QKV机制详解,大模型的注意力
摘要:QKV机制是Transformer模型中注意力机制的核心,通过Query、Key、Value三个向量实现信息检索与融合。Query表示查询需求,Key作为标识用于匹配,Value提供实际信息内容。计算过程包括:线性变换生成QKV向量,计算注意力分数,Softmax归一化权重,加权求和得到上下文感知的输出。该机制使模型能动态关注相关信息,有效处理长距离依赖、代词消解和一词多义等问题,相比传统R
我们先从理论角度来解释QKV机制,QKV机制是注意力机制的核心,尤其在Transformer模型中,注意力机制源于人类感知世界的方式:在处理信息时,我们会选择性地关注一部分信息,而忽略其他信息。在机器学习中,注意力机制允许模型在处理序列数据时,对不同的部分赋予不同的权重,从而更有效地利用信息。
1. QKV的定义
在注意力机制中,每个输入元素会生成三个向量:Query(查询)、Key(键)和Value(值)。这些向量是通过对输入进行线性变换得到的。
Query(Q):表示当前元素想要查询其他元素的信息。它类似于一个提问,用来匹配其他元素的Key。
Key(K):表示当前元素的标识,用于被其他元素的Query匹配。Query和Key的匹配程度决定了注意力权重。
Value(V):表示当前元素实际提供的信息。注意力权重会作用在Value上,从而得到加权的输出。
2. 直观理解
结合图书馆来理解,好比我们去图示馆借阅书籍:
Value:图书馆里所有的书籍本身,包含丰富的知识和信息
Key:每本书的索引卡,简要描述了书的内容特征
Query:我们的借阅请求,比如"我想找一本关于人工智能入门的书"
借书过程就是QKV机制:
1. 管理员将我们的Query与所有Key进行匹配
2. 找到最相关的几本书(计算匹配度)
3. 根据匹配程度决定每本书的"重要性权重"
4. 把这些书的Value按照权重组合起来给你
二、计算过程
给定输入序列X ∈ R^(n×d) ,其中n是序列长度,d是特征维度。我们通过线性变换得到Q、K、V,然后计算注意力权重,公式偏数学理论,先了解大概,记住公式内容,在示例中对比逐步领悟。
1. 输入表示:X ∈ R^(n×d)
n:序列长度(如一句话有10个词,n=10)
d:每个token的嵌入维度(如BERT-base中d=768)
X = [[x₁₁, x₁₂, ..., x₁d], # 第1个token的d维向量
[x₂₁, x₂₂, ..., x₂d], # 第2个token的d维向量
...
[xₙ₁, xₙ₂, ..., xₙd]] # 第n个token的d维向量
# 假设句子:"I love AI" 有3个token,每个token用4维向量表示
X = [[0.1, 0.2, 0.3, 0.4], # "I"的向量表示
[0.5, 0.6, 0.7, 0.8], # "love"的向量表示
[0.9, 0.1, 0.2, 0.3]] # "AI"的向量表示
# 这里 n=3, d=4
2. 线性变换:生成Q, K, V
每个权重矩阵的作用:
W_Q - Query权重矩阵:
学习如何提问
将原始输入映射到查询空间
决定每个token应该关注什么类型的信息
W_K - Key权重矩阵:
学习如何被识别
将原始输入映射到键空间
决定每个token如何被其他token识别和匹配
W_V - Value权重矩阵:
学习"提供什么信息"
将原始输入映射到值空间
决定每个token在被关注时应该贡献什么信息
实际计算示例:
# 假设 d=4, d_k=3, d_v=3
W_Q = [[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[0.2, 0.3, 0.4]] # 4×3
# 计算第一个token的Query向量
token1 = [0.1, 0.2, 0.3, 0.4]
Q1 = [0.1×0.1 + 0.2×0.4 + 0.3×0.7 + 0.4×0.2,
0.1×0.2 + 0.2×0.5 + 0.3×0.8 + 0.4×0.3,
0.1×0.3 + 0.2×0.6 + 0.3×0.9 + 0.4×0.4]
= [0.01 + 0.08 + 0.21 + 0.08,
0.02 + 0.10 + 0.24 + 0.12,
0.03 + 0.12 + 0.27 + 0.16]
