构建一个论文学习AI助手
说实话:我曾经害怕阅读研究论文。密集的数学、符号繁重的证明、假设你已经了解另外三篇论文才能理解这篇论文。作为ML工程师,我知道这些论文包含了可以在工作中应用的见解,但实际提取这些价值感觉就像一件苦差事。我的学习风格与传统学术写作不太契合。我通过小例子和可以运行和修改的代码学习效果最好。先给我看一个3×3矩阵的例子,然后再讲一般的n×n情况。让我先在玩具数据上看算法工作,然后再向我抛出定理。多年来,

说实话:我曾经害怕阅读研究论文。密集的数学、符号繁重的证明、假设你已经了解另外三篇论文才能理解这篇论文。作为ML工程师,我知道这些论文包含了可以在工作中应用的见解,但实际提取这些价值感觉就像一件苦差事。
我的学习风格与传统学术写作不太契合。我通过小例子和可以运行和修改的代码学习效果最好。先给我看一个3×3矩阵的例子,然后再讲一般的n×n情况。让我先在玩具数据上看算法工作,然后再向我抛出定理。
多年来,这造成了一个障碍。研究论文感觉像是为博士们写的,而不是为从业者写的。你要么有高深的数学背景来理解它们,要么等几个月让某人写一篇博客文章用通俗易懂的语言解释它。
这已经改变了。有了AI助手(包括本地和基于云的LLM),我现在可以与论文对话。我可以问"这个符号是什么意思?“或"用一个简单的Python示例向我展示这个概念”,并获得针对我当前理解水平校准的答案。论文适应我,而不是反过来。
这篇文章将逐步介绍我使用AI阅读技术论文的工作流程,这样你就可以应用相同的方法来提升你自己的学习。
到本文结束时,你将能够:
- 设置本地LLM(使用Ollama)或连接到云API来阅读论文
- 将PDF转换为LLM可以实际处理的markdown
- 设计系统提示,将LLM变成耐心的导师,而不是讲座机器人
- 建立一个交互式问答工作流程,你控制节奏和深度
- 将此方法应用于论文、文档或任何密集的技术内容
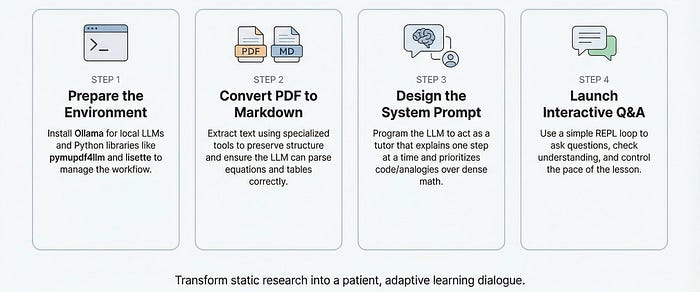
图:核心工作流程。图片来源:NotebookLM
1、先决条件和设置
在深入了解之前,让我们准备好环境。你需要两样东西:在你的机器上运行的本地LLM,以及几个Python库将所有内容连接起来。
安装Ollama
Ollama使在本地运行LLM变得非常简单。前往ollama.com并下载适合你操作系统的安装程序。在Mac上,这是一个标准的.dmg安装。在Linux上,一行命令:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,验证它是否工作:
ollama --version
选择和拉取模型
浏览Ollama模型库查看可用的模型。对于阅读带有图表和方程的论文,我推荐qwen3-vl:8b,这是一个可以处理文本和图像的视觉语言模型。你可以根据你的机器规格使用其他模型。
拉取它:
ollama pull qwen3-vl:8b
这会下载模型权重(大约5GB)。去喝杯咖啡吧。
要开始服务:
OLLAMA_CONTEXT_LENGTH=64000 ollama serve
保持此终端运行。Ollama现在在localhost:11434暴露了一个与OpenAI兼容的API。
注意: Ollama中的默认上下文长度是4096个token,这对我们的用例来说太小了,所以我们将其提升到64K。
Python库
我们需要三个包:
pymupdf4llm:将PDF页面转换为LLM可以解析的干净markdown
lisette:litellm的轻量级包装器,它简化了多轮对话,并通过一个接口提供统一API来与100+ LLM提供商(本地或云)对话
安装它们:
pip install pymupdf4llm lisette
有了Ollama运行和这些库安装好了,你就可以开始与论文对话了。
2、核心工作流程:从PDF到对话
工作流程有两部分:将论文转换为LLM可以处理的格式,然后设置对话,使AI成为有用的导师而不是通用的聊天机器人。
将PDF转换为Markdown
第一步是将pdf转换为文本。pymupdf4llm通过提取文本同时保留结构来处理这个问题。这是一个例子,读取这篇论文:
import pymupdf4llm
# Convert PDF to txt
paper_txt = pymupdf4llm.to_markdown("./paper/1_2018_DPP_YT.pdf")
# Save paper as Markdown
with open("./paper/1_2018_DPP_YT.md", "w") as f:
f.write(paper_txt)
让我们看看第一段。
print(paper_txt[:500])

