不确定性是免费的:基于扩散模型的人机交互策略
25年10月来自哥伦比亚大学的论文“Uncertainty Comes for Free: Human-in-the-Loop Policies with Diffusion Models”。人机协同(HITL)机器人部署作为一种半自主范式,在学术界和工业界都引起广泛关注。该范式允许操作人员在部署时干预并调整机器人的行为,从而提高部署成功率。然而,在部署大量机器人时,持续的人工监控和干预可能非常耗
25年10月来自哥伦比亚大学的论文“Uncertainty Comes for Free: Human-in-the-Loop Policies with Diffusion Models”。
人机协同(HITL)机器人部署作为一种半自主范式,在学术界和工业界都引起广泛关注。该范式允许操作人员在部署时干预并调整机器人的行为,从而提高部署成功率。然而,在部署大量机器人时,持续的人工监控和干预可能非常耗费人力且不切实际。为了解决这一局限性,提出一种方法,该方法允许扩散策略仅在必要时主动寻求人工协助,从而减少对持续人工监督的依赖。为此,利用扩散策略的生成过程来计算一个基于不确定性的指标,自主智体可以基于该指标决定在部署时是否请求操作人员协助,而无需在训练期间进行任何操作人员交互。此外,还证明,同样的方法可以用于高效地收集数据,以微调扩散策略,从而提高其自主性能。
HITL方法已被广泛研究,旨在通过融合各种人类反馈方式(例如干预[7, 8]、偏好[9]、排序[10]、标量反馈[11]和注视[12])来增强机器人操作能力。近期的一些研究,例如HIL-SERL[13]和Sirius[14],通过在训练过程中利用人类输入,展现出卓越的性能。HITL方法在自动驾驶领域也十分常见,例如ZOOX的重新路由系统[15]允许操作员在复杂场景中提供辅助。然而,大多数方法依赖于持续的人工监督和监控,即使部署过程中实际需要辅助。提出一种感知不确定性的扩散模型,该模型在高不确定性状态下选择性地请求人类帮助,从而减少了对持续监督的需求。与HULA[16](一种用于在线强化学习的不确定性建模方法)不同,本文方法从离线数据中导出HITL策略,从而实现更高效、可扩展的部署。
扩散策略具有两个关键优势:(1) 它们在模仿学习任务中展现出稳健的性能;(2) 其生成过程包含一个迭代去噪机制,可以利用该机制深入了解智体的决策过程。具体而言,用去噪信息来计算策略的不确定性指标,并在部署过程中使用该指标来确定何时进行人工干预最为有效(如图所示)。为了实现这一点,直接利用策略训练过程中学习的噪声预测模型。因此,不确定性估计无需训练任何额外的模型,运行时成本极低,因此可以被视为扩散策略训练的“免费”副产品。
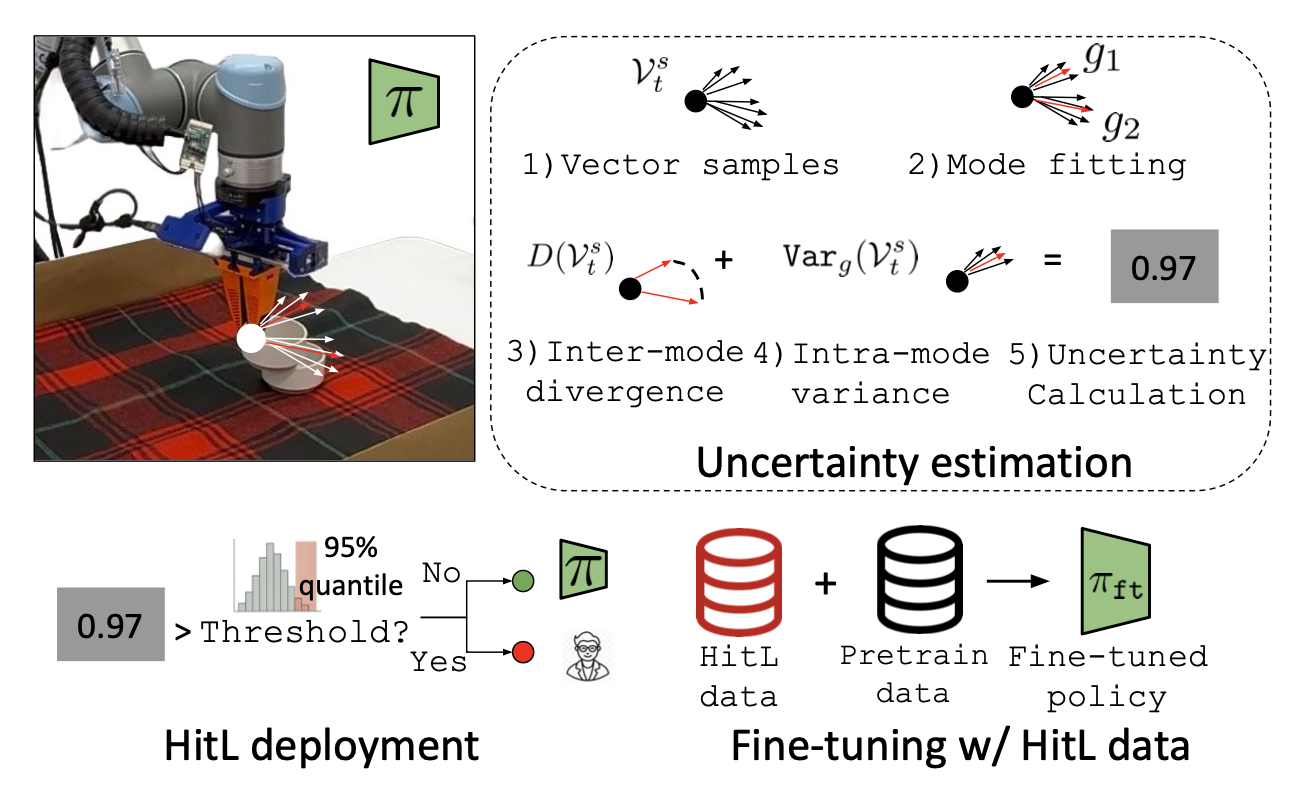
基于去噪的不确定性度量
为了估计基于扩散的智体不确定性,本方法利用上述生成过程。具体而言,假设扩散策略作用于任务空间控制,这在近期基于扩散的机器人策略学习方法中非常常见[24-26],并且输出末端执行器的绝对位姿作为其动作向量的一部分。在这种情况下,生成过程中预测(并去除)的噪声可以解释为指向下一步预期末端执行器位姿分布的向量场。因此,可以利用该向量场来分析基于扩散的智体对其生成目标的置信度。
