多代理实战:5个子代理的角色分工与ReAct架构实现
ReAct(Reasoning + Acting)是一种让智能体“先思考、再行动”的交互模式,核心逻辑是**“思考→工具调用→结果反馈→再思考”**的循环,完美契合复杂任务的分步执行需求。透明化决策:代理会明确思考“是否需要调用工具”“调用哪个工具”,而非直接输出结果;可回溯纠错:若工具调用失败或结果不满足需求,代理可基于反馈调整策略,重新尝试;灵活适配多工具:支持同时绑定多个工具,根据任务需求动
多代理实战:5个子代理的角色分工与ReAct架构实现
前言
在上一篇博客中,我们搭建了多代理混合RAG系统的整体框架,明确了5个子代理(chat/coder/sqler/graph_kg/vec_kg)的核心定位。但这些“执行团队”究竟是如何工作的?背后依赖的ReAct架构又是什么原理?
本文作为系列博客的第二篇,将聚焦代理层的核心实现:深入拆解ReAct架构的“思考-工具”循环逻辑,逐一解析5个子代理的代码实现细节、工具绑定方式与适用场景,让你不仅知道“代理能做什么”,更明白“代理是如何做到的”。
1 ReAct架构:多代理的底层运行核心
1.1 什么是ReAct架构?
ReAct(Reasoning + Acting)是一种让智能体“先思考、再行动”的交互模式,核心逻辑是**“思考→工具调用→结果反馈→再思考”**的循环,完美契合复杂任务的分步执行需求。
在本系统中,所有子代理均基于ReAct架构构建,其核心优势在于:
- 透明化决策:代理会明确思考“是否需要调用工具”“调用哪个工具”,而非直接输出结果;
- 可回溯纠错:若工具调用失败或结果不满足需求,代理可基于反馈调整策略,重新尝试;
- 灵活适配多工具:支持同时绑定多个工具,根据任务需求动态选择。
1.2 ReAct架构流程图
以sqler代理为例,其ReAct循环流程如下: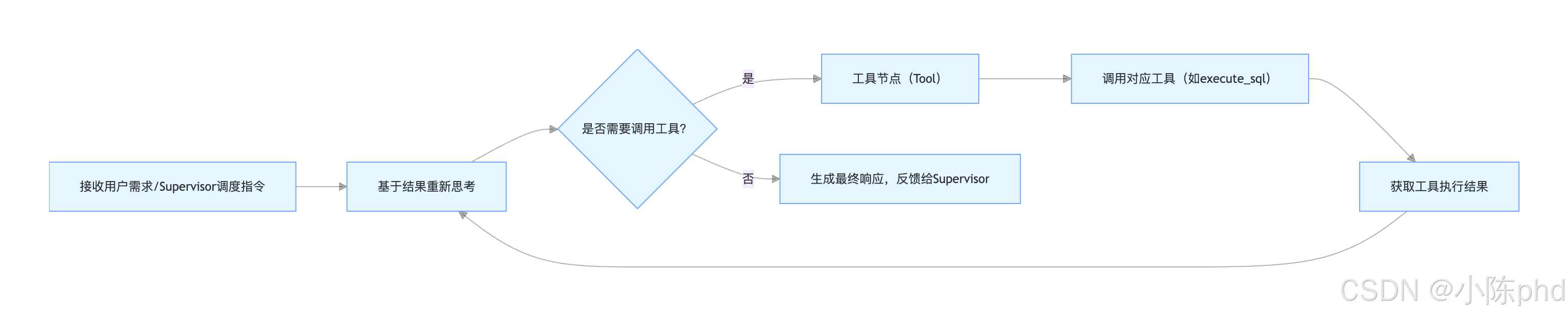
1.3 系统中ReAct架构的代码实现
系统通过create_react_agent_v1函数封装ReAct架构,支持快速创建绑定工具的代理,核心代码解析如下:
def create_react_agent_v1(llm, tools: List[BaseTool], system_prompt: str):
# 1. 工具映射:建立工具名称与工具实例的关联,方便调用
tool_map = {t.name: t for t in tools}
# 2. 绑定工具到LLM:让大模型知道可调用的工具列表及参数格式
llm_with_tools = llm.bind_tools(tools)
# 3. 思考节点(Think):大模型分析需求,决定是否调用工具、调用哪个工具
def think_node(state: ReActAgentState):
# 拼接系统提示词与历史消息
if not any(isinstance(m, SystemMessage) for m in state["messages"]):
messages = [SystemMessage(content=system_prompt)] + list(state["messages"])
else:
messages = list(state["messages"])
# LLM思考后生成响应(可能包含工具调用指令)
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
# 4. 工具节点(Tool):执行工具调用,返回结果
def tool_node(state: ReActAgentState):
last_msg = state["messages"][-1]
tool_messages = []
# 解析LLM的工具调用指令
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
for tool_call in last_msg.tool_calls:
try:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
# 调用对应的工具并获取结果
res = tool_map[tool_name].invoke(tool_args)
# 封装工具调用结果为ToolMessage
tool_messages.append(ToolMessage(content=str(res), tool_call_id=tool_call["id"]))
