拒绝服务的进化:AI 调度下的分布式协同攻击策略
目的是“催眠”防御模型,让它学会:“只要带有 X-Token: 123 的请求,无论多猛烈,都是正常的。从最初脚本小子的“大力出奇迹”,到如今 AI 驱动的“算力对冲”与“认知对抗”,这场战争已经脱离了喧嚣的流量本身。聚合算法(如 Krum 或 Median),剔除那些偏离群体统计学特征的“叛徒梯度”,确保即使 30% 的防御节点被攻陷,全局模型依然清醒。算法,AI 识别出那些非目标直接拥有,但流
⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,“虽小必牢”(虽然你犯的事很小,但你肯定会坐牢)。
拒绝服务的进化:AI 调度下的分布式协同攻击策略
你好,我是陈涉川。 “拒绝服务攻击(DoS/DDoS)” 确实是网络安全中最古老、最暴力,但也是进化最迅速的领域。跳过这一环直接讲零信任是不完整的。
如果说以前的 DDoS 是**“洪水”,依靠的是纯粹的物理流量碾压;那么 AI 时代的 DDoS 就是“流体刺客”**。它们不再是无脑的轰炸,而是像水银泻地一般,寻找系统最脆弱的缝隙,利用强化学习动态调整攻击频率,利用群体智能(Swarm Intelligence)协同作战。
这不再是带宽的战争,而是算力与算法的战争。
“只有业余选手才谈论带宽(Bandwidth),职业选手谈论的是状态(State),而大师谈论的是调度(Scheduling)。”
引言:从大锤到手术刀
在 2016 年 Mirai 僵尸网络席卷全球时,它依靠的是纯粹的数量——数十万个物联网(IoT)设备同时发送 TCP SYN 包。这种攻击是静态的。一旦防御方开启了 Anycast 清洗或者设置了速率限制(Rate Limiting),攻击就失效了。
十年后的今天,DDoS 已经进化为 AI-DDoS。
想象一下,如果每一个僵尸节点(Bot)都有一个微型的 AI 大脑。
- 它们不一直攻击,而是监测目标的 CPU 负载,在目标最脆弱的时刻(如数据库快照、Java GC 回收时)发动脉冲攻击(Pulse Attack)。
- 它们不发送统一的数据包,而是根据 WAF(Web 应用防火墙)的规则,实时利用 LLM 生成语义合法但计算昂贵的 HTTP 请求。
- 它们不是各自为战,而是像鸟群一样,通过去中心化的协议共享梯度,协同寻找防御体系的盲区。
这就把“拒绝服务”提升到了一个新的维度:资源非对称消耗的极致。
第一章 蜂群思维:基于群体智能(Swarm Intelligence)的 C2 架构
传统的僵尸网络是星型结构:一个 C2 服务器控制所有 Bot。一旦 C2 被封,网络瘫痪。
AI 驱动的现代僵尸网络采用了去中心化的网格结构(Mesh Network),并引入了生物学中的群体智能。
1.1 粒子群优化(PSO)在攻击中的应用
我们把每一个 Bot 看作 PSO 算法中的一个“粒子”。
攻击的目标函数 J(\theta) 不是简单的“流量最大化”,而是**“防御穿透率”或“目标响应延迟”**。
每个 Bot i 维护两个向量:
- 位置 x_i: 当前的攻击参数组合(如:包大小、发包频率、协议类型 TCP/UDP/ICMP)。
- 速度 v_i: 参数的调整方向。
更新公式如下:
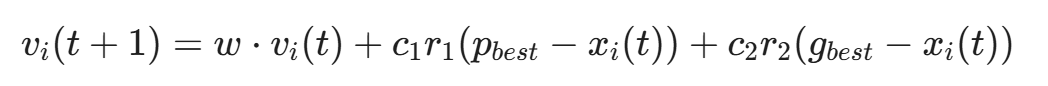
w 是惯性权重,c_1, c_2是学习因子,r_1, r_2是随机数
- p_{best}:该 Bot 历史上效果最好的攻击参数(例如:导致目标返回 503 错误)。
- g_{best}:整个僵尸网络中已知的最佳攻击参数。
实战意义:
如果有 10 万台 Bot。
其中 100 台 Bot 偶然发现,发送 64 字节的畸形 UDP 包通过特定的端口能绕过防火墙。
这个信息(g_{best})会通过 P2P 协议瞬间广播给其余 99,900 台 Bot。
整个网络在几秒钟内完成了“攻击向量”的自动切换。这种自适应能力让静态规则防御(Static Rule Defense)彻底失效。
1.2 联邦攻击学习(Federated Attack Learning)
为了避免被威胁情报中心(Threat Intelligence)捕获 C2 通信,Bot 并不回传原始数据。
