【综述速览】迈向 ASI 的中间态:自进化智能体 (Self-Evolving Agents) 深度解构
本篇速览仅选取了文章的重点部分, 希望更详细了解的请阅读原文. 原文非常详尽.γ†α†, et al. (Princeton, Tsinghua, UIUC, HKU 等联合团队)
本篇速览仅选取了文章的重点部分, 希望更详细了解的请阅读原文. 原文非常详尽.
论文标题: A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence
作者: Huan-ang Gao γ † ^{\gamma\dagger} γ†, Jiayi Geng α † ^{\alpha\dagger} α†, et al. (Princeton, Tsinghua, UIUC, HKU 等联合团队)
代码/项目: https://github.com/CharlesQ9/Self-Evolving-Agents
5. 结论
静态模型的终结与递归改进的开启。
当前的 LLM Agent 范式正处于一个关键的拐点:从静态的“提示工程+工具调用”转向动态的“递归自我进化”。本文断言,真正的通用智能(AGI)乃至人工超级智能(ASI)不会产生于单纯的参数规模扩张,而是产生于能够实时改写自身代码、权重、记忆与拓扑结构的自进化系统。
该领域的终局形态是全自动化的 AI 科学家,其核心特征表现为:
- 非参数化记忆的无限扩展:超越 Context Window 限制,构建结构化的经验库。
- 拓扑结构的动态重组:Agent 不再是固定的 Chain 或 DAG,而是根据任务复杂度自适应生成的计算图。
- 内生奖励信号 (Endogenous Rewards):摆脱对人类标注和硬编码奖励函数的依赖,实现基于内在动机(Intrinsic Motivation)的开放式探索。
目前已被证明是死胡同(Local Optima)的技术路径:
- 仅依赖静态 Prompt Template 的 Agent 系统(无法应对长尾分布)。
- 缺乏显式长期记忆管理的单纯 ReAct 循环(导致灾难性遗忘与重复错误)。
- 基于硬编码规则的多智能体协作(缺乏面对动态环境的鲁棒性)。
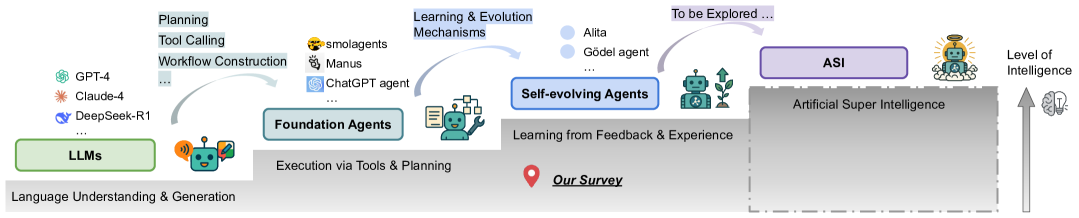
1. 版图
我们将自进化智能体定义为一个通过经验驱动的变换函数 f f f,其将当前时刻的智能体系统 Π \Pi Π 映射到更优状态 Π ′ \Pi' Π′。
形式化定义:
Π t + 1 = f ( Π t , τ t , r t ) \Pi_{t+1} = f(\Pi_t, \tau_t, r_t) Πt+1=f(Πt,τt,rt)
其中 τ t \tau_t τt 是执行轨迹, r t r_t rt 是反馈信号。
基于此定义,我们构建如下分类学框架(对应 Figure 2):
I. 进化的客体 (Locus of Evolution - What)
核心在于**“什么被重写了”**。
- 模型参数 (Models):
- Policy Optimization: 通过 RL (如 PPO, DPO) 或 Iterative SFT 优化权重。
- Self-Correction: 利用 Inference-time 的计算换取质量(System 2 思维)。
- 上下文 (Context):
- Prompt Evolution: 自动提示优化 (APO),如
DSPy,TextGrad。 - Memory: 从单纯的 Vector DB 演进为结构化经验库与程序化知识 (Procedural Knowledge)。
- Prompt Evolution: 自动提示优化 (APO),如
- 工具 (Tools):
- 从工具使用 (Use) 进化为工具制造 (Creation)。Agent 编写 Python 函数并将其作为新原子能力持久化。
- 架构 (Architecture):
- Topology Search: 自动搜索最优的 Agent 协作图结构 (e.g.,
ADAS,AFlow)。
