午间杂谈:深挖Wan2.2-T2V-A5B:从技术内核到企业数字人实战
Wan2.2-T2V-A5B是一款专为中文商业场景优化的文本转视频大模型,通过"文本编码+时空注意力扩散模型+A5B算力优化"三层架构,解决了传统T2V模型的中文理解差、视频跳变等问题。其核心技术包括:1)基于BERT的中文文本编码器,能理解商业风格、镜头语言等深层语义;2)时空注意力机制确保视频帧间流畅过渡;3)A5B优化使消费级显卡也能流畅运行。该模型可快速将企业文案转化为
午间杂谈:深挖Wan2.2-T2V-A5B:从技术内核到企业数字人实战
你的文案和PPT,正在被这个模型一键变成专业的企业宣传视频。
哈喽,我是你们的老朋友木斯佳,上周,我为一家公司的年终总结大会制作宣传视频。市场部给了我一页产品文档,要求在次日给出视频初稿。传统流程下,我需要协调编剧、模特、拍摄和后期团队,成本高且周期长。
但这次,我只用了3小时。上午理解产品核心,中午配置Wan2.2的JSON参数,下午就生成了一个逻辑清晰、演示生动的产品讲解视频。这家公司的CTO看完后直接问:“这个虚拟产品专家,能不能加入我们后续的线上发布会?”
这背后的核心,就是Wan2.2-T2V-A5B模型——一个专为中文商业场景优化的文本转视频大模型。
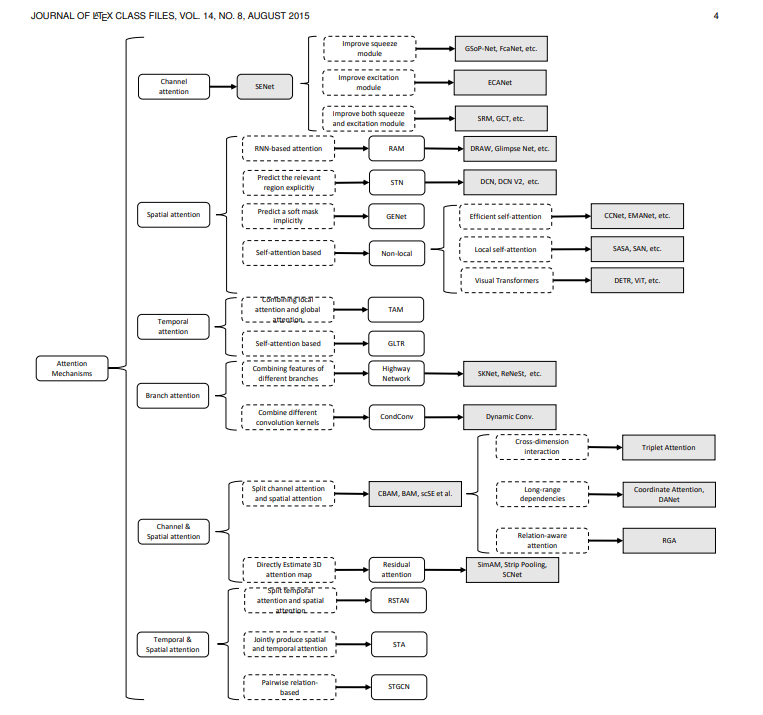
一、技术原理解析:三大核心模块如何运作
Wan2.2-T2V-A5B的核心是“文本编码+时空注意力扩散模型+A5B算力优化”三层架构。这套架构的巧妙之处在于,它不仅解决了传统T2V模型的技术瓶颈,还专门针对中文商业场景做了深度优化。
让我用一个简单的流程图帮你理解它的工作过程:
下面我们来深入看看这个流程中的三个关键模块是如何工作的:
1. 中文文本编码器:商业文案的“理解大脑”
传统T2V模型最大的痛点是什么?中文理解能力差。当你输入“打造智能化解决方案”时,英文模型可能生成一堆不相关的科技图标,而Wan2.2却能精准理解为“展示企业数字化转型场景”。
看看它的核心代码实现:
class WanTextEncoder(nn.Module):
"""Wan2.2核心:中文文本编码器(BERT扩展,教育/广告场景适配)"""
def __init__(self):
super().__init__()
