论文导读 | 大模型推理能耗优化
作者发现Agent利用复杂推理策略(如Tree of Thought(ToT), Fleet of Agent(FoA))进行推理时,会产生大量冗余Prompt,且目前的缓存策略(如KV Cache)多在底层优化,难以支持在线API,且而现有的客户端缓存往往缺乏统计完整性和复现性,无法处理需要多个独立响应的随机采样场景。TiME的核心思路是利用MiniLMv2的蒸馏框架,将大型、强大的教师模型(X
背景
随着大语言模型(LLM)在各领域的爆发式应用,其卓越的智能化表现正深刻改变人类的生产生活方式。然而,这一进程伴随着巨大的能源消耗挑战。根据国际能源署(IEA)的预测[1],到2030年,全球数据中心的年耗电量将攀升至945 TWh,这一数字已超越日本当前的全国总电力消耗量。在大模型的全生命周期中,持续性的推理服务所产生的能效赤字和二氧化碳排放量远超模型训练阶段[2]。因此,针对大模型推理阶段的能耗优化,不仅是提升AI系统经济性的技术必然,更是响应国家“双碳”战略目标、实现人工智能可持续发展的关键路径。
本文将从结构优化、系统优化以及模型压缩三个方面介绍大模型推理能耗优化相关工作。
结构优化

LayerSkip[3]提出了一套端到端的解决方案,旨在加速大模型的推理过程,同时不增加额外的显存负担。作者通过观察发现,模型在生成每个token时,其实并不总是需要经过所有层的计算,简单token在浅层就已经能准确输出。现有方法有以下问题:
-
计算浪费:在标准的模型中,即便是一个简单的token,也需要经过所有层的计算才能得出结果。
-
提前退出(Early Exit):传统的提前退出方案通常需要为每一层添加辅助模块,增加了模型复杂度和显存占用。
-
投机解码(Speculative Decoding):通常需要一个额外的、更小的草稿模型,这不仅需要维护两套模型的 KV Cache,还增加了实现难度。

作者提出了一套三阶段pipeline,涵盖训练、推理和验证:
-
训练阶段(LayerDropout + Early Exit Loss):引入了LayerDropout,在训练时随机跳过一些层,且丢弃概率随层数增加而指数增大,避免模型过度依赖深层;改造了损失函数,所有层共享同一个Model Head,总的损失函数值由各层损失相加,使中间层也具有了输出结果的能力。
-
推理阶段(Early Exit):只运行前E层,然后直接通过Model Head输出结果。
-
验证阶段(Self Speculation Decoding):用模型的前E层快速生成候选token,用剩下的L-E层并行验证这些 token是否正确。由于草稿和验证是在同一个模型上运行,LayerSkip可以重用前E层的KV Cache,而且引入了“Exit Query Cache”进一步减少重复计算。
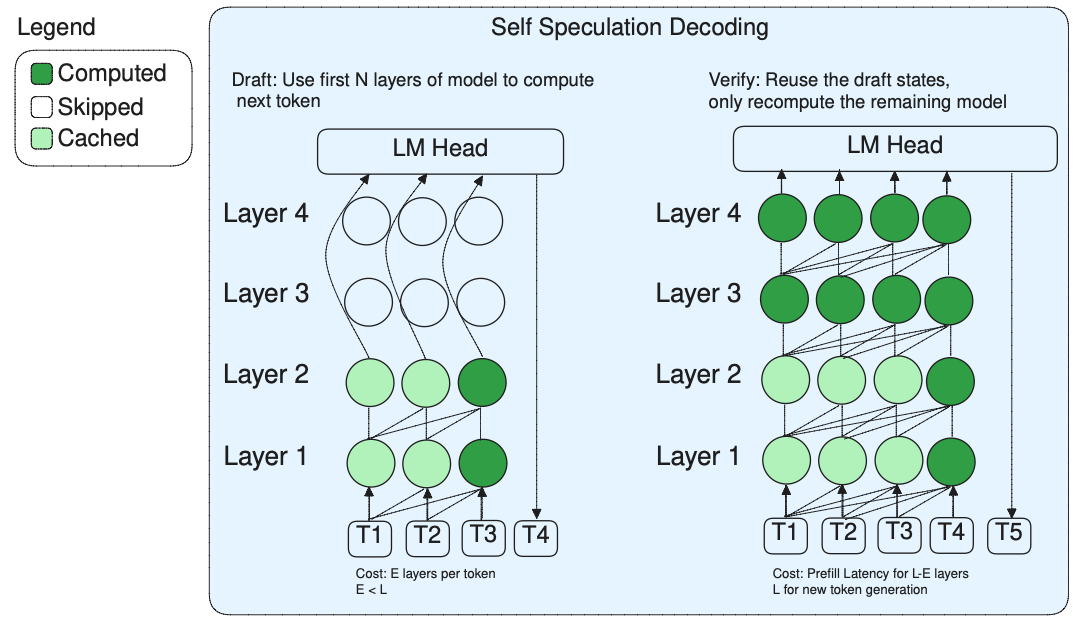
