大数据项目:大模型Python新闻推荐系统 热点新闻平台 大数据 Hadoop 混合推荐算法 爬虫 可视化 推荐算法 vue框架 Django框架 selenium爬虫技术✅
本文介绍了一款基于Python+Django+Vue的智能新闻推荐系统,采用Selenium爬虫技术采集新浪新闻数据(标题、文本、图片及视频链接),结合MySQL数据库存储。系统创新性地融合三重推荐算法:权重衰减防止重复推荐、标签匹配实现个性化推送、热点计算(阅读量/评论量/发布时间)保障时效性。功能模块包括用户端(分类浏览、评论互动、个性化推荐)和管理端(爬虫配置、数据管理、可视化分析),通过E
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
该项目是一款融合网络爬虫与智能推荐功能的数字化新闻平台,以解决传统新闻传播效率低、个性化不足等问题为核心目标。技术架构上,后端采用Python+Django框架提供稳定服务,前端通过Vue框架构建流畅交互界面,数据存储依赖MySQL数据库,核心技术涵盖Selenium与BeautifulSoup爬虫工具、jieba分词库及Echarts可视化组件。
功能层面,平台通过爬虫技术精准爬取新浪新闻的标题、文本、图片及视频链接,支持管理员端对爬虫任务的灵活配置与新闻数据的全面管理。用户端提供分类新闻浏览、注册登录、新闻详情查看及评论互动等基础功能,同时创新集成三重推荐机制:通过权重衰减避免兴趣标签固化导致的重复推荐,依托标签匹配实现个性化内容推送,结合阅读量、评论量与发布时间计算热点新闻,兼顾个性化与时效性。此外,系统配备数据可视化大屏,直观呈现新闻传播数据与用户行为趋势,管理员还可进行推荐配置调整、用户管理及评论审核等操作。