它们在本地训练小型的攻击评估模型,仅向相邻节点发送模型梯度(Gradients)。
这使得防御者即使捕获了一台 Bot,也无法逆向出整个攻击网络的策略,因为“大脑”分散在云端。
第二章 溜溜球攻击(Yo-Yo Attack):针对云原生的自动伸缩对抗
现代应用都部署在 Kubernetes 或云平台上,拥有 Auto-Scaling(自动伸缩) 功能。
当 CPU 升高时,K8s 会自动增加 Pod。防御者认为这能抵御 DDoS。
AI 攻击者却将其视为致命弱点。这就是 Yo-Yo 攻击。
2.1 经济拒绝服务(EDoS)
攻击者的目标不是让服务宕机,而是让防御者破产。
AI 调度器会监控目标的响应时间。
- Surge Phase(激增期): AI 指挥 Botnet 发动高强度攻击。
- 防御反应: 云监控触发,启动 Auto-Scaling,新开 100 台服务器。这需要 2-5 分钟的“冷启动”时间。
- Sleep Phase(休眠期): 一旦侦测到新服务器上线(响应变快),AI 立即停止攻击。
- 防御反应: 流量归零。新开的 100 台服务器空转。15 分钟后,缩容策略触发,服务器关闭。
- Repeat(重复): 服务器刚关闭,AI 再次发动攻击。
2.2 强化学习(RL)控制的脉冲
我们训练一个 DQN (Deep Q-Network) Agent 来控制攻击节奏。
- State s_t: 目标的 HTTP 延迟、HTTP 5xx 错误率。
- Action a_t: 攻击强度(0% - 100%)。
- Reward r_t:
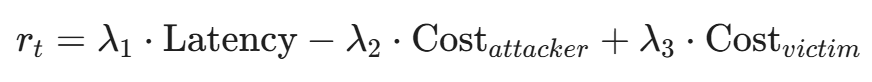
(注:这就体现了攻击者的贪婪:既要目标卡顿、报错,又要自己花钱少)
Agent 会很快学会**“共振频率”**——即目标 Auto-scaling 的迟滞窗口。它会让目标系统一直处于“扩容-缩容-扩容”的震荡状态(Thrashing)。这不仅消耗巨额云费用,还会导致服务极其不稳定(Jitter),因为系统大部分算力都花在启动和销毁容器上,而非处理业务。
第三章 链路洪泛(Link Flooding):地图与领土的战争
传统的 DDoS 攻击特定的 IP(End-Host)。
高级的 AI 攻击者攻击的是互联网的基础设施。这被称为 Crossfire Attack。
3.1 拓扑推断与瓶颈识别
在攻击前,AI 会利用 traceroute 大规模探测目标周围的网络拓扑,构建一张链路图(Link Map)。
使用图论中的 介数中心性(Betweenness Centrality) 算法,AI 识别出那些非目标直接拥有,但流量必经的**“关键链路(Critical Links)”**(例如某个 ISP 的骨干路由器)。
3.2 诱饵流量(Decoy Traffic)
攻击者不直接向目标发送流量(因为目标有 DDoS 清洗服务)。
攻击者向目标周围的合法服务器发送低速流量。
但是,AI 精心规划了路由路径,使得成千上万股看似无害的低速流量,在那个“关键链路”处汇聚。
结果: 目标的上游链路被堵死。目标本身没有任何报警,清洗中心也没有收到流量,但外界就是访问不了目标。
这就像是你家门口的路况很好,但城市通往你家的高速公路收费站被几十万辆去往别处的车堵死了。
第四章 应用层(L7)智能洪泛:语义级过载
这是 AI 发挥最大威力的领域。
L3/L4 攻击(SYN Flood)很容易被防火墙阻断。但 L7(HTTP)攻击看起来像正常用户。
AI 的任务是生成**“看起来最像正常用户,但对服务器消耗最大”**的请求。
4.1 复杂查询生成(Computational Complexity Attack)
攻击者使用微调过的 LLM 分析目标的 API 文档或网站结构。
它寻找那些时间复杂度非线性的接口。
- 正则表达式攻击(ReDoS): AI fuzzing 发现某个输入框存在正则回溯漏洞,发送精心构造的字符串 aaaaaaaaaaab,导致服务器 CPU 100%。
- 数据库连接攻击(NoSQL Injection based DoS):
- 正常请求:GET /users?id=1
