【ACP-LLM】RAG篇 2
本章介绍了如何使用LlmaIndex创建一个简单的RAG应用,以回答私域问题。
准备工作
构建应用前的准备工作请参见上一节。
2.2 创建一个简单的 RAG 应用
第一步:解析文件
LlamaIndex提供了SimpleDirectoryReader方法,可以直接将指定文件夹中的文件加载为document对象,对应着解析过程.。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader('docs').load_data()
第二步:创建索引
VectorStoreIndex.from_documents方法包含切片与建立索引步骤。
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
index = VectorStoreIndex.from_documents(
documents,
embed_model=DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2
))
文本向量模型使用Qwen TEXT_EMBEDDING_V2,你也可以使用阿里云提供的其它embedding模型。
注
DashScopeTextEmbeddingModels枚举常量目前只支持到text-embedding-v3,而阿里最新的文本向量模型为text-embedding-v4,静待后期更新。
第三步:创建提问引擎
采用流式输出:
from dotenv import load_dotenv, find_dotenv
from llama_index.llms.openai_like import OpenAILike
query_engine = index.as_query_engine(
streaming=True,
llm=OpenAILike(
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
is_chat_model=True
))
此处使用 qwen-plus 模型,你也可以使用阿里云提供的其它 qwen 的文本生成模型。
第四步:生成回复
streaming_response = query_engine.query('我们公司项目管理应该用什么工具')
print("回答是:")
streaming_response.print_response_stream()
模型输出
回答是:
2026-01-27 11:42:39,433 - INFO - HTTP Request: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
你们公司项目管理可以使用 Jira 或 Trello。
查看docs文件夹下的内容开发工程师岗位指导说明书.pdf,其中明确提到了项目管理软件。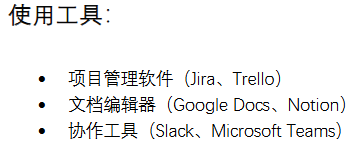
上述实验表明通过RAG,大模型已能准确回答能够准确回答公司内部项目管理工具的问题。
2.3 保存与加载索引
你可能会发现,创建索引消耗的时间比较长。
如果能够将索引保存到本地,并在需要使用的时候直接加载,而不是重新建立索引,那就可以大幅提升回复的速度,LlamaIndex 提供了简单易实现的保存与加载索引的方法。
使用index.storage_context.persist方法将索引保存为本地文件:
index.storage_context.persist("knowledge_base/test")
将本地索引文件加载为索引:
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="knowledge_base/test"),
embed_model=DashScopeEmbedding(model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V2)
)
从本地加载索引后,你可以再次调用第三步和第四步。模型正常输出:
回答是:
2026-01-27 12:06:05,376 - INFO - HTTP Request: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
你们公司项目管理可以使用 Jira 或 Trello。
RAG封装
你可以将上述代码进行封装,以便在后续持续迭代时快速使用。
封装代码存rag.py存放在p2_构造大模型问答系统下的chatbot文件夹下。
由于在前面的步骤中已经建立了索引,因此这里可以直接加载索引。
from chatbot import rag
index = rag.load_index(persist_path='./knowledge_base/test')
query_engine = rag.create_query_engine(index=index)
rag.ask('我们公司项目管理应该用什么工具', query_engine=query_engine)
模型输出:
你们公司项目管理可以使用 Jira 或 Trello。
注
如果需要重建索引,可以增加一行代码:rag.indexing()
📝 3. 本节小结
在本节课程中,你不仅动手构建了一个 RAG 应用,更重要的是,你进一步深化了对 上下文工程(Context Engineering) 这一核心理念的理解与实践。
我们来回顾一下:
-
理解了
RAG是上下文工程的关键实践
你学习到,上下文工程是为大模型准备“恰到好处”信息的艺术。
而RAG正是实现这一目标的核心技术,它通过“建立索引”和“检索生成”两个阶段,为大模型动态地提供了外部知识,解决了它不知道最新或私有信息的问题。 -
实践了包含上下文管理的 RAG 应用
通过LlamaIndex,你快速地创建了一个RAG应用,并通过构建、保存和加载索引,高效地管理了外部知识库。
你的答疑机器人已经可以基于公司文件回答问题,并能处理简单的多轮对话了。
这再次证明了上下文工程的巨大威力:我们没有重新训练模型,仅仅通过巧妙地构建和管理上下文,就显著扩展了它的能力边界。
在后续课程中,你将学习更多高级的上下文工程技术,进一步提升机器人的性能。
🔥 课后小测验
🔍 单选题
在 RAG 应用中进行多轮对话,应该如何进行检索❓
- A. 使用完整的对话历史作为检索查询
- B. 结合历史对话信息对输入问题改写后进入检索阶段
- C. 仅使用最新问题进行检索,忽略对话历史。
- D. 将上一轮召回的文本段迁移过来
✅ 参考答案:B
📝 解析:
- 在多轮对话中,直接使用原始问题(如选项
C)或完整历史记录(选项A)会导致检索噪声或信息冗余。 - 选项
B通过动态重写当前问题,既保留了对话连贯性,又避免了过时或不必要的信息迁移,是平衡效率与精度的最优方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)