平台既满足普通用户高效获取多元新闻、表达观点的需求,又为管理者提供数据驱动的运营支持,实现了新闻采集、分发、互动全流程的智能化升级。
网络爬虫:通过Python实现新浪新闻的爬取,可爬取新闻页面上的标题、文本、图片、视频链接
推荐算法:权重衰减+标签推荐+热点推荐
- 权重衰减进行用户兴趣标签权重的衰减,避免内容推荐的过度重复
- 标签推荐进行用户标签与新闻标签的匹配,按照匹配比例进行新闻的推荐
- 热点推荐进行新闻热点的计算的依据是新闻阅读量、新闻评论量、新闻发布时间
涉及框架:
Django框架、vue框架、MySQL数据库、jieba、selenium爬虫、BeautifulSoup、vue.js
2、项目界面
(1)数据可视化大屏展示
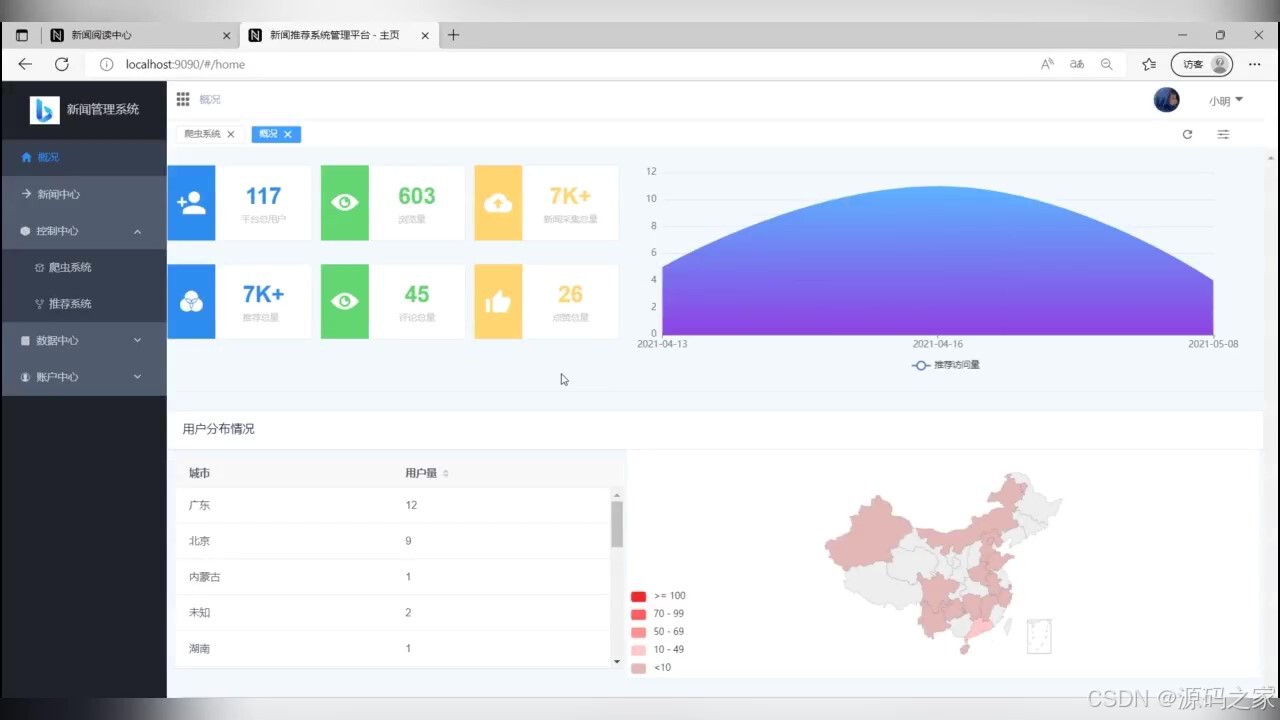
(2)系统首页
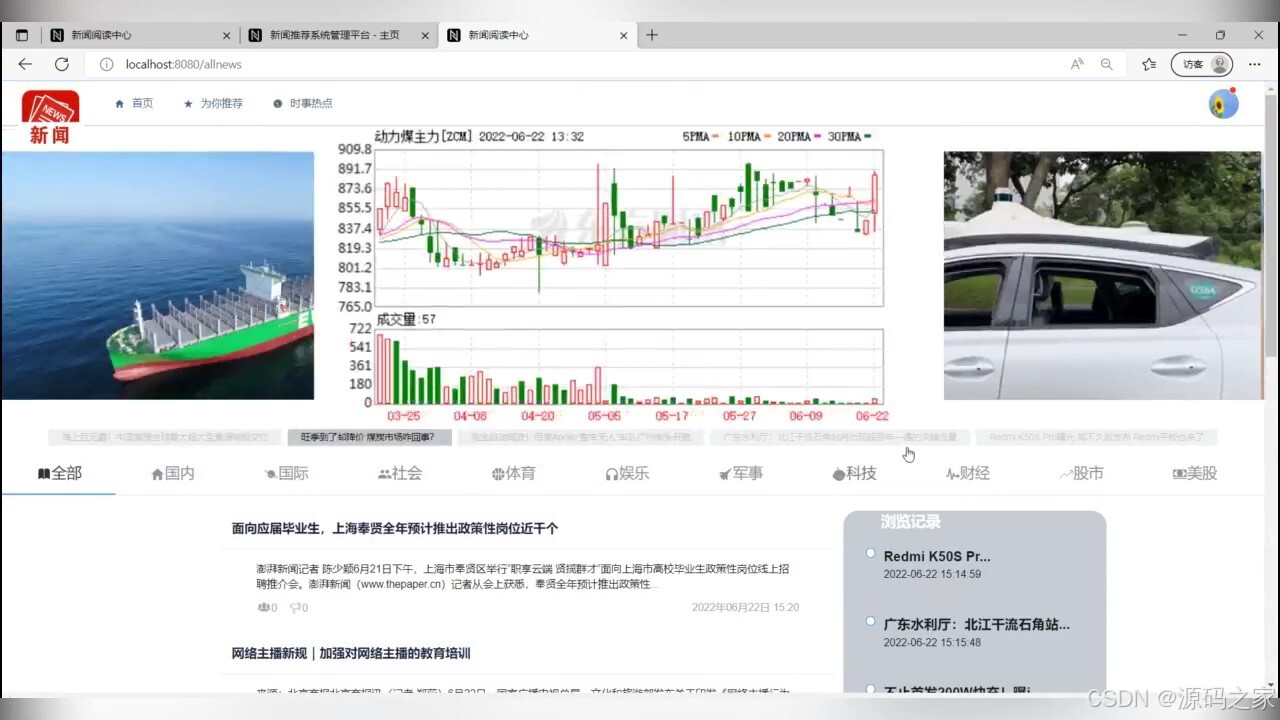
(3)数据爬虫设置
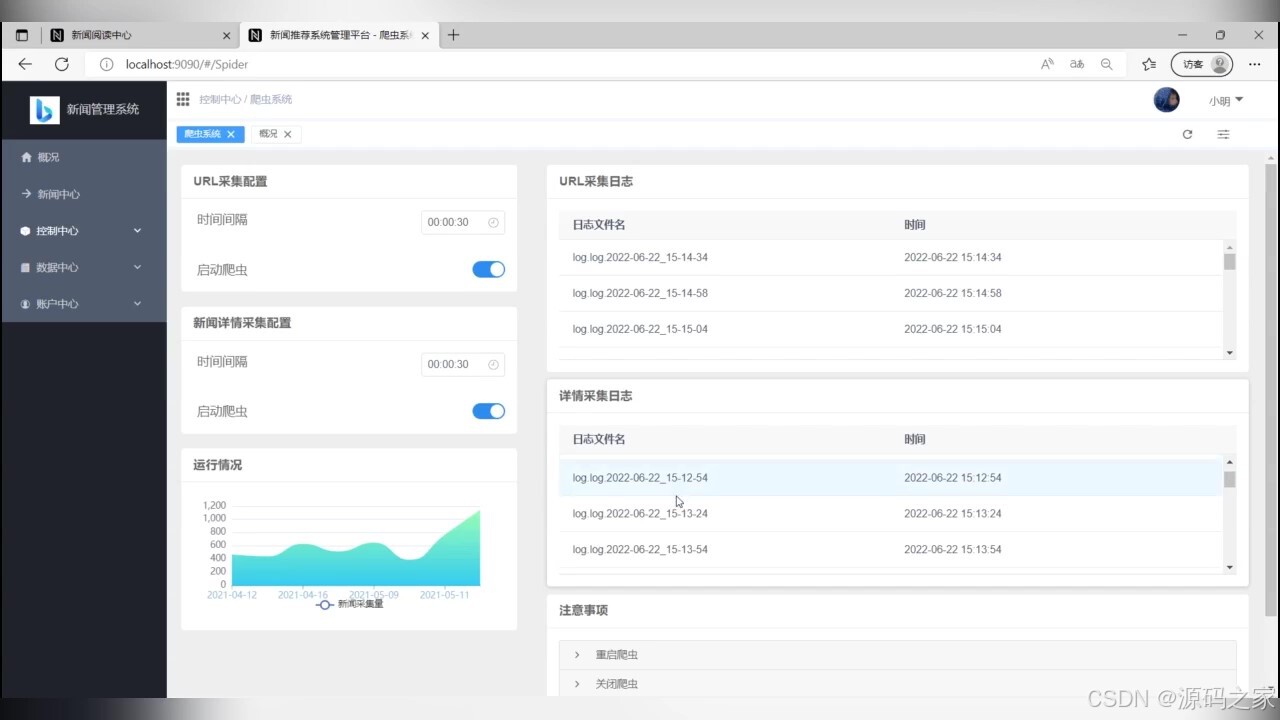
(4)新闻数据管理
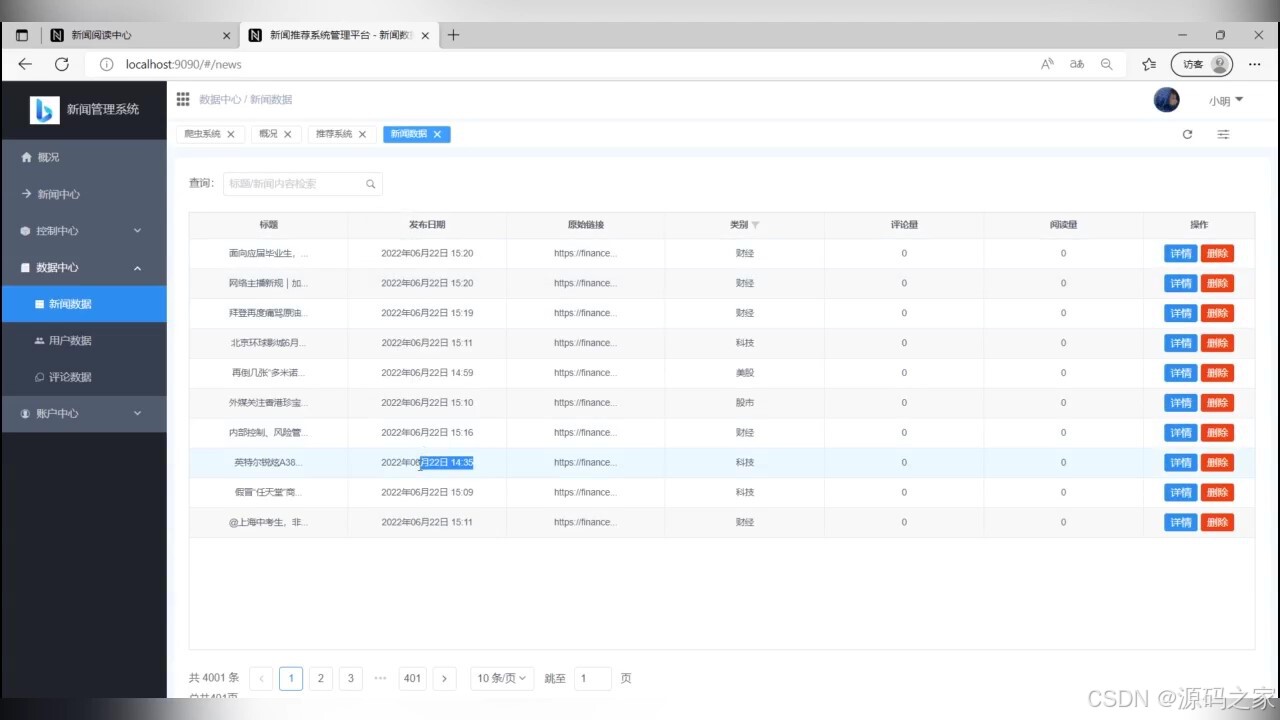
(6)新闻数据详情页面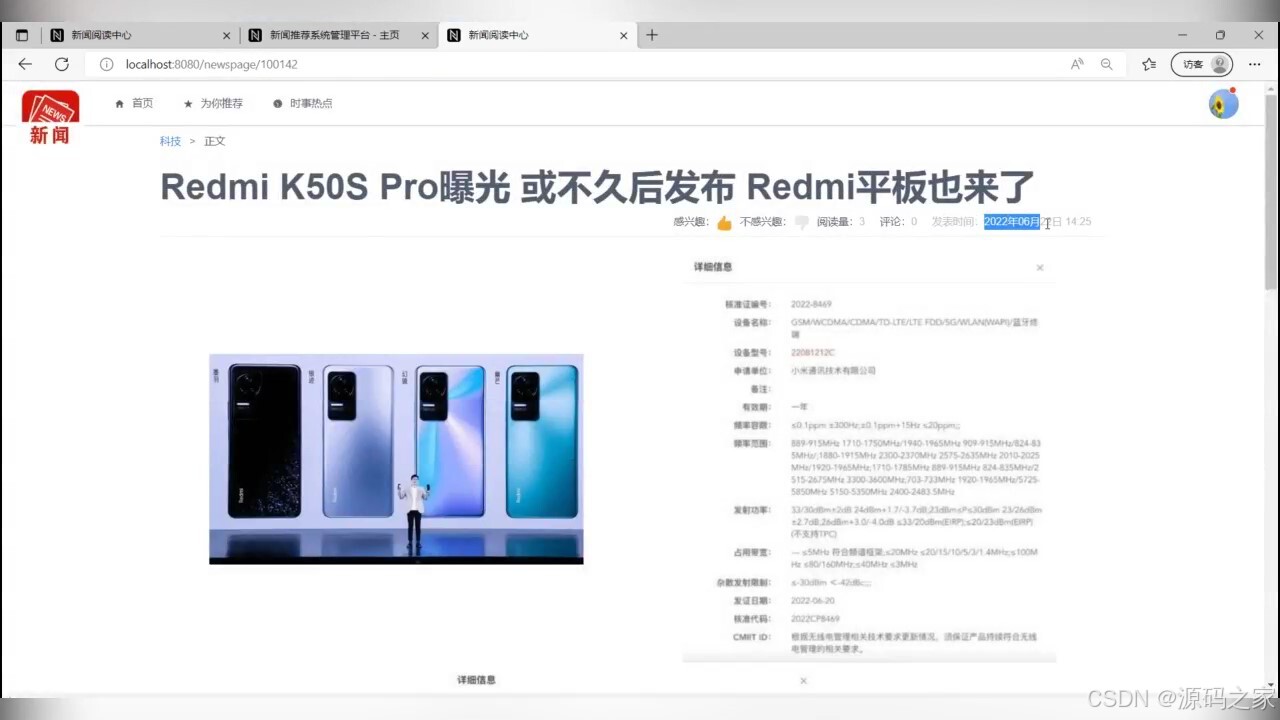
(7)新闻数据评论功能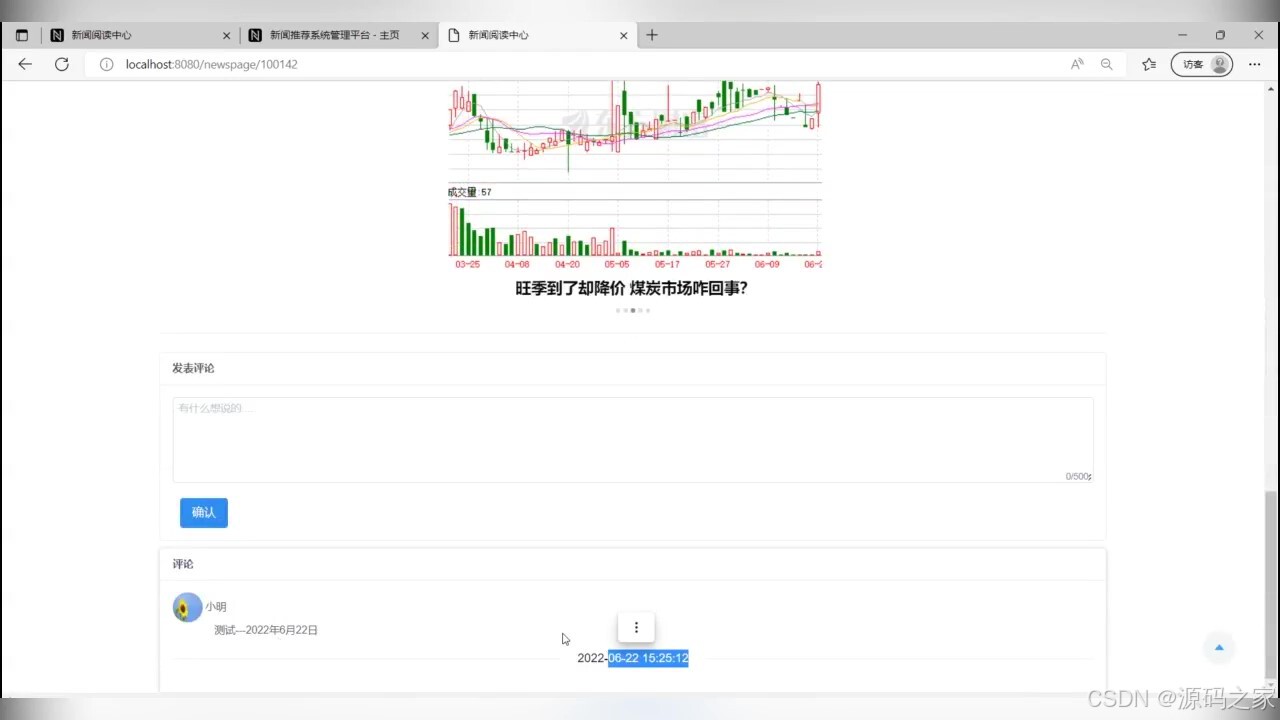
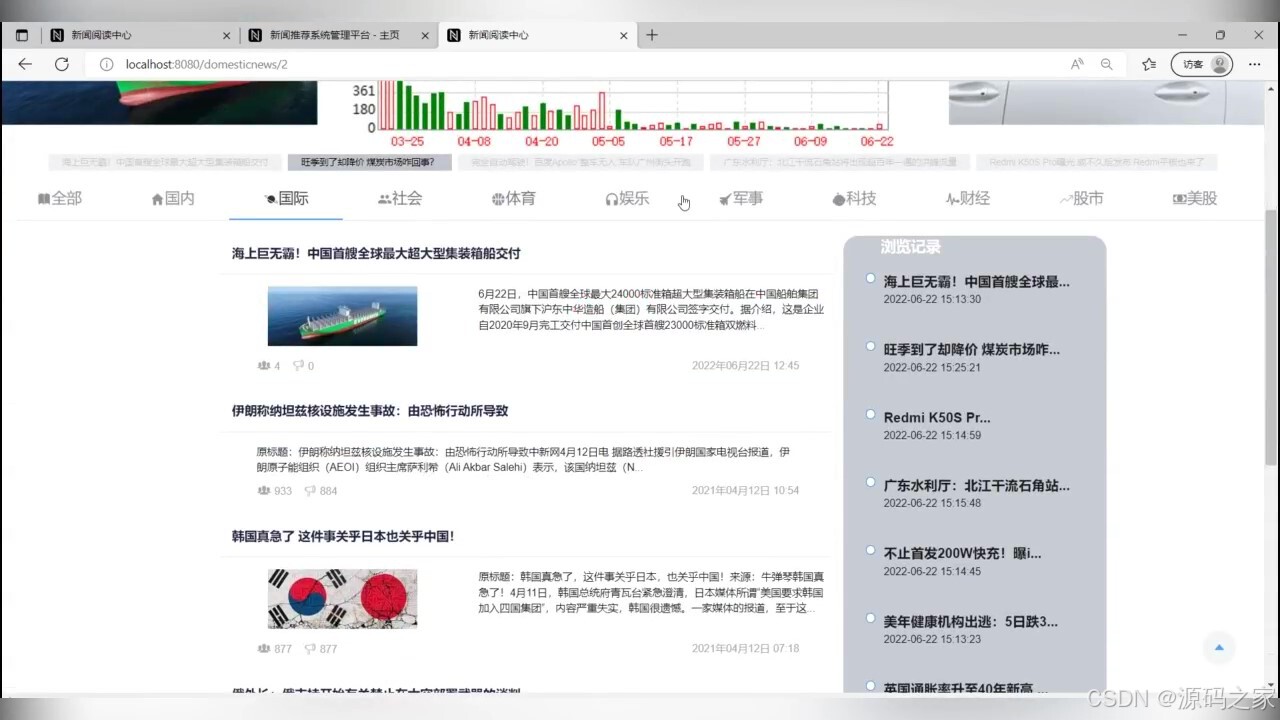
(8)不同类型的新闻数据浏览
(9)注册登录界面