作者使用Llama系列模型在文档摘要,代码生成等数据集上进行了实验:
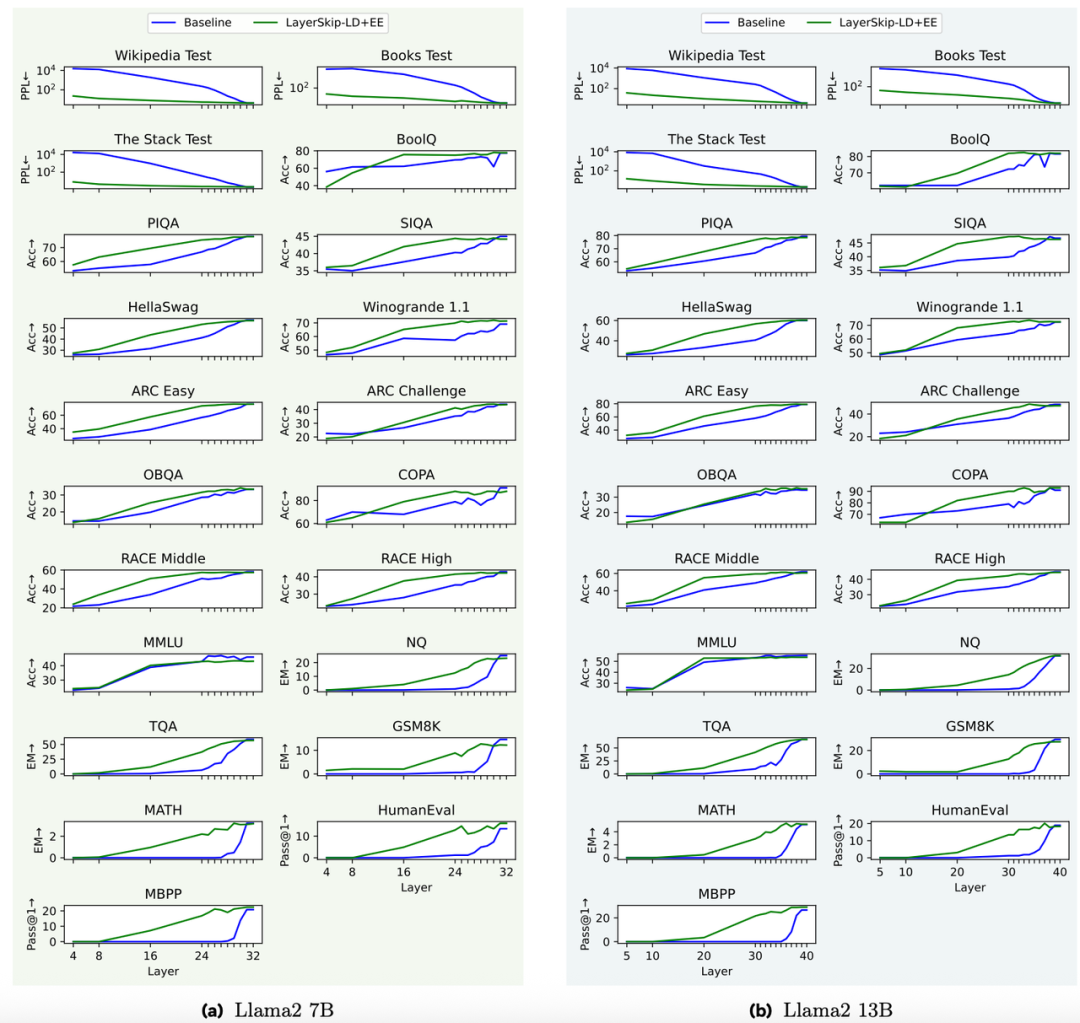
本文提出的方法在中间层表现优于baseline,说明中间层也具有了输出能力。
在加入自投机解码后作者比较了模型表现效果与推理速度:
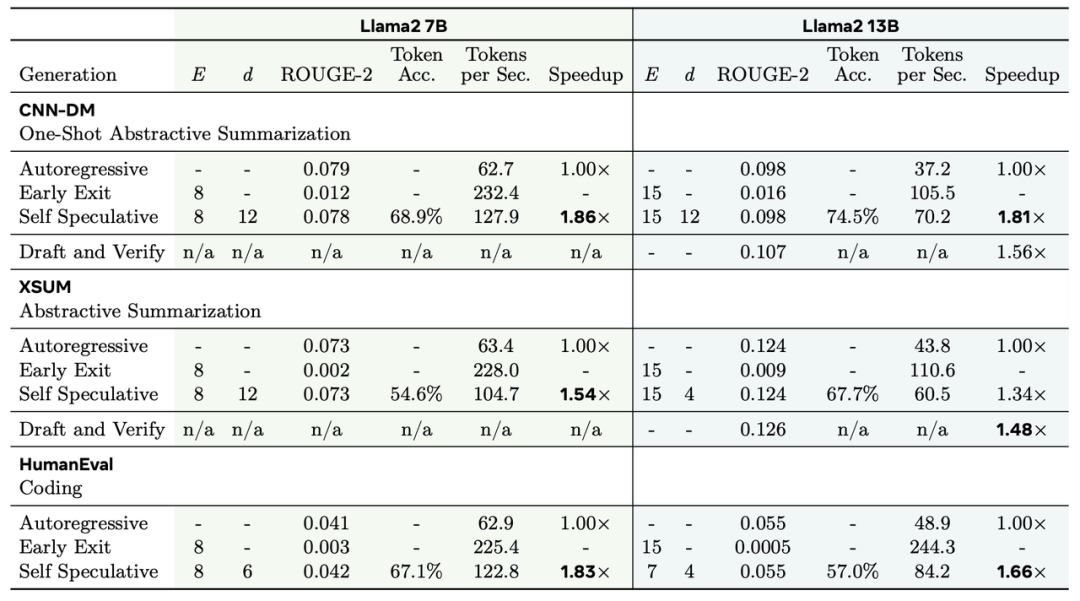
与传统的自回归解码相比,LayerSkip能在不牺牲模型表现的同时显著加快模型推理速度,降低推理成本。
系统优化

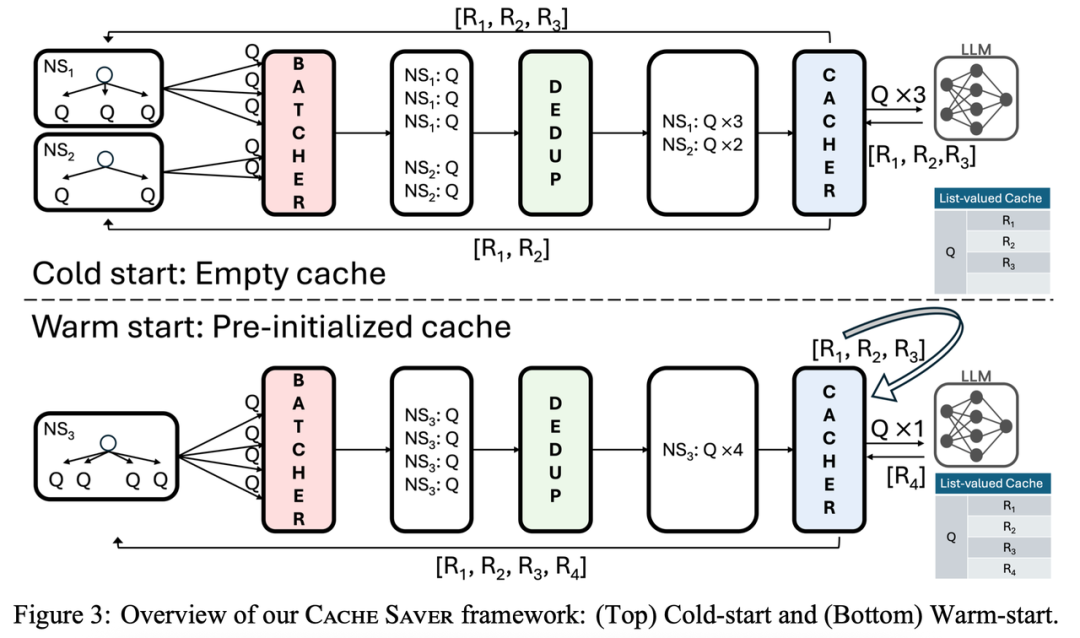
CacheSaver[4]旨在解决大模型推理成本高昂、环境影响大以及实验难以复现的问题。作者发现Agent利用复杂推理策略(如Tree of Thought(ToT), Fleet of Agent(FoA))进行推理时,会产生大量冗余Prompt,且目前的缓存策略(如KV Cache)多在底层优化,难以支持在线API,且而现有的客户端缓存往往缺乏统计完整性和复现性,无法处理需要多个独立响应的随机采样场景。
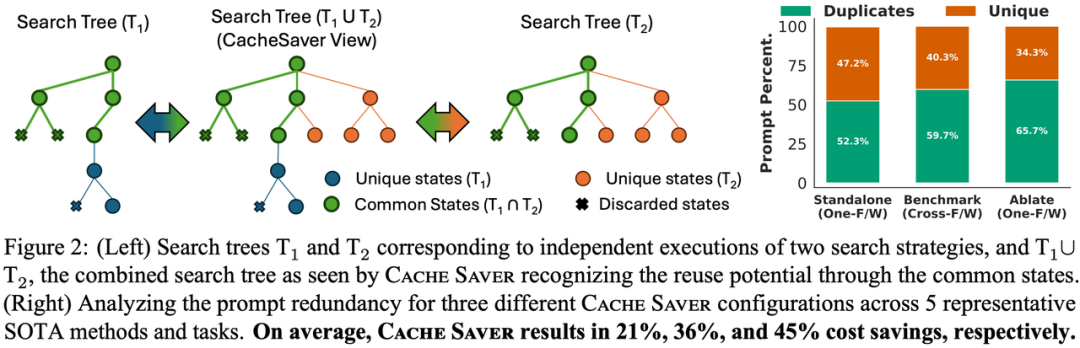
CacheSaver是一个模块化、即插即用的框架,能够拦截请求并进行优化。
其核心创新点包括:
-
列表值缓存(List-valued Cache): 为每个唯一Prompt维护一个响应序列,而不是传统一对一的缓存。