# 基于bert-base-chinese,这是关键!
self.tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
self.bert = BertModel.from_pretrained("bert-base-chinese").to(DEVICE)
# 多特征投影层:这是商业场景的秘诀
self.style_proj = nn.Linear(768, 256).to(DEVICE) # 风格:科技感/亲和力
self.camera_proj = nn.Linear(768, 128).to(DEVICE) # 镜头:特写/全景
self.time_proj = nn.Linear(768, 64).to(DEVICE) # 时长:15秒快剪/30秒详述
self.fusion = nn.Linear(768+256+128+64, 1024).to(DEVICE) # 特征融合
这个编码器的聪明之处在于,它不只是理解文字表面意思,还能理解:
- 商业风格:“科技感”会生成蓝色调、数据流可视化;“亲和力”则生成暖色调、人物微笑互动
- 镜头语言:“产品特写”会给产品细节放大;“团队全景”会展示协作场景
- 时长适配:15秒视频节奏快、画面切换迅速;30秒视频则会有更多解说镜头
2. 时空注意力机制:告别“PPT式”视频
企业最怕什么?生成出来的视频像幻灯片一样一帧一帧跳变。Wan2.2的时空注意力机制解决了这个问题:
class SpatioTemporalAttention(Attention):
"""Wan2.2核心:时空注意力(帧间一致性关键)"""
def forward(self, hidden_states, encoder_hidden_states=None, frame_num=None):
batch, num_frames, seq_len, hidden_dim = hidden_states.shape
# 1. 空间注意力:单帧内像素关联(保证产品细节清晰)
hidden_states = hidden_states.reshape(batch * num_frames, seq_len, hidden_dim)
spatial_attn_output = super().forward(hidden_states, encoder_hidden_states)
# 2. 时间注意力:帧与帧关联(产品演示流畅不跳变)
spatial_attn_output = spatial_attn_output.reshape(batch, num_frames, seq_len, hidden_dim)
temporal_input = spatial_attn_output.permute(0, 2, 1, 3).reshape(batch * seq_len, num_frames, hidden_dim)
# 时间维度的注意力计算
q, k, v = self.to_q(temporal_input), self.to_k(temporal_input), self.to_v(temporal_input)
attn_weights = torch.bmm(q, k.transpose(1, 2))
attn_weights = F.softmax(attn_weights, dim=-1)
temporal_attn_output = torch.bmm(attn_weights, v)
return temporal_attn_output
这个机制确保:
- 产品演示时:虚拟人物的手势从指向A功能平滑过渡到B功能
- 数据展示时:图表的变化是渐变而非突变
- 场景转换时:有自然的过渡效果而非硬切
3. A5B算力优化:企业也能用得起的AI
企业不是科研机构,没有A100集群。Wan2.2的A5B优化让RTX 3060这样的消费级显卡也能流畅运行:
class A5BOptimizer:
"""Wan2.2核心:A5B算力优化(低显卡适配关键)"""
def optimize_inference(self, noisy_latents, text_embeds, timestep):
# 张量切片:将视频帧分块推理(3060 12G建议slice_size=4)
frame_slices = torch.split(noisy_latents, self.slice_size, dim=1)
noise_pred_slices = []
for frame_slice in frame_slices:
with torch.no_grad():
# 分块处理,显存占用降低50%+
noise_pred_slice = self.model(frame_slice, text_embeds, timestep)
noise_pred_slices.append(noise_pred_slice)
# 拼接切片结果,还原完整视频
noise_pred = torch.cat(noise_pred_slices, dim=1)
# 显存复用:及时释放中间变量
torch.cuda.empty_cache()
return noise_pred
这意味着什么?中小企业不用投资数十万建AI服务器,用现有的办公电脑或普通工作站就能部署。
二、企业数字人实战:从文案到视频的完整流程
下面我以“制作产品宣传数字人视频”为例,展示完整的实战流程。如果想定制形象,可以参考lite-avatar形象库。
步骤1:配置文件设计(JSON即脚本)
{
"video_id": "saas_ai_predict_001",
"project": "智能预测模块宣传片",
"target_audience": "企业决策者",
"duration": 45,
"resolution": [1080, 1920],
"digital_human": {
"appearance": "30-35岁专业男性,商务休闲装,自信微笑",
"voice_setting": {
"type": "专业男声",
"speed": 1.1,
"tone": "自信且亲和",
"pauses": [{"text_segment": "核心功能", "pause_duration": 0.5}]
},
"gesture_plan": [
{"time_range": [5, 10], "gesture": "单手前伸介绍", "target": "产品主界面"},
{"time_range": [15, 22], "gesture": "双手展开示意", "target": "数据可视化大屏"}
]
},
"content_flow": [
{
"segment": "开场痛点",
"duration": 8,
"visual": "企业决策者面对复杂数据犹豫不决的场景",
"script": "在数据爆炸的时代,企业决策是否还在凭经验?"
