POC避坑指南|VectorDBBench自定义数据集测试实战教程
本文介绍了企业在大模型落地过程中面临的向量数据库选型难题,指出传统测试数据集(如SIFT)与真实业务场景存在维度差异,导致性能评估失真。为解决这一问题,文章推荐使用真实业务数据进行测试,并详细介绍了Zilliz团队开源的VectorDBBench工具。该工具支持多种数据库性能评测,允许用户接入自定义数据集。文章提供了从数据准备到测试的完整指南,包括如何将CSV/NPY格式数据转换为符合要求的Par

本文是 “向量数据库 POC 指南” 的系列文章之一。
大模型落地,如何做配套的技术设施选型,已经成为了困扰很多企业的一大难题。但哪怕只是一个向量数据库,纸面参数就已经膨胀到需要重新统一度量衡。这些被吹的天花乱坠的成绩,往往会干扰企业的判断, 甚至导致企业浪费了大量企业的人力、物力之后,后期产品性能掉链子、运维一堆麻烦、成本越花越高…… 全部推倒重来。
在这个过程中,一个更科学、更符合实际生产的POC 可以帮我们规避大部分问题。
那如何做好POC?接下来,我们将产出“向量数据库 POC 指南” 系列文章,对 POC 环节的重点问题做逐一拆解,本文为该系列的第一篇文章。
文|Zilliz 黄金写手蔡一凡
正文
企业大模型落地,做POC的时候最怕什么?
答案是,供应商给的参数都是真的,但成绩都是基于 SIFT、GloVe、LAION 这些老旧数据集刷出来的,但生产上用的都是最新的模型,性能效果完全不一样。
比如,SIFT是向量数据库领域的常见测试数据集,其向量数据维度 是128 维,而 OpenAI、Cohere 的主流模型的embedding模型维度是 768~3072 维。也就是说,主流benchmark的测试结果,对真实业务场景已经失去参考意义。

而这些差异可能导致:
-
QPS(查询吞吐量)和延迟在业务数据上与测试数据差别很大
-
Recall(召回率) 受向量分布影响,可能和真实效果不一致
-
索引构建、内存占用等成本评估不准确
更多数据集老旧导致的测试问题,详见历史文章:开源|VDBBench 1.0正式官宣,完全复刻业务场景,支持用户自定义数据集
而解决问题的办法也很简单,那就是使用业务里真实产生的向量数据测试,也就是用自定义数据集。
但如何实操呢?
Zilliz 团队开源的VectorDBBench 向量数据库性能评测工具,支持多种数据库(Milvus、Elasticsearch、pgvector 等)和真实模拟生产中的流量特征(比如边插入边查询),并允许用户接入自定义数据集,这就很符合我们的需求了。