= [0.38, 0.48, 0.58]
3. 注意力分数:
数学含义:
点积相似度:
测量Query向量和Key向量之间的相似性
值越大表示两个token之间的关联性越强
缩放因子 1/√d_k:
防止点积值过大导致softmax梯度消失
当d_k很大时,点积的方差也会变大,缩放保持数值稳定性
实际意义:
S矩阵是关联强度矩阵:
S[i,j]:第i个token对第j个token的关注程度
对角线元素 S[i,i]:token对自己的关注度
非对角线元素 S[i,j]:token之间的相互关注度
# 示例:3个token的关联矩阵
S = [[0.9, 0.3, 0.1], # token1: 很关注自己,不太关注其他
[0.2, 0.8, 0.6], # token2: 关注自己和token3
[0.1, 0.5, 0.7]] # token3: 比较关注token2
4. 注意力权重:
数学含义:
Softmax操作:
将注意力分数转换为概率分布
确保每行的权重和为1
放大较大值,抑制较小值
概率解释:
A[i,j] = P(关注token_j | 当前是token_i)
即:给定当前处理的是第i个token,它应该以多大概率关注第j个token
实际效果:
# Softmax前
S = [[1.0, 0.5, 0.1],
[0.2, 2.0, 0.3],
[0.1, 0.4, 0.8]]
# Softmax后(每行和为1)
A = [[0.57, 0.29, 0.14], # 主要关注自己
[0.12, 0.73, 0.15], # 强烈关注自己
[0.18, 0.27, 0.55]] # 主要关注自己,也关注其他
5. 输出计算:Z = A × V
实际意义:
上下文感知的表示:
原始输入X:每个token的独立表示
输出Z:每个token包含全局上下文信息的表示
# 示例:代词消解
句子:"The cat ate the fish because it was hungry"
# 计算"it"的输出时:
Z_it = 0.02 × V_The + 0.01 × V_cat + 0.01 × V_ate +
0.02 × V_the + 0.01 × V_fish + 0.90 × V_cat + # 主要关注"cat"
0.03 × V_was + 0.00 × V_hungry
6. 计算过程示例
6.1 输入准备
假设我们有3个词的句子:"猫 吃 鱼",每个词用4维向量表示:
猫: [0.8, 0.2, 0.4, 0.1]
吃: [0.1, 0.9, 0.3, 0.7]
鱼: [0.3, 0.1, 0.9, 0.2]
计算得出输入矩阵 X = [[0.8, 0.2, 0.4, 0.1], [0.1, 0.9, 0.3, 0.7], [0.3, 0.1, 0.9, 0.2]]
6.2 生成Q、K、V
模型有三个可学习的权重矩阵(开始时是随机值,通过训练学习):
W_Q = [[0.5, 0.2], [0.1, 0.3], [0.4, 0.6], [0.2, 0.1]] ,形状: [4, 2]
W_K = [[0.1, 0.5], [0.3, 0.2], [0.6, 0.4], [0.2, 0.3]] ,形状: [4, 2]
W_V = [[0.2, 0.4], [0.5, 0.1], [0.3, 0.6], [0.1, 0.2]] ,形状: [4, 2]
计算过程:
Q = X × W_Q
K = X × W_K
V = X × W_V
让我们手动计算"猫"这个词的Q向量:
猫的Q = [0.8, 0.2, 0.4, 0.1] × [[0.5, 0.2], [0.1, 0.3], [0.4, 0.6], [0.2, 0.1]]
= [0.8×0.5 + 0.2×0.1 + 0.4×0.4 + 0.1×0.2, 0.8×0.2 + 0.2×0.3 + 0.4×0.6 + 0.1×0.1]
= [0.4 + 0.02 + 0.16 + 0.02, 0.16 + 0.06 + 0.24 + 0.01]
= [0.6, 0.47]
计算最终得到:
Q = [[0.60, 0.47], # 猫的Query
[0.58, 0.90], # 吃的Query
[0.72, 0.65]] # 鱼的Query
K = [[0.32, 0.56], # 猫的Key
