收藏备用|小白/程序员必看!从零搭建可落地的AI Agent学习框架(附实战案例)
过去两三年,我陆续为多家企业的资深开发团队开展AI Agent专项培训;近一个月,又专门针对刚毕业的技术新人,量身设计了一套零门槛Agent入门培训体系。直到本周,结合AI能力的模拟项目顺利落地、通过验收后,我才彻底梳理沉淀出一套核心方法论:如何为不同技术阶段的开发者,搭建一套系统、可落地、能快速上手的AI Agent学习框架,避开入门坑、少走冤枉路。
过去两三年,我陆续为多家企业的资深开发团队开展AI Agent专项培训;近一个月,又专门针对刚毕业的技术新人,量身设计了一套零门槛Agent入门培训体系。直到本周,结合AI能力的模拟项目顺利落地、通过验收后,我才彻底梳理沉淀出一套核心方法论:如何为不同技术阶段的开发者,搭建一套系统、可落地、能快速上手的AI Agent学习框架,避开入门坑、少走冤枉路。
这一梳理过程,也让我深刻体会到“知识诅咒”的杀伤力——那些我们资深开发者习以为常的技术逻辑、默认掌握的行业共识,对刚接触大模型的小白而言,往往是阻碍入门的最大门槛,甚至会让人直接放弃。因此,本文特意将AI Agent学习拆解为四大核心模块,搭配可直接复用的实战案例、工程化落地方法,还补充了新手必备的工具选型建议,无论你是刚入门大模型的编程小白,还是想转型Agent开发的在岗程序员,都能找到清晰的学习方向、拿到可落地的学习路径。
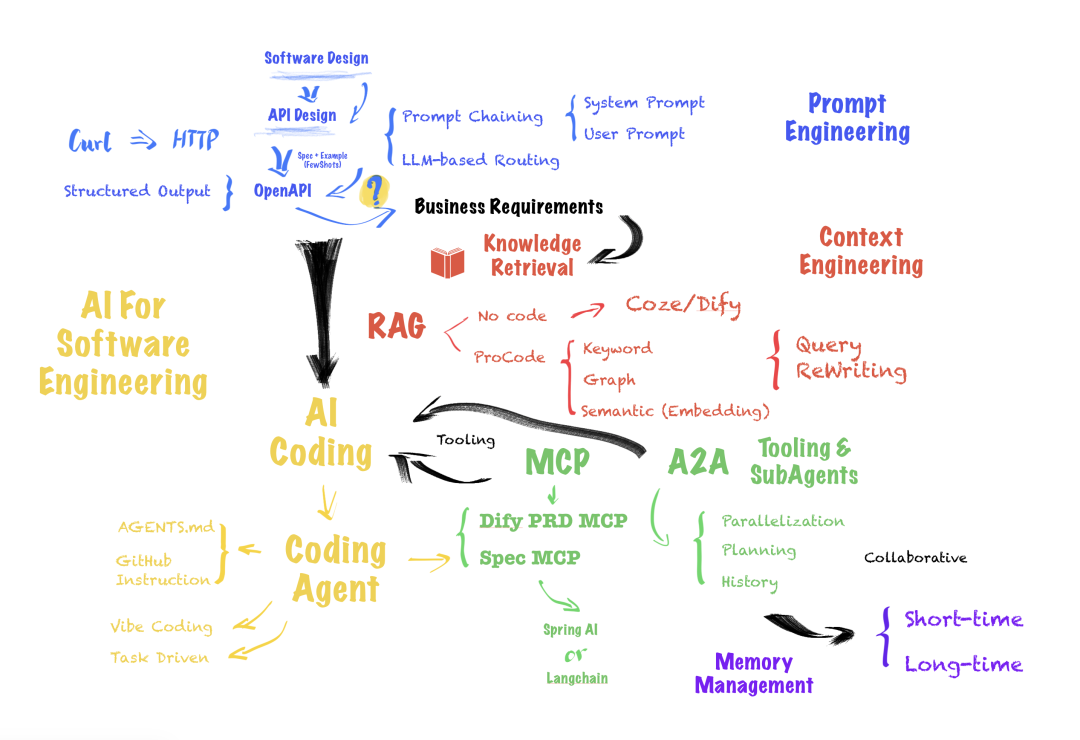
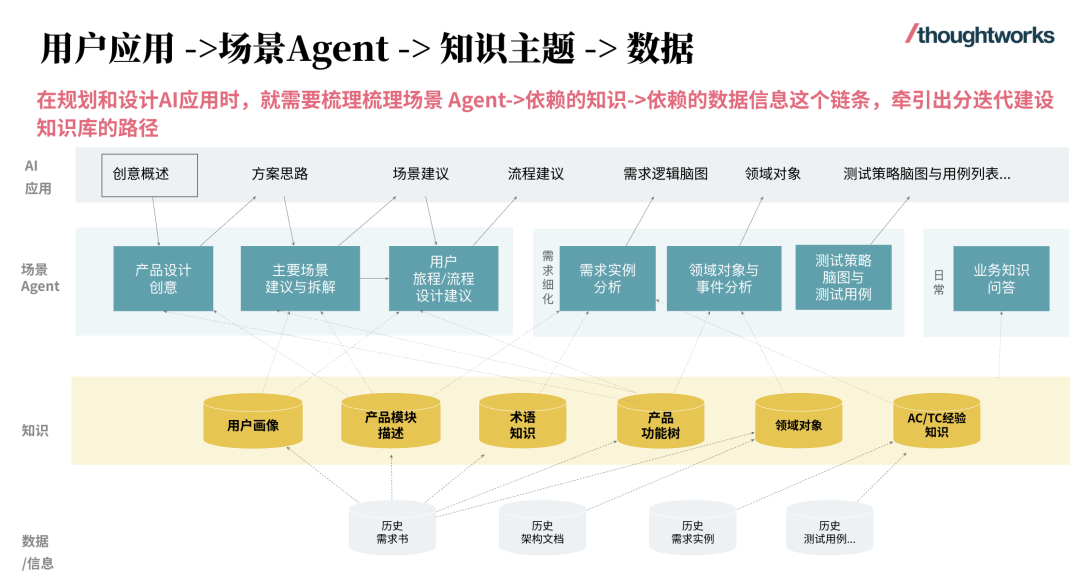
在正式拆解前,先明确AI Agent的核心学习框架,整体分为四大部分,完整覆盖从基础能力搭建到复杂系统落地的全流程,新手可按顺序逐步推进,资深开发者可针对性补弱:
- 结构化提示词工程——用工程化思维设计高效、可复用的提示词,搞定Agent的“基础沟通逻辑”,这是小白入门的第一步;
- 上下文工程与知识检索——精准筛选、科学管理上下文信息,为Agent构建“可靠知识库”,解决大模型“知识滞后”“易幻觉”的痛点;
- 工具系统工程化设计——设计可被Agent调用的工具与接口,赋予Agent“实际行动力”,让Agent能真正落地解决问题;
- Agent规划与多Agent协作——搭建清晰的任务规划链路,实现多Agent分工协同,突破单体Agent的能力上限,落地复杂自动化任务。
开始之前,先帮大家统一对AI Agent的认知(小白重点看)。目前行业内对Agent的定义五花八门,容易让人混淆,这里参考Anthropic在《Building effective agents》中给出的实战性定义,更适合开发者理解和落地:
一些客户将其定义为完全自主运行的系统,能长期独立运作并使用多种工具完成复杂任务;另一些则用它描述遵循预定义工作流程的系统。
简单来说,无需过度神化Agent:小到一个基于提示词的单一任务(比如自动生成接口文档、简单代码修复),大到一个多工具协作的复杂系统(比如智能代码审计平台、自动需求拆解系统),都可以称之为AI Agent。我们的学习也将遵循“由浅入深”的逻辑,从“单一任务Agent”逐步过渡到“复杂系统Agent”,小白不用害怕跟不上。