3、项目说明
该项目是一款融合网络爬虫与智能推荐功能的数字化新闻平台,以解决传统新闻传播效率低、个性化不足等问题为核心目标。技术架构上,后端采用Python+Django框架提供稳定服务,前端通过Vue框架构建流畅交互界面,数据存储依赖MySQL数据库,核心技术涵盖Selenium与BeautifulSoup爬虫工具、jieba分词库及Echarts可视化组件。
功能层面,平台通过爬虫技术精准爬取新浪新闻的标题、文本、图片及视频链接,支持管理员端对爬虫任务的灵活配置与新闻数据的全面管理。用户端提供分类新闻浏览、注册登录、新闻详情查看及评论互动等基础功能,同时创新集成三重推荐机制:通过权重衰减避免兴趣标签固化导致的重复推荐,依托标签匹配实现个性化内容推送,结合阅读量、评论量与发布时间计算热点新闻,兼顾个性化与时效性。此外,系统配备数据可视化大屏,直观呈现新闻传播数据与用户行为趋势,管理员还可进行推荐配置调整、用户管理及评论审核等操作。
平台既满足普通用户高效获取多元新闻、表达观点的需求,又为管理者提供数据驱动的运营支持,实现了新闻采集、分发、互动全流程的智能化升级。
随着信息技术和互联网的发展,新闻传播从传统纸媒向数字化、智能化转变。传统新闻获取方式依赖固定渠道和人工筛选,信息传播效率低,个性化需求难以满足。新闻分类和推荐缺乏智能化手段,用户体验较差,新闻信息重复推荐和区域适配不足的问题显著。
系统后端采用Python语言和Django框架,前端采用Vue框架,数据库使用MySQL。通过Selenium爬虫技术实现新浪新闻爬取,获取标题、文本、图片、视频链接。功能包括首页新闻分类浏览、用户浏览记录和个性化推荐、新闻热度展示、用户标签管理与评论互动。管理员端支持新闻采集控制、推荐配置管理、数据分析日志查看、用户和新闻数据管理、评论操作等。Echarts用于数据可视化,界面采用HTML实现。