[0.50, 0.71], # 吃的Key
[0.68, 0.42]] # 鱼的Key
V = [[0.35, 0.42], # 猫的Value
[0.62, 0.28], # 吃的Value
[0.54, 0.63]] # 鱼的Value
6.3 计算注意力分数
现在计算每个Query与所有Key的匹配度:
注意力分数 = Q × K^T
K^T = [[0.32, 0.50, 0.68], [0.56, 0.71, 0.42]]
计算过程:
分数[0,0] = [0.60,0.47]·[0.32,0.56] = 0.60×0.32 + 0.47×0.56 = 0.192 + 0.263 = 0.455
分数[0,1] = [0.60,0.47]·[0.50,0.71] = 0.60×0.50 + 0.47×0.71 = 0.300 + 0.334 = 0.634
分数[0,2] = [0.60,0.47]·[0.68,0.42] = 0.60×0.68 + 0.47×0.42 = 0.408 + 0.197 = 0.605
... 以此计算所有组合
得到注意力分数矩阵:
注意力分数 = [[0.455, 0.634, 0.605], # 猫对猫/吃/鱼的关注度
[0.572, 0.869, 0.753], # 吃对猫/吃/鱼的关注度
[0.533, 0.767, 0.763]] # 鱼对猫/吃/鱼的关注度
6.4 Softmax归一化
对每一行进行Softmax,使得每行之和为1:
第一行: [0.455, 0.634, 0.605]
exp: [e^0.455, e^0.634, e^0.605] ≈ [1.576, 1.886, 1.831]
和: 1.576 + 1.886 + 1.831 = 5.293
Softmax: [1.576/5.293, 1.886/5.293, 1.831/5.293] ≈ [0.298, 0.356, 0.346]
最终注意力权重:
注意力权重 = [[0.298, 0.356, 0.346], # 猫: 35.6%关注"吃", 34.6%关注"鱼"
[0.246, 0.422, 0.332], # 吃: 最关注自己(42.2%)
[0.276, 0.354, 0.370]] # 鱼: 37.0%关注自己, 35.4%关注"吃"
6.5 加权求和得到输出
最后用注意力权重对Value进行加权求和:
对于"猫"这个词的输出:
输出[0] = 0.298×[0.35,0.42] + 0.356×[0.62,0.28] + 0.346×[0.54,0.63]
= [0.104,0.125] + [0.221,0.100] + [0.187,0.218]
= [0.512, 0.443]
最终输出:
输出 = [[0.512, 0.443], # 猫的上下文感知表示
[0.527, 0.422], # 吃的上下文感知表示
[0.519, 0.468]] # 鱼的上下文感知表示
7. 完整流程总结
整个流程包括输入、线性变换(生成Q、K、V)、计算注意力分数、Softmax归一化、加权求和得到输出。
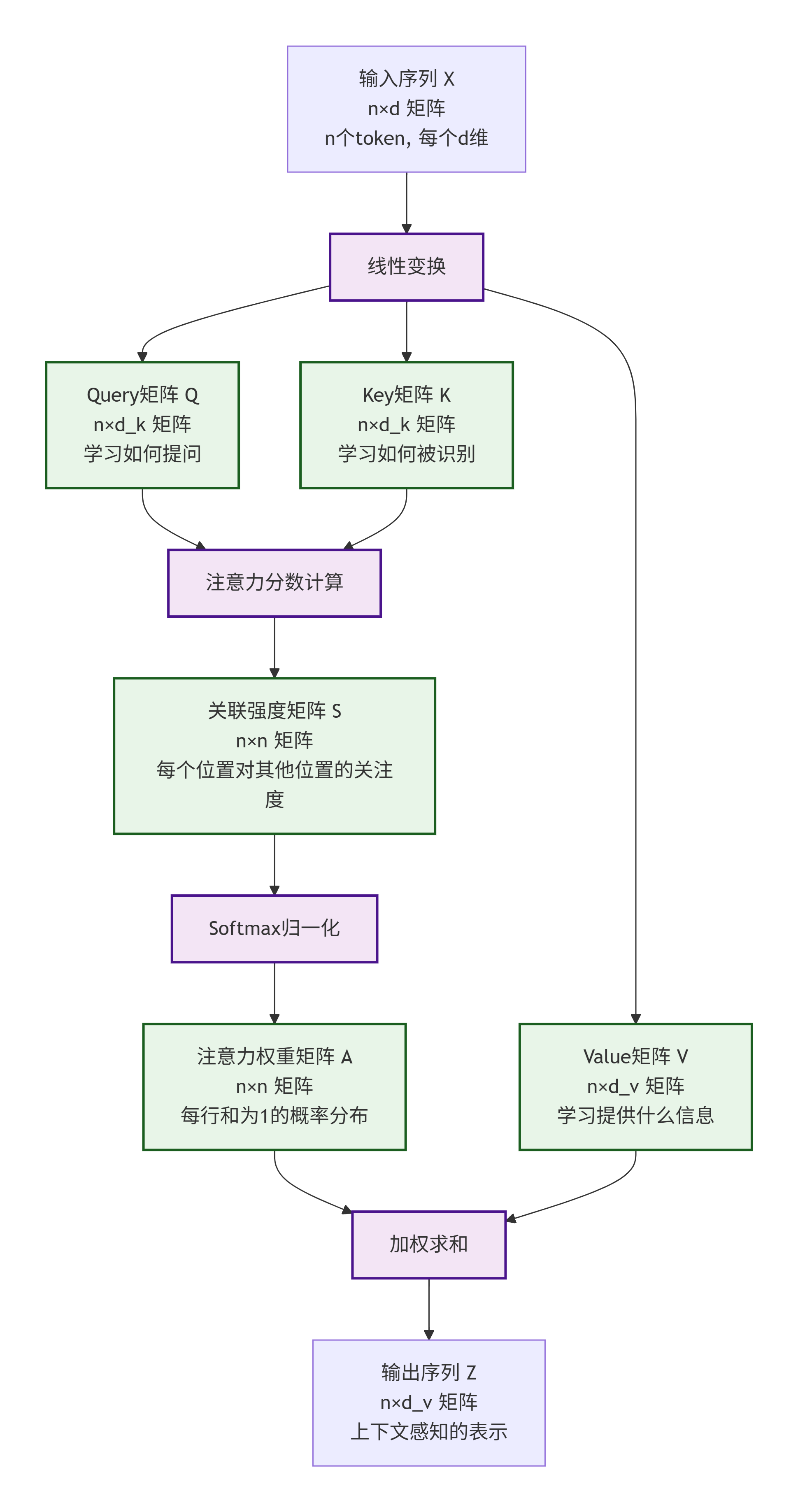
流程详细说明:
1. 输入阶段
X: 原始输入序列,形状为 n×d
n = 序列长度(如10个词)
d = 每个词的向量维度(如768维)
2. 线性变换阶段
通过三个不同的权重矩阵生成Q、K、V:
Q (Query): 学习"如何提问" - 形状 n×d_k
K (Key): 学习"如何被识别" - 形状 n×d_k
V (Value): 学习"提供什么信息" - 形状 n×d_v
3. 注意力计算阶段
S: 关联强度矩阵,形状 n×n
计算每个位置对其他所有位置的关注程度
S[i,j] 表示第i个位置对第j个位置的关注度
4. 归一化阶段
A: 注意力权重矩阵,形状 n×n
通过Softmax确保每行的权重和为1
将关注度转换为概率分布
5. 输出生成阶段
Z: 最终输出序列,形状 n×d_v
每个位置都是所有Value向量的加权和
权重由注意力矩阵A决定
每个token都包含了整个序列的上下文信息
三、体现的价值
1. 实际作用示例
示例1:代词消解
句子:"李华看见张明,他笑了"
计算过程:
- "他"的Query会与所有词的Key匹配
