【论文速读】InfiAgent: 文件为状态实现Agent无限运行
论文标题: InfiAgent: An Infinite-Horizon Framework for General-Purpose Autonomous Agents
作者: Chenglin Yu 1 ^{1} 1, Yuchen Wang 2 ^{2} 2, Songmiao Wang 2 ^{2} 2, Hongxia Yang 2 ^{2} 2, Ming Li 2 ∗ ^{2*} 2∗ ( 1 ^{1} 1The University of Hong Kong, 2 ^{2} 2The Hong Kong Polytechnic University)
代码: https://github.com/ChenglinPoly/infiAgent
5. 总结
当前 LLM Agent 的核心瓶颈在于上下文长度与任务复杂度的矛盾。InfiAgent 通过将状态管理从 Prompt 中剥离,提出了一种以文件为中心 (File-Centric) 的状态抽象机制,从根本上解决了长时序任务中的上下文无限增长问题。
- 核心结论: 在 DeepResearch 基准测试中,InfiAgent 使得一个仅 20B 参数的开源模型,能够在无需特定微调的情况下,达到甚至超越 GPT-4o、Claude-4.5 等超大规模闭源模型的长时序任务表现。
- 前瞻意义: 该工作证明了显式的外部状态管理比单纯增加模型的上下文窗口(Context Window)更为有效。它为构建能够连续运行数周甚至数月的真正的 “Infinite-Horizon” 智能体提供了系统级的架构范式。
1. 思想
大型语言模型 (LLM) 在短时序任务中表现出色,但在处理需要数千步操作的科研或软件工程任务时,往往会因为上下文溢出或注意力分散而由于“幻觉”导致失败。
- 大问题: 上下文中心 (Context-Centric) 范式的局限性。
- 现有的 Agent 框架通常隐式地将 Prompt 作为状态的唯一载体。
- 随着时间推移 t → ∞ t \to \infty t→∞,历史交互、工具调用和中间结果导致上下文长度 ∣ c t ∣ |c_t| ∣ct∣ 无限增长。
- 虽然 RAG 或上下文压缩可以缓解,但它们引入了信息有损压缩,且使得模型难以区分长期记忆与短期推理信号,导致推理稳定性下降。
- 小问题:
- 如何让 Agent 在处理海量信息(如阅读 80 篇论文)时,不污染其核心推理上下文?
- 如何在数千步操作后,依然保持对项目当前状态(如代码库结构、已完成的实验结果)的精确感知?
- 核心思想: 解耦持久化状态与推理上下文 (Decoupling Persistent State from Reasoning Context)。
