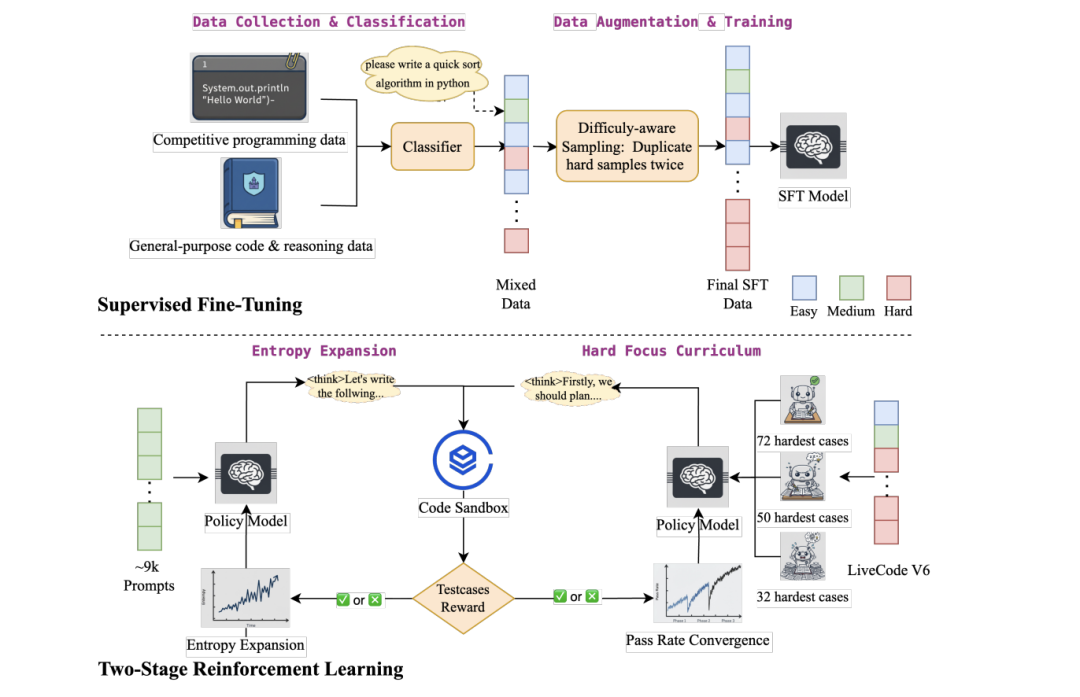
阶段一:用 9 k 均匀难度题、每题 8 rollout,24 k 长度,打破模式坍塌;
阶段二:仅保留最难案例,64 rollout,三阶段递进,持续逼迫模型突破难题边界。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献615条内容
已为社区贡献615条内容

所有评论(0)