- 发现与"李华"、"张明"的匹配度都很高
- 但通过训练,模型学会"他"通常指向前面最近的人名"张明"
- 因此给"张明"的Value更高权重
示例2:多义词理解
句子1:"苹果很好吃"
句子2:"苹果股价上涨"
在句子1中:"苹果"的Query主要与"好吃"、"水果"等Key高匹配
在句子2中:"苹果"的Query主要与"股价"、"公司"等Key高匹配
2. 多头注意力机制
实际中大模型使用多头注意力,让模型同时从多个角度关注信息:
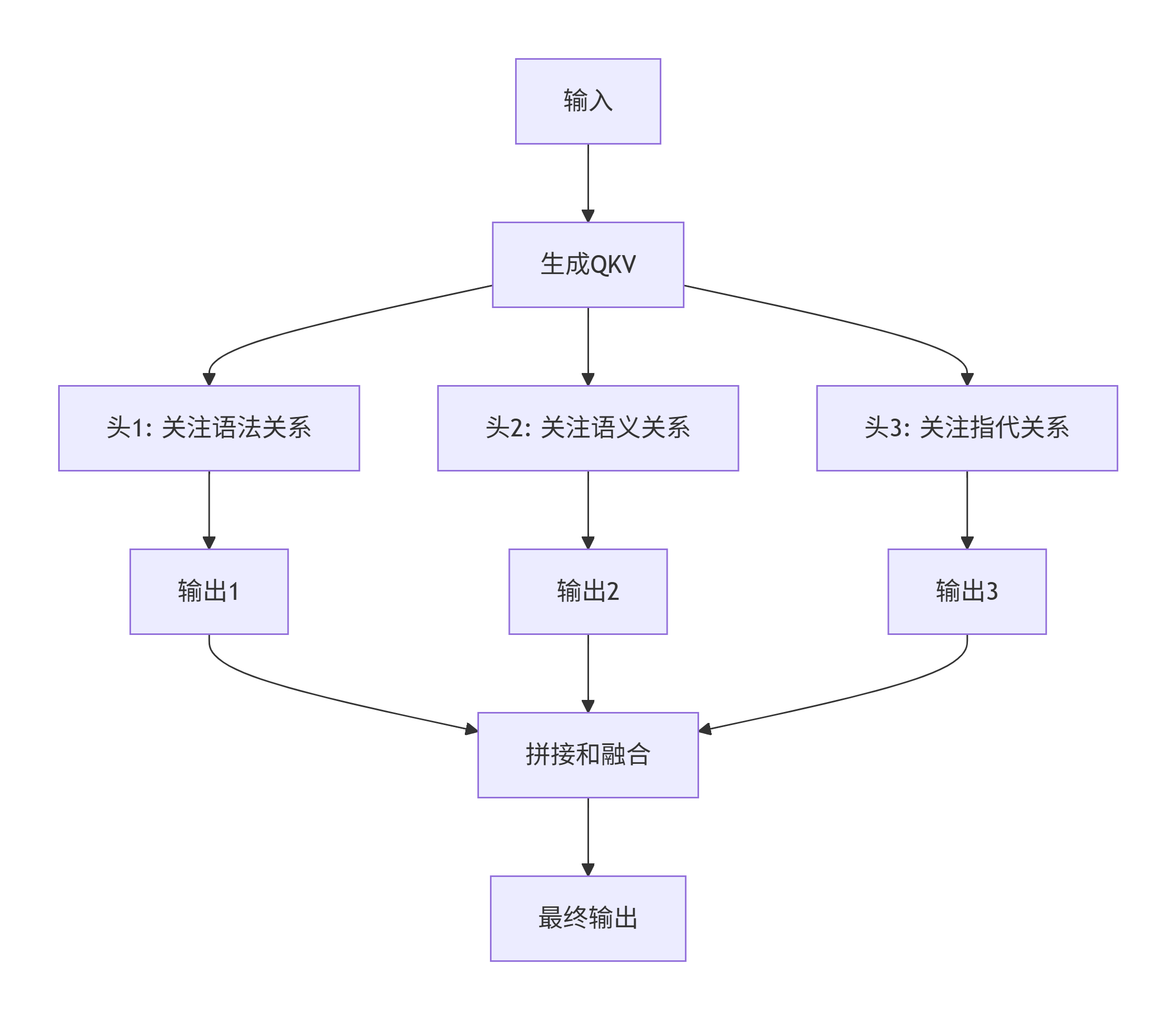
比如在分析"我去银行取钱"时:
头1关注:"取"→"钱"(动作-对象关系)
头2关注:"银行"→"取钱"(地点-活动关系)
头3关注:"我"→"取"(主体-动作关系)
四、代码实现推导
代码语言:python
AI代码解释
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class SimpleSelfAttention(nn.Module):
"""简单的自注意力机制实现"""
def __init__(self, d_model=4, d_k=2, d_v=2):
super(SimpleSelfAttention, self).__init__()
self.d_model = d_model # 输入维度
self.d_k = d_k # Query和Key的维度
self.d_v = d_v # Value的维度
# 定义Q、K、V的线性变换层
# 注意:nn.Linear的权重形状是 (out_features, in_features)
self.W_Q = nn.Linear(d_model, d_k, bias=False)
self.W_K = nn.Linear(d_model, d_k, bias=False)
self.W_V = nn.Linear(d_model, d_v, bias=False)
# 初始化权重,便于理解计算过程
self._initialize_weights()
def _initialize_weights(self):
"""手动初始化权重,便于跟踪计算过程"""
# 预设的权重值,注意形状要与nn.Linear匹配
# nn.Linear权重形状是 (out_features, in_features) = (d_k, d_model)
preset_W_Q = torch.tensor([[0.5, 0.1, 0.4, 0.2], # 第一行对应第一个输出维度
[0.2, 0.3, 0.6, 0.1]], dtype=torch.float32) # 第二行对应第二个输出维度
preset_W_K = torch.tensor([[0.1, 0.3, 0.6, 0.2],
[0.5, 0.2, 0.4, 0.3]], dtype=torch.float32)
preset_W_V = torch.tensor([[0.2, 0.5, 0.3, 0.1],
[0.4, 0.1, 0.6, 0.2]], dtype=torch.float32)
self.W_Q.weight.data = preset_W_Q
self.W_K.weight.data = preset_W_K
self.W_V.weight.data = preset_W_V
def forward(self, X, verbose=False):
"""
前向传播
Args:
X: 输入张量 [seq_len, d_model]
verbose: 是否打印详细计算过程
"""
if verbose:
print("=" * 60)
print("QKV自注意力机制详细计算过程")
print("=" * 60)
print(f"输入 X (shape: {X.shape}):")
print(X)
print()
# 步骤1: 生成Q, K, V
Q = self.W_Q(X) # [seq_len, d_k]
K = self.W_K(X) # [seq_len, d_k]
V = self.W_V(X) # [seq_len, d_v]
if verbose:
print("步骤1: 生成Q, K, V")
print(f"Q (shape: {Q.shape}):")