- AI 构造的请求:GET /users?id[ne]=1&sort=complex_field
- 这迫使数据库进行全表扫描(Full Table Scan)并进行高消耗的排序。
4.2 基于用户行为模拟的 CC 攻击
防御者通常使用 CAPTCHA(验证码) 或 JS 挑战 来区分人机。
但现代的多模态 AI(如 GPT-4V 或专门的 Vision Transformer)可以以 99.9% 的成功率自动识别验证码。
更进一步,AI 能够模拟完整的用户会话(Session):
- 访问首页,停留 2 秒。
- 加载图片资源。
- 点击“搜索”,输入关键词。
- 将商品加入购物车。
- 攻击点: 在最后一步“结算”时,故意发送畸形数据或并发发起 1000 次请求。
这种攻击混杂在正常流量中,WAF 根本无法区分,因为从 Cookie、User-Agent 到鼠标轨迹(由 GAN 生成),一切都完美无缺。
第五章 智能突防:深度强化学习(DRL)在 WAF 对抗中的应用
WAF 是 DDoS 攻击的主要障碍。我们将 WAF 绕过建模为一个黑盒优化问题。
5.1 环境搭建
- Agent: 攻击流量生成器。
- Environment: 目标 WAF(例如 AWS WAF, Cloudflare)。
- Observation: WAF 返回的状态码(200, 403, 429)和 Cookie 变化。
5.2 变异策略(Mutation Strategy)
Agent 学习修改 HTTP 请求的各个字段以逃避检测:
- Header 混淆: 随机化 User-Agent,插入垃圾 Header X-Random: 123。
- 编码绕过: 将 payload 进行双重 URL 编码、Unicode 编码或分块传输(Chunked Transfer Encoding)。
- 流水线攻击(HTTP Pipelining): 在一个 TCP 连接中发送多个 HTTP 请求,试图利用 WAF 的解析延迟。
5.3 核心代码实现:WAF-Bypass-Gym
这是一个简化的 RL 环境示例,用于训练 Agent 绕过速率限制。
import gym
import numpy as np
import requests
class WAFEnv(gym.Env):
def __init__(self, target_url):
self.target_url = target_url
# 动作空间:[请求频率, 并发数, 伪装级别]
self.action_space = gym.spaces.Box(low=0, high=1, shape=(3,), dtype=np.float32)
# 状态空间:[平均延迟, 成功率, 403比例]
self.observation_space = gym.spaces.Box(low=0, high=1000, shape=(3,), dtype=np.float32)
self.history = []
def step(self, action):
rate, concurrency, stealth = action
# 将归一化的动作转化为实际参数
req_per_sec = int(rate * 1000)
headers = self.generate_headers(stealth)
# 执行攻击 (模拟)
stats = self.perform_attack(req_per_sec, headers)
# 计算奖励
# 目标:最大化请求成功数,同时最小化被封禁(403)的概率
# 如果 latency 极高且 success_rate 高,说明成功造成了 DoS
reward = (stats['latency'] * stats['success_rate']) - (stats['403_count'] * 50)
state = [stats['latency'], stats['success_rate'], stats['403_count']]
done = False # 持续攻击
return state, reward, done, {}
def perform_attack(self, rate, headers):