小贴士:建议收藏本文,学习过程中可随时对照框架查漏补缺,实战时直接参考案例和工具选型,大幅提升学习效率。
一、结构化提示词工程:Agent的“沟通基本功”,小白入门必练
虽然Context Engineering(上下文工程)现在热度很高,但对Agent开发入门而言,“写好提示词”依然是最核心、最基础的能力——提示词是Agent的“沟通语言”,语言不通,后续的一切都无从谈起。网上关于提示词的内容繁杂且杂乱无章,很多不适合新手,结合我培训新人的实战经验,把重点聚焦在三个可落地、能快速出效果的方向,搭配框架工具就能直接上手,小白也能快速掌握:
- 提示词输入与输出的结构化设计,让Agent“精准听懂、规范作答”;
- 复杂问题的提示链与模块化拆解,降低Agent的推理难度;
- 提示词路由:实现任务智能分发的核心逻辑,适配多场景需求。
1. 输入输出结构化:让Agent“精准听懂、规范作答”
在实际Agent开发中,即便大模型能辅助生成部分提示词,人工调优提示词依然是核心工作(新手重点练这个)。关键目标是让模型的输出可解析、可复用,比如直接生成JSON、XML或Java类,能无缝对接后续代码逻辑,不用再手动修改格式,提升开发效率。
提示词(Prompts)是引导AI模型生成特定输出的设计艺术与科学。通过精准的措辞和结构设计,能有效控制模型响应方向,让输出符合业务预期,这也是新手和资深开发者的核心差距之一。
以Spring AI文档中的Structured Output Converter为例,核心在于两点:格式化输入指令和标准化输出转换,新手可直接套用这个逻辑:
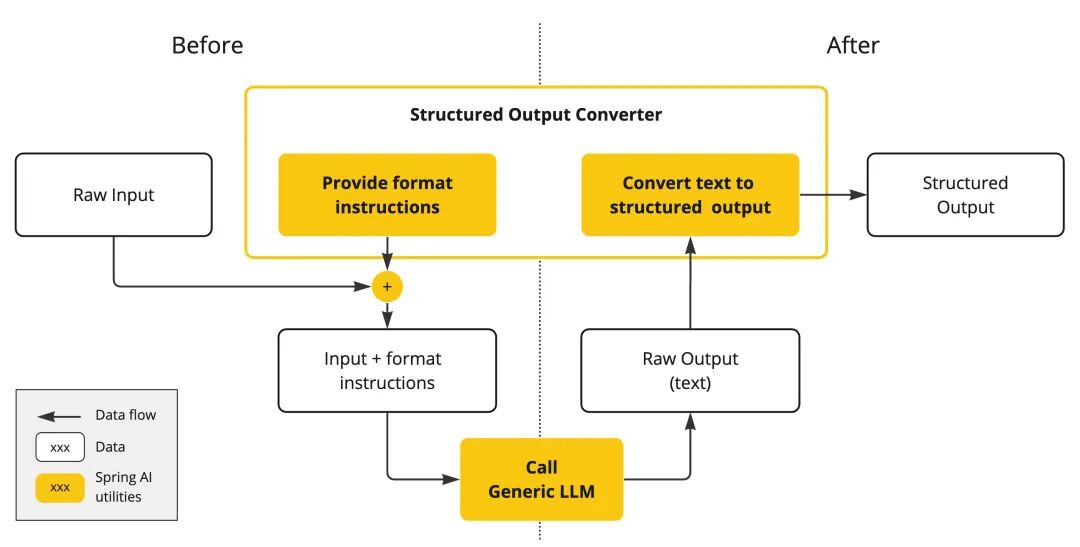
格式化输入指令:核心是用结构化模板和规则约束,让模型明确“自己的角色、要完成的任务、输出的格式要求”。具体可落地的方法有3个,新手优先掌握前2个:
- 使用动态提示词模板:比如LangChain的Jinja2、Spring AI的StringTemplate,能在运行时注入上下文、用户输入等信息,灵活构建Prompt,不用重复编写相似提示词;
- 固定文本结构:明确包含角色定位(比如“你是资深Java开发助手,擅长简单易懂地解决代码问题”)、任务描述、约束条件(比如“禁止生成冗余解释,只输出代码和关键注释”)、输出格式(比如“以JSON格式返回,包含code和note两个字段,note字段不超过50字”);
- 示例驱动(Few-shots):提供1-2个输入输出示例,能大幅提升模型输出的稳定性。比如做代码修复Agent时,先给出“错误代码+修复后代码+修复说明”的示例,模型会更精准。
输出结果转换:核心是处理模型输出,确保符合业务系统要求,同时做好异常兜底(避免模型输出不符合预期时无从下手)。具体包括3点:
- 选对输出格式:JSON适合序列化传输,适配代码交互场景;YAML适合流式处理(传输成本更低);Markdown适合需要可视化展示的场景(比如文档生成);
- 做好解析验证:从模型输出的纯文本中提取代码块,进行反序列化和对象映射,同时用JSON Schema、XSD等工具验证结构合法性,避免格式错误;