print(Q)
print(f"K (shape: {K.shape}):")
print(K)
print(f"V (shape: {V.shape}):")
print(V)
print()
# 步骤2: 计算注意力分数 Q × K^T
attention_scores = torch.matmul(Q, K.transpose(0, 1)) # [seq_len, seq_len]
if verbose:
print("步骤2: 计算注意力分数 Q × K^T")
print(f"注意力分数矩阵 (shape: {attention_scores.shape}):")
print(attention_scores)
print()
# 打印详细的计算过程
print("详细点积计算:")
for i in range(Q.shape[0]):
for j in range(K.shape[0]):
dot_product = torch.dot(Q[i], K[j])
print(f"Q[{i}] · K[{j}] = {Q[i].detach().numpy()} · {K[j].detach().numpy()} = {dot_product:.3f}")
print()
# 步骤3: 缩放
scaled_scores = attention_scores / np.sqrt(self.d_k)
if verbose:
print("步骤3: 缩放")
print(f"缩放因子: 1/sqrt(d_k) = 1/sqrt({self.d_k}) = {1/np.sqrt(self.d_k):.3f}")
print(f"缩放后的分数矩阵:")
print(scaled_scores)
print()
# 步骤4: Softmax归一化
attention_weights = F.softmax(scaled_scores, dim=-1) # [seq_len, seq_len]
if verbose:
print("步骤4: Softmax归一化")
print("对每一行进行Softmax:")
for i in range(scaled_scores.shape[0]):
row = scaled_scores[i]
exp_row = torch.exp(row)
sum_exp = torch.sum(exp_row)
softmax_row = exp_row / sum_exp
print(f"第{i}行: {row.detach().numpy()} -> exp: {exp_row.detach().numpy()} -> "
f"softmax: {softmax_row.detach().numpy()} (sum: {sum_exp:.3f})")
print()
print(f"注意力权重矩阵 (每行和为1):")
print(attention_weights)
print()
# 步骤5: 加权求和得到输出
output = torch.matmul(attention_weights, V) # [seq_len, d_v]
if verbose:
print("步骤5: 加权求和得到输出")
print("每个位置的输出计算:")
for i in range(attention_weights.shape[0]):
weights = attention_weights[i]
weighted_sum = torch.zeros_like(V[0])
for j in range(V.shape[0]):
contribution = weights[j] * V[j]
weighted_sum += contribution
print(f" 位置 {i}: {weights[j]:.3f} × V[{j}] {V[j].detach().numpy()} = {contribution.detach().numpy()}")
print(f" → 输出[{i}] = {weighted_sum.detach().numpy()}")
print()
print(f"最终输出 (shape: {output.shape}):")
print(output)
print("=" * 60)