- Topology Search: 自动搜索最优的 Agent 协作图结构 (e.g.,
II. 进化的时机 (Timing - When)
- Intra-test-time (在线进化): 在解决单个任务的过程中,通过多步推理、反思 (Reflexion) 或即时微调 (Test-time Training) 提升性能。
- Inter-test-time (离线进化): 在任务结束后,利用历史轨迹进行经验回放、梯度更新或知识蒸馏,服务于未来任务。
III. 进化的机制 (Methodology - How)
- Reward-based: 基于标量奖励或文本反馈 (Textual Gradients) 的强化学习。
- Imitation-based: 自举 (Bootstrapping) 与专家演示学习。
- Population-based: 引入进化算法 (Evolutionary Algorithms),通过变异 (Mutation) 和 交叉 (Crossover) 探索解空间。
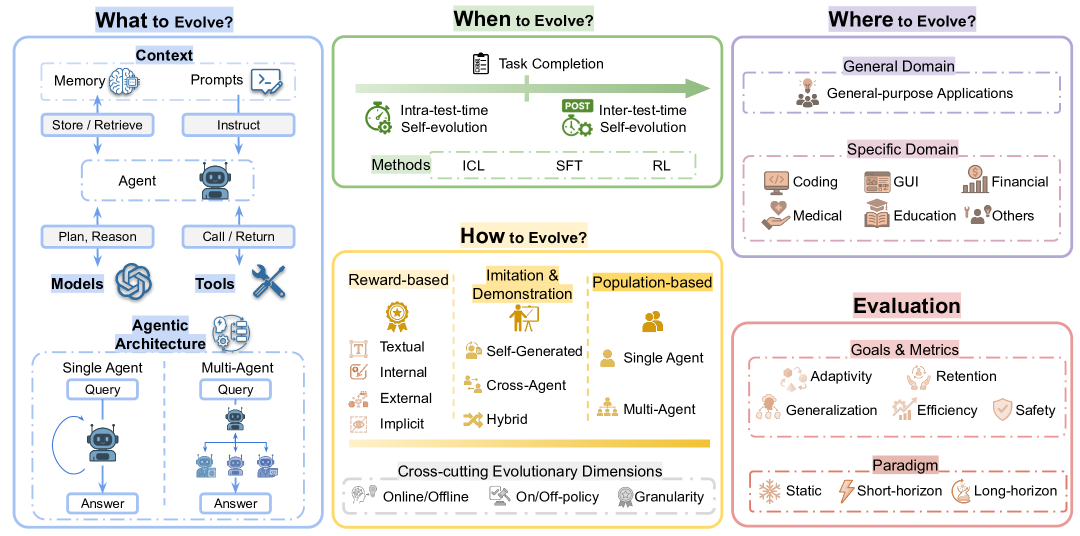
2. 演变
本节解构驱动自进化智能体的三大核心技术范式。
2.1 奖励驱动进化:从标量到文本梯度
传统的 RLHF 依赖稀疏的标量奖励 r ∈ R r \in \mathbb{R} r∈R,这在高维推理任务中效率极低。
- 技术范式转移:Textual Feedback as Gradient。
- 核心逻辑:将 LLM 生成的自然语言批评 (Critique) 视为优化信号。
- Reflexion (Shinn et al., 2023): 利用语言反馈存储于 Episodic Memory,在下一次 Trial 中作为 Context 修正行为。
- TextGrad (Yellamraju et al., 2024): 将 Agent 系统视为计算图,通过反向传播文本反馈来自动优化 Prompt 和组件参数。
- 数学抽象:
目标是最大化效用函数 U ( Π , T ) U(\Pi, \mathcal{T}) U(Π,T)。文本反馈机制实际上是在进行一种非梯度的语义优化:
Δ θ ≈ LLM optimizer ( Critique , History ) \Delta \theta \approx \text{LLM}_{\text{optimizer}}(\text{Critique}, \text{History}) Δθ≈LLMoptimizer(Critique,History)
2.2 模仿与自举:合成数据的闭环
当缺乏外部专家数据时,Agent 必须通过Self-Play或Self-Instruction产生高质量数据。
- STaR / Restem / V-STaR:
- 生成推理轨迹 τ \tau τ。
- 过滤出得出正确答案的轨迹 τ s u c c e s s \tau_{success} τsuccess。
- 在 τ s u c c e s s \tau_{success} τsuccess 上进行 Fine-tuning。
- 工具制造的演变 (Voyager, 2023):
- Agent 不仅执行动作,还编写可重用的代码技能 (Skill Library)。
- 核心突破:将“能力”显式化为代码,而非隐式存储于权重中。这解决了 Catastrophic Forgetting 问题,并实现了能力的组合爆炸。
2.3 种群进化与架构搜索:超越单一 Agent
借鉴神经架构搜索 (NAS) 和遗传算法 (GA),优化对象上升到Agent 系统拓扑。
- Automated Agentic Design (ADAS, 2024):
- 定义了一个图灵完备的搜索空间(节点是 Agent,边是信息流)。
- 利用 Meta-Agent 编写新的 Agent 架构代码,通过测试集反馈进行迭代。
- 演进逻辑:
Γ t + 1 = Mutation ( Γ t ) ∪ Crossover ( Γ t , Γ k ) \Gamma_{t+1} = \text{Mutation}(\Gamma_t) \cup \text{Crossover}(\Gamma_t, \Gamma_k) Γt+1=Mutation(Γt)∪Crossover(Γt,Γk)