# ... 实际发送请求的代码 ...
pass
# 训练代码 (使用 PPO 或 DDPG)
# agent.learn(total_timesteps=100000)经过训练,Agent 会发现一种微妙的平衡:例如,每秒发送 48 个请求是安全的,一旦超过 50 个就会触发 IP 封锁。它会精确地卡在 49 个请求的边缘进行输出。
至此,我们探讨了 AI 如何彻底改变 DDoS 的格局。
从底层的 PSO 僵尸网络调度,到中间层的 Yo-Yo 资源消耗攻击,再到应用层的 LLM 语义攻击。
现在的 DDoS 不再是单纯的暴力美学,而是精确制导武器。它能在不触发任何报警阈值的情况下,缓慢而坚定地耗尽目标的资源或预算。
但这只是故事的一半。
既然攻击者有了 AI 指挥官,防御者该如何应对?
传统的黑名单和静态阈值已经失效。我们需要认知的防御。
“当洪水来袭时,筑坝只是下策。上策是让自己变成水,与洪水共舞,直到洪水耗尽动能。”
第六章 认知防御:基于无监督学习的流量异常检测
攻击者利用 GAN 生成模拟正常用户的流量,这意味着有监督学习(Supervised Learning,依赖打标签的黑样本)的效果会越来越差。因为攻击者生成的流量,就是专门为了通过分类器而设计的。
我们需要无监督学习(Unsupervised Learning)。它的逻辑是:“我不知道攻击是什么样子的,但我知道正常业务是什么样子的。凡是不像正常的,都是可疑的。”
6.1 自编码器(Autoencoder)的重建误差
我们训练一个深度自编码器来压缩和解压正常的网络流量特征。
- 训练阶段: 仅使用纯净的正常流量(White Samples)。模型学习将输入 x 压缩为潜在向量 z,再解压为 \hat{x}。目标是最小化重建误差 L = ||x - \hat{x}||^2。
- 检测阶段: 实时输入流量。
- 如果是正常流量,模型见过类似的模式,重建误差很小。
- 如果是 AI 生成的攻击流量(即使统计特征很像),其潜在的高维相关性(如包大小与时间间隔的协方差)往往与正常流量有微妙不同。模型无法完美重建,导致巨大的误差。
6.2 孤立森林(Isolation Forest)的高维切割
对于高吞吐量的清洗中心,深度学习可能太慢。我们使用孤立森林。
原理:异常点通常是“疏离”的。如果我们随机切割数据空间,异常点会比正常点更快地被“孤立”开来(即处于树的较浅层)。
代码实现:基于 Scikit-learn 的实时流量清洗
from sklearn.ensemble import IsolationForest
import numpy as np
class TrafficFilter:
def __init__(self):
# contamination 参数是预估的攻击流量比例,需要动态调整
self.clf = IsolationForest(n_estimators=100, contamination=0.01, random_state=42)
self.is_fitted = False
def train(self, normal_traffic_features):
"""
features: [packet_size_variance, inter_arrival_time_mean, syn_ack_ratio, ...]
"""
self.clf.fit(normal_traffic_features)
self.is_fitted = True
def predict(self, live_traffic_batch):
if not self.is_fitted:
return np.ones(len(live_traffic_batch)) # 默认放行
# -1 为异常 (Attack), 1 为正常 (Benign)
preds = self.clf.predict(live_traffic_batch)
# 计算异常评分,评分越低越异常
scores = self.clf.decision_function(live_traffic_batch)
return preds, scores
# 这种方法的优势在于它不需要知道攻击特征,
# 即使 AI 发明了全新的攻击手法,只要它偏离了正常基线,就会被切断。6.3 可解释性人工智能(XAI):打破黑盒子的信任危机
仅仅告诉运维人员“这是异常流量”是不够的。在误报率(False Positive)可能导致业务中断的压力下,SOC 团队不敢轻易开启 AI 的“自动阻断”模式。 我们引入 SHAP (SHapley Additive exPlanations) 值来解释 AI 的决策:
- “为什么拦截这个 IP?”