-
命名空间感知(Namespace-aware): 在同一个命名空间内,系统保证响应是独立同分布的;而在不同命名空间之间,可以复用缓存的相应。
由四个模块组成:
-
Batcher: 收集请求并分组,提高吞吐量。
-
Deduplicator: 合并相同的请求,减少对 LLM 的调用。
-
Cacher: 管理列表值缓存,利用随机耦合技术实现复用。
-
Reorderer: 确保异步请求的顺序确定,实现实验的可复现性。
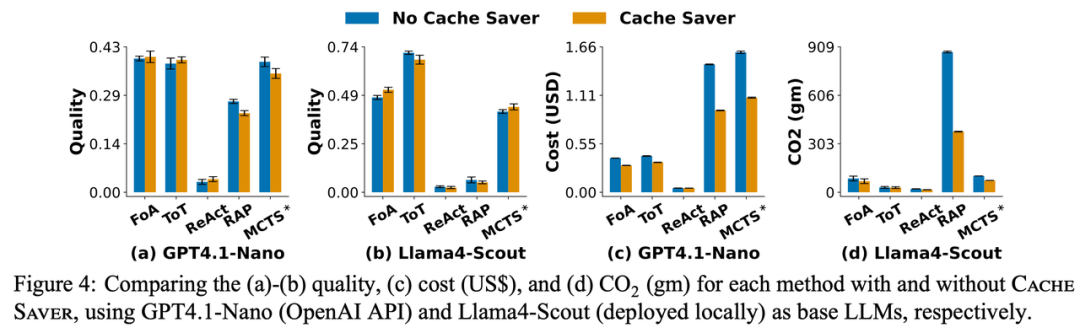
作者在5种推理策略、5个基准任务和3个主流大模型上进行了广泛测试。在模型生成质量与baseline相当的情况下,CacheSaver平均减少了约25%的成本和35%的二氧化碳排放。
模型压缩

TiME[5]介绍了一种训练高效单语言编码器的方法,旨在解决大型语言模型在实际部署中的速度与能耗问题。作者发现目前大模型参数过多能耗过大,限制了其在资源受限的端侧设备(如手机)上的部署。且目前的大模型追求通用、全能、多语言,因此在特定语言上的表现可能被“稀释”,表现效果可能不如专门的单语言模型。
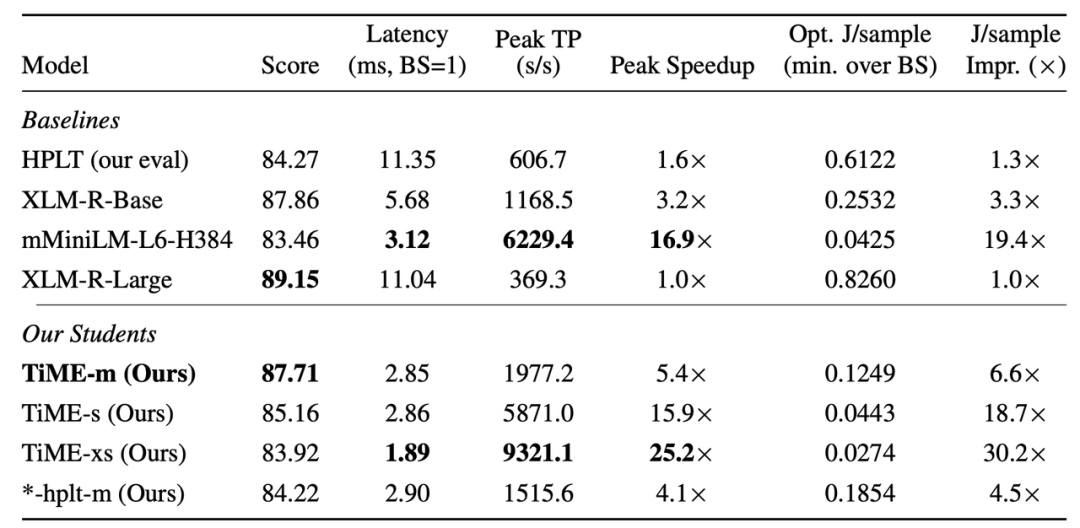
