RAG工作流程与核心组件
RAG(检索增强生成)系统工作流程主要包括查询解析、文档检索、信息整合和回答生成四个关键环节。核心组件涵盖数据预处理(文本分块)、嵌入技术(BERT、BGE等模型)、向量存储与索引、检索优化(查询分解、多向量检索)以及信息整合(重排序、摘要生成)。RAG结合了信息检索的精确性和大模型的生成能力,有效提升了问答系统的准确性和可靠性。
RAG工作流程与核心组件
RAG工作流程
RAG工作流程总览

RAG工作流程关键节点
- 查询解析:查询解析的目标是立即用户的意图和信息需求,将其转化为系统能够有效处理的形式,可能涉及对查询进行预处理、意图识别、关键词提取、实体识别,甚至查询重写或扩展。
- 意图识别和关键词提取:通过意图识别和关键词提取,系统能够识别用户查询的核心目的和关键信息。
- 文档检索:允许系统访问和利用训练数据之外的最新或特定领域知识。检索过程通常依赖于高效的索引结构和相似度搜索算法,以在海量数据中快速定位相关信息。
- 信息整合:信息整合阶段的目标是将检索到的多个相关片段进行筛选、去重、排序,并将其组织称一个适合LLM理解的上下文。这个过程还会涉及到对检索结果的重排序(re-ranking)、摘要生成等。
- 回答生成:在获取了经过整合的上下文信息后,RAG系统将用户查询和这些上下文信息一同输入给大语言模型(LLM)。LLM利用其强大的语言理解和生成能力,结合提供的上下文,生成最终的回答。
RAG核心组件:数据导入与预处理
在RAG系统的整个生命周期中,数据是驱动一切的基础,高质量的知识库是RAG系统成功的关键。
因此,数据导入与预处理是构建RAG系统的第一步,也是至关重要的一步。这一阶段的目标是将原始、异构的数据转化为统一、干净、适合检索和嵌入模型处理的格式。
- 有标记文档:“优雅、简约、统一”表达多种形式的数据,被互联网世界接受,充斥在各种数据中,容易被大模型理解,如:Word, Markdown, HTML等
- 无标记文档:非结构化文档,不具备可编辑性,难以直接被大模型理解,如:PDF文档、图像、视频等
文本分块
在RAG系统中,文本分块是数据预处理的核心环节,合理的分块策略直接影响检索质量和生成效果。
分块的目标是在保持语义完整性的同时,将长文档分割成适合嵌入模型处理的片段。
分块策略的核心考量
- 语义完整性:确保每块包含完整的语义单元
- 检索粒度:平衡信息密度与检索精度
- 上下文保持:维持必要的上下文信息
- 计算效率:优化嵌入和检索性能

RAG核心组件:嵌入技术(Embedding)
嵌入技术是将人类可读的文本转化为机器可理解的数值向量表示,这些向量捕捉了文本的语义信息,使得计算机能够通过计算向量之间的距离或相似度来理解文本之间的关系。
常用的嵌入模型
- BERT:双向Transformer编码器,强大的上下文理解能力,适用场景:通用语义理解、问答系统
- RoBERTa:BERT优化版本,更大批量和数据训练,适用场景:性能要求高的通用NLP任务
- BGE:智源研究院开发的通用文本嵌入模型,适用场景:多语言RAG系统、中文语义检索
- E5:微软提出的对比学习嵌入模型,适用场景:信息检索、文档排序、RAG系统
RAG核心组件:向量存储与索引
向量数据库是专门为存储、管理和查询高维向量而设计的数据库。与传统数据库不同,向量数据库的核心功能是支持高效的相似度搜索。


RAG核心组件:检索
预检索与查询优化
对于需要多步推理的复杂问题,可以根据问题的逻辑结构将其分解为有序的子查询序列,每个子查询的结果为下一个子查询提供上下文信息。