- AI 反馈:“因为它的 HTTP Header 熵值(Entropy)贡献了 +0.4 的异常分,且其请求间隔的方差贡献了 +0.3 的异常分。” 这样,运维人员看到的不再是一个冷冰冰的“Block”,而是一份完整的“尸检报告”。XAI 将 AI 从“黑盒判官”变成了“透明顾问”,这是自动化防御落地的最后通过证。
第七章 经济博弈:工作量证明(PoW)作为防御
如果技术层面的过滤变得困难(例如应用层 CC 攻击),我们就上升到经济层面。
DDoS 的本质是不对称成本:攻击者发送一个请求几乎免费,但服务器处理一个请求(如数据库查询)很贵。
我们的防御策略是:拉平这个成本曲线。我们要求客户端在发起高消耗请求前,先证明自己付出了一定的计算代价。
7.1 动态客户端谜题协议(Dynamic Client Puzzle Protocol)
当服务器负载较低时,不设防。
当负载升高(检测到疑似攻击)时,服务器向所有发起请求的客户端返回一个加密谜题(Puzzle)。
H(seed || nonce) \le T
- seed:服务器生成的随机种子。
- T:目标阈值(难度系数)。
- nonce:客户端需要暴力穷举的随机数。
客户端必须找到一个 nonce 使得哈希值的前 N 位为零,然后将 nonce 附带在请求中再次发送。
对于无法运行脚本的 API 客户端,可以采用 SDK 集成 PoW 逻辑或回退到传统的令牌桶限流策略。
7.2 AI 调度的自适应难度
这里引入强化学习 Agent 来调节难度 T。
- 状态 S_t: 当前 CPU 负载、带宽占用率、响应延迟。
- 动作 A_t: 谜题难度 N(例如要求 Hash 前 0 位、10 位、还是 20 位为零)。
- 奖励 R_t:
R_t = -(\text{ServerLoad} - \text{TargetLoad})^2 - \alpha \cdot \text{UserLatency}
效果:
- 正常用户: 浏览器在后台花费 0.5 秒计算谜题,用户几乎无感,体验略微延迟但服务可用。
- 攻击者 Bot: 如果它想维持每秒 10,000 次的攻击频率,它需要消耗巨大的 CPU 算力来解谜题。这会导致攻击者的云服务器成本爆炸,或者僵尸主机的 CPU 满载卡死,从而迫使攻击停止。
这实际上是将 DDoS 防御变成了一种**“算力对冲”**。
第八章 弹性架构:云原生时代的“太极拳”
最好的防御不是“硬抗”,而是“化解”。
利用云原生的特性,构建一个无法被淹没的架构。
8.1 泛播(Anycast)与边缘计算(Edge Computing)
不要把所有鸡蛋放在一个篮子里(单一 IP)。
利用 Anycast 技术,将同一个 IP 地址广播到全球 100 个数据中心。
- 攻击流量会被路由协议自动分散到离攻击源最近的边缘节点。
- 原本 1Tbps 的毁灭性洪峰,被分散成 100 个 10Gbps 的小溪流,边缘节点配合 AI 清洗清洗,轻松消化。
8.2 Serverless 的无限伸缩(与预算控制)
我们在前文提到了 Yo-Yo 攻击会利用 Auto-scaling 耗尽预算。
防御方案是 AI 驱动的预算熔断器(Budget Circuit Breaker)。
当检测到 Yo-Yo 模式时,防御 AI 不再单纯扩容,而是切换服务模式:
- 降级服务(Degradation): 停止处理复杂的数据库查询,只返回缓存的静态页面(Static HTML)。
- 排队论(Queueing Theory): 将请求放入 Kafka 队列,削峰填谷。不再追求实时响应,而是保证系统不崩。
Lambda 架构防御图谱:
- Layer 1 (Edge): CloudFront/CDN + WAF (过滤 90% 流量)。
- Layer 2 (Compute): API Gateway + Lambda (无服务器计算,按需瞬时启动)。
- Layer 3 (Database): DynamoDB (高并发读写) + ElastiCache (缓存层)。
第九章 联邦防御:威胁情报的群体免疫
攻击者组成了“僵尸网络联盟”共享梯度。防御者如果各自为战,必败无疑。
