AI 真的有思想吗?用大白话拆解大语言模型(LLM)的“大脑”
这只动物没有过马路,因为它太累了。作为人类,你读到**“它”**字时,你的大脑会瞬间反应过来:“它”指的是“动物”,而不是“马路”。为什么?因为“马路”不会“累”。这就是注意力——理解一个词时,要同时关注上下文里的其他词。看完了这四层洋葱,你可能会发现:LLM 并没有科幻电影里的“灵魂”。它没有意识,只有概率。它不懂逻辑,只有向量距离。它不理解你,它只是注意到了你话语中的关键词。但正是这种纯粹的数
引言 当 ChatGPT 写出一首唯美的诗,或者帮你改好一段复杂的代码时,你是否产生过一种错觉:屏幕背后是不是真的坐着一个人?
这种“像人”的错觉,到底是怎么产生的?今天,我们不谈复杂的数学公式,而是通过几个生活中的例子,带你彻底看懂这个改变世界的“黑盒”——大语言模型(LLM)。
第一章:本质——它不是搜索引擎,它是“超级接龙王”
很多人以为问 AI 问题时,它是在像谷歌一样去数据库里找现成的答案。大错特错。
LLM 的本质只有一个核心任务:Next Token Prediction(预测下一个字)。
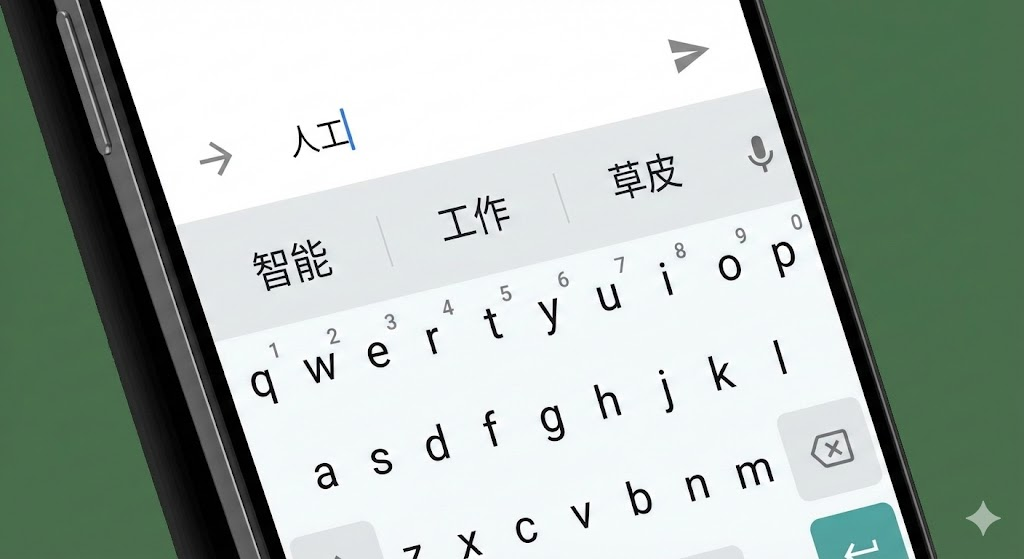
🌰 举个例子:手机输入法
拿出你的手机,输入“人工”两个字,输入法大概率会推荐“智能”。
-
如果你一直点推荐词,它可能会变成:“人工智能技术的发展……”
-
这其实就是最初级的语言模型。
🚀 LLM 强在哪?
