2026最新|程序员/小白转行大模型实操指南,避开90%的坑
2026年,大模型的风口依然在,但竞争也越来越激烈——转行大模型,没有“捷径”可走,却有“方法”可循。小白无需畏惧基础薄弱,程序员无需担心转型困难,核心是“找准方向、夯实基础、落地项目、持续学习”。大模型领域的门槛,不在于“学历”和“基础”,而在于“坚持”和“实操”。很多人之所以转型失败,不是因为基础差,而是因为半途而废、只学不练。每天进步一点点,每周完成一个小练习,每月落地一个小项目,慢慢就会发
2026年,大模型技术持续爆发,从通用大模型到行业定制模型,落地场景覆盖互联网、金融、医疗、工业等全领域,市场对大模型相关人才的需求持续攀升。但很多程序员(尤其是传统后端、前端程序员)和零基础小白,面对迭代飞快的技术、繁杂的学习体系,要么盲目跟风学习,要么陷入“学了不会用”的内耗,最终半途而废。为此,结合2026年大模型行业新趋势、新岗位需求,整理了这份全流程实操指南,从方向选择、基础夯实到项目落地、求职变现,手把手教你从零切入大模型领域,建议收藏+转发,避免踩坑走弯路!

一、找准转型方向,拒绝盲目跟风(2026年新增细分方向)
转行大模型的核心误区,就是“先学技术,再找方向”。2026年大模型领域的分工越来越精细,不同方向的学习难度、职业路径、薪资水平差异极大,结合自身基础和兴趣选择,才能让学习效率翻倍,避免做无用功。以下5个核心方向(含2026年新增细分),小白和程序员可对号入座,精准定位:
1. 大模型开发(进阶首选,适合有编程基础)
核心是“模型本身的打磨与迭代”,涵盖预训练模型优化、微调策略设计、模型性能调优,是2026年薪资涨幅最高的方向之一。需要具备扎实的编程能力、算法理解能力,日常工作涉及模型结构设计、训练参数调试、多模态融合优化等,适合有Python、机器学习基础的传统程序员(如后端、算法入门程序员)转型,零基础小白慎选。
2. 大模型应用开发(小白首选,落地性最强)
最适合零基础小白和擅长项目落地的程序员,核心是“用现成的大模型解决实际问题”,无需深入研究模型底层原理,侧重“实用性+落地性”。2026年主流场景包括:企业级AI应用(智能客服、文档总结)、AIGC工具开发(文案生成、图像编辑)、行业解决方案(教育题库生成、医疗报告解析),只需掌握基础工具和调用方法,就能快速实现项目落地,建立学习信心。
3. 大模型研究(高阶方向,适合科研背景)
侧重“前沿技术探索与创新”,核心是研发新的模型架构、优化预训练方法、突破大模型技术瓶颈(如上下文长度、推理速度),2026年重点聚焦于轻量化大模型、多模态融合、可信AI等方向。需要极强的数学基础(线性代数、概率论、深度学习)和科研思维,适合数学、计算机专业研究生、有科研经验的工程师,小白完全不建议入门。
4. 大模型工程化(刚需方向,适合运维/后端程序员)
核心是“大模型的工程化落地、运维与优化”,解决大模型“体积大、算力高、部署难”的痛点,是2026年企业最刚需的方向之一。日常工作包括多GPU分布式部署、模型压缩(量化、剪枝)、云端/边缘端部署、线上运维监控等,适合有系统运维、后端开发、云计算经验的程序员转型,小白入门需额外补充工程化相关知识(如Docker、K8s)。
5. 大模型Prompt工程师(新增细分,门槛最低)
2026年新增的热门细分方向,核心是“通过精准Prompt设计,让大模型输出符合需求的结果”,无需编程基础,侧重“逻辑思维+场景理解”。适合零基础小白、文案从业者、运营人员转型,入门快、落地快,可先从Prompt工程师切入,积累场景经验后,再进阶学习其他方向。
补充建议:小白优先选“大模型应用开发”或“Prompt工程师”,先快速落地小项目,建立信心;传统后端、运维程序员优先选“大模型工程化”,贴合自身优势,转型成本最低;有算法基础的程序员优先选“大模型开发”,薪资上限更高;数学/科研背景强的,可尝试“大模型研究”方向。
二、夯实基础知识,筑牢转型根基(2026年精简版,拒绝冗余)
无论选择哪个方向,基础知识都是“敲门砖”,但2026年大模型技术日趋成熟,无需像早期那样“死磕所有基础”,重点攻克“高频核心模块”,搭配实操练习,就能快速衔接高阶技术,避免“学了不用、记了就忘”。以下3个核心模块,是所有方向的必备基础,小白和程序员可按需侧重:
(一)编程语言与工具(必学,小白优先攻克)
1. Python(核心中的核心,无需精通,够用就好)
大模型领域的主流编程语言,没有之一,无论是模型开发、应用调用,还是数据处理,都离不开Python。2026年无需掌握所有高级特性,重点攻克“基础语法+核心用法”,小白可在1-2个月内掌握:
基础必备:语法规则、数据结构(列表、字典、集合、元组)、控制流(if语句、for/while循环)、函数定义与调用、模块和包的使用(如import用法),重点掌握Pandas、NumPy的调用语法;