},
{
"segment": "解决方案引入",
"duration": 12,
"visual": "数字人侧身展示产品界面,关键功能高亮",
"script": "我们的AI智能预测模块,能帮助您从海量数据中发现规律。",
"highlight_element": {
"type": "animated_text",
"content": "预测准确率达92%",
"effect": "渐变浮现+脉冲高亮"
}
},
{
"segment": "核心功能演示",
"duration": 18,
"visual": "产品界面操作流程动态演示,数据图表实时变化",
"script": "只需三步:导入数据、选择模型、查看预测结果。复杂分析,简单操作。"
},
{
"segment": "价值主张与CTA",
"duration": 7,
"visual": "数字人直面镜头,背景出现客户logo墙",
"script": "已助力500+企业实现数据驱动决策。立即申请演示,开启智能决策之旅。"
}
],
"branding_elements": {
"logo": {
"position": "top_right",
"show_throughout": true,
"opacity": 0.8
},
"color_scheme": "#1E88E5(主色),#FFC107(强调色)",
"lower_third": {
"enabled": true,
"template": "产品名称:AI智能预测模块 | 优势:零代码部署"
}
},
"post_processing": {
"bgm": "corporate_tech_optimistic.mp3",
"volume_mix": {"voice": 1.0, "bgm": 0.15, "effects": 0.3},
"color_grading": "tech_blue_cool"
}
}
步骤2:多模态融合(语音+视觉+品牌)
Wan2.2的强大之处在于原生多模态支持,无需组合多个工具:
def generate_enterprise_video(config):
"""企业宣传视频完整生成流程"""
# 1. 视频画面生成(核心)
print("步骤1/4:生成数字人视频画面...")
video_path = wan22_inference.generate(
prompt=build_prompt_from_config(config),
duration=config["duration"],
resolution=config["resolution"]
)
# 2. 专业语音合成
print("步骤2/4:生成专业解说音频...")
tts_engine = EnterpriseTTS(config["digital_human"]["voice_setting"])
audio_path = tts_engine.generate_audio(
extract_script_from_config(config),
style="corporate_presentation"
)
# 3. 品牌元素叠加
print("步骤3/4:叠加品牌视觉元素...")
brand_overlay = BrandIntegrationEngine(config["branding_elements"])
video_with_brand = brand_overlay.apply(
video_path,
audio_path, # 音画同步参考
config["content_flow"]
)
# 4. 后期合成
print("步骤4/4:最终合成与优化...")