现在的 LLM(比如 GPT-4),之所以被称为“大”模型,是因为它“读”过的书太多了。它阅读了几乎整个互联网的文本。 当你输入:“床前明月光”,模型并不是在背诗,它是在计算:
“根据我在千亿级数据里看到的规律,‘光’字后面接‘疑’字的概率是 99.9%,接‘饭’字的概率是 0.001%。”
小结: AI 并没有“思考”你在问什么,它只是在用惊人的概率计算能力,猜你应该想听到的下一个字是什么。
第二章:理解——机器不读字,机器读“地图”
既然只是猜字,为什么它能听懂“把这句话翻译成英文”这种复杂的指令?这就涉及到了 AI 的“语言地图”——Embedding(嵌入)。
🗺️ 词汇的 GPS 坐标
计算机不认识中文,也不认识英文,它只认识数字。 在训练中,模型会把每一个词(Token)变成一串数字坐标(向量)。
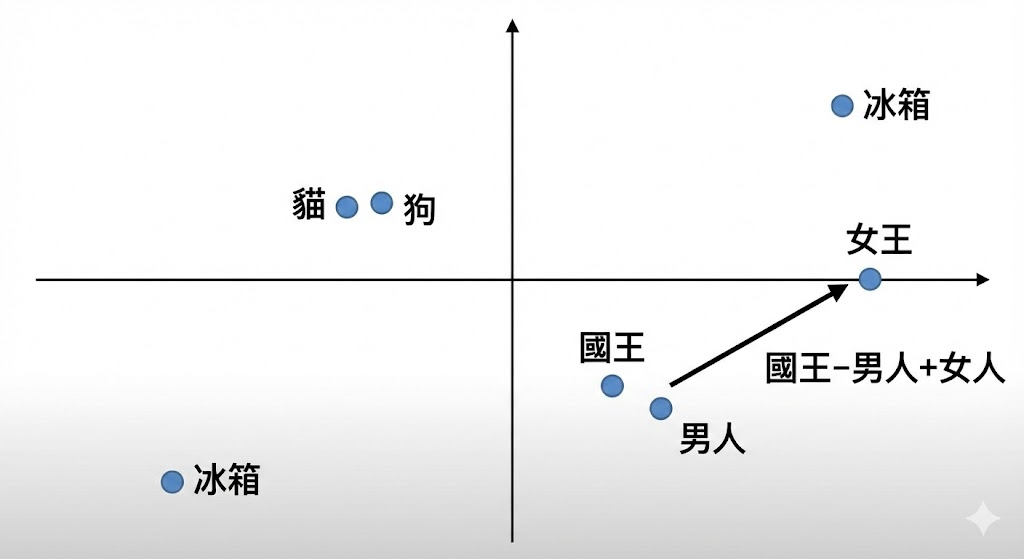
想象一张巨大的二维地图:
-
**“猫”**的坐标是 (10, 10)
-
**“狗”**的坐标是 (11, 11) —— 离猫很近,因为都是宠物。
-
**“冰箱”**的坐标是 (90, 50) —— 离猫很远,因为毫无关系。
✨ 神奇的数学魔法
在这个地图里,语义变成了距离。模型甚至能做数学题:
“国王”的坐标 - “男人”的坐标 + “女人”的坐标 = ❓ 结果惊人地落在了 “女王” 的坐标附近!
小结: 通过把文字变成坐标,AI 不需要理解“含义”,它只需要计算“距离”。它知道“苹果”和“好吃”经常凑在一起,所以它们在地图上是邻居。
第三章:核心——Transformer 与“注意力机制”(这也是最难懂的部分)
以前的 AI(比如 Siri 早期版本)经常聊着聊着就忘了前文。为什么现在的 LLM 记性这么好? 因为一种叫 Attention Mechanism(注意力机制) 的技术。
👀 什么是“注意力”?
请读这句话:
“这只动物没有过马路,因为它太累了。”
作为人类,你读到**“它”**字时,你的大脑会瞬间反应过来:“它”指的是“动物”,而不是“马路”。为什么?因为“马路”不会“累”。 这就是注意力——理解一个词时,要同时关注上下文里的其他词。
🔍 那个著名的 Q、K、V 是什么?
在技术文章里,你常看到 Query (Q), Key (K), Value (V)。别被吓跑,我们用**“图书馆找书”**来比喻:
想象你走进一个巨大的图书馆(模型):
-
Query (查询/需求): 你手里拿着一张借书条,上面写着“我要找关于**‘疲惫’**的主体”。(这就好比句子里的“它”在寻找指代对象)。
-
Key (标签/索引): 图书馆里的每本书脊上都有标签。
-
“马路”这本书的标签写着:“我是水泥做的,硬的”。
-
“动物”这本书的标签写着:“我是生物,会跑,会累”。
-
-
Attention Score (匹配度): 你的借书条(Query)和“动物”的标签(Key)高度匹配!