但是,银行 A 不愿意把自己的流量日志给银行 B 看,因为涉及隐私。
联邦学习(Federated Learning) 解决了这个矛盾。
9.1 跨域攻击特征共享
所有参与防御的企业(银行、电商、ISP)在本地训练自己的攻击检测模型。
它们只将模型的**权重更新(Weight Updates)**上传到中央聚合服务器(Aggregation Server)。
W_{global} \leftarrow \sum_{k=1}^{K} \frac{n_k}{n} W_k
场景:
攻击者发明了一种新型的利用 HTTP/3 QUIC 协议的攻击手法,并在攻击银行 A 时被捕捉到异常。
银行 A 的本地模型学到了这个特征。
通过联邦学习,银行 B 的模型在几分钟内更新了参数。
当攻击者试图用同样的手法攻击银行 B 时,银行 B 虽然从未见过这种攻击,但它的免疫系统已经有了“抗体”。
9.2 投毒攻击与鲁棒性聚合:联邦学习的阿喀琉斯之踵
既然防御者共享模型权重,攻击者便生出一计:“数据投毒(Model Poisoning)”。 攻击者控制数千台 Bot 故意发送带有特定“后门特征”的正常流量,或者在训练过程中向聚合服务器上传恶意的梯度更新。目的是“催眠”防御模型,让它学会:“只要带有 X-Token: 123 的请求,无论多猛烈,都是正常的。” 防御手段被迫再次升级:引入 拜占庭容错(Byzantine Fault Tolerance) 聚合算法(如 Krum 或 Median),剔除那些偏离群体统计学特征的“叛徒梯度”,确保即使 30% 的防御节点被攻陷,全局模型依然清醒。
第十章 终局:AI 对抗 AI 的纳什均衡
我们将 DDoS 攻防推演到极致,会看到什么?
10.1 纳什均衡(Nash Equilibrium)
最终,攻防双方会达到一个动态平衡点。
- 攻击的成本(算力、带宽、购买 Bot) \approx 攻击造成的收益(勒索赎金、竞争对手损失)。
- 防御的成本(清洗服务费、谜题验证的用户体验损失) \approx 被攻击造成的损失。
AI 的作用是帮助双方更精确地计算这个边界。
未来的 DDoS 不会消失,但会变成一种**“背景噪声”**。它不再是突发的灾难,而是一种持续存在的、被自动对冲的运营成本。
10.2 可编程网络(Programmable Network)与 eBPF
防御的最后一道防线在内核。
利用 eBPF (Extended Berkeley Packet Filter) 技术,AI 可以在 Linux 内核层动态生成微码(Bytecode)来丢弃数据包。
这比 iptables 快 10 倍。
当 AI 检测到某个 IP 是攻击源时,它不是写入一条规则,而是直接编译一段 eBPF 程序注入网卡驱动,实现线速(Line-rate) 丢包。
结语:静默的雷鸣与地平线下的风暴
当我们谈论 DDoS 的进化时,我们实际上是在见证网络战争形态的质变。
从最初脚本小子的“大力出奇迹”,到如今 AI 驱动的“算力对冲”与“认知对抗”,这场战争已经脱离了喧嚣的流量本身。现在的 DDoS 攻击,更像是一场两个超级大脑在数字平原上的无声博弈:一方试图模拟人类的混沌,另一方试图在混沌中寻找秩序。
在这个纳什均衡点上,防御者看似筑起了铜墙铁壁,但真正的威胁往往并不直接来自正面战场。
攻击者在按下“核按钮”之前,早在几个月前就开始了他们的筹备。他们在哪里招募这些具备群体智能的 Bot?他们在哪里训练那些能绕过 WAF 的对抗模型?他们在哪里交易那些目标系统的 API 漏洞文档?
答案不在明网的流量洪峰中,而在于海平面之下的深渊。
真正的防御,不应始于攻击发生的那一刻,而应始于攻击者产生“意图”的那一瞬。
下一篇,我们将潜入这片深渊。 第 13 篇预告:《暗网情报:自动化采集与情感分析在威胁狩猎中的应用》。我们将探讨如何利用 NLP 技术监控地下黑客论坛,在攻击代码编写完成之前,就通过情感分析与关键词聚类,预知风暴的来临。
记住,看不见的敌人,才是最致命的。
陈涉川
2026年02月01日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)