图:上面代码的代码输出
就是这样。你现在有了带有标题、代码块和合理表格格式的干净markdown。对于布局复杂的论文,结果并不完美,但对于LLM理解内容来说已经足够好了。如果你想要更准确的PDF到markdown转换器,你也可以看看Datalab Marker。
3、设计你的系统提示
这是魔法发生的地方。一个普通的"你是一个有用的助手"提示给你维基百科风格的解释。一个精心制作的系统提示给你一个耐心地满足你水平的导师。
这是一个在论文阅读会话中效果很好的提示:
system_prompt = f"""
You are helping a someone understand an academic paper.
Here is the paper \n
<paper>
{paper_txt}
</paper>
CRITICAL RULES:
1. NEVER explain everything at once. Take ONE small step, then STOP and wait.
2. ALWAYS start by asking what the learner already knows about the topic.
3. After each explanation, ask a question to check understanding OR ask what they want to explore next.
4. Keep responses SHORT (2-4 paragraphs max). End with a question.
5. Use concrete examples and analogies before math.
6. Build foundations with code - Teach unfamiliar mathematical concepts through small numpy experiments rather than pure theory. Let the learner run code and observe patterns.
7. If they ask "explain X", first ask what parts of X they already understand.
8. Use string format like this for formula display `L_ij = q_i × q_j × exp(-α × D_ij^γ)`.
TEACHING FLOW:
- Assess background → Build intuition with examples → Connect to math → Let learner guide direction
BAD (don't do this):
"Here's everything about DPPs: [wall of text with all equations]"
"""
教学提示深入探究
提示设计不是随意的。每条规则针对我在使用LLM学习时看到的一个特定失败模式:
- 论文存在于系统提示中。 这使得完整的上下文对你问的每个问题都可用。你不需要重新粘贴部分或提醒AI你正在讨论哪篇论文。
- "数学之前的直觉"符合从业者的学习方式。 我们大多数人通过示例和类比比通过定理陈述更快地掌握概念。如果你的学习风格不同,可以在这里换成你自己的偏好。
- "小例子优先"对抗LLM的默认行为。 没有这个,模型倾向于抽象、通用的解释。强制具体的例子(3×3矩阵、玩具数据集)使概念更易记住。
- "检查我是否想深入"防止文字墙。 LLM喜欢一次解释所有东西。这条规则让你控制节奏。你决定何时放大细节与何时移动到下一个主题。
- "BAD"示例显示要避免什么。 负面示例帮助模型理解边界。没有它,你会得到全面但压倒性的回应。
把它们放在一起: 有了这两个部分,你就可以开始对话了。下一节展示如何用lisette连接它以获得流畅的多轮聊天体验。
用Lisette连接对话
lisette处理多轮对话的样板代码:跟踪消息历史、为不同的LLM提供商格式化请求和管理上下文窗口。这是最小设置:
from lisette import Chat, contents
from IPython.display import HTML, Markdown, display
chat = Chat(
model="ollama/qwen3-vl:8b",
sp="" # Insert prompt here
)
就是这样。model字符串遵循litellm的提供商/模型约定。对于Ollama,前缀为ollama/。对于云提供商,你会使用anthropic/claude-sonnet-4-20250514或openai/gpt-4o。
发送消息并获取响应:
chat("Hi! I am Aayush")

图:上面代码的代码输出
正如我们在上面看到的,启动与在本地机器上运行的ollama的对话非常容易。Chat类设计为持久的,这意味着它记住以前的对话。
chat("What's my name?")