接下来,我们将手把手教你如何用VectorDBBench 基于真实数据,完成一场高质量的POC。
01
准备工作
-
安装与环境要求
-
Python >= 3.11
-
安装
可选仅安装 Milvus/Zilliz Cloud 客户端:
pip install vectordb-bench
pip install vectordb-bench
也可安装所有支持的数据库客户端(如需对比多种数据库):
pip install vectordb-bench[all]
pip install vectordb-bench[all]
或者安装指定数据库客户端(如 Elasticsearch):
pip install vectordb-bench[elastic]
pip install vectordb-bench[elastic]
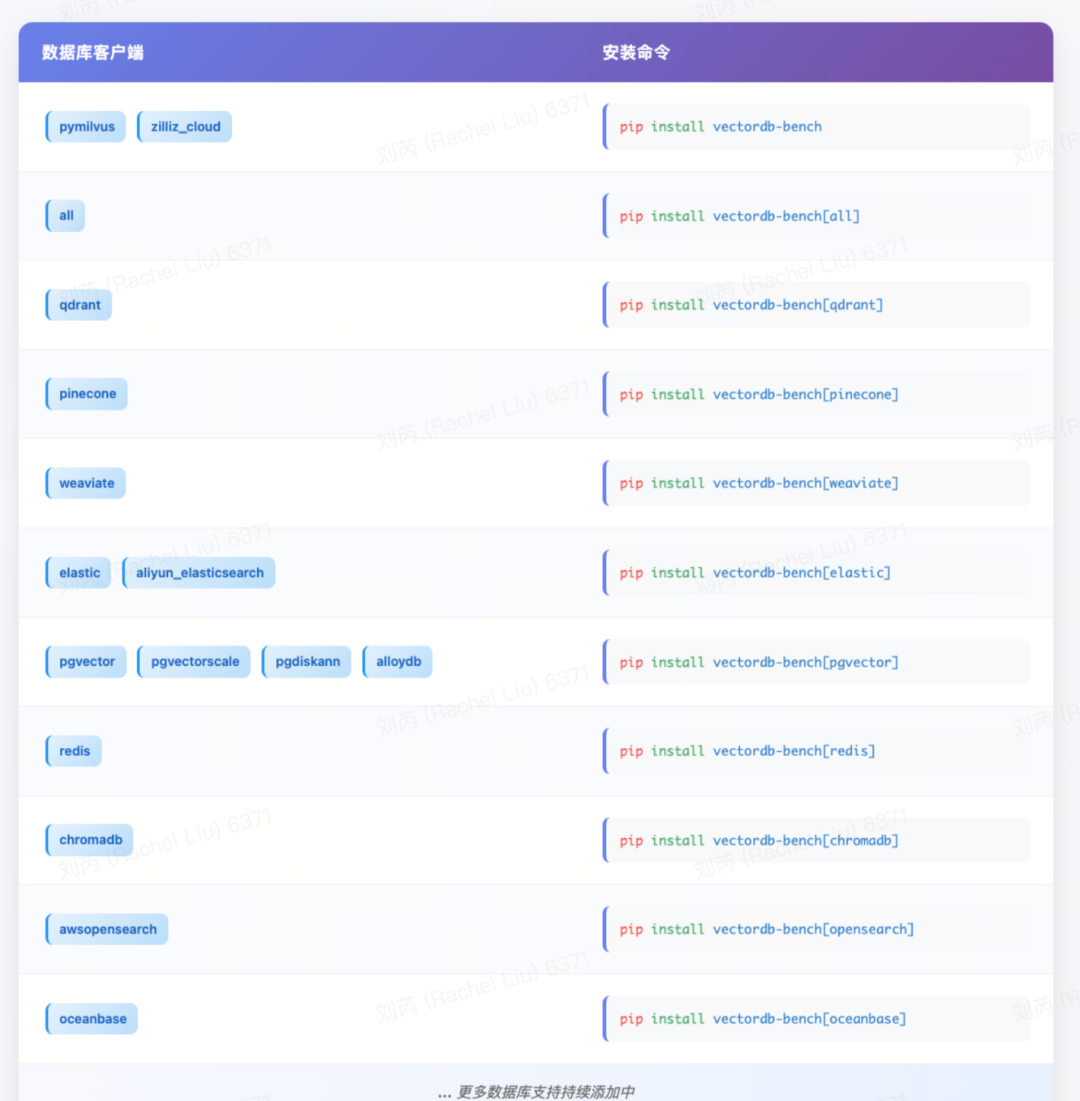
支持的数据库客户端及安装命令如下:
- 启动
安装完成后,直接运行:
init_bench
init_bench
默认会启动本地 Web 服务:
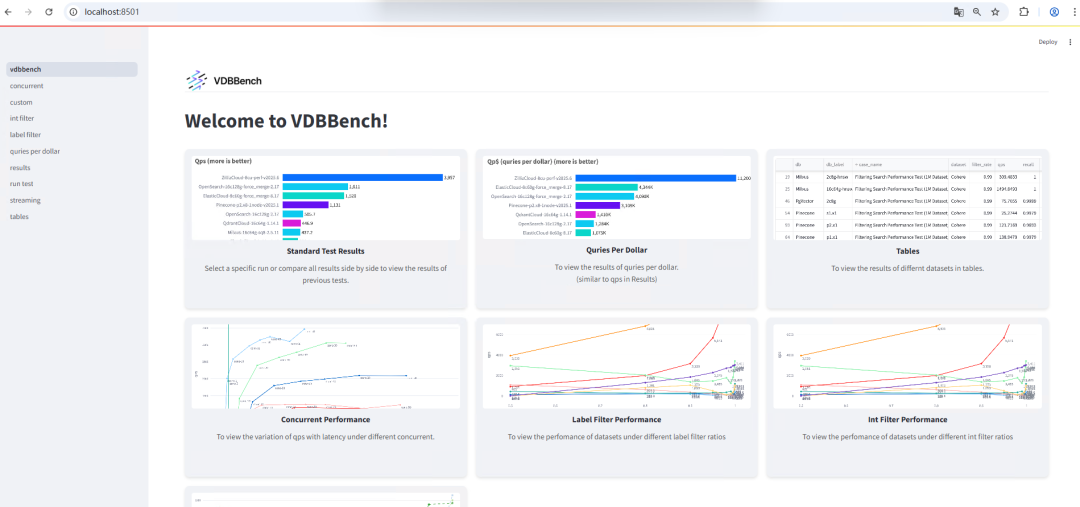
界面示例:
02
准备自定义数据集
(1) VectorDBBench 支持的数据格式
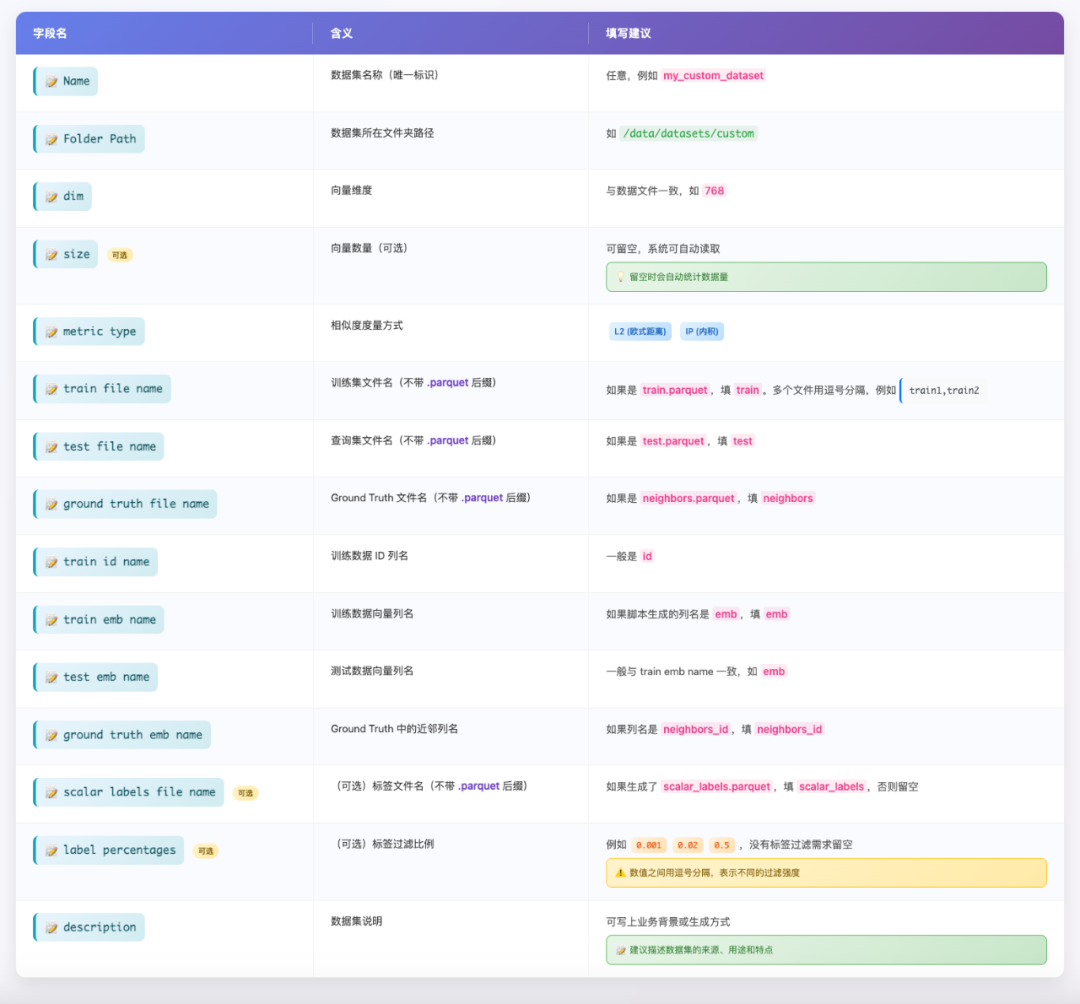
VectorDBBench 官方要求的数据集必须是 特定结构的 Parquet 文件,通常包括:

向量数据要求:
-
训练向量文件(train.parquet)
-
必须包含:id(递增整数)、 向量列(如 emb,类型为 float32 数组)
-
列名可以自定义
-
测试向量文件(test.parquet)
-
必须包含:id(递增整数)、向量列(如 emb)
-
注意:id 列名必须是 id,向量列名可自定义
-
Ground Truth 文件(neighbors.parquet)
-
必须包含: id(对应测试向量 ID)、近邻 ID 数组列(如 neighbors_id)
-
id 列名必须是 id
-
(可选)标签文件(scalar_labels.parquet)
-
必须包含:id(对应训练向量 ID)、 labels (标量字符串)
(2)普通用户面临的困难
虽然 Parquet 格式和结构有明确要求,但大多数业务数据是:
-
存在 CSV 文件(向量以字符串形式存储)
-
存在 NPY 文件(纯向量矩阵,没有 ID、标签)
-