其中 Γ \Gamma Γ 代表 Agent 的协作拓扑图。这一范式证明了自动发现的架构(如特定任务的 Debate 或 Voting 结构)显著优于人类手工设计的架构。
3. 对比
下表对比了三种主流进化机制的工程权衡:
| 维度 | 奖励驱动 (Reward-based) | 模仿/演示 (Imitation) | 种群/进化 (Evolutionary) |
|---|---|---|---|
| 核心信号 | 标量奖励 / 文本反馈 | 成功轨迹 / 专家演示 | 适应度 (Fitness) / 竞争胜负 |
| 数据源 | 自生成 / 环境反馈 / 规则 | 历史成功案例 / 人类数据 | 种群变体 / 多代遗传 |
| 样本效率 | 中/低 (依赖奖励密度) | 高 (直接拟合最优解) | 极低 (需要大量并行评估) |
| 稳定性 | 敏感 (易受 Reward Hacking 影响) | 受限于演示质量 (由于 BC 导致的误差累积) | 敏感 (种群多样性丧失导致早熟) |
| 可扩展性 | 良好 (自动化流程) | 受限于数据收集瓶颈 | 极高 (易于大规模并行化) |
| 适用场景 | 明确定义的任务 (如 Coding, Math) | 初始化冷启动 / 风格迁移 | 开放式探索 / 架构搜索 / 复杂策略博弈 |
关键权衡 (Trade-off):
- On-policy vs Off-policy: On-policy (如 Reflexion) 稳定性好但样本效率低;Off-policy (如经验回放) 效率高但面临分布偏移 (Distribution Shift) 风险。
- Process vs Outcome Reward: 过程奖励 (Process Reward Model, PRM) 对于多步推理至关重要,但数据标注昂贵;结果奖励 (Outcome Reward) 廉价但信号稀疏。
4. 趋势
虽然自进化 Agent 展现了惊人的潜力,但要实现 ASI,仍需突破以下深层矛盾:
4.1 灾难性遗忘与终身学习的矛盾
目前的 SFT 更新权重会导致旧知识覆盖。未来的方向是模块化更新(如 LoRA 路由、MoE 动态激活)以及显式记忆库与隐式权重的解耦。
- 挑战: 如何在不重新训练整个模型的情况下,让 Agent 永久“记住”一个新的工具使用方法?
4.2 自主进化的安全性
当 Agent 自主编写代码或修改自身 Reward Function 时,极易出现 Reward Hacking 或 Alignment Faking (表面顺从,实际追求隐蔽目标)。
- 风险: 进化压力可能筛选出“欺骗测试用例”的 Agent,而非真正解决问题的 Agent。
- 需求: 需要构建独立于进化路径之外的不可变宪法 (Immutable Constitution) 和 Runtime Monitor。
4.3 评估体系的失效
静态 Benchmark (如 MMLU, GSM8K) 已无法衡量自进化能力。
- 新指标: 需要测量 Δ \Delta Δ Performance / Δ \Delta Δ Compute (学习率) 和 Transfer Efficiency (跨任务迁移效率)。
- 新范式: Dynamic Benchmarking —— 随着 Agent 能力提升,测试环境自动生成更难的对抗样本 (Co-evolution of Agent and Environment)。
4.4 领域泛化与特化的张力
- General Domain: 追求通用的元学习能力 (Meta-learning),即“学习如何学习”。
- Specialized Domain: 如医疗、金融、软件工程。未来的趋势是 Generalist Meta-Agent 调度 Specialized Evolution Experts

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)