关键词:新闻推荐系统,Django,Vue,MySQL
随着信息技术和互联网的发展,新闻传播从传统纸媒向数字化、智能化转变。传统新闻获取方式依赖固定渠道和人工筛选,信息传播效率低,个性化需求难以满足。新闻分类和推荐缺乏智能化手段,用户体验较差,新闻信息重复推荐和区域适配不足的问题显著。
系统后端采用Python语言和Django框架,前端采用Vue框架,数据库使用MySQL。通过Selenium爬虫技术实现新浪新闻爬取,获取标题、文本、图片、视频链接。功能包括首页新闻分类浏览、用户浏览记录和个性化推荐、新闻热度展示、用户标签管理与评论互动。管理员端支持新闻采集控制、推荐配置管理、数据分析日志查看、用户和新闻数据管理、评论操作等。Echarts用于数据可视化,界面采用HTML实现。
关键词:新闻推荐系统,Django,Vue,MySQL
网络爬
虫:通过Python实现新浪新闻的爬取,可爬取新闻页面上的标题、文本、图片、视频链接
推荐算法:权重衰减+标签推荐+热点推荐
- 权重衰减进行用户兴趣标签权重的衰减,避免内容推荐的过度重复
- 标签推荐进行用户标签与新闻标签的匹配,按照匹配比例进行新闻的推荐
- 热点推荐进行新闻热点的计算的依据是新闻阅读量、新闻评论量、新闻发布时间
涉及框架:
Django框架、vue框架、MySQL数据库、jieba、selenium爬虫、BeautifulSoup、vue.js
软件功能结构/页面展示

4、核心代码