final_video = post_process.enhance(
video_with_brand,
color_grading=config["post_processing"]["color_grading"],
audio_mix=config["post_processing"]["volume_mix"]
)
return final_video
步骤3:专业语音合成配置
企业视频的语音要求与教育视频不同,需要更专业的语调:
class EnterpriseTTS:
"""企业级语音合成(商务场景专用)"""
def __init__(self, voice_config):
self.voice_type = voice_config["type"]
self.speed = voice_config["speed"]
# 企业专用音色映射
self.corporate_voice_map = {
"专业男声": {"api_voice": "aisxping", "pitch": "medium", "style": "narrative"},
"专业女声": {"api_voice": "aisjinger", "pitch": "medium-high", "style": "authoritative"},
"亲和力解说": {"api_voice": "xiaoyan", "pitch": "medium", "style": "conversational"}
}
def generate_business_audio(self, script, style="corporate"):
"""生成商务风格语音"""
# 企业脚本预处理
processed_script = self._preprocess_business_script(script)
# 关键参数:企业语音需要更稳定的语速和清晰的断句
tts_params = {
"voice": self.corporate_voice_map[self.voice_type]["api_voice"],
"speed": self.speed * 50, # 企业推荐1.0-1.2倍速
"pitch": self.corporate_voice_map[self.voice_type]["pitch"],
"volume": 100,
"emotion": "neutral" if style == "corporate" else "friendly"
}
return self._call_tts_api(processed_script, tts_params)
def _preprocess_business_script(self, script):
"""企业脚本专用预处理"""
# 1. 专业术语保护(确保"SaaS"、"API"等发音正确)
protected_terms = {"SaaS": "萨斯", "API": "A-P-I", "UI": "U-I"}
for term, pronunciation in protected_terms.items():
script = script.replace(term, pronunciation)
# 2. 关键数据强调(给数字添加语音标记)
import re
script = re.sub(r'(\d+%?)', r'<emphasis level="strong">\1</emphasis>', script)
# 3. 自然停顿插入(在句号和关键连接词后)
pause_points = ["。", ";", ":", "——", "而", "但是", "因此"]
for point in pause_points:
script = script.replace(point, point + "<break time='300ms'/>")
return script
三、企业级优化技巧:质量与效率的平衡
1. 批量生成工作流
企业往往需要制作系列视频或不同版本,批量生成能力至关重要:
def batch_enterprise_videos(product_line, template_config):
"""批量生成产品线宣传视频"""
results = []
for product in product_line:
print(f"开始生成产品视频:{product['name']}")
# 动态适配配置
product_config = adapt_template_for_product(template_config, product)
# 生成视频(可并行化)
video_path = generate_enterprise_video(product_config)
# 自动质量检查
quality_report = quality_check(video_path, product_config)
results.append({
"product": product["name"],
"video_path": video_path,
"duration": product_config["duration"],
"quality_score": quality_report["score"],
"generation_time": quality_report["generation_time"]
})
# 智能缓存:相似产品复用中间结果
cache_intermediate_results(product_config)
# 生成批量报告
generate_batch_report(results)
return results
2. 质量调优参数
针对企业视频的特殊需求,这些参数调整很关键:
# enterprise_quality_tuning.yaml
高级质量参数:
视频流畅度:
时间注意力温度系数: 0.7 # 更低的值=更稳定的帧间关系
运动一致性权重: 1.5 # 企业视频需要更平稳的镜头运动
视觉清晰度:
企业logo保护: 开启 # 确保logo在任何帧都清晰
文字可读性增强: 开启 # 特别针对数据图表中的小字
音频专业度:
去除口语填充词: 开启 # 自动移除"嗯"、"啊"等
专业术语词典: "./configs/business_terms.txt"
音量标准化: 符合ITU-R BS.1770-4标准
品牌一致性:
颜色容差: 严格 # 确保品牌色准确
字体渲染: 抗锯齿最高 # 确保文字边缘平滑
元素位置公差: ±5像素 # 品牌元素位置精准
3. 低显存环境优化
即使只有RTX 3060 12GB,也能通过以下配置生成高质量企业视频:
# 3060_12G_optimized_config.py
OPTIMIZATION_PROFILE = {
"resolution_strategy": "adaptive",
# 第一阶段:低分辨率生成故事板
"stage1": {
"resolution": [540, 960],
"denoise_steps": 25,
"slice_size": 4,
"purpose": "快速预览与节奏确认"
},
# 第二阶段:关键片段高质量重制
"stage2": {
"resolution": [1080, 1920],
"denoise_steps": 40,
"slice_size": 2,
"target_segments": ["product_demo", "cta"], # 只对关键部分高质
"memory_management": "aggressive" # 积极释放显存
},
# 第三阶段:最终合成
"stage3": {
"upscaling": "smart", # 智能超分而非全程高分辨率
"color_uniformity": True # 确保不同分辨率片段色调一致
}
}
四、企业数字人的进阶应用
1. 个性化客户演示视频
想象一下:销售团队可以为每个潜在客户生成个性化的产品演示视频:
def personalized_demo_video(client_profile, product_config):
"""生成针对特定客户的个性化演示视频"""
# 分析客户画像
client_analysis = analyze_client_profile(client_profile)
# 动态调整脚本
personalized_script = adapt_script_for_client(
base_script=product_config["script"],
client_industry=client_analysis["industry"],
client_pain_points=client_analysis["pain_points"],
mentioned_competitors=client_analysis["known_competitors"]
)
# 调整视觉风格
visual_style = select_visual_style_for_industry(client_analysis["industry"])
# 插入客户专属元素
if client_analysis["company_name"]:
personalized_config = insert_client_references(
product_config,
company_name=client_analysis["company_name"],
industry_examples=client_analysis["industry_examples"]
)
# 生成视频
return generate_enterprise_video(personalized_config)
2. 数据驱动的内容更新
企业的产品数据和客户案例经常更新,视频内容也需要同步:
class DataDrivenVideoUpdater:
"""数据驱动的企业视频自动更新系统"""
def __init__(self, base_video_config, data_sources):
self.base_config = base_video_config
self.data_sources = data_sources # API、数据库等
def check_and_update_video(self):
"""检查数据变化并更新视频"""
# 监控关键数据点
changed_data = self.monitor_data_changes([
"user_count", "success_cases", "feature_updates",
"performance_metrics", "client_testimonials"
])
if changed_data:
print(f"检测到{len(changed_data)}处数据更新,开始视频更新...")
