PPO算法深度解析:为什么它如此强大又如此“挑食”?
AI博主maoku深度解析PPO算法:揭秘其“在线策略”本质——为何不能重用数据、为何必须用向量化环境。从On-policy/Off-policy哲学对比,到裁剪机制原理、向量化加速实践,再到完整代码实现与调参指南,助你真正掌握工业界首选强化学习算法。
大家好,我是AI技术博主maoku。今天我们要深入探讨一个在深度强化学习中绕不开的算法——PPO(近端策略优化)。如果你曾经尝试训练游戏AI、机器人控制或者推荐系统,很可能已经接触过它。PPO以其出色的稳定性和良好的性能,成为工业界最受欢迎的强化学习算法之一。
但你是否曾困惑:为什么PPO训练时不能像DQN那样重用数据?为什么每个教程都强调要使用向量化环境?今天,我将为你彻底解开这些谜团。
引言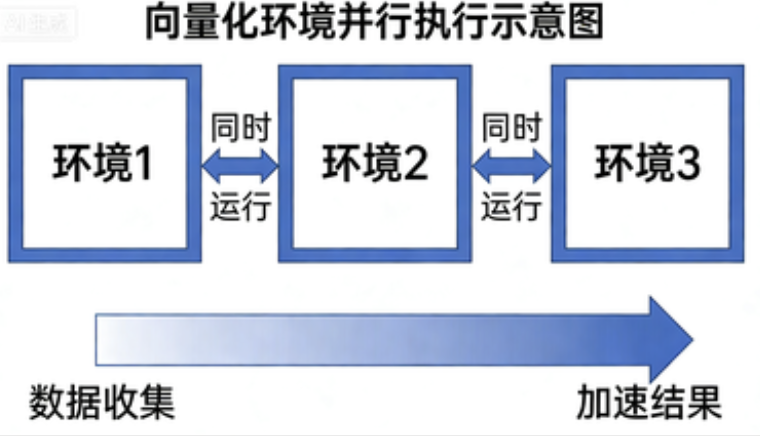 :从游戏AI到现实应用
:从游戏AI到现实应用
想象一下,你正在训练一个玩《星际争霸》的AI。传统的强化学习算法如DQN,就像是一个有“记忆”的学生——它会反复复习过去的对局经验。而PPO则像是一个“活在当下”的学生,它学完一批新对局后,就把之前的经验全部忘掉,重新开始学习。
这种独特的“健忘”特性,正是PPO算法的核心特点,也决定了它的使用方式和优化策略。无论是在游戏AI、机器人控制、自动驾驶,还是在金融交易策略优化中,理解PPO的这些特性都至关重要。
一、PPO技术原理:深入浅出解析
1.1 On-policy vs Off-policy:两种学习哲学
要理解PPO,首先要明白强化学习中的两种基本范式:
On-policy(在线策略):
- 原则:“我怎么行动,就怎么学习”
- 特点:只能使用当前策略收集的数据来更新自己
- 类比:厨师只能品尝自己刚做的菜来改进手艺
- 代表算法:PPO、A2C、TRPO
Off-policy(离线策略):
- 原则:“我看别人怎么行动,也能学习”
- 特点:可以使用任意策略收集的数据来学习
- 类比:厨师可以通过看美食节目学习别人的技巧
- 代表算法:DQN、DDPG、SAC、TD3
1.2 PPO的核心创新:策略更新的“安全绳”
PPO最大的贡献在于解决了策略梯度方法的一个根本问题:更新步长难以控制。
传统策略梯度的问题:
# 简化的策略梯度更新
old_policy = current_policy()
data = collect_data(old_policy)
new_policy = old_policy + learning_rate * gradient
# 问题:如果learning_rate太大,新策略可能完全“跑偏”
# 导致之前收集的数据全部失效,需要重新开始
PPO的解决方案:
PPO引入了“裁剪”(clipping)机制,就像给策略更新加了“安全绳”:
# PPO的裁剪目标函数(简化理解)
def ppo_loss(ratio, advantage, clip_epsilon=0.2):
# ratio = 新策略概率 / 旧策略概率
unclipped = ratio * advantage
clipped = torch.clamp(ratio, 1-clip_epsilon, 1+clip_epsilon) * advantage
# 取两者中较小的,防止更新过大
return torch.min(unclipped, clipped)
这个简单的裁剪操作,让PPO在保持更新效率的同时,大幅提高了稳定性。
1.3 PPO与其他主流算法的对比
为了更直观地理解PPO的特点,我们来看看它与其它主流算法的对比:
| 特性 | PPO (在线策略) | DDPG (离线策略) | A2C (在线策略) | SAC (离线策略) |
|---|---|---|---|---|
| 策略类型 | 随机策略 | 确定性策略 | 随机策略 | 随机策略 |
| 数据重用 | ❌ 不能重用 | ✅ 可重用 | ❌ 不能重用 | ✅ 可重用 |
| 采样效率 | 低 | 高 | 低 | 高 |
| 稳定性 | 高 | 中等 | 中等 | 高 |
| 探索方式 | 策略随机性 | 动作噪声 | 策略随机性 | 最大熵原理 |
| 适合场景 | 连续/离散动作 | 连续动作 | 连续/离散动作 | 连续动作 |
关键洞察:
- PPO vs A2C:两者都是在线策略,但PPO通过裁剪机制获得了更好的稳定性
- PPO vs DDPG:PPO采样效率较低但更稳定,DDPG效率高但需要精细调参
- PPO vs SAC:SAC基于最大熵原理,探索更系统,数据效率更高
二、为什么向量化环境对PPO如此关键?