TiME的核心思路是利用MiniLMv2的蒸馏框架,将大型、强大的教师模型(XLM-R-Large)的知识转移到学生模型中。作者针对16种语言训练了三种尺寸的模型:Medium (m): 6层,768 Hidden Size。Small (s): 6 层,384 Hidden Size。Extra-Small(xs): 4 层,384 Hidden Size。
TiME模型在命名实体识别、词性标注、词形还原和依存句法分析等NLP任务上进行了全面评估。TiME-m模型在参数量减少58%的情况下,保留了教师模型XLM-R-Large约98.4%的平均分。相比教师模型,TiME模型实现了高达25×的推理加速。在能效方面,TiME实现了最高30×的能耗压缩。
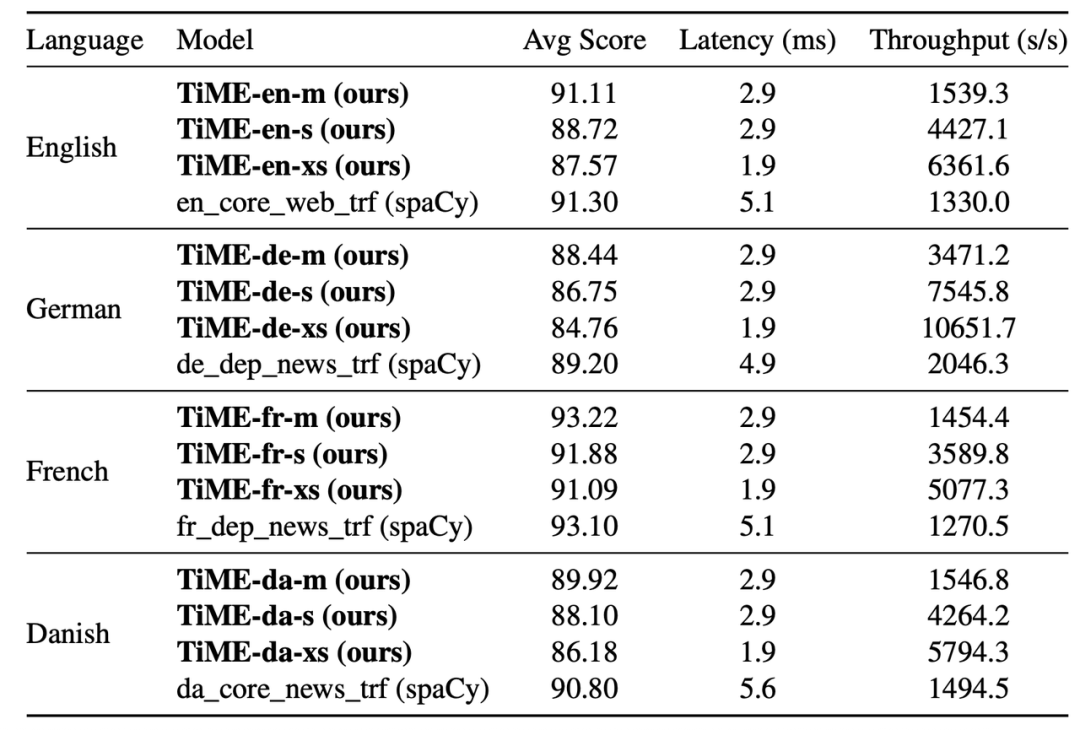
作者还将TiME与工业界常用的NLP库spaCy进行了对比。结果显示,TiME模型在达到相似准确率的前提下,延迟大幅降低。例如在英语任务中,TiME-xs的延迟仅为spaCy对应模型的37%。
参考文献:
[1] IEA. 2025. Energy and AI. https://www.iea.org/reports/energy-and-ai/
[2] Fu Z, Chen F, Zhou S, et al. LLMCO2: Advancing Accurate Carbon Footprint Prediction for LLM Inferences[J]. ACM SIGENERGY Energy Informatics Review, 2025, 5(2): 63-68.
[3] Elhoushi M, Shrivastava A, Liskovich D, et al. Layerskip: Enabling early exit inference and self-speculative decoding[C]//Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024: 12622-12642.
[4] Potamitis N, Klein L H, Xu C, et al. Cache Saver: A Modular Framework for Efficient, Affordable, and Reproducible LLM Inference[C]//ES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models. 2025.
[5] Schulmeister D, Hartmann V, Klein L, et al. TiME: Tiny Monolingual Encoders for Efficient NLP Pipelines[J]. arXiv preprint arXiv:2512.14645, 2025.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)