进阶补充:装饰器、迭代器、多线程/多进程(处理大规模数据时常用),仅大模型开发、工程化方向需要深入学习,应用开发、Prompt工程师只需了解即可。
实操建议:每天练1个Python小案例(如数据读取、简单函数编写、调用Hugging Face模型),推荐使用PyCharm编辑器,搭配CSDN的Python入门题库,快速熟悉编程环境。
2. 深度学习框架(重点掌握1个,小白优先PyTorch)
核心作用:简化大模型的构建、训练和部署流程,无需从零编写复杂算法。2026年主流框架依然是PyTorch和TensorFlow,小白优先学PyTorch(语法简洁、上手快,研究/工业界都常用,社区资源最丰富);有TensorFlow基础的程序员,可无需切换,重点补充大模型相关API的使用。
必备技能:模型结构定义(搭建简单神经网络)、数据集加载与预处理、优化器设置(SGD、Adam)、模型训练与评估(计算损失、验证准确率);
进阶补充:自定义层、分布式训练(大模型开发、工程化方向必备),小白先掌握“基础用法”,能独立调用预训练模型即可。
3. 核心工具(2026年高频必备,小白循序渐进)
大模型训练/应用离不开工具,这4个工具是2026年所有方向的必备,小白可按“易到难”顺序学习:
Hugging Face:大模型入门“捷径”,开源平台,提供丰富的预训练模型(GPT-4、LLaMA 3、Qwen等)和工具,必备技能:模型加载、简单微调、推理预测(小白可直接调用现成模型,无需从零训练);
Pandas:数据处理与分析神器,必备技能:数据读取(csv、excel)、数据清洗(去空值、去重)、数据转换(格式调整、特征提取),大模型应用、开发都离不开;
NumPy:数值计算库,核心用于处理多维数组,是深度学习的基础工具,必备技能:数组创建、数组运算(加减乘除、矩阵运算);
LangChain:2026年大模型应用开发必备工具,用于搭建复杂的AI应用(如对话机器人、文档问答),必备技能:链的搭建、向量数据库的使用,小白重点掌握基础调用。
(二)数学基础(小白不用深究推导,会用即可)
很多小白看到“数学”就退缩,其实2026年大模型入门,无需掌握复杂的推导过程,重点理解“核心概念+应用场景”,后续结合技术逐步深化即可,避免陷入“死磕数学”的误区。
1. 线性代数(核心中的核心)
核心知识点:矩阵运算(加法、乘法、转置)、向量(点积、叉积)、特征值分解;
应用场景:神经网络中,权重和偏置用矩阵表示,通过矩阵乘法计算神经元输出,小白只需理解“矩阵是什么、怎么简单运算”即可。
2. 概率论与统计
核心知识点:概率分布(正态分布、均匀分布)、贝叶斯定理、最大似然估计;
应用场景:处理数据噪声、模型不确定性(如训练时的随机抽样),比如随机梯度下降算法,就基于概率论中的随机思想,小白只需知道“这些概念是用来解决什么问题的”。
3. 微积分
核心知识点:梯度、导数、链式法则;
应用场景:模型优化(如通过梯度下降更新参数,降低模型误差),小白无需推导导数,只需理解“梯度是用来衡量模型误差变化的,链式法则是用来计算复杂模型梯度的”。
(三)机器学习基础(衔接大模型的关键,无需精通)
大模型本质是“深度神经网络的延伸”,掌握基础的机器学习知识,能让你更快理解大模型的原理,避免“只会用、不会懂”。2026年无需精通所有算法,重点掌握核心思想即可:
1. 经典机器学习算法(重点掌握3个)
无需全部精通,重点掌握3个核心算法,理解“机器学习的基本思想”——从数据中学习规律,用于预测和分类:
线性回归:建立输入与输出的线性关系(如根据房价数据预测房价),理解“拟合”的核心思想;
决策树:用于分类和预测(如根据用户特征判断是否购买商品),理解“特征分裂”的逻辑;
SVM(支持向量机):寻找最优分类超平面(如文本分类、图像分类),为后续理解大模型的分类逻辑打下基础。
实操建议:用Python实现简单的算法案例(如用线性回归预测数据),感受“数据→模型→预测”的流程,无需深入优化。
2. 深度学习基本概念
先掌握这些基础概念,再学大模型会更轻松,避免被“专业术语”劝退:
神经网络:由神经元、层组成,核心是“通过多层计算提取数据特征”;
反向传播:用于计算模型误差对参数的梯度,更新参数以降低误差;
损失函数:衡量模型预测误差(如均方误差、交叉熵),误差越小,模型性能越好。
三、深入学习大模型核心技术(2026年重点更新,突破进阶瓶颈)
夯实基础后,就可以聚焦大模型本身的核心技术——这部分是转型的“核心竞争力”,也是2026年企业招聘的重点考察内容。小白侧重“理解原理+会用”,能独立调用模型、落地项目即可;程序员侧重“深入掌握+优化”,打造自身技术优势。
(一)Transformer架构(大模型的“灵魂”,必学)