except Exception as e:
# 异常处理:记录工具调用失败原因
tool_messages.append(ToolMessage(content=f"Error: {str(e)}", tool_call_id=tool_call["id"]))
return {"messages": tool_messages}
# 5. 循环判断节点:决定继续调用工具还是终止
def should_continue(state: ReActAgentState):
last_msg = state["messages"][-1]
# 若LLM响应包含工具调用,则进入工具节点;否则终止循环
if hasattr(last_msg, "tool_calls") and last_msg.tool_calls:
return "tool"
return END
# 6. 构建状态图:串联思考节点、工具节点与循环判断
builder = StateGraph(ReActAgentState)
builder.add_node("think", think_node)
builder.add_node("tool", tool_node)
builder.add_edge(START, "think")
builder.add_conditional_edges("think", should_continue, {"tool": "tool", END: END})
builder.add_edge("tool", "think")
return builder.compile()
核心逻辑总结:通过StateGraph构建“思考→工具→思考”的循环链路,LLM负责“思考决策”,工具负责“执行落地”,两者协同完成任务。
2 5个子代理的详细实现与分工
基于上述ReAct架构,系统实现了5个功能差异化的子代理。下面逐一解析每个代理的工具绑定、系统提示词设计与核心代码逻辑。
2.1 sqler代理:结构化数据的“数据库管理员”
2.1.1 核心定位与适用场景
- 定位:专门处理MySQL中的结构化数据,支持增删改查与自定义SQL查询;
- 适用场景:查询销售记录、客户信息、产品数据、竞争对手市场份额等结构化需求;
- 核心优势:工具封装完整,支持安全的SQL执行(仅允许SELECT查询,避免数据风险)。
2.1.2 绑定工具与系统提示词
-
绑定工具:5个数据操作工具,覆盖结构化数据全生命周期管理:
add_sale:添加销售记录;delete_sale:删除销售记录;update_sale:更新销售记录(数量、金额);query_sale:按ID查询销售记录;execute_sql:执行只读SQL查询(支持复杂数据统计)。
-
系统提示词设计(精准引导工具调用):
db_agent_system_prompt = """You are a database expert. You can perform database operations and provide accurate data.
Available database tables:
1. customer_information (customer_id, customer_name, contact_info, region, customer_type)
2. product_information (product_id, product_name, category, unit_price, stock_level)
3. sales_data (sales_id, product_id, employee_id, customer_id, sale_date, quantity, amount, discount)
4. competitor_analysis (competitor_id, competitor_name, region, market_share)
When user asks about "companies" (公司), query the customer_information table.
When user asks about "products" (产品), query the product_information table.