存在 数据库表(MySQL、MongoDB 中存储的 embedding)
这些格式和 VectorDBBench 直接使用的 Parquet 文件差异较大,普通用户要自己生成符合规范的 train/test/ground truth 三个文件会遇到:
-
格式转换难(CSV/NPY → Parquet,需要代码)
-
Ground Truth 计算难(需要用 FAISS 或其他库做精确 KNN 检索)
-
数据切分麻烦(区分 train/test,并保证匹配关系正确)
(3)解决方案:一键生成工具脚本
为了简化流程,笔者准备了一个 Python 脚本,可以将 用户已有的 CSV 或 NPY 数据 一键转换成 VectorDBBench 能直接识别的完整数据集目录,包括:
train.parquet
test.parquet
neighbors.parquet
(可选)
scalar_labels.parquet
优势:
-
支持 CSV 和 NPY 两种输入
-
自动切分 train/test 数据
-
自动生成 Ground Truth(精确搜索计算)
-
可自定义
top_k、相似度度量方式(L2 / Inner Product)
(4) 脚本输入要求
脚本接受两种输入形式:
格式一:CSV 格式
-
第一列为 id(唯一标识符)
-
第二列为 vector(字符串形式的浮点数组,如
[0.1, 0.2, 0.3, ...]) -
其他列可选(metadata、标签)
示例:
id,emb,label1,"[0.12,0.56,0.89,...]",A2,"[0.33,0.48,0.90,...]",B
id,emb,label
1,"[0.12,0.56,0.89,...]",A
2,"[0.33,0.48,0.90,...]",B
格式二:NPY 格式
-
一个二维数组,shape =
(num_vectors, dim) -
向量顺序默认从 0 开始分配 id
-
标签可单独提供一个 CSV(id,label)
示例:
import numpy as npvectors = np.random.rand(10000, 768).astype('float32')np.save("vectors.npy", vectors)
import numpy as np
vectors = np.random.rand(10000, 768).astype('float32')
np.save("vectors.npy", vectors)
(5)运行脚本
- 安装依赖:
pip install numpy pandas faiss-cpu
pip install numpy pandas faiss-cpu
- 启动命令:
python convert_to_vdb_format.py \ --train data/train.csv \ --test data/test.csv \ --out datasets/custom \ --topk 10
python convert_to_vdb_format.py \
--train data/train.csv \
--test data/test.csv \
--out datasets/custom \
--topk 10
-
参数说明:

(6)输出目录结构
import os
import argparse
import numpy as np
import pandas as pd
import faiss
from ast import literal_eval
from typing import Optional
def load_csv(path: str):
df = pd.read_csv(path)
if 'emb' not in df.columns:
raise ValueError(f"CSV 文件中缺少 'emb' 列:{path}")
df['emb'] = df['emb'].apply(literal_eval)
if 'id' not in df.columns:
df.insert(0, 'id', range(len(df)))
return df
def load_npy(path: str):
arr = np.load(path)
df = pd.DataFrame({
'id': range(arr.shape[0]),
'emb': arr.tolist()
})
return df
def load_vectors(path: str) -> pd.DataFrame:
if path.endswith('.csv'):
return load_csv(path)
elif path.endswith('.npy'):
return load_npy(path)
else:
raise ValueError(f"不支持的文件格式: {path}")
def compute_ground_truth(train_vectors: np.ndarray, test_vectors: np.ndarray, top_k: int = 100):