所有主流大模型(GPT-4、LLaMA 3、Qwen、BERT等)的核心架构,摒弃了传统RNN、CNN的结构,核心优势是“能捕捉长距离数据依赖,支持并行计算”,大大提升了模型的效率和性能,2026年所有大模型的优化,都基于Transformer架构的改进。
小白重点理解2个核心组件(无需深究代码实现):
\1. 自注意力机制(Self-Attention):模型能“关注到输入数据的不同部分”,比如处理文本时,能理解上下文之间的关联(如“他”指代前文的哪个人);
\2. 多头注意力机制(Multi-Head Attention):多个自注意力机制并行工作,能捕捉到更丰富的数据特征,提升模型的表达能力。
补充建议:推荐阅读论文《Attention is All You Need》(Transformer的开创性论文),小白无需精读推导,重点看“核心思想和架构图”,理解Transformer是如何工作的;程序员可深入研读,掌握架构细节,为后续模型优化打下基础。
(二)预训练与微调(大模型应用/开发的核心流程,2026年重点)
大模型的训练/应用,本质是“预训练+微调”的流程——2026年,预训练的门槛越来越高(需要海量算力和数据),小白无需掌握预训练的完整流程,重点掌握“微调”,就能快速落地项目;程序员可深入学习预训练的核心逻辑,提升自身竞争力。
1. 预训练(小白了解,程序员重点)
核心:在大规模无监督数据集上训练模型,让模型学习通用的特征(如语言知识、图像特征)。2026年主流预训练模型(如LLaMA 3、Qwen 2.0),都是在海量文本、图像语料库上预训练,从而具备基础的语言理解、生成和图像识别能力。
补充:小白无需自己做预训练(需要大量算力和数据,个人难以实现),直接使用Hugging Face、字节跳动即梦AI等平台的现成预训练模型即可;程序员可深入学习预训练的策略(如指令微调、多模态预训练),提升模型优化能力。
2. 微调(小白/程序员都需掌握,2026年高频考点)
核心:在预训练模型的基础上,用小规模“任务专属数据”进一步训练,让模型适配具体应用场景(如文本分类、机器翻译、文案生成),是2026年企业招聘的重点考察内容。
实操案例:用预训练的BERT模型,在IMDB电影评论数据集上微调,实现“电影评论情感分类”(正面/负面);用LLaMA 3模型微调,实现“企业专属文案生成”;用Qwen模型微调,实现“行业文档问答”。
关键技巧:2026年主流的微调方法是“LoRA微调”(参数高效微调),无需修改模型全部参数,只需调整部分顶层参数,就能兼顾“效率和性能”,小白可重点练习这一操作,程序员可深入研究微调策略优化。
(三)大模型优化(程序员重点,小白了解即可)
大模型的痛点依然是“体积大、算力要求高、部署困难”,优化技术就是解决这些问题,让模型能在普通设备上稳定运行,也是大模型工程、开发方向的核心技能,2026年企业对这部分能力的需求持续提升。
1. 模型压缩(2026年高频优化方向)
核心:在不显著降低模型性能的前提下,减小模型体积、降低计算开销,常用3种技术(程序员需掌握,小白了解概念):
知识蒸馏:将复杂大模型(教师模型)的知识,迁移到简单小模型(学生模型)上,小模型体积小、速度快,适合边缘端部署(如手机、物联网设备);
剪枝:去除模型中“不重要的连接或神经元”,减少参数数量(如去除权重接近0的连接),2026年重点是“结构化剪枝”,兼顾效率和性能;
量化:将模型参数从高精度(如32位)转换为低精度(如8位、4位),减少存储和计算需求,是2026年边缘端部署的必备技术,程序员需掌握具体实现方法。
2. 分布式训练与部署(工程化核心)
分布式训练:将训练任务分配到多个GPU、多个节点上并行执行,缩短训练时间(大模型单GPU训练可能需要数月,分布式训练可缩短至数天),2026年主流工具是Horovod、PyTorch Distributed,程序员需掌握“数据并行”“模型并行”的核心逻辑;
分布式部署:将微调后的大模型部署到云端、边缘端,支持高并发请求,2026年重点是“容器化部署”(Docker、K8s),程序员需掌握部署流程和监控方法;小白了解“分布式训练/部署是用来解决算力不足、部署困难问题”即可。
(四)大模型应用场景(2026年热门,小白重点,落地为王)
学习技术的最终目的是“落地应用”,2026年大模型的应用场景越来越广泛,小白可优先选择一个深耕,快速实现项目落地,积累实战经验,为后续求职加分;程序员可结合自身基础,选择贴合的场景深耕,打造项目成果。
1. 自然语言处理(NLP,最成熟、最适合小白)
2026年依然是最成熟、落地性最强的场景,常见任务(小白可优先练习):
文本分类:情感分析、新闻分类、垃圾邮件识别(实操案例:用BERT微调实现电商商品评论情感分类,落地企业客服场景);
文本生成:文案生成、报告总结、代码生成(实操案例:用LLaMA 3微调,实现企业产品文案自动生成);
