论文阅读:Chain-of-thought prompting elicits reasoning in large language models
在OOD测试中【具体而言是测试样本的步骤数多于提示示例中的步骤数,旨在测试模型是否学会了推理的逻辑模式,而不仅仅是模仿长度】,标准提示在测试中(即更长的序列)中完全失败,无法解决问题,但使用思维链提示,模型展现出了良好的长度泛化能力。具体而言,让模型只输出数学公式。让模型先给答案再出推理。实际上思维链提示是一种随模型规模扩大而涌现的能力,对于小模型,思维链提示并没有带来性能提升,甚至会导致流畅但不
Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models[J]. Advances in neural information processing systems, 2022, 35: 24824-24837.
引言与方法提出
虽然扩大模型规模(Scaling up)带来了性能提升和样本效率等好处,但这并不足以让模型在具有挑战性的任务上——如算术、常识和符号推理——达到高性能。作者通过结合两个主要思路来解锁大模型的推理能力,一是利用中间推理步骤的价值,即算术推理可以通过生成通向最终答案的自然语言理由而获益 ;二是大模型ICL能力,大型语言模型具备通过提示进行上下文少样本学习的能力,无需为每个新任务微调单独的模型。
定义思维链为一系列导致最终输出的中间自然语言推理步骤,作者提出了一种名为 “思维链提示”的方法。该方法在提示中向模型展示三元组示例:(输入, 思维链, 输出)。事实上思维链方法具有四个优势,一个是问题分解,原则上允许模型将多步问题分解为中间步骤,这意味着可以将更多的计算资源分配给需要更多推理步骤的问题;第二是可解释性,提供了一个观察模型行为的可解释窗口,展示了模型是如何得出特定答案的,并提供了调试推理路径错误的机会;三是广泛适用性,可用于数学应用题、常识推理和符号操作等任务,原则上适用于任何人类可以通过语言解决的任务;四是易于获取,只需在少样本提示的示例中包含思维链序列,即可在足够大的现成语言模型中轻松激发这种能力。
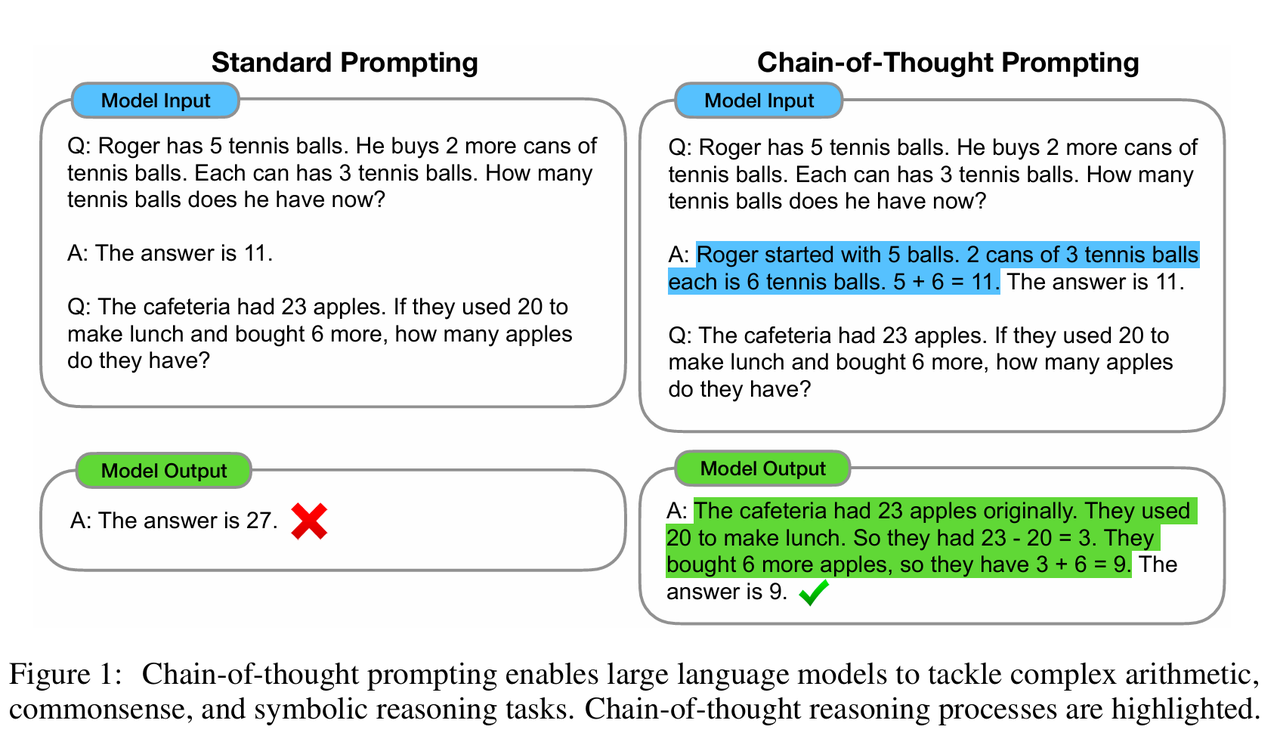
算术推理实验