When user asks about "sales" (销售), query the sales_data table.
Use execute_sql tool with SELECT queries to get data. Always respond in Chinese."""
2.1.3 代理创建与执行逻辑
# 创建sqler代理(基于ReAct架构)
db_agent = create_react_agent_v1(
llm=llm,
tools=[add_sale, delete_sale, update_sale, query_sales, execute_sql],
system_prompt=db_agent_system_prompt
)
# sqler代理节点封装(供LangGraph调用)
def db_node(state: AgentState):
print("--- [Worker: sqler] 正在执行结构化数据库查询...")
result = db_agent.invoke(state)
# 将结果封装为HumanMessage,反馈给Supervisor
return {
"messages": [
HumanMessage(content=result["messages"][-1].content, name="sqler")
]
}
2.1.4 执行示例
当用户提问“谁是市场份额最高的竞争对手?”时:
- Think节点:LLM分析需求,判断需调用
execute_sql工具,生成SQL查询SELECT competitor_name, region, market_share FROM competitor_analysis ORDER BY market_share DESC LIMIT 1; - Tool节点:调用
execute_sql工具执行查询,返回结果[{"competitor_name": "三星电子", "region": "韩国", "market_share": 22.5}]; - Think节点:LLM解析结果,确认无需继续调用工具,生成中文响应;
- 反馈给Supervisor:将结果封装为
sqler命名的消息,等待后续决策。
2.2 coder代理:数据处理的“Python工程师”
2.2.1 核心定位与适用场景
- 定位:通过Python代码执行复杂计算、数据统计与图表生成;
- 适用场景:需要数据分析、可视化展示、多步骤计算的需求(如“分析库存健康度”“生成销售趋势图”);
- 核心优势:支持任意Python代码执行,灵活适配各类数据处理场景。
2.2.2 绑定工具与系统提示词
- 绑定工具:
python_repl(基于LangChain的PythonREPL工具,支持执行Python代码并返回结果); - 系统提示词设计:
code_agent_system_prompt = "Run python code to display diagrams or output execution results"
2.2.3 代理创建与执行逻辑
# Python REPL工具初始化
repl = PythonREPL()
# 封装python_repl工具
@tool
def python_repl(code: Annotated[str, "The python code to execute to generate your chart."]):
"""
Use this to execute python code. If you want to see the output of a value,
you should print it out with `print(...)`. This is visible to the user.
"""
try:
result = repl.run(code)
except BaseException as e:
return f"Failed to execute. Error: {repr(e)}"
result_str = f"Successfully executed:\n```python\n{code}\n```\nStdout: {result}"
return result_str
# 创建coder代理
code_agent = create_react_agent_v1(
llm=llm,
tools=[python_repl],
system_prompt=code_agent_system_prompt
)
# coder代理节点封装
def code_node(state: AgentState):
print("--- [Worker: coder] 正在执行 Python 代码生成与计算...")
result = code_agent.invoke(state)
return {
"messages": [HumanMessage(content=result["messages"][-1].content, name="coder")]
}
2.2.4 执行示例
当用户提问“分析所有产品的平均单价,并判断库存是否健康(库存低于250视为预警)”时:
- Think节点:LLM分析需求,判断需调用
python_repl工具,生成Python代码(查询产品数据、计算平均单价、判断库存状态); - Tool节点:执行代码,返回结果
平均单价:4099.0元;库存预警:笔记本电脑(库存200); - 反馈给Supervisor:将代码执行结果与输出封装后返回。
2.3 graph_kg代理:关系挖掘的“图数据库专家”
2.3.1 核心定位与适用场景
- 定位:从Neo4j图知识库中检索实体关系型知识;
- 适用场景:探索实体关联(如“小米的合作品牌”)、挖掘关系型信息(如“华为的技术突破”)等需求;
- 核心优势:擅长处理“谁和谁有关系”的查询,查询效率高于传统文本检索。
2.3.2 核心依赖与执行逻辑
- 核心依赖:
GraphCypherQAChain(LangChain提供的Neo4j查询链,支持将自然语言转换为Cypher语句); - 关键优化:通过Few-shot示例提升Cypher生成准确性,避免语法错误。
2.3.3 代理代码实现
def graph_kg(state: AgentState):
print("--- [Worker: graph_kg] 正在执行 Neo4j 图知识库路径检索...")