问答系统:基于文本内容,回答用户问题(实操案例:用BERT+SQuAD数据集,搭建企业文档问答系统,解决员工查询文档效率低的问题)。
2. 计算机视觉(CV,2026年热门拓展方向)
结合大模型的CV场景,落地性越来越强,适合有一定基础的小白和程序员,常见任务:
图像生成:用扩散模型、GAN模型生成逼真图像(如人脸、风景、产品图,实操案例:用Stable Diffusion微调,生成企业产品宣传图);
目标检测:在图像/视频中,检测出指定物体(如人脸、车辆、工业零件缺陷,实操案例:用YOLO模型+大模型优化,实现工业零件缺陷检测);
图像分割:将图像中的不同区域分割开来(如医学影像分割、城市地图分割),2026年在医疗、工业领域需求旺盛。
3. 多模态模型(2026年前沿方向,拓展视野)
核心:融合多种数据类型(文本、图像、音频),实现更强大的功能,是2026年大模型的发展趋势,小白可尝试用现成模型落地简单场景,程序员可深入研究融合策略。
常见模型:CLIP(能理解图像和文本的语义关联)、DALL·E 3(文本生成图像)、GPT-4V(图文理解)、Qwen-VL(多模态问答);
实操案例:用CLIP实现图文匹配(如上传一张产品图,匹配对应的产品描述);用DALL·E 3根据文本描述,生成企业宣传海报;用GPT-4V实现图文问答(如上传一张图表,让模型分析图表数据)。
四、实操项目落地(重中之重,2026年求职必备)
大模型领域,“实战经验”比“理论知识”更重要——小白之所以难以转型,核心是缺乏项目经验,无法将所学知识落地;程序员转型,也需要通过项目积累大模型相关经验,提升求职竞争力。以下4个入门级项目(2026年最新,从简单到复杂),小白可循序渐进,程序员可在此基础上优化升级,打造自己的项目作品集。
1. 文本分类(小白入门首选,0基础可落地)
项目目标:用预训练模型,实现文本情感分类(如电商商品评论好评/差评、电影评论正面/负面),可直接用于企业客服场景;
所需工具:Python、PyTorch、Hugging Face、Pandas;
数据集推荐:IMDB电影评论数据集、京东商品评论数据集(公开可下载,数据量适中,适合小白);
核心步骤:数据读取与清洗(去空值、去重、分词)→ 加载预训练BERT模型 → 用LoRA方法微调模型 → 模型评估(计算准确率)→ 生成预测结果;
补充:小白可直接调用Hugging Face的现成模型,无需从零搭建,重点练习“数据预处理”和“LoRA微调操作”,完成后可上传GitHub,标注清晰的代码注释和项目说明。
2. 文案生成工具(进阶实操,贴合2026年企业需求)
项目目标:用预训练大模型(LLaMA 3、Qwen)微调,实现企业专属文案生成(如产品文案、活动文案、朋友圈文案);
所需工具:Python、PyTorch、Hugging Face、LangChain;
数据集准备:收集企业产品相关文案(可从企业官网、电商平台抓取),整理成微调数据集;
核心步骤:数据集预处理(格式调整、指令构造)→ 加载预训练模型 → LoRA微调 → 搭建简单的交互界面(可选)→ 测试文案生成效果;
补充:小白可简化步骤,用LangChain调用现成模型,无需微调,快速实现文案生成;程序员可优化微调策略,提升文案生成的准确性和贴合度,增加交互功能。
3. 文档问答系统(综合实操,求职加分项)
项目目标:基于给定的企业文档(如员工手册、产品说明书),让模型回答用户提出的问题,解决企业员工查询文档效率低的问题;
所需工具:Python、PyTorch、Hugging Face、LangChain、向量数据库(Chroma);
数据集准备:整理企业文档(PDF、Word格式),分割成小块,存入向量数据库;
核心步骤:加载文档并分割 → 构建向量数据库(存储文档嵌入)→ 加载预训练BERT/Qwen模型 → 搭建问答链 → 测试问答效果(如输入“员工年假有多少天”,模型返回对应答案);
关键技巧:重点练习“向量数据库的使用”和“问答链的搭建”,这是2026年大模型应用开发的高频技能,项目完成后可作为求职时的核心成果。
4. 图像生成工具(拓展实操,贴合前沿趋势)
项目目标:用扩散模型(Stable Diffusion),实现文本生成图像(如产品宣传图、风景图、人物图),可用于企业宣传、设计场景;
所需工具:Python、PyTorch、Stable Diffusion WebUI、Hugging Face;
数据集推荐:COCO数据集、FFHQ数据集(公开可下载,用于微调模型);
核心步骤:加载Stable Diffusion模型 → 编写Prompt(优化文本描述,提升图像生成质量)→ 生成图像 → 微调模型(可选,让生成的图像更贴合需求)→ 优化图像效果;