- 以文件系统为权威状态: 借鉴计算机操作系统的设计,将文件系统 (File System) 视为 Agent 的持久化内存 ( F t \mathcal{F}_t Ft)。所有中间结果、计划、代码都必须写入文件。
- 有界上下文重构: 在每一步决策时,Agent 不再依赖完整的历史对话,而是根据当前文件工作区快照加上极短的近期动作窗口来动态重构 Prompt。这保证了推理时的上下文长度是常数级的 O ( 1 ) \mathcal{O}(1) O(1),与任务总时长无关。
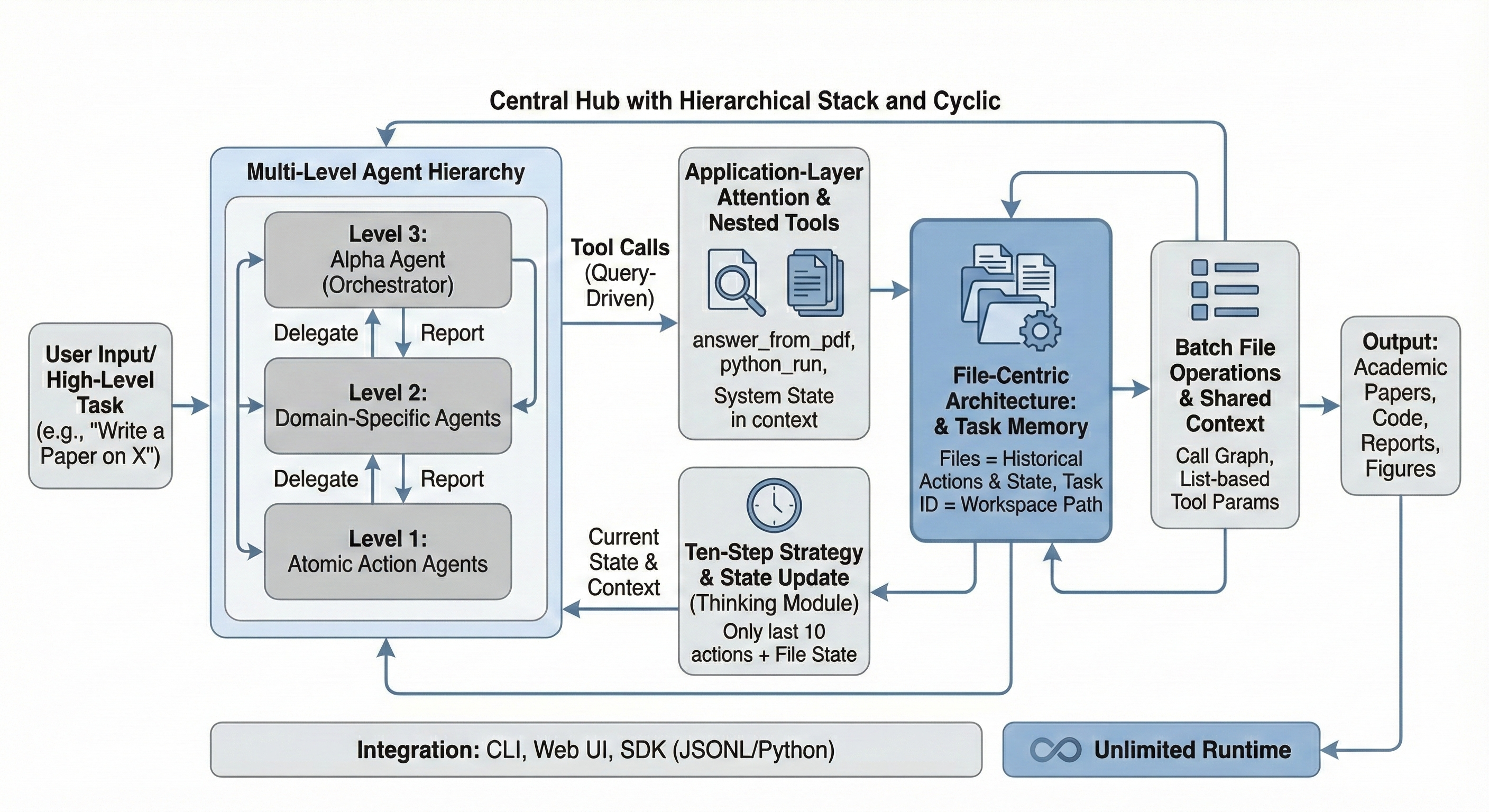
Figure 1: InfiAgent 框架概览。核心在于基于文件系统的持久化状态管理,配合分层 Agent 结构和外部注意力机制,实现无限时序的运行。
2. 方法
InfiAgent 的方法论建立在对 Agent 状态的形式化重定义之上,辅以工程上的分层架构设计。
2.1 状态形式化 (Formalization)
传统的 Agent 将状态定义为累积的上下文序列:
c t = ⟨ o 1 , a 1 , … , o t − 1 , a t − 1 , o t ⟩ c_t = \langle o_1, a_1, \dots, o_{t-1}, a_{t-1}, o_t \rangle ct=⟨o1,a1,…,ot−1,at−1,ot⟩
这种定义导致 ∣ c t ∣ |c_t| ∣ct∣ 随 t t t 线性增长。
InfiAgent 重新定义了状态转移过程:
-
持久化状态外部化: 定义 S t = F t S_t = \mathcal{F}_t St=Ft,其中 F t \mathcal{F}_t Ft 是 t t t 时刻 Agent 工作区内的所有文件集合。状态演变通过文件操作算子 T \mathcal{T} T 完成:
F t + 1 = T ( F t , a t ) \mathcal{F}_{t+1} = \mathcal{T}(\mathcal{F}_t, a_t) Ft+1=T(Ft,at)
这里 F t \mathcal{F}_t Ft 的大小不受 LLM 上下文窗口限制。 -
有界推理上下文重构: 在 t t t 时刻,构建给 LLM 的输入 c t bounded c_t^{\text{bounded}} ctbounded 仅由当前文件状态和最近 k k k 步动作决定:
c t bounded = g ( F t , a t − k : t − 1 ) c_t^{\text{bounded}} = g(\mathcal{F}_t, a_{t-k:t-1}) ctbounded=g(Ft,at−k:t−1)