return output, attention_weights
def demonstrate_attention():
"""演示自注意力机制的工作过程"""
# 创建模型
attention = SimpleSelfAttention(d_model=4, d_k=2, d_v=2)
# 示例输入:3个词的序列,每个词用4维向量表示
# "猫" [0.8, 0.2, 0.4, 0.1]
# "吃" [0.1, 0.9, 0.3, 0.7]
# "鱼" [0.3, 0.1, 0.9, 0.2]
X = torch.tensor([
[0.8, 0.2, 0.4, 0.1], # 猫
[0.1, 0.9, 0.3, 0.7], # 吃
[0.3, 0.1, 0.9, 0.2] # 鱼
], dtype=torch.float32)
print("输入句子: ['猫', '吃', '鱼']")
print("每个词的向量表示:")
words = ["猫", "吃", "鱼"]
for i, word in enumerate(words):
print(f" '{word}': {X[i].numpy()}")
print()
# 前向传播,显示详细计算过程
output, attention_weights = attention(X, verbose=True)
# 可视化注意力权重
print("\n注意力权重热力图解释:")
print("行: 当前词(Query), 列: 被关注的词(Key)")
print(" 猫 吃 鱼")
for i, word in enumerate(words):
weights = attention_weights[i].detach().numpy()
print(f"{word} {weights}")
return output, attention_weights
def demonstrate_multihead_attention():
"""演示多头注意力的概念"""
print("\n" + "=" * 70)
print("多头注意力机制概念演示")
print("=" * 70)
# 使用PyTorch内置的多头注意力
multihead_attn = nn.MultiheadAttention(embed_dim=4, num_heads=2, batch_first=True)
# 同样的输入,但增加batch维度
X = torch.tensor([[
[0.8, 0.2, 0.4, 0.1], # 猫
[0.1, 0.9, 0.3, 0.7], # 吃
[0.3, 0.1, 0.9, 0.2] # 鱼
]], dtype=torch.float32) # [batch_size=1, seq_len=3, embed_dim=4]
print("输入形状:", X.shape)
# 前向传播
output, attention_weights = multihead_attn(X, X, X)
print("输出形状:", output.shape)
print("注意力权重形状:", attention_weights.shape)
print("\n多头注意力的优势:")
print("- 每个头可以关注不同类型的信息")
print("- 头1可能关注: 语法关系(主谓宾)")
print("- 头2可能关注: 语义关系(猫→吃→鱼)")
print("- 最终融合所有头的信息,获得更丰富的表示")
if __name__ == "__main__":
# 演示基础自注意力
output, weights = demonstrate_attention()
# 演示多头注意力
demonstrate_multihead_attention()
输出结果:
输入句子: ['猫', '吃', '鱼']
每个词的向量表示:
'猫': [0.8 0.2 0.4 0.1]
'吃': [0.1 0.9 0.3 0.7]
'鱼': [0.3 0.1 0.9 0.2]
============================================================
QKV自注意力机制详细计算过程
============================================================