补充:小白可使用Stable Diffusion WebUI,无需编写大量代码,重点练习“Prompt优化”,快速生成图像;程序员可深入研究模型微调,优化生成速度和图像质量,搭建自定义的图像生成接口。
项目注意事项(2026年重点提醒):① 每做一个项目,都要整理代码,上传到GitHub(后续求职/复盘有用),标注清晰的项目说明、核心代码注释和效果演示;② 遇到问题,优先查官方文档、Stack Overflow、CSDN博客,培养独立解决问题的能力,这是企业招聘的重点考察点;③ 不要追求“完美项目”,先实现核心功能,再逐步优化,避免半途而废;④ 可在CSDN、Medium等平台分享项目实操过程,提升个人影响力。
五、参与开源社区,加速成长(小白/程序员都适用)
2026年大模型领域的技术更新速度极快,单靠自己学习,很容易落后于行业趋势——参与开源社区,能接触到最新的技术、优秀的代码、行业同行,既能快速补全知识漏洞,又能积累行业人脉,甚至能为后续求职加分(很多企业会关注开源社区的贡献者)。
4个必关注的开源项目/社区(2026年最新,小白优先前2个)
1. Hugging Face(小白首选,最实用)
核心优势:提供丰富的预训练模型(含2026年最新的LLaMA 3、Qwen 2.0)、工具库、教程,还有大量开发者分享的项目代码,小白可直接调用模型、参考代码,快速上手;
参与方式:① 阅读官方教程,学习模型的使用方法和微调技巧;② 参考社区内的入门项目,仿写代码,积累经验;③ 遇到问题,在社区提问,与开发者交流;④ 小白可尝试提交简单的代码修改,积累开源经验。
2. 字节跳动即梦AI(国内首选,本土化资源丰富)
核心优势:字节跳动旗下AI创作平台,提供免费的预训练模型、微调工具和实操教程,贴合国内开发者的学习习惯,还有大量中文数据集和项目案例,小白可快速上手;
参与方式:① 学习平台内的大模型入门教程,掌握基础工具的使用;② 参与平台的开源项目,仿写中文场景下的大模型应用;③ 加入平台的开发者社群,与同行交流学习,获取求职机会。
3. TensorFlow Model Garden(程序员重点)
核心优势:包含大量经典深度学习、大模型的参考实现(如图像分类、目标检测、NLP模型),代码规范、注释详细,2026年更新了大量多模态模型的实现代码,适合程序员学习和借鉴;
参与方式:① 阅读代码,学习模型的工程化实现方法和优化技巧;② 基于现有代码,进行二次开发、优化,适配具体场景;③ 提交自己的代码贡献,解决社区内的issues,提升个人影响力。
4. PyTorch Lightning(简化训练流程,程序员必备)
核心优势:封装了PyTorch的训练流程,提供简洁的接口,让开发者无需花费大量时间搭建训练框架,可专注于模型设计和优化,2026年新增了大模型LoRA微调、分布式训练的简化接口;
参与方式:① 学习官方文档,掌握工具的使用方法;② 用PyTorch Lightning重构自己的项目,简化训练流程;③ 参与社区讨论,解决使用过程中遇到的问题,分享自己的使用经验。
补充建议:小白初期以“学习、借鉴”为主,多阅读代码、仿写项目,积累经验;程序员可尝试“贡献代码、解决issues”,积累开源经验,打造个人技术品牌,为求职加分。
六、优质学习资源推荐(2026年最新,省时高效,拒绝踩坑)
大模型领域的学习资源繁杂,很多小白容易陷入“资源囤积”的误区——收藏了大量教程、书籍,却从来没有认真学习,最终一事无成。以下资源经过筛选(2026年最新),覆盖视频、书籍、论文、博客,小白和程序员可按需选择,重点是“学透一个,再学下一个”,避免贪多嚼不烂。
(一)在线课程(小白优先,可视化学习,快速入门)
1. 字节跳动即梦AI:《大模型入门到落地实战》
推荐理由:本土化教程,贴合国内开发者的学习习惯,从基础工具到项目落地,循序渐进,包含2026年最新的LoRA微调、多模态模型应用等内容,免费开放,适合小白和零基础程序员,搭配实操案例,能快速上手。
2. Coursera:Andrew Ng《深度学习专项课程》(2026年更新版)
推荐理由:深度学习领域的经典课程,由AI领域权威Andrew Ng授课,2026年更新了大模型相关内容,系统讲解深度学习的基础、算法、应用,适合小白入门,内容通俗易懂,搭配实操练习,能快速建立知识体系。
3. Fast.ai:面向实践的深度学习课程(2026年版)
推荐理由:课程节奏快、侧重实操,通过真实项目案例,讲解深度学习和大模型的核心技术,包含2026年热门的多模态模型、模型优化等内容,适合有一定Python基础的小白和程序员,能快速提升实操能力。
(二)书籍(深入学习,夯实基础,程序员重点)
1. 《深度学习》(Ian Goodfellow 著,2026年修订版)