- 异常场景处理:针对模型输出缺失字段、类型错误等问题,提前定义默认值或回退策略,比如字段缺失时触发模型重试生成,或直接返回预设的错误提示。
进阶技巧(适合有基础的程序员):如果某类任务的提示词调优效果较好,可基于现有数据微调模型,进一步提升输出稳定性,减少人工调优成本。
2. 提示词路由:让Agent“智能分工”处理复杂任务
复杂AI Agent系统中,单一提示词无法覆盖所有任务——比如一个代码助手Agent,既要处理基础语法问题,也要处理复杂的性能优化、架构设计问题,还可能遇到非技术类问题,这就需要“提示词路由”来实现任务分发,让不同的任务匹配最合适的提示词,提升响应精度。
https://www.ibm.com/think/topics/prompt-chaining
提示词路由(Prompt Routing)是在多任务、多Agent场景中,通过分析输入和上下文,将任务智能分配给最合适的模型或子任务提示词的工程化模式,核心是“精准匹配、高效响应”。
核心逻辑是“先判断任务类型,再匹配处理方案”。以代码助手Agent的QA场景为例,可设计这样的路由规则(新手可直接参考复用):
- 非技术类问题(比如“你好”“今天天气怎么样”)→ 直接返回“不支持该类型查询,请输入技术相关问题”;
- 基础语法问题(比如“Java循环怎么写”“Python列表去重方法”)→ 调用文档检索+基础QA提示词,优先返回简洁答案和示例代码;
- 性能优化问题(比如“这段代码运行很慢,怎么优化”)→ 调用代码分析工具+专家级提示词,拆解优化点并给出修改方案;
- 架构设计问题(比如“如何设计一个用户登录Agent系统”)→ 触发多Agent协作(需求分析Agent+架构设计Agent),分步输出设计方案。
落地工具:新手优先用LangChain的RouterChain,可直接实现基础路由功能,无需从零开发;有基础的程序员可基于语义相似度(Routing by semantic similarity)自定义路由规则,适配更复杂的场景。
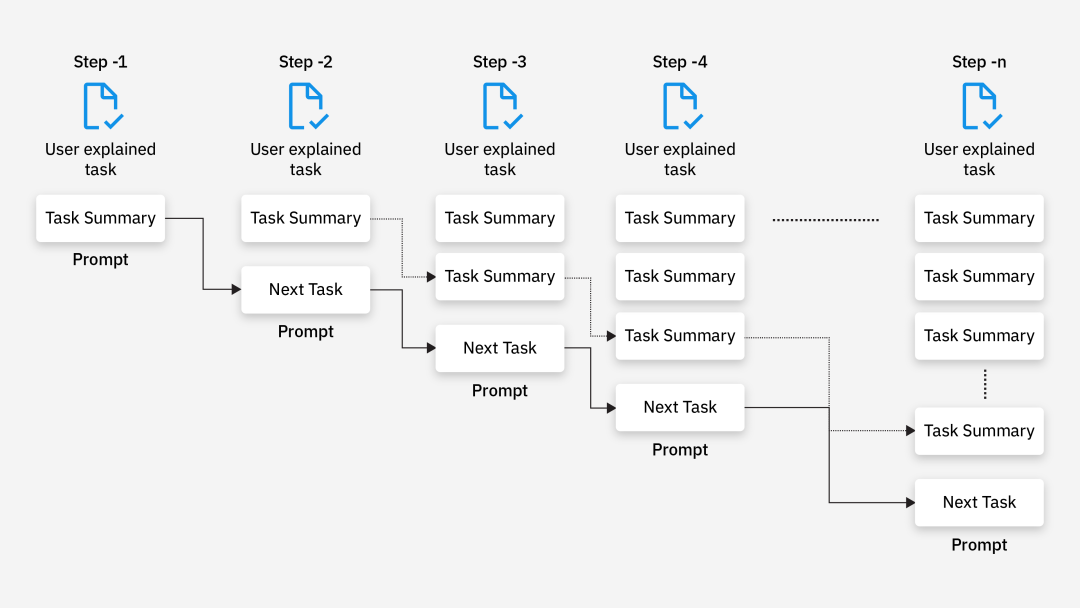
3. 提示链与模块化:拆解复杂任务的“万能方法”
基于提示词路由,复杂任务可通过“提示链(Prompt Chaining)”拆解为多个子任务,每个子任务对应独立的提示词或模型调用,最终整合结果——这种方式特别适合有固定流程、可分步执行的任务,能大幅降低开发难度,新手也能落地复杂任务。
https://arxiv.org/pdf/2308.11432
模块化的优势很明显:每个子任务专注单一目标,可单独修改、替换提示词,不用改动整个系统,还能根据前一步输出动态调整后续逻辑,便于调试和维护。以“将产品经理的创意转化为需求文档”为例,可拆解为这样的提示链(新手可直接套用这个拆解逻辑):
- 创意收集:提取产品创意核心诉求(可用带搜索功能的Agent实现,新手可先用Dify等低代码工具快速搭建);
- 需求梳理:理顺功能逻辑和优先级(可用Dify、Copilot 365等工具辅助,减少手动梳理成本);
- 预排期:生成初步任务列表和时间规划,明确每个需求的落地节点;
- 需求定稿:输出正式需求文档(可对接文档生成工具,自动格式化文档,无需手动排版)。