输入 X (shape: torch.Size([3, 4])):
tensor([[0.8000, 0.2000, 0.4000, 0.1000],
[0.1000, 0.9000, 0.3000, 0.7000],
[0.3000, 0.1000, 0.9000, 0.2000]])
步骤1: 生成Q, K, V
Q (shape: torch.Size([3, 2])):
tensor([[0.6000, 0.4700],
[0.4000, 0.5400],
[0.5600, 0.6500]], grad_fn=<MmBackward0>)
K (shape: torch.Size([3, 2])):
tensor([[0.4000, 0.6300],
[0.6000, 0.5600],
[0.6400, 0.5900]], grad_fn=<MmBackward0>)
V (shape: torch.Size([3, 2])):
tensor([[0.3900, 0.6000],
[0.6300, 0.4500],
[0.4000, 0.7100]], grad_fn=<MmBackward0>)
步骤2: 计算注意力分数 Q × K^T
注意力分数矩阵 (shape: torch.Size([3, 3])):
tensor([[0.5361, 0.6232, 0.6613],
[0.5002, 0.5424, 0.5746],
[0.6335, 0.7000, 0.7419]], grad_fn=<MmBackward0>)
详细点积计算:
Q[0] · K[0] = [0.6 0.47000003] · [0.40000004 0.63 ] = 0.536
Q[0] · K[1] = [0.6 0.47000003] · [0.6 0.56] = 0.623
Q[0] · K[2] = [0.6 0.47000003] · [0.64000005 0.59 ] = 0.661
Q[1] · K[0] = [0.39999998 0.54 ] · [0.40000004 0.63 ] = 0.500
Q[1] · K[1] = [0.39999998 0.54 ] · [0.6 0.56] = 0.542
Q[1] · K[2] = [0.39999998 0.54 ] · [0.64000005 0.59 ] = 0.575
Q[2] · K[0] = [0.56 0.65000004] · [0.40000004 0.63 ] = 0.634
Q[2] · K[1] = [0.56 0.65000004] · [0.6 0.56] = 0.700
Q[2] · K[2] = [0.56 0.65000004] · [0.64000005 0.59 ] = 0.742
步骤3: 缩放
缩放因子: 1/sqrt(d_k) = 1/sqrt(2) = 0.707
缩放后的分数矩阵:
tensor([[0.3791, 0.4407, 0.4676],
[0.3537, 0.3835, 0.4063],
[0.4480, 0.4950, 0.5246]], grad_fn=<DivBackward0>)
步骤4: Softmax归一化
对每一行进行Softmax:
第0行: [0.37907997 0.440669 0.46760976] -> exp: [1.4609399 1.5537463 1.5961744] -> softmax: [0.31684756 0.33697537 0.34617713] (sum: 4.611)
第1行: [0.35369486 0.38353473 0.40630355] -> exp: [1.4243205 1.4674625 1.5012583] -> softmax: [0.32422197 0.33404252 0.34173554] (sum: 4.393)
第2行: [0.44795218 0.4949748 0.52460253] -> exp: [1.5651039 1.6404569 1.689787 ] -> softmax: [0.31971252 0.3351053 0.34518224] (sum: 4.895)
注意力权重矩阵 (每行和为1):
tensor([[0.3168, 0.3370, 0.3462],