dim = train_vectors.shape[1]
index = faiss.IndexFlatL2(dim)
index.add(train_vectors)
_, indices = index.search(test_vectors, top_k)
return indices
def save_ground_truth(df_path: str, indices: np.ndarray):
df = pd.DataFrame({
"id": np.arange(indices.shape[0]),
"neighbors_id": indices.tolist()
})
df.to_parquet(df_path, index=False)
print(f"✅ Ground truth 保存成功: {df_path}")
def main(train_path: str, test_path: str, output_dir: str,
label_path: Optional[str] = None, top_k: int = 10):
os.makedirs(output_dir, exist_ok=True)
# 加载训练和查询数据
print("📥 加载训练数据...")
train_df = load_vectors(train_path)
print("📥 加载查询数据...")
test_df = load_vectors(test_path)
# 向量提取并转换为 numpy
train_vectors = np.array(train_df['emb'].to_list(), dtype='float32')
test_vectors = np.array(test_df['emb'].to_list(), dtype='float32')
# 保存保留所有字段的 parquet 文件
train_df.to_parquet(os.path.join(output_dir, 'train.parquet'), index=False)
print(f"✅ train.parquet 保存成功,共 {len(train_df)} 条记录")
test_df.to_parquet(os.path.join(output_dir, 'test.parquet'), index=False)
print(f"✅ test.parquet 保存成功,共 {len(test_df)} 条记录")
# 计算 ground truth
print("🔍 计算 Ground Truth(最近邻)...")