二、上下文工程与知识检索:Agent的“记忆库”构建,解决核心痛点
上下文本质是提示词的延伸,决定了Agent对“历史信息”和“外部知识”的掌握程度——Agent能否记住之前的对话、能否获取最新的外部知识,全靠上下文工程。构建带上下文的Agent,主要有两种落地方案,适配不同阶段需求,新手和资深开发者可按需选择:
- NoCode方案(小白/快速验证):用Dify、N8N、Coze等低代码平台,通过UI配置预定义RAG管道和检索策略,无需大量编码,新手1-2天就能搭建基础版本;
- ProCode方案(进阶/定制化):用LangChain、Spring AI等框架自定义检索流程,比如实现多阶段HyDE+混合检索+重排序管道,适配复杂业务场景。
先明确Anthropic在《Effective context engineering for AI agents》中给出的定义,帮大家建立正确认知(避免理解偏差):
上下文工程是一门将不断变化的信息宇宙中最相关内容,精心筛选并放入有限上下文窗口的艺术与科学。
1. 上下文窗口:有限空间里的“信息优先级”
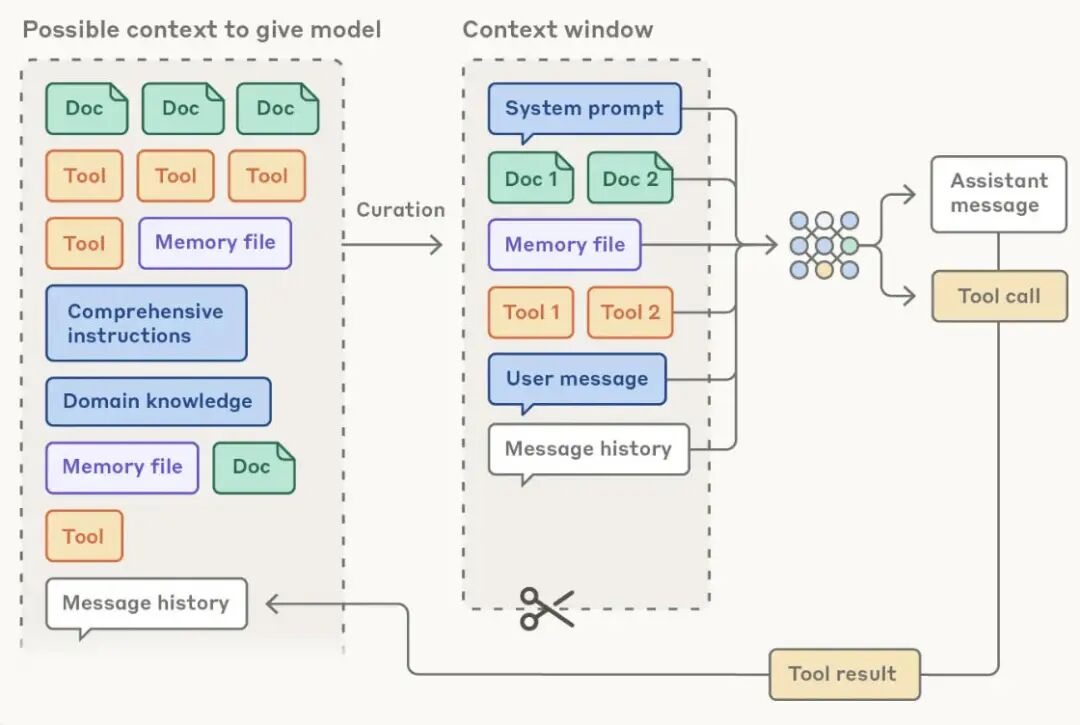
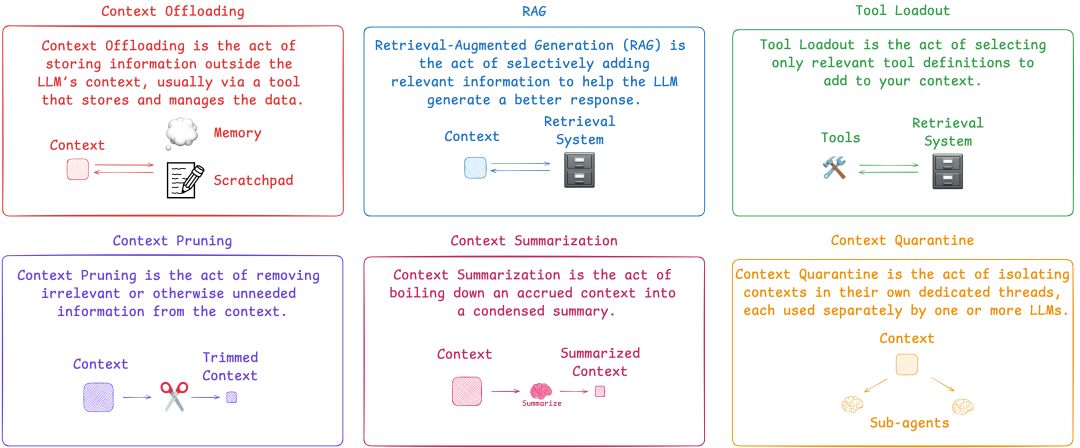
核心目标是在有限的上下文窗口中,筛选最关键的信息,提升模型推理效率——大模型的上下文窗口是有限的(比如GPT-4 Turbo的上下文窗口虽大,但也有上限),无关信息过多会导致模型分心,影响响应精度。Langchain整理的6种常见上下文工程技术,新手可直接参考:
一个完整的上下文窗口(即最终传给模型的Prompts),通常包含三部分,新手需明确每部分的作用:
- 系统提示词部分:含角色定义(“你是谁”)、任务指令(“你要做什么”)、输出格式要求,是Agent的基础行为准则,决定了Agent的核心定位;
- 函数调用部分:含可用工具定义、工具调用后的响应结果,赋予Agent与外部交互的能力,让Agent能调用工具完成任务;
- 动态上下文部分:含短期记忆(当前会话信息)、长期记忆(历史会话信息)、外部知识(通过RAG检索的信息)、全局状态(任务临时存储),是Agent的“记忆核心”。
其中,外部知识获取和记忆系统设计是影响上下文质量的关键,也是上下文工程的核心重点,后面会重点拆解。
2. 检索增强生成(RAG):为Agent补充“外部知识库”
RAG是构建Agent的核心技术,也是新手必须掌握的重点——通过从外部知识库检索相关信息,弥补大模型“知识滞后”(比如大模型无法获取最新的技术文档)和“易幻觉”(生成虚假信息)的问题。在代码库问答、文档解读等复杂场景,单一检索策略不够精准,需组合多种方式提升效果。
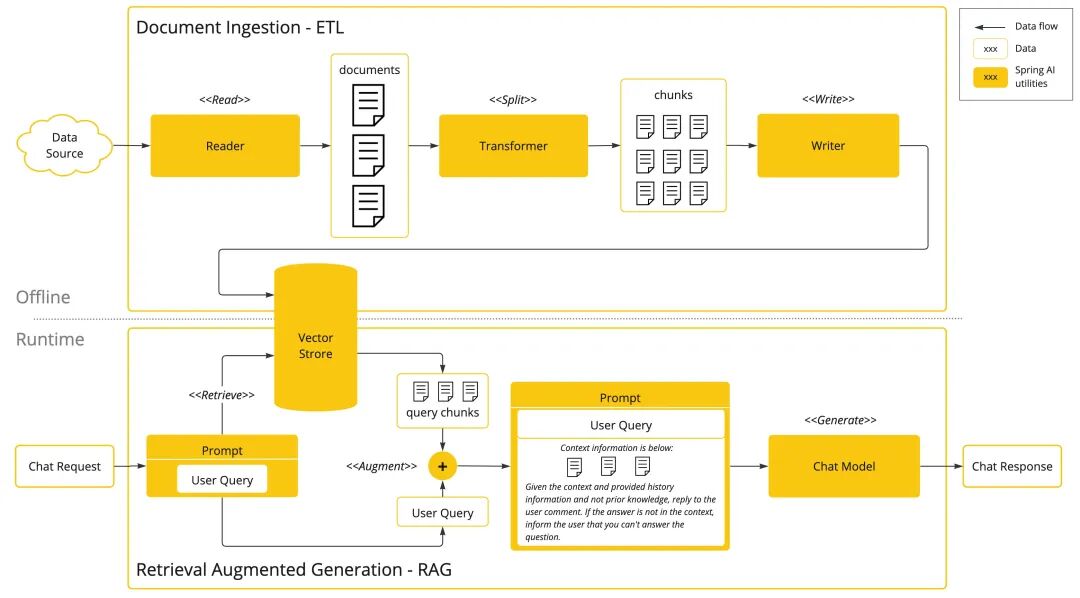
RAG(检索增强生成,Retrieval-Augmented Generation)通过从外部知识库中检索相关信息来增强大语言模型的生成能力。在代码库问答等复杂场景中,单纯的向量检索往往不够精准,需要组合多种检索策略来提升准确率。
按实现复杂度,检索策略可分为三类,可根据场景组合使用,新手先掌握前两种:
- 关键词检索:基础且精准,适合匹配特定术语场景(如代码中的函数名、类名、技术关键词)。常见实现:Elasticsearch、Solr等搜索引擎(用BM25、TF-IDF算法),或ripgrep、grep等正则匹配工具(Cursor就用了ripgrep+向量检索的混合方式,新手可参考);
- 语义检索:理解查询语义,适合自然语言查询场景(比如“如何用Python实现Agent的基础功能”)。实现步骤:用OpenAI text-embedding-3-large、Jina embeddings v3等模型将文本转为向量,再通过余弦相似度、点积计算查询与文档的相关性;
- 图检索:关注内容间的关系依赖,适合代码分析、知识图谱场景。代码场景下可构建调用关系图、依赖关系图,通过AST(抽象语法树)提取结构信息,代表工具如微软GraphRAG、Aider的repomap、Joern、CodeQL(适合有基础的程序员)。
前置优化(新手必做):检索前需做“查询改写(Query Rewriting)”,将用户模糊需求转化为精准查询(比如用户说“Agent怎么落地”,改写为“AI Agent从零落地的步骤和工具选型”),解决自然语言与知识库数据的“阻抗不匹配”问题,提升检索精度。
代码场景RAG实战示例(LanceDB官方方案,新手可参考)
代码库RAG需结合多种检索策略,LanceDB的实现方案很有参考价值,新手可借鉴其思路,不用完全照搬:
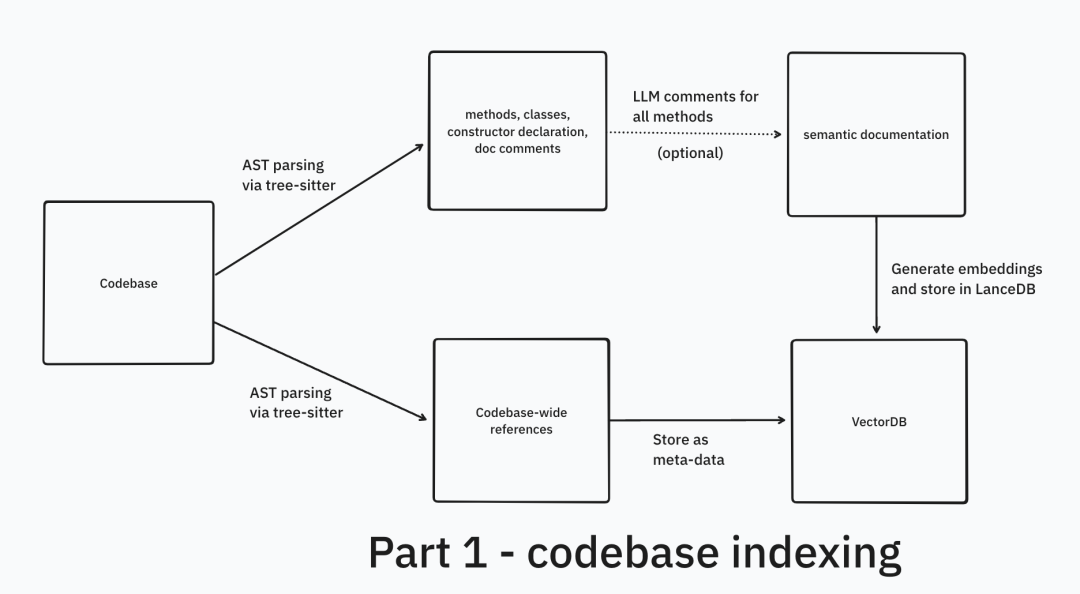
核心亮点(新手重点关注):
- 索引阶段:用TreeSitter生成代码知识,同时通过微调后的LLM提取代码元特征(生成文本描述后再做向量嵌入),提升检索精准度;
- 检索阶段:组合HyDE(生成假设性代码片段再检索)、BM25(关键词精准匹配)、混合检索(融合语义与关键词)、重排序(交叉注意力优化结果顺序),兼顾精准度和全面性。
3. 上下文窗口工程化:参考GitHub Copilot的设计思路
两年前GitHub Copilot的上下文系统,至今仍是业内标杆,其核心设计思路可直接复用——无论是新手搭建基础Agent,还是资深开发者优化上下文系统,都有很高的参考价值:
- 持续信号监控:实时捕捉IDE中的编辑信号(如光标移动、文件切换、字符插入/删除),动态调整上下文优先级,确保Agent能关注到用户当前的操作;
- 上下文优先级排序:按“光标周围代码(最高)→ 当前文件其余部分(高)→ 打开的其他文件(中)→ 辅助信息(文件路径、导入语句等,低)”排序,合理利用上下文窗口;
- Token预算感知:实时估算上下文Token占用,接近限制时自动裁剪低优先级内容,确保不超限,避免模型无法响应。
落地简化方案(新手重点看):对中小规模Agent,无需复杂开发,可采用“新鲜度优先”(最近编辑内容权重高)、“滑窗增量更新”(仅更新变化部分,减少Token占用)、“持久化记忆”(用AGENTS.md存储跨会话关键信息)等策略,平衡效果与复杂度,快速落地。
4. Agentic检索:让Agent自主优化检索策略
Agentic检索是更高级的检索模式,让Agent自主判断检索工具、调整检索参数,确保上下文足够精准——这种模式在Cursor、Claude Code等AI编码工具中已广泛应用,也是资深开发者提升Agent能力的关键。