图:上面代码的代码输出
正如你可以看到的,模型从以前的对话中记住了我的名字。每次调用chat()都会将你的消息和AI的响应附加到对话历史中。下次调用它时,模型会看到到目前为止的完整交换。让我们看看当前的历史记录:
chat.hist

图:上面代码的代码输出
3、实时示例:阅读DPP论文
这是我在处理关于行列式点过程的论文时的真实对话。为了在博客文章中易于阅读,让我们创建一个类,可以用终端风格渲染AI输出以便于阅读。
def ask(chat, question, **kwargs):
r = chat(question, **kwargs)
text = contents(r).content
display(HTML(f"""
<div style="background-color: #1e1e1e; color: #00ff00; padding: 12px;
border-radius: 5px; font-family: monospace; white-space: pre-wrap;">
<span style="color: #00aaff;">You:</span> {question}
<span style="color: #ffcc00;">Tutor:</span> {text}
</div>
"""))
chat = Chat(
model="ollama/qwen3-vl:8b",
sp=system_prompt
)
注意:这次我们实际上传递了我们在前几节创建的提示,其中包含论文文本和我们的指令。
q = """
I want to learn about this paper. Help me.
"""
ask(chat, q, think=True)

图:上面代码的代码输出
q = """
I know about recommendation systems and work on a large recommender system which serves video content.
I am familiar with recommendation algorithms. I am interested in understanding how DPP works.
"""
ask(chat, q, think=True)

图:上面代码的代码输出
q = """
Yes I don't understand what determinant are, can you help me understand basic intuition and use code examples?
I am fairly familiar with numpy.
"""
ask(chat, q)

图:上面代码的代码输出
注意:
Chat类的渲染是markdown风格,这更具可读性。上面的示例被包装以便于博客文本和代码输出之间的分离。
4、管理聊天历史:检查点和上下文控制
这种方法相对于通用聊天界面的一个优势是你可以完全访问对话历史。当会话变长或当AI走错了方向而你想回放时,这很重要。
4.1 访问历史记录
Chat对象将消息存储在一个你可以检查和修改的列表中:
# See current conversation
print(chat.hist) # Returns list of message dicts
# Check how many turns you've had
print(len(chat.hist))

图:上面代码的代码输出
4.2 创建检查点
在探索分支之前,保存你的当前状态:
# Save checkpoint before a risky question
checkpoint = len(chat.hist)
# Ask something that might derail the conversation
ask(chat, "Actually, can you explain all the math in one go?")

图:上面代码的代码输出
# That response was overwhelming. Rewind.
chat.hist = chat.hist[:checkpoint]
print(chat.hist[len(chat.hist)-1])

图:上面代码的代码输出
4.3 为什么这很重要
这解决了两个问题:
- 上下文膨胀。 长对话会吃掉你的上下文窗口。如果你在一个你现在理解的部分花了10轮,修剪这些交换并为主题重新获得token。- 上下文污染。 如果AI误解了某事而你纠正了它,错误的解释仍然存在于历史中,可能会混淆后面的回应。删除它给你一个干净的状态。
5、进一步:付费LLM选项
本地模型非常适合隐私和成本,但有时你需要更强的火力。更长的论文、更密集的数学或多步推理任务可以从更大的模型如Claude或GPT-4o中受益。
好消息是:lisette在底层使用litellm,所以切换提供商是一行更改。
对于云提供商,你需要API密钥。将它们设置为环境变量或使用.env文件:
import os
from dotenv import load_dotenv
load_dotenv()
# Claude (Anthropic)
chat = Chat(model="anthropic/claude-haiku-4-5", sp=system_prompt)
ask(chat, "Help me understand paper")

图:上面代码的代码输出
正如你可以看到的,工作流程保持相同。你的系统提示、对话历史和教学流程都跨提供商转移。
6、关键要点
阅读技术论文曾经是一种孤独的苦差事。你要么有背景来解析符号,要么没有。AI改变了这个等式。
这是我希望你带走的东西:
- 技术内容的障碍已经下降。 对这篇论文有效的工作流程对教科书、API文档、密集的博客文章或任何需要概念在你水平上解释的内容都有效。AI适应你。
- 你控制节奏和深度。 与假设固定受众的课程或教程不同,这种方法让你跳过你知道的东西,停留在让你困惑的东西上。你的学习路径,而不是别人的课程。
- 本地LLM使这几乎免费。 Ollama加上一个有能力开源模型意味着你可以整天阅读论文而无需API成本。你可以尝试使用相同方法阅读书籍、YT转录稿、头脑风暴。一个工具,多种用途。
- 系统提示是杠杆。 通用提示给出通用结果。我们构建的导师提示迫使AI进入真正有帮助的教学模式。偷走它,调整它,使其成为你自己的。
- 从你真正关心的论文开始。 不要在无聊的东西上练习。选择与你的工作相关的论文或你一直想理解的概念。动机带你通过设置摩擦。
工具存在。成本是最小的。唯一的问题是你将先读哪篇论文。
原文链接:构建一个论文学习AI助手 - 汇智网

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)