[0.3242, 0.3340, 0.3417],
[0.3197, 0.3351, 0.3452]], grad_fn=<SoftmaxBackward0>)
步骤5: 加权求和得到输出
每个位置的输出计算:
位置 0: 0.317 × V[0] [0.39000005 0.6000001 ] = [0.12357055 0.19010855]
位置 0: 0.337 × V[1] [0.63 0.45] = [0.21229446 0.1516389 ]
位置 0: 0.346 × V[2] [0.4 0.71000004] = [0.13847084 0.24578576]
→ 输出[0] = [0.47433585 0.58753324]
位置 1: 0.324 × V[0] [0.39000005 0.6000001 ] = [0.12644659 0.19453323]
位置 1: 0.334 × V[1] [0.63 0.45] = [0.21044679 0.15031913]
位置 1: 0.342 × V[2] [0.4 0.71000004] = [0.13669422 0.24263225]
→ 输出[1] = [0.4735876 0.5874846]
位置 2: 0.320 × V[0] [0.39000005 0.6000001 ] = [0.12468789 0.19182752]
位置 2: 0.335 × V[1] [0.63 0.45] = [0.21111631 0.15079737]
位置 2: 0.345 × V[2] [0.4 0.71000004] = [0.1380729 0.2450794]
→ 输出[2] = [0.47387707 0.5877043 ]
最终输出 (shape: torch.Size([3, 2])):
tensor([[0.4743, 0.5875],
[0.4736, 0.5875],
[0.4739, 0.5877]], grad_fn=<MmBackward0>)
============================================================
注意力权重热力图解释:
行: 当前词(Query), 列: 被关注的词(Key)
猫 吃 鱼
猫 [0.31684753 0.33697534 0.3461771 ]
吃 [0.324222 0.33404252 0.34173554]
鱼 [0.3197125 0.33510527 0.34518224]
=====================================================================
多头注意力机制概念演示
=====================================================================
输入形状: torch.Size([1, 3, 4])
输出形状: torch.Size([1, 3, 4])
注意力权重形状: torch.Size([1, 3, 3])
多头注意力的优势:
- 每个头可以关注不同类型的信息
- 头1可能关注: 语法关系(主谓宾)
- 头2可能关注: 语义关系(猫→吃→鱼)
- 最终融合所有头的信息,获得更丰富的表示
五、Token钱包官网|Token钱包下载安装 - 安全加密数字货币钱包www.jnjtjx.com
QKV注意力机制是现代Transformer架构的核心突破,其本质是一个高效的信息检索与融合系统。该机制通过线性变换将输入序列转化为三组向量:
Query代表当前需要信息的"提问者"
Key作为其他位置的"身份标识"
Value则是实际承载的"信息内容"
核心计算流程首先通过Query与所有Key的点积相似度建立关联矩阵,再经Softmax归一化为概率分布,最终对Value进行加权融合。QKV机制赋予模型动态上下文感知能力,每个位置的输出都融合了全局相关信息,而非固定窗口内的局部特征,这使模型能有效处理代词指代、一词多义等复杂语言现象。相比传统循环神经网络的序列处理,注意力机制能直接捕获任意距离的依赖关系,且完全并行化计算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)