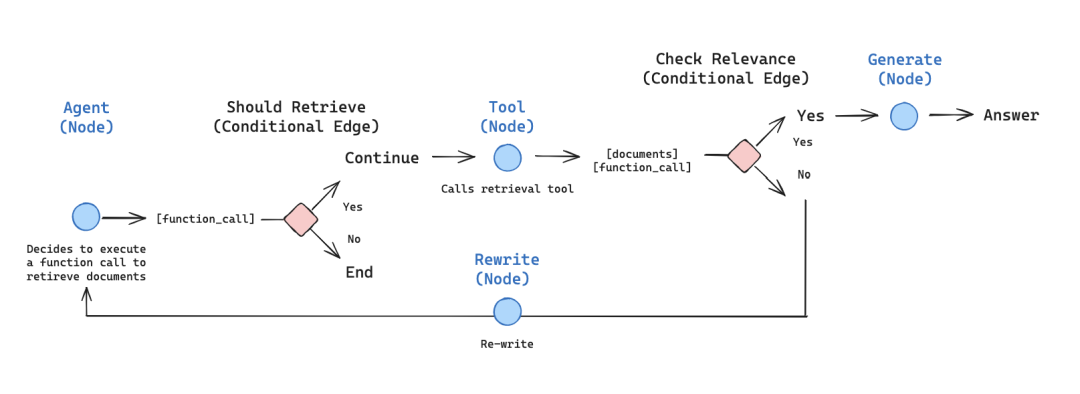
https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_agentic_rag/
Agentic指AI系统具备自主感知、动态决策与目标导向执行能力,能在任务过程中主动优化上下文、生成检索策略并持续自我迭代,不用人工干预。
实战案例:Cursor会先通过“file+ripgrep”检索代码,若结果不足(比如未找到相关函数),再调用向量检索或Git历史检索,补充上下文;Google DeepResearch Agent则通过“任务拆分→检索探索→信息整合”的流程完成研究任务,自主优化检索方向。
DeepResearch Agent实战框架(进阶参考)
Langchain AI构建的Open DeepResearch示例,展示了系统化的Agentic检索方法,有基础的程序员可参考落地:
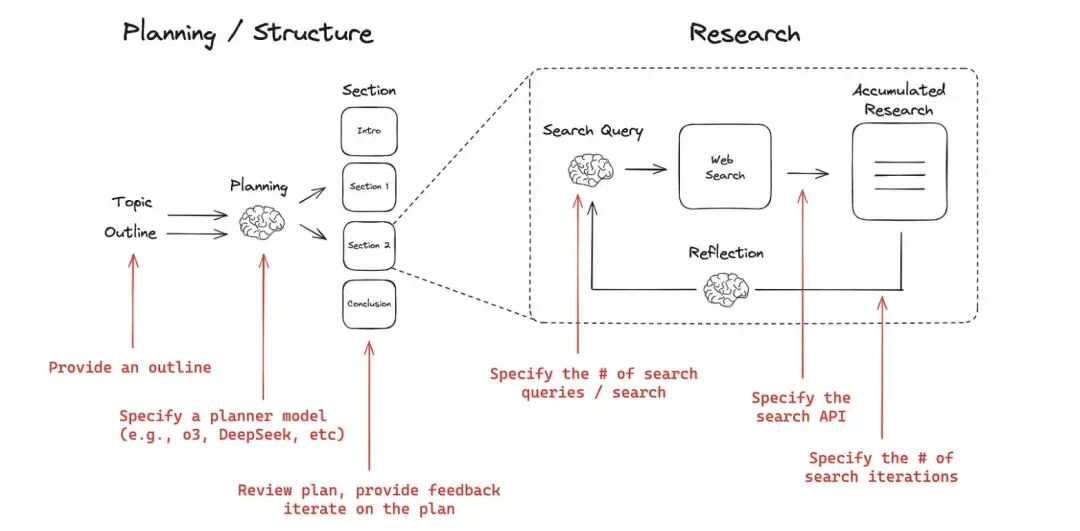
- 任务拆分:Manager Agent负责理解任务、拆分子任务、设计检索策略,明确每个子任务的检索目标;
- 执行检索:Execution Agent负责搜索、文档抓取、内容解析,获取所需信息;
- 状态维护:实时跟踪已覆盖子问题和信息缺口,动态调整探索方向,避免遗漏关键信息;
- 结果整合:生成结构化报告并附来源引用,可插入用户审查环节提升精度,确保信息准确。
三、Agent工具系统工程化设计:赋予Agent“行动力”,从理论到落地
工具系统是Agent与外部世界交互的核心,直接决定Agent的能力边界——Agent之所以能解决实际问题,核心是能调用各类工具。这里的工具可以是任何API、函数或服务(如数据库查询、邮件发送、代码执行、文件读取等)。LlamaIndex的工具封装思路很直观,适合新手参考,可分为两类:
- FunctionTool:将Python函数封装为Agent可用工具,新手可先从简单的Python函数封装入手;
- QueryEngineTool:将数据查询引擎(如向量索引)转为工具,支持Agent查询推理,适配知识库场景。
1. 语义化工具:让模型“看懂并会用”的函数接口
工具本质是“模型可理解的语义化函数”——不仅要包含核心执行逻辑,还需包含让模型识别的元信息(模型靠这些元信息判断是否调用该工具、如何调用),新手封装工具时,必须包含以下3个元信息:
- 名称(name):唯一标识符,简洁明了,如getWeather、searchCode、readFile,避免歧义;
- 描述(description):核心元信息,用自然语言说明工具功能、适用场景(模型靠这段文字判断是否调用),可视为“面向AI的微提示词”,描述越精准,模型调用越准确;
- 参数(parameters):定义输入参数的名称、类型、是否必填,如searchFlights(origin: str, destination: str, date: str),明确参数要求,避免模型传入错误参数。
工具调用的两种核心范式,新手可按需选择:
- ReAct框架(Reasoning + Acting):让模型交替生成“思考轨迹”和“行动指令”,形成“思考-行动-观察”的闭环,适合需要多步推理的任务(比如复杂代码分析);
- 直接函数调用(Direct Function Calling):模型单步推理后,输出结构化JSON,明确指定要调用的工具和参数,适合流程明确的简单任务(比如读取文件、查询天气)。
选择建议:根据模型支持情况和业务场景,ReAct适合需要多步推理的任务,直接调用适合流程明确的简单任务;新手优先从直接函数调用入手,难度更低,更容易出效果。
2. 工具设计四大原则(落地必看,新手重点记)
无论是编码Agent还是其他领域Agent,工具设计都应遵循以下四大原则,确保可用性、可复用性和可扩展性,避免后期返工:
- 语义清晰:名称、描述、参数命名无歧义,description可视为“面向AI的微提示词”,让模型一眼看懂用途;
- 无状态客观:仅封装技术逻辑,不做主观决策,便于复用和调试——比如“搜索航班”工具,只返回航班信息,不判断哪个航班更好;
- 原子性单一职责:每个工具只做一件事,如“搜索航班”和“预订航班”应拆分为两个工具,避免工具功能过于复杂,难以调试;
- 最小权限:仅授予完成任务必需的权限,如读取代码的工具不授予写入权限,降低安全风险。
工具编排的两种实用模式
基于上述原则,工具编排可分为两种模式,适配不同场景,新手可直接参考落地:
- Workflow式编排(任务链式):适合流程稳定、有依赖关系的任务。比如“规划北京旅行”可拆分为:searchFlights(查航班)→ searchHotels(查酒店)→ getLocalEvents(查景点)→ bookTicket(订票)。可通过DAG可视化建模,落地工具如N8N、Airflow,新手优先用N8N,操作更简单;
- 分类式调用(动态决策):适合动态场景,如代码助手Agent。参考GitHub Copilot的架构,通过“意图分类器”判断用户需求,再调用对应工具(如read_file读取文件、semantic_search语义搜索、run_in_terminal执行代码),灵活适配不同需求。
3. MCP协议:构建可组合的工具网络
当工具和Agent数量增多时,需要标准化协议实现工具的动态注册和跨Agent调用,MCP(Model Context Protocol)就是为此设计的通用协议层——核心价值是解决“工具碎片化”“Agent无法共享工具”的问题,适合中大规模Agent系统。
核心价值:
- 标准化:统一工具调用格式,不同Agent可共享工具集,不用重复开发;
- 动态化:运行时可注册、选择工具,适配多变的任务需求;
- 可组合:Agent和工具可像搭积木一样组合,落地复杂任务。
简化落地(新手重点看):中小规模系统可不用直接引入MCP,参考AutoDev的实现思路——将Agent以MCP工具形式暴露,在不增加复杂度的前提下实现Agent协作,降低开发难度。
四、Agent规划与多Agent协作:从“单体”到“团队”,突破能力上限