2.1 PPO的“数据饥饿症”
PPO作为在线策略算法,有一个天生的特点:数据用过即弃。这就像一次性餐具——吃完一顿饭就必须扔掉,不能洗洗再用。
数据生命周期对比:
# DQN(离线策略)的数据流
experience_replay = [] # 经验回放池
for episode in range(10000):
data = collect_data()
experience_replay.append(data) # 保存到池中
# 每次更新从池中随机抽样,一条数据可以用很多次
# PPO(在线策略)的数据流
for update in range(1000):
data = collect_data() # 收集新数据
update_policy(data) # 用新数据更新
data = [] # 清空!不能重用
这种特性导致PPO需要持续不断地收集新数据,数据收集时间成为训练的主要瓶颈。
2.2 向量化环境:PPO的“数据加速器”
向量化环境的本质是并行执行多个环境实例,就像超市开了多个收银台:
# 非向量化(单线程)
env = make_env("CartPole-v1")
for step in range(1000):
action = policy(obs)
obs, reward, done, info = env.step(action) # 一次只执行一步
# 慢!大部分时间在等待环境响应
# 向量化(并行)
envs = gym.vector.make("CartPole-v1", num_envs=16)
for step in range(1000):
actions = policy(obs_batch) # obs_batch形状:(16, obs_dim)
obs_batch, rewards, dones, infos = envs.step(actions) # 同时执行16步!
# 快!16倍速度收集数据
2.3 向量化程度的性能影响
让我们看看不同并行度下的实际性能差异:
| 环境数量 | 收集2048步数据时间 | 相对速度 | 适用场景 |
|---|---|---|---|
| 1个环境 | ~20秒 | 1x | 仅调试用 |
| 4个环境 | ~5秒 | 4x | 小型实验 |
| 16个环境 | ~1.3秒 | 15x | 标准配置 |
| 64个环境 | ~0.4秒 | 50x | 大规模训练 |
| 256个环境 | ~0.1秒 | 200x | 工业级应用 |
实践建议:对于大多数任务,16-64个并行环境是性价比最高的选择。太少则数据收集慢,太多则可能受限于CPU/GPU计算资源。
三、实践指南:从零开始实现PPO训练
3.1 环境搭建与配置
import gym
import torch
import numpy as np
from torch import nn
import torch.optim as optim
# 1. 创建向量化环境
import gym
envs = gym.vector.make("CartPole-v1", num_envs=4)
# 2. 神经网络架构定义
class PolicyNetwork(nn.Module):
def __init__(self, obs_dim, action_dim):
super().__init__()
# 使用正交初始化(关键!)
self.fc1 = self.layer_init(nn.Linear(obs_dim, 64))
self.fc2 = self.layer_init(nn.Linear(64, 64))
self.actor = self.layer_init(nn.Linear(64, action_dim), std=0.01)
self.critic = self.layer_init(nn.Linear(64, 1), std=1.0)
@staticmethod
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
"""正交初始化:RL训练稳定的关键技巧"""
nn.init.orthogonal_(layer.weight, std)
nn.init.constant_(layer.bias, bias_const)
return layer
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
return self.actor(x), self.critic(x)
为什么正交初始化如此重要?