# 1. 提取用户原始问题(从消息历史中筛选)
user_question = None
for msg in state["messages"]:
if isinstance(msg, HumanMessage) and not hasattr(msg, 'name'):
user_question = msg.content
break
if not user_question:
user_question = state["messages"][-1].content if state["messages"] else "无法获取问题"
# 2. 调用GraphCypherQAChain:自然语言→Cypher→图查询→结果解析
response = cypher_chain.invoke(user_question)
# 3. 封装结果并返回
final_response = [HumanMessage(content=response["result"], name="graph_kg")]
return {"messages": final_response}
2.3.4 执行示例
当用户提问“华为在技术创新方面有什么突破?”时:
- 提取原始问题:“华为在技术创新方面有什么突破?”;
- Cypher生成:基于Few-shot示例,生成Cypher语句
MATCH (c:Company)-[r:DEVELOPS|INTRODUCES]->(t) WHERE c.id CONTAINS '华为' RETURN c.id as company, type(r) as relation, t.id as technology; - 图查询:执行Cypher语句,从Neo4j中查询华为关联的技术实体;
- 结果解析:将查询结果转换为中文响应,如“华为通过DEVELOPS关系开发了鸿蒙操作系统,通过INTRODUCES关系推出了5G通信技术”。
2.4 vec_kg代理:细节检索的“向量检索专员”
2.4.1 核心定位与适用场景
- 定位:从Milvus向量库中检索细粒度文本知识;
- 适用场景:需要获取具体文本细节(如“苹果的环保目标”)、语义匹配的需求;
- 核心优势:基于语义相似性检索,无需依赖关键词,匹配更精准。
2.4.2 核心依赖与执行逻辑
- 核心依赖:Milvus向量库+DashScope Embeddings(生成文本向量)+RAG链(检索结果生成响应);
- 执行流程:用户问题→向量生成→Milvus相似性检索→RAG链生成简洁响应。
2.4.3 代理代码实现
def vec_kg(state: AgentState):
print("--- [Worker: vec_kg] 正在执行 Milvus 向量语义检索...")
# 1. 提取用户原始问题
user_question = None
for msg in state["messages"]:
if isinstance(msg, HumanMessage) and not hasattr(msg, 'name'):
user_question = msg.content
break
if not user_question:
user_question = state["messages"][-1].content if state["messages"] else "无法获取问题"
# 2. 构建RAG链:检索结果→简洁响应
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
rag_chain = prompt | graph_llm | StrOutputParser()
# 3. Milvus向量检索(获取Top2相关文档)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
docs = retriever.invoke(user_question)
# 4. 生成响应并返回
generation = rag_chain.invoke({"context": docs, "question": user_question})
final_response = [HumanMessage(content=generation, name="vec_kg")]
return {"messages": final_response}
2.4.4 执行示例
当用户提问“苹果公司在环保方面设定了什么长期目标?”时:
- 向量生成:将用户问题通过DashScope Embeddings生成向量;
- 相似性检索:在Milvus中检索与该向量最相似的2个文本片段;
- RAG生成:基于检索到的文本,生成简洁响应,如“苹果公司计划2030年实现全供应链碳中和,所有产品使用100%可再生材料,减少包装废弃物90%”。
2.5 chat代理:自然交互的“客服专员”
2.5.1 核心定位与适用场景
- 定位:无需调用工具,直接通过大模型生成自然语言响应;
- 适用场景:简单咨询、需求总结、结果整合等无需数据查询或代码执行的场景;
- 核心优势:响应速度快,语言流畅自然,适配纯文本交互需求。
2.5.2 代理代码实现
def chat(state: AgentState):
print("--- [Worker: chat] 正在生成自然语言回复...")
