论文阅读:Training language models to follow instructions with human feedback
经过RLHF的模型模型不仅符合训练它的标注者的偏好,也能很好地泛化到未参与训练数据的“保留(held-out)”标注者的偏好上,此外能够将“遵循指令”的能力泛化到其微调数据中很少见的任务上的潜力,例如非英语语言和代码相关的任务。,在Instruct GPT中,KL散度的添加是为了为了防止强化学习模型在优化奖励模型时过拟合,具体而言,在强化学习的每一步,模型生成的最终奖励R(x,y)不仅仅是奖励模型
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
引言
引言首先指出了当前大型语言模型(LMs)存在的一个核心问题:模型规模变大并不意味着它们能更好地遵循用户的意图 。具体而言,大型模型经常生成不真实、有毒或对用户毫无帮助的输出,这是因为语言模型的训练目标(预测网页上的下一个 token)与用户希望的目标(“有用且安全地遵循指令”)是错位的。作者的目标是让模型在“有用性”(Helpful)、“诚实性”(Honest)和“无害性”(Harmless)这三个方面与用户意图对齐。
为了解决上述问题,论文提出使用人类反馈强化学习(RLHF)来微调 GPT-3,使其能遵循广泛的书面指令,该方法分为三个步骤展开,其中监督学习部分使用标注者编写的 prompt 和演示数据微调 GPT-3 ;奖励模型构建部分收集模型输出的排名数据,训练一个奖励模型;强化学习部分使用 PPO 算法,根据奖励模型的反馈进一步微调模型。
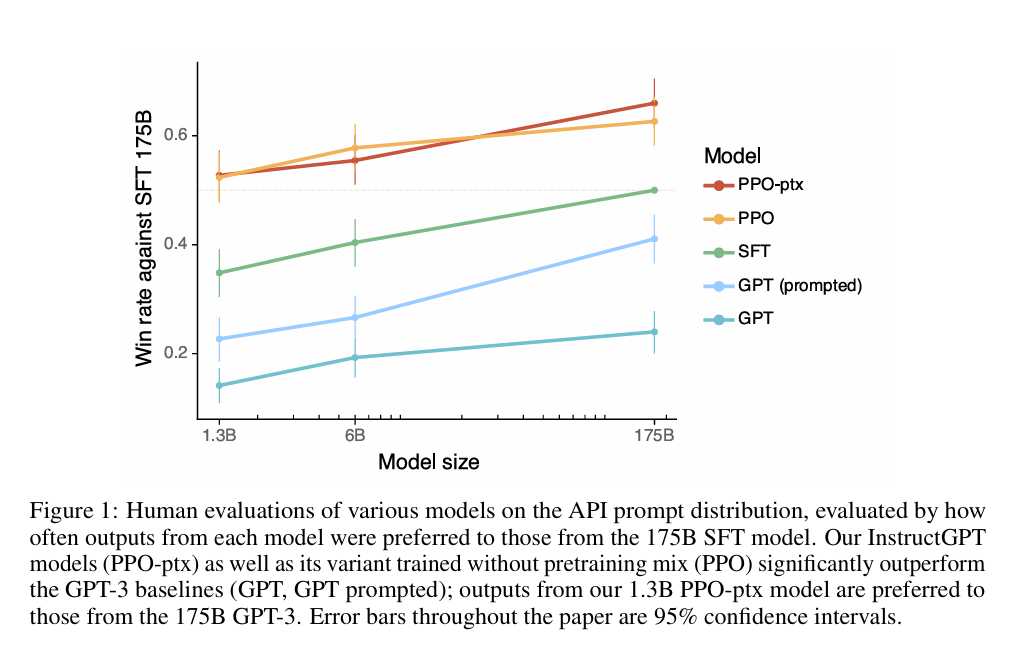
在 RLHF 过程中,模型在公共 NLP 数据集上的性能可能会下降。作者发现通过将 PPO 更新与预训练分布的对数似然更新混合(即 PPO-ptx 模型),可以大大减少这种性能衰退。经过RLHF的模型模型不仅符合训练它的标注者的偏好,也能很好地泛化到未参与训练数据的“保留(held-out)”标注者的偏好上,此外能够将“遵循指令”的能力泛化到其微调数据中很少见的任务上的潜力,例如非英语语言和代码相关的任务。
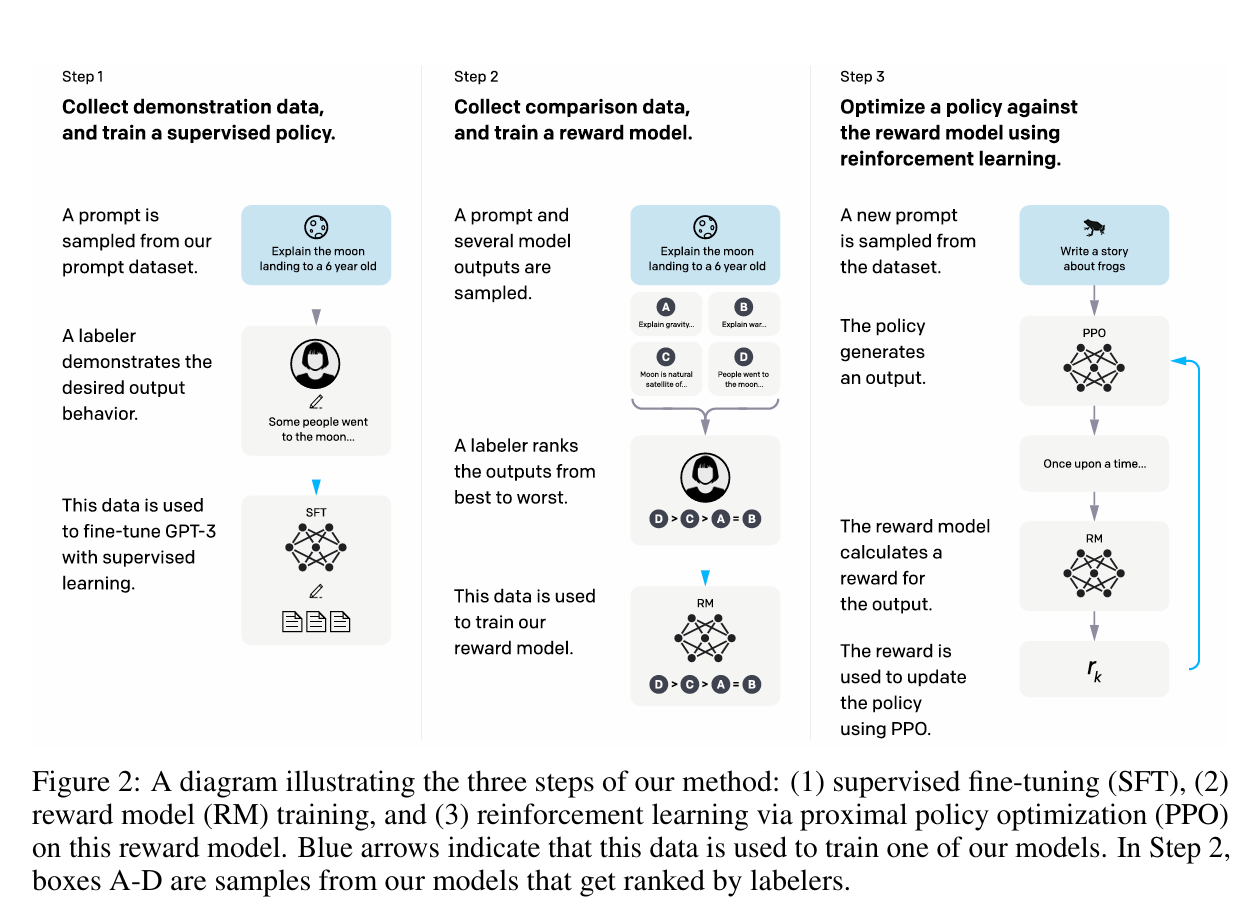
方法与实验细节