- 梯度稳定:防止深度网络中的梯度消失/爆炸
- 激活均衡:确保各层激活值保持合理范围
- 特征多样:促使不同神经元学习不同特征
- RL特别需求:策略梯度方法对初始化极为敏感
3.2 PPO训练循环完整实现
class PPOTrainer:
def __init__(self, env_name="CartPole-v1", num_envs=4):
self.envs = gym.vector.make(env_name, num_envs=num_envs)
self.obs_dim = self.envs.single_observation_space.shape[0]
self.action_dim = self.envs.single_action_space.n
# 初始化策略网络
self.policy = PolicyNetwork(self.obs_dim, self.action_dim)
self.optimizer = optim.Adam(self.policy.parameters(), lr=2.5e-4)
# PPO超参数
self.gamma = 0.99 # 折扣因子
self.gae_lambda = 0.95 # GAE参数
self.clip_epsilon = 0.2 # 裁剪系数
self.epochs = 4 # 每批数据训练轮数
self.batch_size = 64
def collect_trajectories(self, num_steps=2048):
"""收集一批轨迹数据"""
obs = self.envs.reset()
dones = np.zeros(self.envs.num_envs, dtype=bool)
# 临时缓冲区(注意:每次收集都会覆盖之前的数据)
storage = {
'obs': np.zeros((num_steps, self.envs.num_envs, self.obs_dim)),
'actions': np.zeros((num_steps, self.envs.num_envs)),
'rewards': np.zeros((num_steps, self.envs.num_envs)),
'dones': np.zeros((num_steps, self.envs.num_envs)),
'values': np.zeros((num_steps, self.envs.num_envs)),
'log_probs': np.zeros((num_steps, self.envs.num_envs)),
}
for step in range(num_steps):
# 转换为张量并获取动作
obs_tensor = torch.FloatTensor(obs)
with torch.no_grad():
action_logits, values = self.policy(obs_tensor)
dist = torch.distributions.Categorical(logits=action_logits)
actions = dist.sample()
log_probs = dist.log_prob(actions)
# 执行动作
next_obs, rewards, dones, infos = self.envs.step(actions.numpy())
# 存储数据(这些数据只用一次!)
storage['obs'][step] = obs
storage['actions'][step] = actions.numpy()
storage['rewards'][step] = rewards
storage['dones'][step] = dones
storage['values'][step] = values.squeeze(-1).numpy()
storage['log_probs'][step] = log_probs.numpy()
obs = next_obs
return storage
def compute_advantages(self, rewards, values, dones):
"""计算GAE优势函数"""
advantages = np.zeros_like(rewards)
last_gae = 0
# 反向计算
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_value = 0 # 终止状态价值为0
else:
next_value = values[t+1] * (1 - dones[t])
delta = rewards[t] + self.gamma * next_value - values[t]
advantages[t] = last_gae = delta + self.gamma * self.gae_lambda * (1 - dones[t]) * last_gae
return advantages
def update_policy(self, storage):
"""PPO核心更新步骤"""
# 展平数据
obs = torch.FloatTensor(storage['obs']).reshape(-1, self.obs_dim)
actions = torch.LongTensor(storage['actions']).reshape(-1)
old_log_probs = torch.FloatTensor(storage['log_probs']).reshape(-1)
advantages = torch.FloatTensor(self.compute_advantages(
storage['rewards'], storage['values'], storage['dones']
)).reshape(-1)
# 多轮小批量更新
for epoch in range(self.epochs):
# 随机打乱
indices = torch.randperm(len(obs))
for start in range(0, len(indices), self.batch_size):
end = start + self.batch_size
batch_idx = indices[start:end]
# 获取批次数据
batch_obs = obs[batch_idx]
batch_actions = actions[batch_idx]
batch_old_log_probs = old_log_probs[batch_idx]
batch_advantages = advantages[batch_idx]
# 计算新策略的输出
action_logits, values = self.policy(batch_obs)
dist = torch.distributions.Categorical(logits=action_logits)
new_log_probs = dist.log_prob(batch_actions)
# 策略比率
ratio = torch.exp(new_log_probs - batch_old_log_probs)
# PPO裁剪目标
surr1 = ratio * batch_advantages
surr2 = torch.clamp(ratio, 1-self.clip_epsilon, 1+self.clip_epsilon) * batch_advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 价值函数损失
value_loss = nn.MSELoss()(values.squeeze(-1), batch_advantages + storage['values'].reshape(-1)[batch_idx])
# 总损失
loss = policy_loss + 0.5 * value_loss
# 反向传播
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5)
self.optimizer.step()
def train(self, total_timesteps=100000):
"""主训练循环"""
num_updates = total_timesteps // (self.envs.num_envs * 2048)
for update in range(num_updates):
# 关键:每次更新都要收集新数据
storage = self.collect_trajectories(num_steps=2048)
# 更新策略
self.update_policy(storage)
# 清空storage(逻辑上)
# 实际上,collect_trajectories每次都会创建新的storage
# 打印进度
if update % 10 == 0:
mean_reward = np.mean(np.sum(storage['rewards'], axis=0))
print(f"Update {update}, Mean Reward: {mean_reward:.2f}")
# 启动训练
if __name__ == "__main__":
trainer = PPOTrainer(num_envs=16)
trainer.train(total_timesteps=100000)
3.3 大规模训练优化建议
对于需要大规模训练的场景,特别是当涉及到复杂环境或大量并行实例时,手动管理计算资源会变得复杂。这时候,考虑使用专业托管平台如【LLaMA-Factory Online】会显著提高效率,它提供了:
- 自动化的资源调度和扩缩容
- 内置的向量化环境管理
- 分布式训练支持
- 实验跟踪和结果可视化
- 预配置的PPO优化模板
四、效果评估:如何验证PPO训练效果?