推荐理由:深度学习领域的“圣经”,2026年修订版新增了大模型、多模态模型的相关内容,全面讲解深度学习的数学原理、算法模型、应用场景,适合想要深入掌握基础的程序员,小白可先通读,后续逐步精读。
2. 《动手学深度学习》(李沐 著,2026年第三版)
推荐理由:最适合小白的实操指南,2026年第三版更新了大量大模型实操案例(如LoRA微调、LangChain应用),搭配大量Python代码示例和项目案例,深入浅出地讲解深度学习和大模型的核心知识,小白可跟着代码一步步练习,快速上手。
3. 《大模型工程化实践》(2026年新书)
推荐理由:聚焦大模型工程化落地,包含2026年热门的模型压缩、分布式训练与部署、容器化部署等内容,适合想要转型大模型工程化方向的程序员,内容贴合工业界需求,实操性强。
(三)论文与博客(关注前沿,补充拓展)
1. arXiv(论文平台)
推荐理由:全球最大的预印本论文平台,大模型领域的最新研究成果(如Transformer改进、新模型发布、多模态融合技术),都会率先在该平台发布,适合想要了解前沿技术的程序员,小白可选择性阅读摘要和核心结论。
2. Medium(技术博客)
推荐理由:有大量AI领域专家、从业者,分享大模型的技术文章、实操经验、行业见解,2026年有很多关于LoRA微调、多模态模型应用的优质文章,内容通俗易懂,适合小白和程序员日常阅读,拓宽技术视野。
3. CSDN博客(本土化资源,小白首选)
推荐理由:国内最大的技术博客平台,有大量开发者分享大模型入门教程、项目实战、问题解决方案,贴合国内开发者的学习习惯,遇到问题可直接搜索,快速找到解决方案;小白可关注大模型相关博主,跟着学习实操案例。
七、职业发展建议(2026年最新,小白/程序员针对性指导)
学习大模型技术,最终目的是“转型就业、实现变现”——2026年大模型领域的岗位需求持续攀升,但竞争也越来越激烈,只有掌握正确的职业发展策略,才能少走弯路,快速实现职业突破,拿到心仪的offer。以下建议,结合小白和程序员的不同基础,针对性给出。
(一)构建个人品牌(2026年求职核心竞争力)
1. GitHub分享项目和代码(必备)
GitHub是程序员的“个人名片”,无论是小白还是程序员,都要养成“上传代码、整理项目”的习惯:小白可上传入门项目(如文本分类、文案生成工具),标注清晰的代码注释、项目说明和效果演示;程序员可上传优化后的项目、开源工具、模型优化代码,展示自己的技术能力。2026年企业招聘大模型相关岗位时,都会重点查看GitHub项目,优质的项目能直接吸引雇主的关注。
2. 分享学习心得,建立个人影响力
在CSDN、Medium、知乎等平台,撰写技术博客,分享自己的学习心得、项目实操过程、遇到的问题及解决方案。既能强化自己的记忆,又能帮助其他学习者,逐步建立自己在大模型领域的个人影响力。小白可从“入门教程”“踩坑记录”“项目实操”写起,程序员可分享“技术优化”“源码解析”“模型工程化实践”,吸引行业同行和企业关注。
3. 参加技术会议和比赛(拓展人脉,提升知名度)
多参加大模型相关的技术会议(如AI Summit、大模型技术论坛、字节跳动即梦AI开发者大会)和比赛(如Kaggle大模型竞赛、国内大模型应用大赛),与行业内的专家、同行交流切磋,展示自己的技术实力。比赛中的成绩、会议中的交流经历,都能成为求职时的加分项,也能拓宽自己的职业人脉,甚至能获得内推机会。
(二)寻找实习/全职机会(2026年最新,针对性投递)
1. 大厂机会(适合有基础的程序员)
关注Google、OpenAI、DeepMind、字节跳动、百度、阿里、腾讯等大厂的招聘信息——这些大厂在大模型领域资源丰富、团队优秀,能参与前沿项目,积累宝贵的工作经验,薪资水平也高于行业平均。2026年大厂重点招聘大模型开发、工程化、多模态模型相关岗位,适合有一定编程、算法基础的程序员,投递时重点突出自己的项目经验和技术能力(如模型优化、工程化落地能力)。
2. 初创公司机会(适合小白和新手程序员)
初创公司在大模型领域的发展速度快、创新活力强,对新手的包容度更高,不需要丰富的工作经验,更看重学习能力和实操能力,2026年很多初创公司在招聘大模型应用开发、Prompt工程师等岗位,门槛较低。小白和新手程序员可优先选择初创公司,能快速接触到实际业务场景,参与完整的项目流程,快速提升综合能力,同时也可能获得更多的晋升空间,积累项目经验后,再跳槽到大厂。
3. 投递技巧(2026年重点提醒)
小白投递时,重点突出“项目经验”(即使是入门项目)和“学习能力”,附上自己的GitHub地址和技术博客,简历中重点写清楚项目的核心步骤、自己负责的部分和项目成果;
程序员投递时,重点突出“技术优势”(如模型优化、工程部署、多模态模型应用)和“项目成果”(如优化后的模型性能、落地的项目案例、开源贡献),针对岗位需求,调整简历侧重点(如应聘工程化岗位,重点写分布式部署、模型压缩相关经验)。
