【ComfyUI】SD1.5 + ControlNet 边缘检测搭配深度融合动漫转真人
本文介绍了一个基于ComfyUI的动漫转真人AI工作流,通过双重ControlNet(Canny边缘检测和Depth深度图)实现高度还原的风格转换。该工作流采用majicmixRealistic_v7主模型,配合WD14Tagger自动标签识别和BNK_CLIPTextEncodeAdvanced提示词编码等节点,形成完整的图像处理流程:首先对输入动漫图像进行768x768的尺寸统一,然后分别提取
今天给大家演示一个动漫转真人的 ComfyUI 工作流,利用双重 ControlNet 控制(Canny 与 Depth)实现对动漫图像进行结构还原与细节映射,最终生成具有高度还原度的真人风格图像。本工作流集成了图像预处理、深度与边缘控制、标签自动识别、提示词编码、双重 ControlNet 推理、多模型组合以及最终图像输出。整体流程精密衔接,适用于想要将二次元风格图像转换为真实风格的创作者、插画师或AI艺术从业者。

文章目录
工作流介绍
本工作流以动漫风格图像为输入,通过两个 ControlNet 模块分别引导图像的轮廓(LineArt)与深度(Depth),结合 VAE 和高质量 SD 模型,最终生成具备真实感的人物图像。整个流程核心在于双 ControlNet 的配合使用——一方面保持输入图的结构完整性,另一方面加强立体信息的保留,从而实现动漫图像向真人图像的高质量转换。
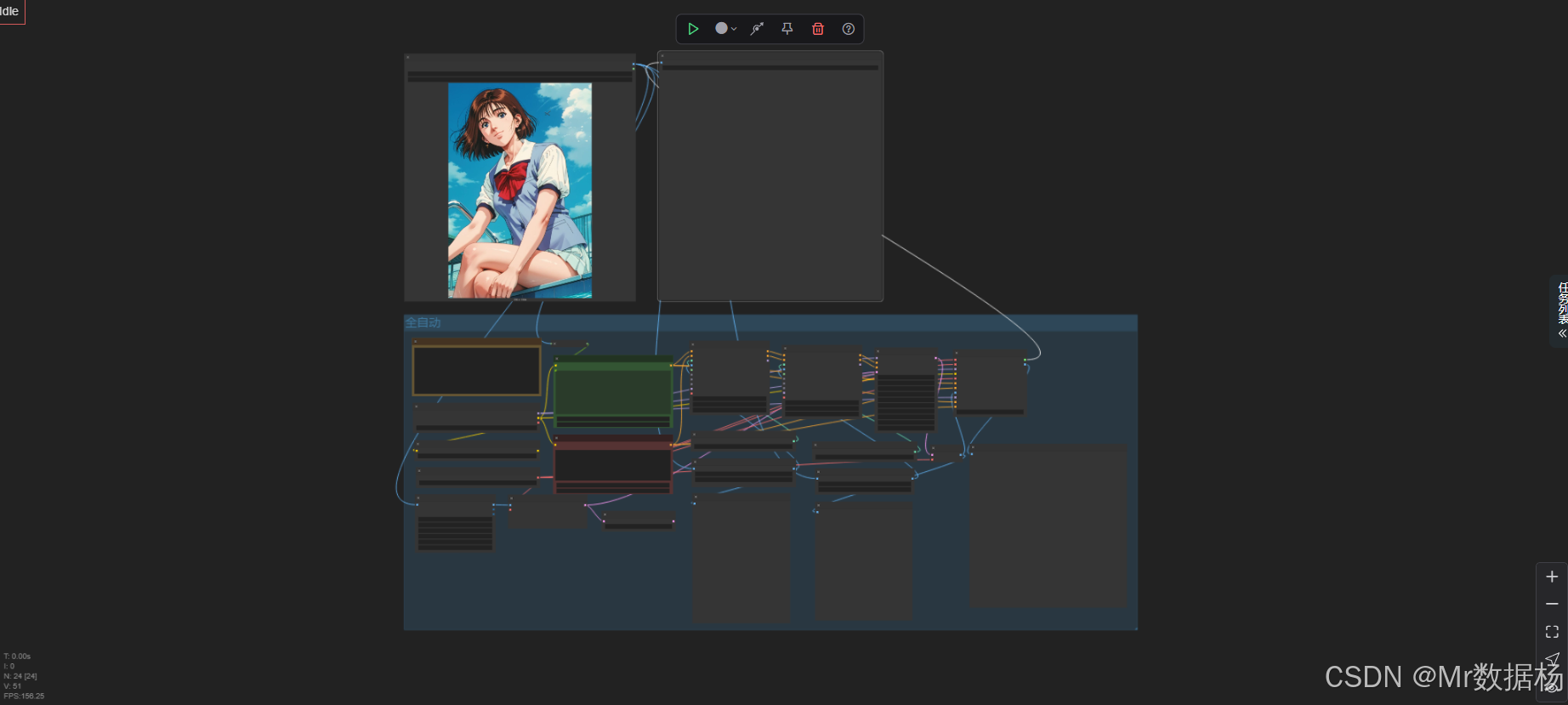
在流程中,通过引入 WD14Tagger 节点自动生成标签,用于精炼提示词内容;使用 BNK_CLIPTextEncodeAdvanced 节点进行复杂提示词的高效嵌入表达;再结合 KSamplerAdvanced 控制采样过程,确保生成图像既具还原度又不失艺术表现力。多种节点之间协同工作,形成一个逻辑严密、性能高效的 AI 图像推理链路。
核心模型
工作流中使用了以真实风格见长的 majicmixRealistic_v7 模型作为主模型,并配合预训练的 Canny 与 Depth 控制网络,分别加载 control_v11p_sd15_canny.pth 和 control_v11f1p_sd15_depth.pth,以实现高保真的图像风格转换效果。VAE 模块采用 vae-ft-mse-840000-ema-pruned.safetensors,保证图像解码时的细节保留与清晰度。
| 模型名称 | 说明 |
|---|---|
| majicmixRealistic_v7.safetensors | 主模型,具备高真实感风格的图像生成能力 |
| control_v11p_sd15_canny.pth | Canny 边缘控制模型,用于保持图像线稿结构 |
| control_v11f1p_sd15_depth.pth | Depth 深度控制模型,用于增强立体感和细节层次 |
| vae-ft-mse-840000-ema-pruned.safetensors | 精细化 VAE 解码器,提升图像清晰度和细节还原 |
Node节点
工作流中的核心节点按功能分为预处理、特征编码、控制网络加载与应用、图像采样与重建、以及最终输出。其中,LineArtPreprocessor 与 AIO_Preprocessor 分别完成边缘与深度的图像提取;WD14Tagger 自动识别输入图像的标签标签;BNK_CLIPTextEncodeAdvanced 精准控制提示词嵌入;ACN_AdvancedControlNetApply 则负责将控制图与模型配合,用于 ControlNet 的深度整合与推理执行。
| 节点名称 | 说明 |
|---|---|
| LineArtPreprocessor | 对输入图像进行边缘检测,提取线稿信息 |
| AIO_Preprocessor(DepthAnythingV2) | 进行深度图像分析,捕捉图像立体结构 |
| WD14Tagger | 自动识别动漫图像标签,优化提示词 |
| BNK_CLIPTextEncodeAdvanced | 处理提示词和反向提示词并生成嵌入向量 |
| ControlNetLoader | 加载 Canny 与 Depth 控制模型 |
| ACN_AdvancedControlNetApply | 应用 ControlNet 控制条件进行推理 |