gt_indices = compute_ground_truth(train_vectors, test_vectors, top_k=top_k)
save_ground_truth(os.path.join(output_dir, 'neighbors.parquet'), gt_indices)
# 加载并保存标签文件(如果有)
if label_path:
print("📥 加载标签文件...")
label_df = pd.read_csv(label_path)
if 'labels' not in label_df.columns:
raise ValueError("标签文件中必须包含 'labels' 列")
label_df['labels'] = label_df['labels'].apply(literal_eval)
label_df.to_parquet(os.path.join(output_dir, 'scalar_labels.parquet'), index=False)
print("✅ 标签文件已保存为 scalar_labels.parquet")
if
name
== "__main__":
parser = argparse.ArgumentParser(description="将CSV/NPY向量转换为VectorDBBench数据格式 (保留所有列)")
parser.add_argument("--train", required=True, help="训练数据路径(CSV 或 NPY)")
parser.add_argument("--test", required=True, help="查询数据路径(CSV 或 NPY)")
parser.add_argument("--out", required=True, help="输出目录")
parser.add_argument("--labels", help="标签CSV路径(可选)")
parser.add_argument("--topk", type=int, default=10, help="Ground truth")
args = parser.parse_args()
main(args.train, args.test, args.out, args.labels, args.topk)
(8)使用示例
- 脚本输出:

- 文件输出:

03
加载自定义数据集