4.1 关键监控指标
在PPO训练过程中,需要密切监控以下指标:
def monitor_training(storage, update_step):
"""监控训练关键指标"""
metrics = {
# 1. 性能指标
'mean_reward': np.mean(np.sum(storage['rewards'], axis=0)),
'max_reward': np.max(np.sum(storage['rewards'], axis=0)),
'episode_length': np.mean(np.sum(1 - storage['dones'], axis=0)),
# 2. 策略更新指标
'policy_ratio': np.mean(np.exp(
storage['new_log_probs'] - storage['old_log_probs']
)),
'clip_fraction': np.mean(
(storage['policy_ratio'] > 1.2) | (storage['policy_ratio'] < 0.8)
),
# 3. 价值函数指标
'value_loss': compute_value_loss(storage),
'advantage_mean': np.mean(storage['advantages']),
'advantage_std': np.std(storage['advantages']),
# 4. 探索指标
'action_entropy': compute_entropy(storage['action_probs']),
}
return metrics
4.2 常见问题诊断
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 奖励不增长 | 学习率太大/太小 | 调整学习率(通常2.5e-4到1e-3) |
| 训练不稳定 | 裁剪系数不合适 | 调整clip_epsilon(通常0.1-0.3) |
| 探索不足 | 初始化问题/熵奖励不够 | 检查正交初始化,考虑增加熵奖励 |
| 过拟合 | 批量大小太小 | 增加批量大小或并行环境数 |
| 收敛慢 | 并行环境数不足 | 增加向量化环境数量 |
4.3 可视化分析工具
import matplotlib.pyplot as plt
def plot_training_progress(logs):
"""绘制训练进度图"""
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 1. 奖励曲线
axes[0,0].plot(logs['mean_reward'])
axes[0,0].set_title('Mean Reward per Episode')
axes[0,0].set_xlabel('Update Step')
# 2. 策略比率分布
axes[0,1].hist(logs['policy_ratio'], bins=50, alpha=0.7)
axes[0,1].axvline(x=0.8, color='r', linestyle='--')
axes[0,1].axvline(x=1.2, color='r', linestyle='--')
axes[0,1].set_title('Policy Ratio Distribution')
# 3. 价值损失
axes[1,0].plot(logs['value_loss'])
axes[1,0].set_title('Value Loss')
axes[1,0].set_xlabel('Update Step')
# 4. 动作熵
axes[1,1].plot(logs['action_entropy'])
axes[1,1].set_title('Action Entropy (Exploration)')
axes[1,1].set_xlabel('Update Step')
plt.tight_layout()
plt.show()
五、总结与展望
5.1 PPO的核心优势总结
通过今天的深入探讨,我们可以看到PPO之所以成为工业界首选,主要基于以下几点:
- 出色的稳定性:裁剪机制提供了更新步长的安全保障
- 调参友好:相对于其他RL算法,PPO的超参数更鲁棒
- 广泛适用性:支持连续和离散动作空间
- 实现相对简单:核心思想直观,易于实现和调试
5.2 未来发展趋势
随着强化学习技术的发展,我们观察到以下趋势:
-
PPO的持续改进:
- 自适应裁剪系数
- 更高效的重要性采样方法
- 与模型预测控制(MPC)的结合
-
向量化环境的进化:
- 异构环境支持(不同环境类型混合)
- 动态环境数量调整
- GPU原生环境模拟
-
硬件与算法协同优化:
- 针对特定硬件(如TPU)优化的PPO变体
- 分布式收集与更新的更优平衡
5.3 给实践者的建议
基于我多年的实践经验,给正在或准备使用PPO的开发者几点建议:
- 从简单开始:先用CartPole等简单环境验证实现正确性
- 重视向量化:不要低估并行环境带来的性能提升
- 监控是关键:建立完善的监控体系,及时发现训练问题
- 耐心调参:RL训练有时需要多次尝试才能找到最优参数
- 利用社区:参考CleanRL等高质量实现,避免重复造轮子
记住,PPO虽然强大,但它对数据收集效率有较高要求。在实际项目中,如果遇到大规模训练需求,合理利用云平台和专业工具可以事半功倍。
希望这篇深入浅出的解析能帮助你更好地理解和应用PPO算法。如果你在实践过程中遇到任何问题,或者有更多关于RL算法的疑问,欢迎在评论区留言讨论!
学习资源推荐:
- PPO原始论文
- CleanRL实现 - 极简清晰的RL实现
- Stable-Baselines3 - 生产级RL库
- RL基础知识课程 - OpenAI的免费RL教程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)