# -*- coding: utf-8 -*-
'''
Author:Z
Desc:通过热值对用户进行推送新闻
'''
import datetime
import logging
from logging.handlers import TimedRotatingFileHandler
import pymysql
from Spider.settings import DB_HOST, DB_USER, DB_PASSWD, DB_NAME, DB_PORT
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(levelname)-7s - %(message)s')
# 2. 初始化handler,并配置formater
log_file_handler = TimedRotatingFileHandler(filename="Recommend/recommend/hlg.log",
when="S", interval=10,
backupCount=20)
log_file_handler.setFormatter(formatter)
# 3. 向logger对象中添加handler
logger.addHandler(log_file_handler)
class NewsRecommendByHotValue():
def __init__(self):
self.db = self.connect()
self.cursor = self.db.cursor()
self.userlist = self.loadDBData()
# self.news_tags = self.loadFileData()
self.result = self.getRecResult()
def connect(self):
'''
@Description:数据库连接
@:param host --> 数据库链接
@:param user --> 用户名
@:param password --> 密码
@:param database --> 数据库名
@:param port --> 端口号
@:param charset --> 编码
'''
db = pymysql.Connect(host=DB_HOST, user=DB_USER, password=DB_PASSWD, database=DB_NAME, port=DB_PORT,
charset='utf8')
return db
def loadDBData(self):
'''
@Description:加载数据库用户数据
@:param None
'''
sql_s = 'select userid from news_api_user'
try:
self.cursor.execute(sql_s)
useridlist = self.cursor.fetchall()
except:
logging.error("Database Error")
self.db.rollback()
return useridlist
def getRecResult(self):
'''
@Description:加载数据库新闻热度数据并进行热度推荐
@:param None
'''
sql_s = 'select news_id,news_hot from news_api_newshot order by news_hot DESC limit 0,20;'
self.cursor.execute(sql_s)
newsidlist = self.cursor.fetchall()
print(newsidlist)
time = datetime.datetime.now().strftime("%Y-%m-%d")
for user in self.userlist:
print(user[0])
for newsid in newsidlist:
sql_w = 'insert into news_api_recommend(userid, newsid, hadread, cor, species, time) values (%d, %d, 0, %.2f, 2, \'%s\')' % \
(int(user[0]), int(newsid[0]), 1, time)
logger.info("sql_w:{}".format(sql_w))
try:
self.cursor.execute(sql_w)
self.db.commit()
except:
logger.error("rollback:{}".format(newsid[0]))
self.db.rollback()
return True
def beginrecommendbyhotvalue():
NewsRecommendByHotValue()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)