-
Value (内容): 于是,你把“动物”这本书的内容(Value)提取出来,赋给了“它”。
小结: Transformer 架构让 AI 拥有了这种“如人类般阅读”的能力。它不再是一个字一个字死读,而是能全局扫视,瞬间搞清楚谁和谁有关系。

第四章:进化——从“野孩子”到“好助理”
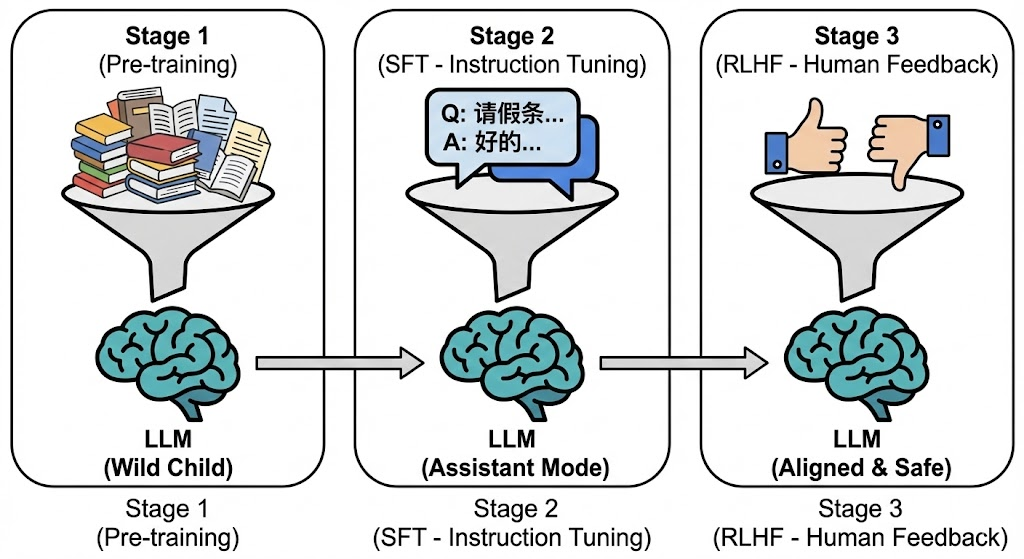
拥有了上述技术,模型其实还只是一个“读过万卷书”但“不懂人话”的野孩子。 要把它变成我们现在用的助手,还需要三步走:
-
预训练 (Pre-training) —— 填鸭式教育
-
做什么: 把海量数据喂给它,让它做填空题。
-
结果: 它学会了语法、知识,知道地球是圆的,但它不懂礼貌。你问“怎么做坏事”,它可能真的会教你。
-
-
指令微调 (SFT) —— 职业技能培训
-
做什么: 人类写好高质量的问答(比如:“请帮我写个请假条” -> “好的,老板...”),喂给模型看。
-
结果: 它学会了“对话模式”。它知道你是来提问的,它是来回答的。
-
-
人类反馈 (RLHF) —— 价值观对齐
-
做什么: 模型生成两个回答,人类来打分:“这个回答太粗鲁(0分),那个回答很得体(10分)”。
-
结果: 模型为了拿高分,学会了谦卑、安全、符合人类道德。
-
结语:祛魅之后,依然震撼
看完了这四层洋葱,你可能会发现:LLM 并没有科幻电影里的“灵魂”。
-
它没有意识,只有概率。
-
它不懂逻辑,只有向量距离。
-
它不理解你,它只是注意到了你话语中的关键词。
但正是这种纯粹的数学构建,涌现出了惊人的智慧。它像一面镜子,虽然镜子本身没有生命,但它折射出了全人类文明的光辉。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)