在第二章中,我们已经用脚本生成了符合 VectorDBBench 要求的 Custom 数据集目录(train.parquet, test.parquet, neighbors.parquet 等)。 接下来,我们将在 VectorDBBench Web UI 中加载并运行测试。
- 进入 Web UI 首页,选择主页中的 Custom Dataset:
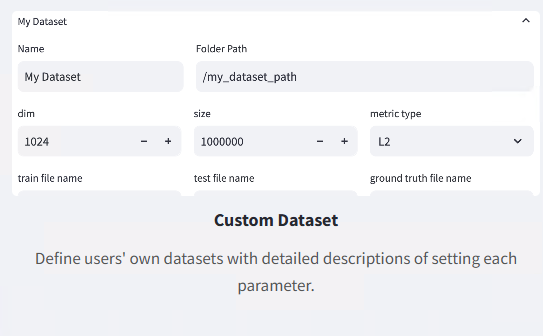
- 选择之后,我们可以看到 Custom Dataset 相关的解释以及需要填写的内容:
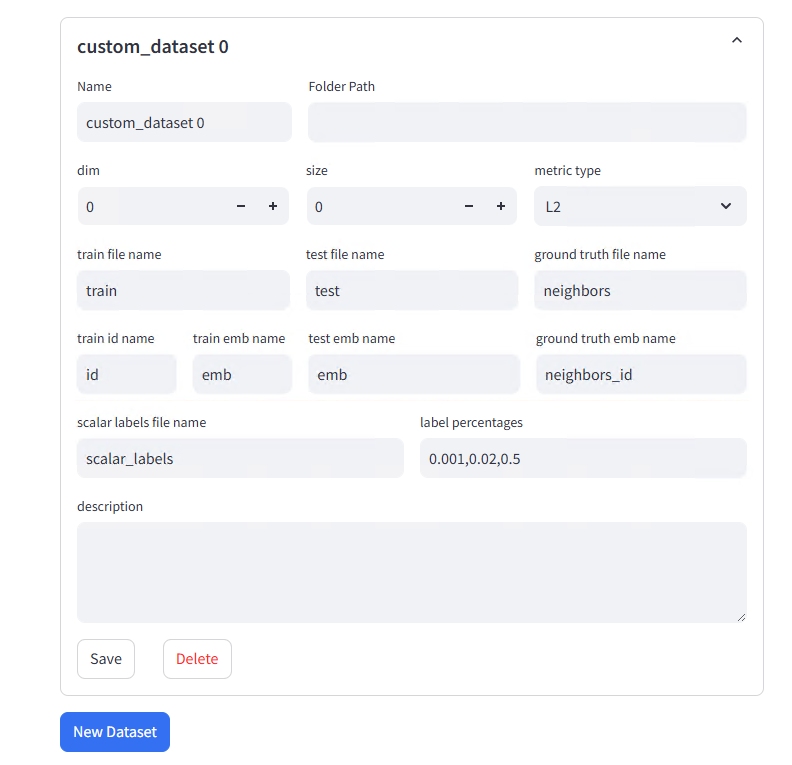
-
参数详解
-
点击 Save 保存。
04
配置测试方案并运行测试
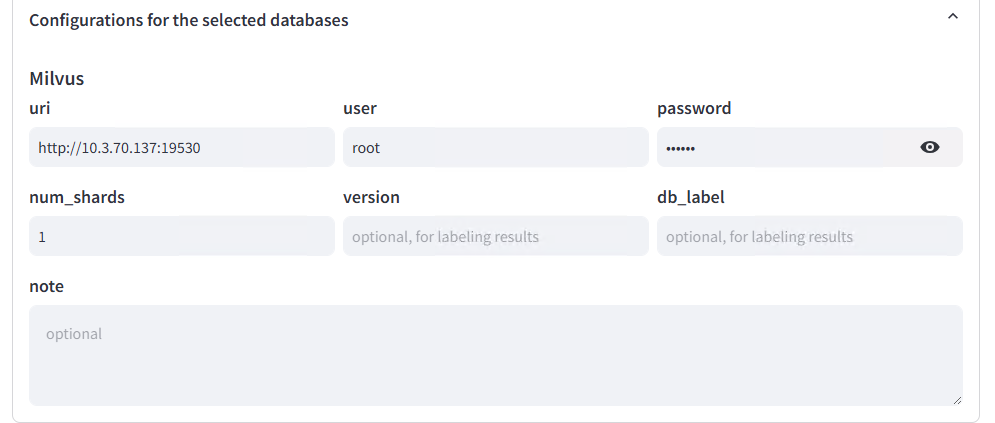
- 在 Web UI 中进入 Run Test 页面:

- 勾选并填写要测试的向量数据库,本文以 milvus 为例:
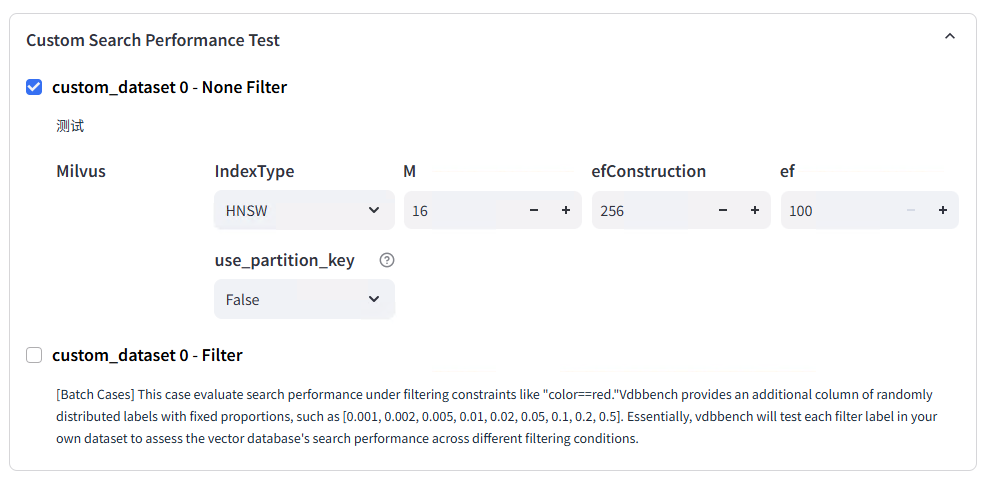
- 选择我们创建的 Custom 数据集:
- 设置任务标签
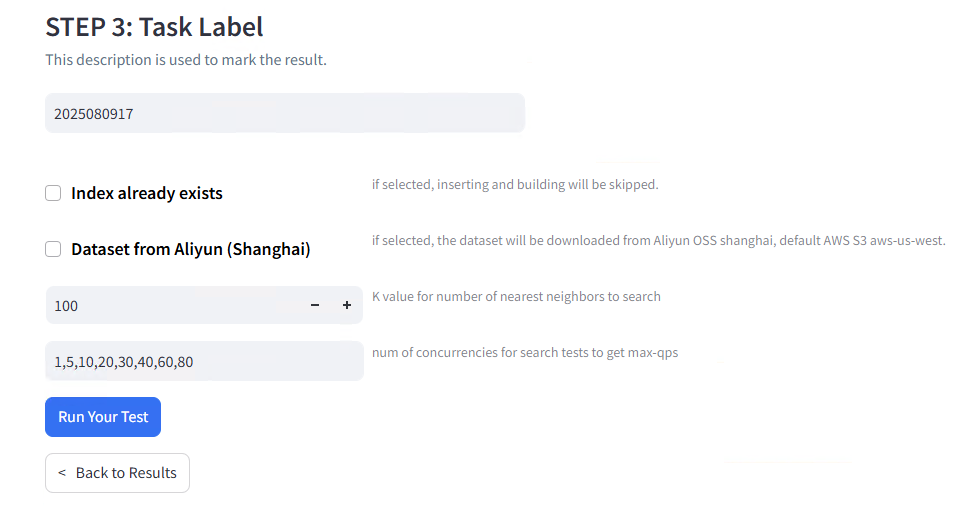
- 开始测试

05
查看结果
在 Web UI 的 Results 页面,可以看到测试结果:
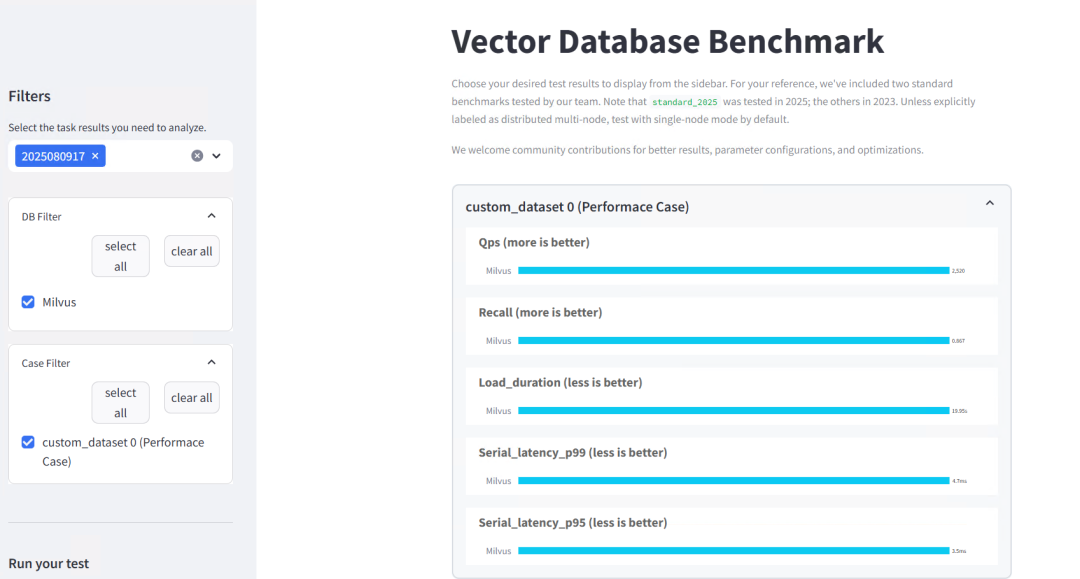
测试说明:
-
并发度:由于测试机器性能有限,本次仅测试了 1、5、10 三种并发情况
-
测试数据集:
-
维度:768
-
数量:train 和 test 各 3000 条向量
-
标量标签:未使用
06
踩坑与经验
-
维度不一致会直接报错 → 确保 train/test 文件维度相同
-
Ground Truth 必须匹配 test 文件 → 否则 Recall 计算错误
-
数据量太小 → QPS 测试结果波动大,建议至少几万条向量
-
Docker 资源限制 → 测试大规模数据时,增加内存和 CPU 配额
-
要注意 VectorDBBench 输出的日志,可能在任务中报错了,Web UI 中没有提示
-
本文也适用于不同数据库之间的横向对比
07
总结
本文通过对 VectorDBBench 自定义(Custom)数据集测试全流程的详细讲解,展示了如何将业务真实向量数据高效转换为符合 VectorDBBench 标准的数据格式,并在其 Web UI 中完成全流程性能测试。