这一部分展示了思维链提示带来的巨大性能提升,尤其是随着模型规模的扩大。实际上思维链提示是一种随模型规模扩大而涌现的能力,对于小模型,思维链提示并没有带来性能提升,甚至会导致流畅但不合逻辑的推理,表现不如标准提示,只有在约 100B 参数量级以上的模型中,思维链提示才开始产生显著的性能增益。
此外,思维链对于更复杂问题的增益更大,对于只需一步推理的简单问题提升则非常微小甚至为负,作者分析了 LaMDA 137B 在 GSM8K 上的错误,发现对于回答错误的情况,46% 是轻微错误(如计算错误),54% 是语义理解或逻辑连贯性的大错误。通过扩大模型规模(如从 PaLM 62B 到 540B),可以修正大部分语义理解错误。
为了证明思维链的有效性并非来自其他因素(如计算量增加),作者进行了严谨的消融实验。具体而言,让模型只输出数学公式。结果显示这对 GSM8K 这种语义复杂的题目帮助不大,证明自然语言的推理步骤是必要的;让模型输出与方程字符数相等的点号(...)来模拟消耗计算资源。结果与基准持平,证明思维链的成功不仅仅是因为“让模型想久一点”,而是自然语言推理步骤本身在起作用;让模型先给答案再出推理。效果与基准持平,证明模型确实依赖生成的思维链来推导最终答案,而不是事后解释。
常识推理实验和符号推理实验
对于常识推理实验得出的结论是,思维链提示不仅限于数学,还能有效提升大模型在通过背景知识进行多步推理时的表现。对于符号推理实验得出的结论是,在一些看似简单的任务中,小模型仍然无法完成,说明对未见过的符号进行抽象操作的能力是在 100B 参数规模左右才涌现的;在OOD测试中【具体而言是测试样本的步骤数多于提示示例中的步骤数,旨在测试模型是否学会了推理的逻辑模式,而不仅仅是模仿长度】,标准提示在测试中(即更长的序列)中完全失败,无法解决问题,但使用思维链提示,模型展现出了良好的长度泛化能力。尽管性能低于域内测试,但随着模型规模扩大,性能曲线呈上升趋势,证明了对于足够大的模型,思维链提示不仅能解决当前问题,还能促进模型将推理逻辑泛化到比示例更长的序列中。
讨论与结论
思维链推理被视为模型规模扩大带来的一种“涌现能力”,对于许多标准提示表现平平(scaling curve 平缓)的任务,思维链提示能带来显著的性能增长曲线。作者提出一个重要观点:标准提示仅仅提供了大语言模型能力的“下界”(lower bound),思维链提示进一步拓展了模型能解决的任务范围。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)