| KSamplerAdvanced | 控制采样方式、步数等关键生成参数 |
| VAELoader / VAEEncode / VAEDecode | 编解码图像 latent 表达与图像 |
| ImageResize+ | 对输入图像尺寸进行统一处理 |
| PreviewImage / SaveImage | 展示与保存最终输出结果 |
工作流程
本工作流围绕“动漫转真人”这一核心目标展开,共分为输入处理、结构提取、提示词生成、控制融合、采样生成与输出展示六大阶段。每个阶段由多个节点配合完成,确保图像信息的完整传递与风格转换的准确执行。
在输入阶段,用户加载原始动漫图像,使用 ImageResize+ 对图像统一到 768x768 的标准尺寸,随后由两个预处理器分别提取边缘信息(LineArtPreprocessor)与深度信息(AIO_Preprocessor),这两类图像结构数据是后续双 ControlNet 应用的关键。
标签提取则通过 WD14Tagger 节点自动分析图像内容并生成关键描述词,配合 BNK_CLIPTextEncodeAdvanced 将提示词向量嵌入转化为模型可识别的条件。
双 ControlNet 控制流程使用两个 ControlNetLoader 载入边缘和深度模型,通过两个 ACN_AdvancedControlNetApply 节点分别融合对应的图像结构与提示条件。
中间由 VAEEncode 将原图转为 latent 表达,与模型和条件一起交由 KSamplerAdvanced 控制生成细节,之后再由 VAEDecode 将生成的 latent 解码为最终图像。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 图像导入与尺寸规范 | 加载原始图像并统一分辨率至 768x768 | ImageResize+ |
| 2 | 图像结构提取 | 提取图像边缘和深度作为 ControlNet 控制输入 | LineArtPreprocessor、AIO_Preprocessor |
| 3 | 标签识别与提示词生成 | 自动识别图像内容标签并转换为向量 | WD14Tagger、BNK_CLIPTextEncodeAdvanced |
| 4 | 控制模型加载与配置 | 分别加载 Canny 和 Depth 控制模型 | ControlNetLoader(2次) |
| 5 | 双重ControlNet融合 | 应用两个 ControlNet 引导模型进行推理 | ACN_AdvancedControlNetApply(2次) |
| 6 | Latent 编码与图像生成 | 将输入图像转为 latent、采样生成、解码输出 | VAEEncode、KSamplerAdvanced、VAEDecode |
| 7 | 输出与展示 | 生成图像结果并进行预览或保存 | PreviewImage、SaveImage |
大模型应用
BNK_CLIPTextEncodeAdvanced 文本语义驱动的内容约束核心
这个节点负责把用户输入的文字 Prompt 转成可用于生成模型的语义向量。它不参与图像、线稿、深度处理,只专注于理解文本并将语义映射到生成模型内部的概念空间。正向 Prompt 决定画面里的主体样貌、光影、构图与风格走向,反向 Prompt 抑制低质量特征与错误结构。Prompt 在此节点中的表达越具体,生成结果越稳定。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| BNK_CLIPTextEncodeAdvanced | Positive Prompt: (用户输入文本) Negative Prompt: foot,nsfw,nude,(worst quality:2),(low quality:2),(normal quality:2),lowres,((monochrome)),((grayscale)),bad anatomy,DeepNegative,skin spots,acnes,skin blemishes,(fat:1.2),facing away,looking away,tilted head,lowres,bad anatomy,bad hands,missing fingers,extra digit,fewer digits,bad feet,poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,missing arms,missing legs,extra digit,extra arms,extra leg,extra foot,teethcroppe,signature,watermark,username,blurry,cropped,jpeg artifacts,text,error,embedding:EasyNegative,embedding:bad-picture-chill-75v |