(三)持续学习(立足行业的核心,2026年重点)
2026年大模型领域的技术更新速度极快,新模型(如LLaMA 3、Qwen 2.0)、新工具(如LangChain新版本)、新算法不断涌现,想要长期立足,必须保持持续学习的习惯,避免被行业淘汰。
\1. 关注行业动态:每天花10-20分钟,阅读大模型相关的博客、论文摘要、行业资讯,了解最新技术趋势和岗位需求;
\2. 补充新技术:定期学习新的工具、新的模型(如2026年热门的多模态模型、模型优化技术),更新自己的知识体系,避免“只会用旧技术”;
\3. 与同行交流:加入大模型学习社群、开源社区,与同行交流学习经验、解决技术难题,避免闭门造车,及时了解行业内的最新动态和求职信息。
八、常见问题解答(2026年小白/程序员高频疑问)
整理了2026年小白和程序员转型大模型时,最常遇到的4个问题,精准解答,帮你避开误区,坚定转型信心,少走弯路。
1. 没有机器学习基础,能转行大模型吗?(小白最常问)
完全可以!2026年大模型的入门门槛已经降低,无需担心自己没有基础。核心建议:先从“Python+基础工具(Hugging Face、LangChain)”入手,再学习机器学习、深度学习的基础概念(无需深究推导),最后聚焦大模型的应用和实操(如调用模型、简单微调),循序渐进即可。虽然零基础会增加学习难度,但只要制定合理的学习计划,坚持每天学习、实操,8-12个月就能实现转型,关键在于“坚持”和“落地项目”,而不是“基础有多好”。
2. 转行大模型需要多长时间?(因人而异)
没有固定答案,核心取决于“个人基础”和“学习投入”,结合2026年的技术趋势,给出参考时间:
① 有Python/机器学习基础的程序员:每天投入2-3小时,6-8个月可掌握核心技术,完成项目积累,实现转型;
② 有后端/运维基础,无机器学习基础的程序员:每天投入2-3小时,8-10个月可转型(重点补充机器学习基础和大模型工程化相关知识);
③ 零基础小白:每天投入3-4小时,10-12个月可完成从基础到实操的突破,具备求职竞争力;
补充:学习时一定要“专注”,不要同时学多个方向、多个工具,先攻克一个模块(如Python),再学下一个,避免贪多嚼不烂。制定详细的学习计划,每天完成固定的学习任务,能大幅缩短转型时间。
3. 2026年大模型领域的职业前景如何?值得转行吗?(核心疑问)
非常值得!2026年大模型技术已经从“概念炒作”进入“全面落地”阶段,成为AI领域的核心风口,也是未来10年的热门技术方向,职业前景广阔、薪资水平偏高,具体优势如下:
① 岗位需求:随着大模型在互联网、金融、医疗、教育、工业等各个行业的落地,对大模型开发、应用、工程、研究等方向的人才需求持续增长,岗位缺口大,尤其是大模型工程化、多模态模型相关岗位;
② 薪资水平:大模型相关岗位的薪资,比普通程序员、AI工程师高出30%-50%,2026年入门级岗位(如Prompt工程师、大模型应用开发)薪资普遍在18k+/月,有1-2年经验的工程师薪资可达35k+/月,大厂资深工程师薪资可达50k+/月;
③ 发展空间:大模型领域处于快速发展阶段,有大量的技术创新和职业晋升机会,无论是深耕技术(如从应用开发晋升为模型架构师),还是转向管理、创业,都有广阔的发展空间。
4. 2026年转行大模型,最容易踩的坑有哪些?(重点提醒)
① 盲目跟风,不找方向:上来就学Transformer、学数学,不知道自己要做哪个方向,最终学了一堆知识,却无法落地,半途而废;
② 只学理论,不做项目:沉迷于看教程、看书籍,却不做实操项目,导致“学了不会用”,求职时没有项目经验,无法竞争力;
③ 贪多嚼不烂:同时学多个框架、多个方向(如既学PyTorch,又学TensorFlow;既学开发,又学工程),最终哪个都没学好;
④ 死磕底层推导:小白过度纠结于数学推导、模型底层原理,忽略了“实操落地”,导致学习进度缓慢,失去信心;
⑤ 忽视开源社区和个人品牌:不积累项目经验,不分享学习心得,求职时没有拿得出手的成果,难以获得企业关注。
最后寄语(2026年转型共勉)
2026年,大模型的风口依然在,但竞争也越来越激烈——转行大模型,没有“捷径”可走,却有“方法”可循。小白无需畏惧基础薄弱,程序员无需担心转型困难,核心是“找准方向、夯实基础、落地项目、持续学习”。
大模型领域的门槛,不在于“学历”和“基础”,而在于“坚持”和“实操”。很多人之所以转型失败,不是因为基础差,而是因为半途而废、只学不练。每天进步一点点,每周完成一个小练习,每月落地一个小项目,慢慢就会发现,入门大模型并没有那么难。
2026年,大模型的落地场景越来越广泛,只要你愿意坚持、愿意动手,就能在这个领域找到自己的位置。建议收藏这份指南,跟着流程逐步学习、实操,遇到问题随时复盘,相信你一定能成功转型,在大模型领域实现自己的职业价值!