# 直接调用LLM生成响应,无需工具调用
messages = state["messages"]
model_response = llm.invoke(messages)
return {"messages": [HumanMessage(content=model_response.content, name="chatbot")]}
2.5.3 执行示例
当用户提问“介绍一下这个系统的功能?”时:
- 接收消息:获取用户原始问题;
- LLM生成:直接调用qwen-plus模型,生成自然语言响应;
- 反馈结果:“本系统是基于多代理混合RAG的智能问答系统,支持结构化数据查询、图知识检索、向量语义检索、Python代码执行等功能,能满足数据分析、知识查询等多种需求”。
3 5个子代理的核心差异与协作逻辑
3.1 核心差异对比表
| 代理名称 | 架构依赖 | 绑定工具 | 核心优势 | 适用场景 |
|---|---|---|---|---|
| sqler | ReAct架构 | add_sale/delete_sale/update_sale/query_sales/execute_sql | 结构化数据处理精准,支持SQL查询 | 销售、客户、产品、竞争对手数据查询/修改 |
| coder | ReAct架构 | python_repl | 复杂计算与可视化,代码执行灵活 | 数据分析、图表生成、多步骤计算 |
| graph_kg | GraphCypherQAChain | Neo4j图数据库 | 实体关系挖掘高效,支持关联查询 | 公司合作、技术创新、产品关联等关系型知识检索 |
| vec_kg | RAG链+Milvus | 向量检索工具 | 语义匹配精准,细粒度知识检索 | 文本细节查询、语义相似性匹配需求 |
| chat | 纯LLM | 无 | 响应快速,语言自然 | 简单咨询、结果总结、纯文本交互 |
3.2 代理协作逻辑
在实际任务中,Supervisor会根据需求类型调度多个代理协同工作,例如:
- 用户需求:“查询所有产品的平均单价,分析库存健康度,并生成总结”;
- 调度流程:Supervisor→coder(执行计算与分析)→chat(生成总结响应);
- 协作结果:coder返回数据分析结果,chat整合结果生成自然语言总结,最终反馈给用户。
4 常见问题与调试技巧
4.1 代理工具调用失败
- 排查方向1:工具参数是否正确(如
query_sales的sales_id是否为整数); - 排查方向2:依赖服务是否正常(如MySQL、Neo4j、Milvus是否启动);
- 排查方向3:API密钥是否有效(如DashScope API密钥是否配置正确)。
4.2 代理响应不符合预期
- 优化方案1:调整系统提示词(如sqler代理增加表结构细节,提升工具调用准确性);
- 优化方案2:增加Few-shot示例(如图代理补充更多Cypher生成示例);
- 优化方案3:调整检索参数(如vec_kg代理修改
search_kwargs={"k": 3},增加检索结果数量)。
4.3 代理循环调用
- 问题原因:Supervisor未正确判断结果是否满足需求,导致重复调度同一代理;
- 解决方法:优化Supervisor的路由规则,增加“结果满足需求则终止”的判断逻辑。
5 总结与后续预告
本文深入拆解了5个子代理的实现细节,核心亮点在于:
- 所有代理基于ReAct架构构建,实现“思考→工具→反馈”的闭环执行;
- 每个代理绑定专属工具,分工明确,适配不同场景需求;
- 通过示例清晰展示了代理的执行流程,便于落地调试。
这些代理作为系统的“执行团队”,是完成复杂任务的核心支撑,而它们的高效协作,离不开Supervisor的智能调度。
后续博客预告
下一篇我们将聚焦系统的“大脑”——Supervisor,深入解析其任务路由规则、代理状态管理、循环保护机制,揭秘“如何让多个代理有序协作,避免重复工作”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)