将正反向 Prompt 编码为文本语义,为生成模型提供清晰的风格控制信号。 |
BNK_CLIPTextEncodeAdvanced(自动标签反推) 标签语义补全编码单元
该节点使用 WD14Tagger 自动识别输入图的标签,再将标签文本经过语义编码,生成一份贴合源图风格的 CLIP 语义向量。它的任务是为最终生成提供“参考风格引导”,确保动漫到真人的转绘更符合原图特征。Prompt 在此节点中由自动标签提供,可进一步被用户修改,以强化风格或弱化某些元素。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| BNK_CLIPTextEncodeAdvanced | Auto Tag Prompt: (来自 WD14Tagger 自动生成的标签文本,如:1girl、solo、looking_at_viewer、blue_eyes 等) Negative Prompt: (默认空) |
自动把图像标签编码进语义空间,用于保证生成结果与原图结构、姿态、特征一致。 |
使用方法
整个工作流围绕“动漫人物 → 真人风格转绘”展开。通过双 ControlNet(线稿 + 深度)锁定结构,再结合 Prompt 文本控制画面气质、光影与面部特征,使最终图像既保留动漫主体又具备真实摄影感。用户替换输入图后,系统自动执行线稿提取、深度分析、语义反推、双向文本编码、模型推理与最终渲染,无需手动更新任何节点。
角色图提供主体与姿态基础,线稿用于确定轮廓层次,深度图提供立体结构参考。自动标签反推补充风格语义,而用户正向 Prompt 决定最终呈现的质感、光影、肤色、发质与真实度。替换任意素材后,工作流会自动重新执行完整推理流程。
| 注意点 | 说明 |
|---|---|
| 正向 Prompt 要明确写出风格方向 | 例如“realistic photo, soft light, skin detail”等会显著提升写实度 |
| 反向 Prompt 建议保持完整 | 能明显减少手部畸形、拉伸、塌鼻等常见错误 |
| 输入动漫图需尽量清晰 | 清晰图像能提升线稿与深度的准确性 |
| 控制图(线稿 / 深度)不要手动改动 | 系统会自动预处理,改动会影响一致性 |
| 自动标签来自 WD14Tagger | 若标签偏差,可在第二个文本编码节点中自行补充或删除 |
| 输出分辨率受原图尺寸影响 | 建议输入图至少 1024×1024 以获得更高细节 |
应用场景
该工作流广泛适用于动画角色现实化、美术创作草图还原、虚拟偶像视觉开发、动漫衍生品视觉设计等多个领域。其自动化程度高,对图像结构与语义的精准控制,适合专业创作者批量处理内容、快速迭代效果。尤其在 AI 人物定制与风格融合类场景下,本工作流能高效完成“卡通 → 写实”的风格迁移。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 动漫角色现实化 | 将动漫人物形象转化为真人风格图像 | AI美术师、概念设计师 | 动漫风格头像/全身图 | 输出高保真、写实风格图像 |
| 虚拟偶像视觉开发 | 构建写实风格的虚拟人形象 | IP运营者、品牌视觉团队 | 宣传视觉稿、数字人图像 | 统一风格、高还原、可商用 |
| 美术草图还原 | 结构草图快速实现为写实图 | 插画师、原画师 | 线稿草图 | 还原结构比例、提升质感 |
| 动漫周边定制图 | 提供写实版本用于产品包装 | 文创设计师 | 手办包装、周边商品图 | 提升视觉冲击力与现实感 |
| 二次元风格迁移 | 在不同视觉风格间切换 | AI实验用户、研究人员 | 动漫图输入、真人图输出 | 可调节风格保留度,提升可控性 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)