其中 k k k 是一个小常数(例如 10)。函数 g ( ⋅ ) g(\cdot) g(⋅) 负责将文件状态摘要(如目录树、关键文件内容)映射到 Prompt 中。
关键点: 通过这种设计,无论任务执行了多少步,输入给 LLM 的 Token 数量始终保持在低水平,消除了“迷失在中间 (Lost-in-the-Middle)”现象。
2.2 架构实现
基于上述理论,InfiAgent 实现了三个关键工程组件:
-
分层 Agent 架构 (DAG Hierarchy):
- Level 3 (Alpha Agent): 负责高层规划和任务分解。它不直接操作底层工具,而是指挥下层 Agent。
- Level 2 (Domain Agents): 领域专家,如 Coder、Writer。
- Level 1 (Atomic Agents): 执行原子操作,如
grep、curl。
这种结构将复杂的长任务分解为模块化的短任务,配合文件系统作为层级间的通信接口,避免了单 Agent 的认知过载。
-
外部注意力管道 (External Attention Pipeline):
- 针对超长文档阅读(如文献综述),InfiAgent 拒绝将全文加载到主上下文中。
- 它启动一个独立的、临时的 LLM 进程作为“外部注意力头”,专门负责从文档中提取特定问题的答案,仅将答案返回给主 Agent:
C m a i n ← C m a i n ∪ Tool ( Q u e r y , D o c u m e n t ) C_{main} \leftarrow C_{main} \cup \text{Tool}(Query, Document) Cmain←Cmain∪Tool(Query,Document) - 这相当于在应用层实现了 Attention 机制,极大地降低了主推理流的 Token 消耗。
-
周期性状态固化 (Periodic State Consolidation):
为了防止短期记忆缓冲区 ( a t − k : t − 1 a_{t-k:t-1} at−k:t−1) 溢出,系统会定期强制 Agent 将当前的思维链、计划更新写入文件( F t \mathcal{F}_t Ft),然后清空短期缓冲区。这类似于操作系统的sync指令,确保了内存数据的持久化。
3. 优势
相较于现有的长上下文(Long-Context)和 RAG 增强型 Agent,InfiAgent 的优势在于:
- 无限时序稳定性: 上下文长度与任务时长解耦,理论上支持无限步数运行,且推理延迟不随时间增加。
- 模型无关性 (Model Agnostic): 不依赖于特制的长窗口模型(如 Gemini-1.5-Pro),即使是上下文窗口较小的开源模型(如 Llama-3-70B 或 Qwen)也能胜任长任务。