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。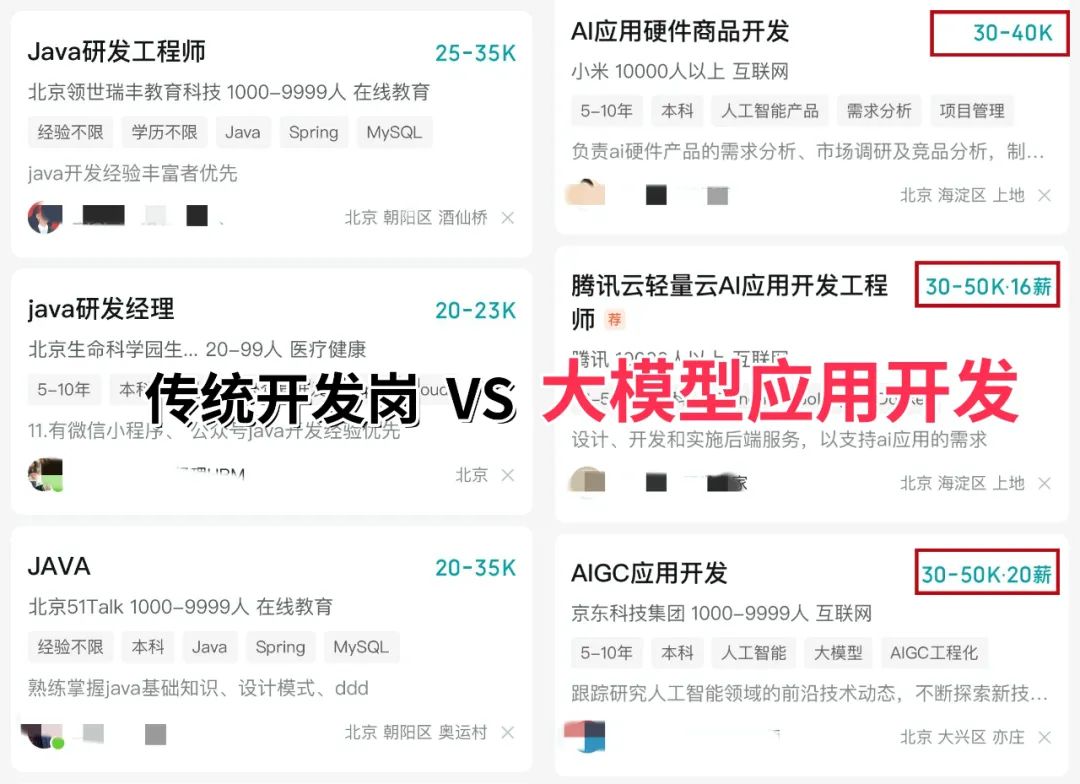
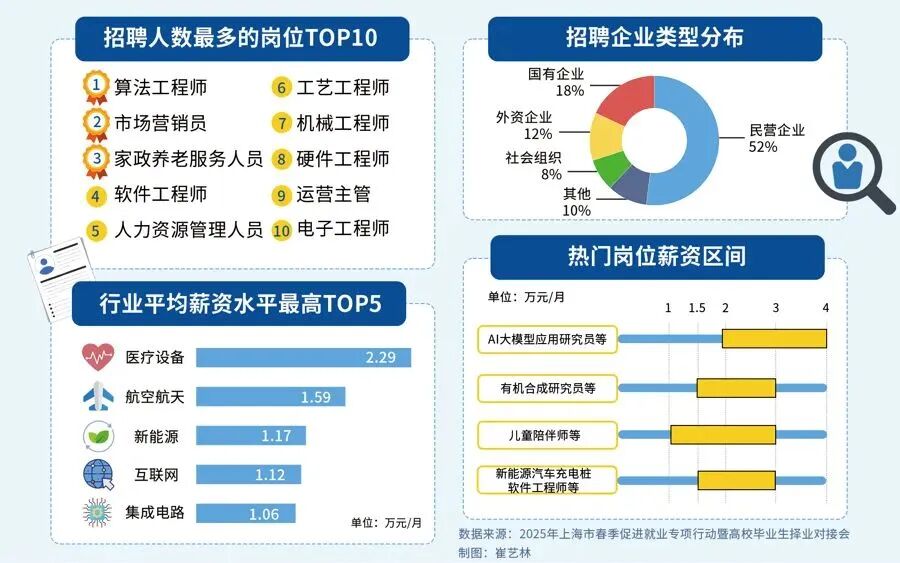
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献492条内容
已为社区贡献492条内容

所有评论(0)