检索方法
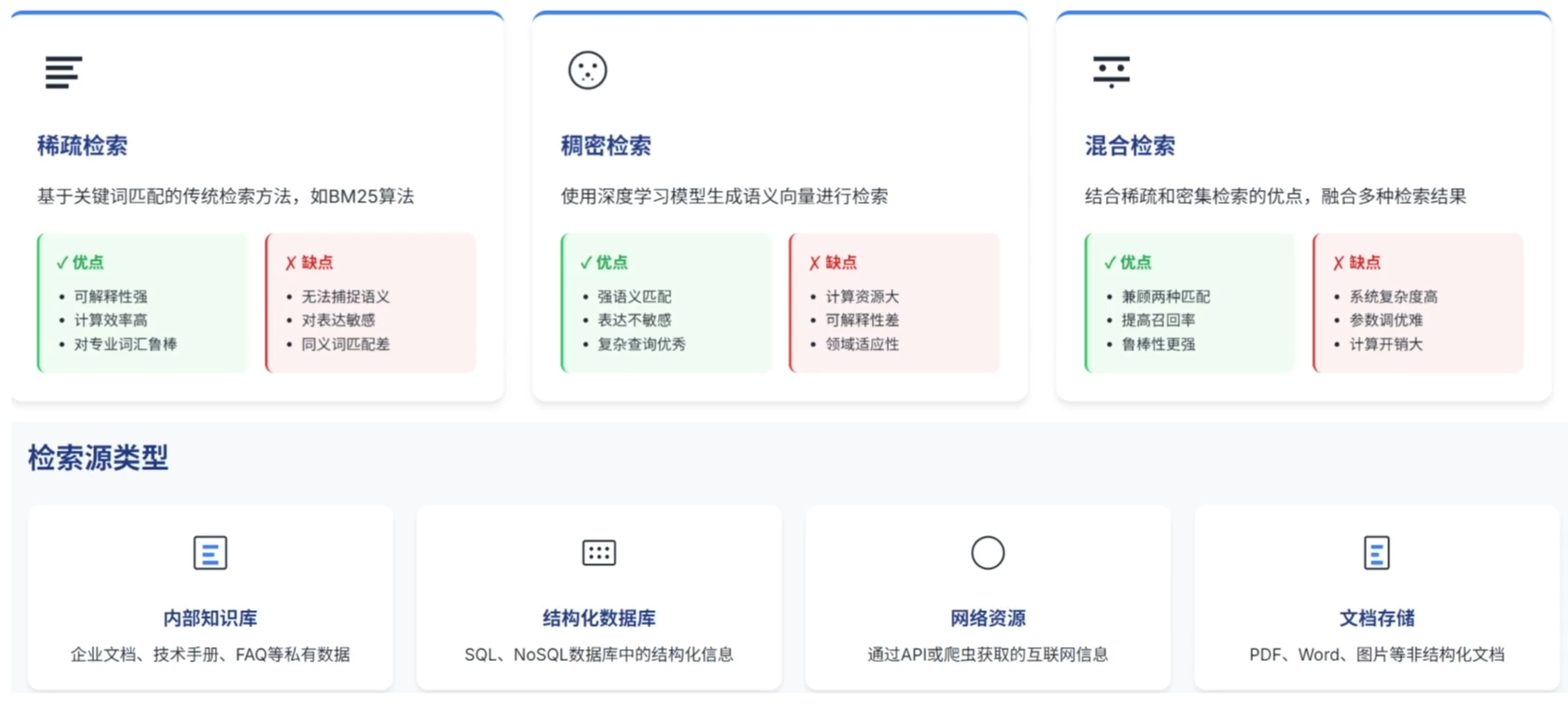
检索后处理
检索模块通常会返回大量潜在相关的文档或文本片段,为了提供LLM处理的效率和质量,需要对这些结果进行初步的筛选和排序:
- 相似度排序:根据查询与文档(或片段)之间的相似度得分进行降序排列,这是最基本的排序方式
- 多样性考虑:避免返回过多高度相似的文档,而是尝试返回覆盖查询不同方面、具有一定多样性的文档,以提供更全面的上下文
- 长度限制:LLM的上下文窗口是有限制的,因此需要限制检索结果的总长度,可以根据相似度得分截断,或者选择前N个最相关的片段
- 元数据过滤:根据文档的元数据(如:日期、作者、主题、文档类型等)进行过滤,只保留符合特定条件的文档
- 初步去重:去除高度重复的文档片段,避免LLM处理冗余信息

RAG核心组件:信息整合与回答生成
信息整合
在RAG工作流程中,文档检索阶段提供了与用户查询相关的原始信息。然后,这些信息通常是分散的、可能包含冗余或不完全相关的内容。因此,信息整合阶段至关重要,它负责将检索到的信息进行精炼和组织,为大模型提供一个高质量、紧凑且有用的上下文。随后,大模型将利用这些上下文和原始查询来生成最终的回答。
信息整合不是简单地拼接检索到的文本片段,更重要的是要将这些片段与原始查询进行有效融合,形成一个连贯的、对LLM友好的输入。

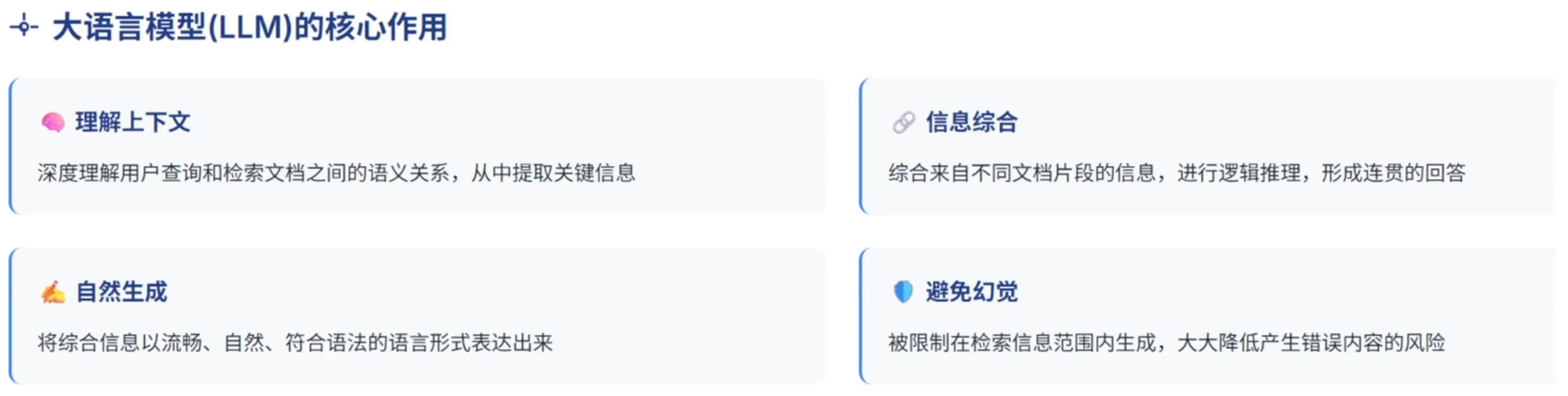
回答生成
在RAG系统中,LLM扮演着“智能生成器”的角色。它不再是独立地从其内部知识生成回答,而是做为一个强大的推理和文本生成引擎,被检索到的外部知识所“增强”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)