从预训练语言模型,通过三个步骤使其与用户意图对齐。其中,步骤一监督微调(SFT)收集由人类标注者针对输入的 prompt 提供期望的输出行为,而后使用这些数据对预训练的 GPT-3 模型进行监督学习微调;步骤二训练奖励模型(RM)收集比较数据。对于同一个 prompt,模型生成多个输出,由人类标注者根据优劣进行排名,利用这些排名数据训练一个奖励模型,该模型的目标是预测人类更偏好哪个输出;步骤三强化学习(RL)使用 PPO算法针对奖励模型优化策略,奖励模型的输出作为标量奖励,指导 SFT 模型进行微调,使其生成的输出能获得更高的奖励。
其中,RM使用6B参数的模型,通过让标注者对 K 个(4到9个)响应进行排名来提高效率,一次性训练所有个比较对,RL环境是一个“老虎机”(bandit)环境,给定 prompt 生成响应并获得奖励,为了防止模型过度优化奖励模型而偏离原始分布,在每个 token 上增加了 KL 散度惩罚,此外为了解决在公共 NLP 数据集上的性能退化问题,作者在 PPO 更新中混合了预训练梯度,由此得到的模型是PPO-ptx
本部分需要补充的内容:
1.KL散度
KL 散度(也称为相对熵)是衡量两个概率分布之间差异的一种非对称度量。它量化了当使用分布 Q来近似真实分布P时所损失的信息量。对于离散概率分布P和Q,其公式为:,在Instruct GPT中,KL散度的添加是为了为了防止强化学习模型在优化奖励模型时过拟合,具体而言,在强化学习的每一步,模型生成的最终奖励R(x,y)不仅仅是奖励模型给出的分数
,还减去了一个 KL 惩罚项:
,其中带有RL/SFT上标的分别为当前正在训练的强化学习模型的输出概率和原始监督微调模型的输出概率。
注意,这里是RL模型根据提示词生成一个完整的回复序列,而后计算自己生成每个token yt的概率,而后将完全相同的序列输入SFT模型中,计算“如果是我,生成这个token yt的概率是多少”,即
,所以这里不存在长度不一致的问题,因而KL散度可以进行计算。
2.如何在更新中混合预训练梯度
作者发现单纯使用 RLHF(即只优化人类偏好奖励)会导致模型在公共 NLP 数据集(如问答、阅读理解等)上的性能下降,这种现象被称为“对齐税”。因此作者在在进行PPO梯度更新的同时,混合了预训练梯度的更新,训练的目标函数变成了一个组合目标:既要最大化人类偏好奖励(PPO 目标),又要最大化预训练数据分布的对数似然。总的优化目标函数可以表示为:,其中
是包含KL惩罚的标准的强化学习目标,
这是预训练损失项,
是原始的预训练数据集。【这里说人话就是在训练 PPO 的同时,随机抽取一些原始的预训练文本让模型填空(相当于重复预训练过程),并将这部分的损失纳入PPO的优化指标】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)