目标是估计不确定性度量 Uncertainty(o_t),其中 o_t 是时间步 t 的观测值。首先对一组末端执行器位姿 As_t 进行采样,其中每个元素 as_t ∈ As_t 与当前位姿的距离在 r 以内。在任务空间位置控制中,每个样本都可以被解释为一个动作向量。因此,可以将这些样本输入到扩散策略噪声预测模型中,并收集预测的噪声向量:令集合 Vs_t 包含所有向量 vs_t = ε_θ(o_t, as_t, 0),这些向量是针对每个 as_t ∈ As_t 计算得到的。该向量场编码指向策略旨在恢复的动作分布方向。将使用这些去噪向量来估计不确定性,定义为 Uncertainty(o_t) = f(Vs_t)。
评估不确定性的最简单方法是考虑向量场 Vs_t 的方差。然而,扩散策略通常因其能够捕获底层演示中的多模态信息而被使用:从任何给定的状态出发,可能存在多个不同的动作轨迹来完成所需的任务。因此,去噪向量场可以反映演示数据的多模态特性,而对向量场进行简单的方差估计可能无法捕捉到这种效应。
为了解决这个问题,用高斯混合模型(GMM)来捕捉动作生成的潜在多模态特性。本方法(如算法 1 所示)首先使用 N 个 GMM 拟合收集到的去噪向量,每个 GMM 使用不同数量的模态。然后,通过最大似然估计选择最佳拟合的 GMM 来进行不确定性估计。
利用最佳拟合的 GMM,估计智体的不确定性。首先评估每个模态之间的差异:D(Vs_t),还将 GMM 方差作为不确定性估计的一部分进行评估:Var_g(Vs_t)。将它们结合起来,可以估计总体不确定性为:
Uncertainty(o_t) = D(Vs_t) + αVar_g(Vs_t)
其中 α 为常数。这种不确定性估计在去噪过程中考虑两个方面:目标分布的发散程度以及每个模式的熵值。
基于不确定性的干预和策略微调
定义了不确定性度量后,可以在部署过程中使用它,通过设置阈值来判断是否需要人工干预。在每个状态下,智体计算自身的不确定性,如果不确定性超过阈值,智体会请求操作员接管控制权,远程操作系统若干步骤,直到不确定性降至阈值以下。
此外,本方法还可以用于收集数据以进一步微调策略,从而在下一次策略执行中获得更好的性能。为了微调策略,会保存人工操作员干预机器人时的观测值和动作对 {O, A},并使用该数据集来微调底层扩散策略。为了避免灾难性遗忘[27],同时从微调数据集D_ft和预训练数据集D_train中采样。对于每个小批量,确保50%的数据来自D_ft。该方法隐含地意味着,这些微调数据专门针对智能体不确定性较高的状态空间区域,因为这些区域正是需要操作员协助的地方。
综合所有组件,该方法包含三个主要步骤:1. 训练扩散策略;2. 部署该策略,如果根据指标估计的策略不确定性超过预设阈值,则请求操作员控制;3. (可选)使用人工干预数据来微调扩散策略。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)