# 智能判断更新范围
update_scope = self.determine_update_scope(changed_data)
if update_scope == "minor":
# 小更新:只替换数据图表
updated_video = self.partial_update_data_visualizations(changed_data)
elif update_scope == "medium":
# 中更新:更新相关片段
updated_video = self.update_related_segments(changed_data)
else: # major
# 大更新:重新生成核心部分
updated_video = self.regenerate_core_sections(changed_data)
return updated_video
return None # 无更新
五、为什么选择Wan2.2:企业级对比分析
| 评估维度 | Wan2.2-T2V-A5B | 传统视频制作 | 国际AI工具(如Runway) |
|---|---|---|---|
| 中文商业理解 | ⭐⭐⭐⭐⭐ 基于BERT中文优化,理解商业术语 |
⭐⭐⭐⭐ 依赖编剧个人能力 |
⭐⭐ 英文思维,中文常出错 |
| 品牌一致性 | ⭐⭐⭐⭐⭐ JSON配置确保每次生成一致 |
⭐⭐⭐ 不同团队、时间点有差异 |
⭐⭐⭐ Prompt控制,但稳定性一般 |
| 制作速度 | ⭐⭐⭐⭐⭐ 小时级别,支持批量 |
⭐⭐ 周级别,沟通成本高 |
⭐⭐⭐⭐ 较快,但中文优化差 |
| 定制灵活性 | ⭐⭐⭐⭐⭐ 配置化调整,快速迭代 |
⭐⭐⭐⭐ 灵活但成本高 |
⭐⭐⭐ 依赖Prompt工程 |
| 成本效益 | ⭐⭐⭐⭐⭐ 一次投入,无限生成 |
⭐ 每次制作都需要预算 |
⭐⭐⭐ 按量付费,长期成本高 |
| 技术门槛 | ⭐⭐⭐⭐ 需要技术配置,但有GUI工具 |
⭐⭐⭐⭐⭐ 任何人可参与 |
⭐⭐ 需要Prompt工程技能 |
| 多模态集成 | ⭐⭐⭐⭐⭐ 原生支持语音、字幕、品牌元素 |
⭐⭐⭐ 需要多工具配合 |
⭐⭐⭐ 基础支持,需额外工具 |
结语:企业内容生产的新范式
在效率与质量的天平上,Wan2.2找到了一个巧妙的平衡点——既不是牺牲质量的简单自动化,也不是高不可攀的影视级制作。
对于前端开发者而言,理解这套系统的价值在于:我们看到了如何将复杂算法封装为可配置的商务工具。这不正是我们一直在做的事情吗?将复杂的技术封装成简单易用的界面和API。
下一次当你需要制作产品演示、培训材料或客户案例视频时,不妨思考:这真的需要传统拍摄吗?还是一次配置、多次生成的数字人解决方案更合适?
毕竟,在这个快速变化的时代,能跟上产品迭代速度的,或许不是最专业的摄像机,而是最懂你业务的AI模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)