相比于使用官方默认数据集,基于业务场景的自定义数据集测试能够更准确地反映实际生产环境中的性能表现,包括查询吞吐量(QPS)、延迟、召回率以及索引构建等关键指标,帮助我们更科学地评估和优化向量数据库的部署方案。
此外,借助本文提供的一键转换脚本,用户能够轻松解决格式转换、数据切分和 Ground Truth 计算等常见难题,大幅降低自定义测试的门槛,实现高效、可重复的性能验证流程。
未来,随着向量数据库应用场景的不断丰富,定制化性能测试的重要性将愈发凸显。希望本实践经验能够为广大开发者和运维人员在向量数据库落地过程中提供实用参考和技术支持,推动行业整体性能测试水平的提升。
08
彩蛋
如果只是想生成指定条数和维度的人造数据集,那么可以使用以下代码来生成:
import pandas as pd
import numpy as np
def generate_csv(num_records: int, dim: int, filename: str):
ids = range(num_records)
vectors = np.random.rand(num_records, dim).round(6) # 保留6位小数
emb_str = [str(list(vec)) for vec in vectors]
df = pd.DataFrame({
'id': ids,
'emb': emb_str
})
df.to_csv(filename, index=False)
print(f"生成文件 {filename} ,共 {num_records} 条数据,向量维度 {dim}")
if
name
== "__main__":
num_records = 3000 # 生成数据的数量
dim = 768 # 向量维度
generate_csv(num_records, dim, "train.csv")
generate_csv(num_records, dim, "test.csv")
关于如何做向量数据库POC,大家还有哪些问题或者建议,欢迎评论区指出,点赞前三,将送出milvus神秘纪念品一份。
作者介绍

Zilliz 黄金写手:蔡一凡
推荐阅读
Manus、LangChain一手经验:先别给Multi Agent判死刑,是你不会管理上下文
Agent 还是 Workflow?其实80%的agent需求可以用Workflow搞定
ES vs Milvus vs PG vector :LLM时代的向量数据库选型指南



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)