- 可解释性与容错: 所有的中间状态都以人类可读的文件形式(代码、Markdown、日志)存在。如果 Agent 失败,人类可以直接检查工作区文件进行调试或恢复,而不是去挖掘晦涩的 Vector Database 或 KV Cache。
4. 实验
实验旨在验证“文件中心状态”是否能提升长时序任务的鲁棒性,特别是在模型参数规模较小的情况下。
实验设置
- 基准:
- DeepResearch Benchmark: 评估多步信息收集、综合和报告生成能力。
- Long-Horizon Literature Review: 自定义的高压任务,要求 Agent 阅读 80 篇学术论文并生成综述及评分,主要考察覆盖率 (Coverage)。
- 模型: 主力模型为 gpt-oss-20b (基于 DeepSeek-V3/Llama 等开源权重的 20B 参数级别模型),对比闭源模型 GPT-4o, Claude-4.5-Sonnet, Gemini-1.5-Pro。
核心结果
- 小模型越级挑战:
在 DeepResearch 榜单上,InfiAgent (20B) 取得了 41.45 的总分。- 这一分数超过了 perplexity-Research (GPT-5 backboned?), Nvidia-AIQ (70B) 等系统。
- 虽然略低于 OpenAI DeepResearch (GPT-4o),但考虑到 20B vs >1T 的参数差距,证明了架构优势可以弥补模型能力的不足。
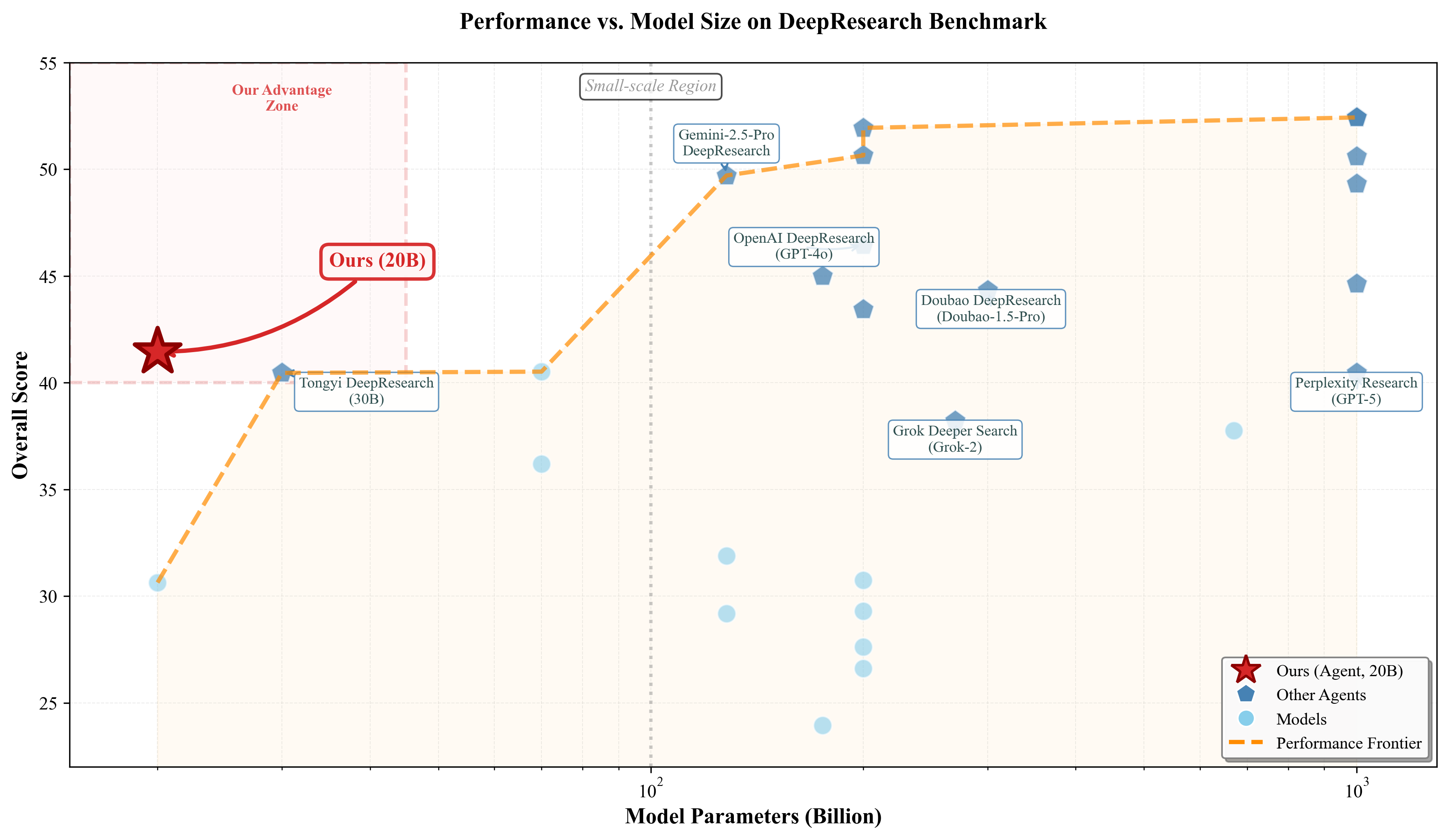
Figure 3: DeepResearch 性能 vs 模型规模。InfiAgent (红色星号) 位于效率前沿的左上角,以极小的参数量实现了与大规模闭源模型相当的性能。
-
长时序可靠性 (Coverage):
在 80 篇论文的综述任务中,考察 Agent 是否能坚持读完所有论文而不中断或遗漏。- InfiAgent (20B): 平均覆盖率 67.1%,最高 80/80。
- Claude Code (Claude-4.5): 平均覆盖率仅 29.1%。
- Cursor (Claude-4.5): 平均覆盖率 1.0% (几乎完全失败)。
- 结论: 现有的基于上下文的商业 Agent 在超长任务中极易崩溃(Context Window 溢出或错误累积),而 InfiAgent 即使使用较弱的模型,也能通过文件状态回溯保证任务的完成度。
-
消融实验:
移除“文件中心状态”并单纯依赖长上下文压缩技术后,20B 模型的覆盖率从 67.1% 暴跌至 3.2%。这强有力地证明了长窗口不能替代结构化的外部状态管理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)