Google Cloud对Agent的定义很精准:“Agent是使用AI实现目标并代表用户完成任务的软件系统,具备推理、规划、记忆能力,能自主学习和适应”。前面我们已覆盖“推理(提示词)、感知(上下文/检索)、行动(工具)”三大核心能力,这一部分聚焦“规划”和“协作”,实现Agent能力的跃升——从“单一功能单体Agent”升级为“多能力团队Agent”,落地更复杂的任务。
1. 模块化系统提示词:Agent的“思维蓝图”
系统提示词(System Prompt)是Agent的核心“操作系统”,而非简单的指令集——优秀的系统提示词能让Agent具备清晰的思维逻辑,避免行为混乱。参考Cursor、Claude Code的实践,系统提示词需模块化设计,可分为以下层次(新手可直接套用这个结构):
- 角色与通信层:明确Agent身份(如“资深Python开发助手,擅长简单易懂地解决新手代码问题”)和交流规范(如“用自然语言总结问题,代码用backticks标注,注释简洁明了”);
- 工具与任务层:定义可用工具、工具优先级(优先专用工具)、任务管理规则(复杂任务用TODO标记进度),让Agent明确“能做什么、怎么做”;
- 安全与权限层:默认最小权限,危险操作(如修改master分支、删除文件)需显式授权,定义错误处理机制(如工具调用失败时如何提示用户);
- 上下文层:明确上下文定位规则(如代码修改需指定前后3-5行)、动态更新策略,确保Agent能精准获取所需记忆。
设计技巧:用Markdown或XML标记语言组织提示词,提升模型对复杂规则的理解能力,同时便于维护和动态加载——新手可先用Markdown,格式更简洁,容易上手。
2. 任务规划:让Agent“拆解目标”的核心策略
单体Agent的智能上限,取决于其规划能力——能否将模糊目标拆解为可执行的子任务。核心策略有两种,适配不同场景,新手可按需选择:
- 预先分解(静态规划):任务开始前,完整拆解为子任务序列。比如BabyAGI的架构,通过task_creation_agent(生成任务)、execution_agent(执行任务)、prioritization_agent(排序任务)形成闭环,适合流程固定、目标明确的任务(如“生成用户登录接口文档”);
- 交错分解(动态规划):执行过程中动态决定下一个子任务,适合需求模糊、需实时调整的场景(如“优化一段未知问题的代码”)。比如Claude Code的todo_spec机制,Agent根据当前执行结果动态补充子任务,逐步逼近目标。
规划原则(新手重点记):子任务需原子化、行动导向,避免琐碎步骤(如不拆“读取a.txt”,而是拆“分析a.txt中的代码性能问题”),同时控制子任务数量,优先“少而精”——过多的子任务会增加Agent的推理负担,影响效率。
3. 多Agent协作:从“个体”到“团队”的工程化方向
单体Agent能力有限,多Agent系统(Multi-Agent System, MAS)是落地复杂任务的必然选择——类似“微服务拆分单体应用”的思路,通过职责拆分实现能力扩展,让不同Agent各司其职、协同完成复杂任务。常见的协作拓扑(参考LangGraph、AutoGen),新手可先掌握前两种:
- 主管-专家模式(层级结构):主管Agent拆解任务,分派给不同专家Agent(如前端专家、后端专家、测试专家),适合分工明确的场景(如“搭建一个完整的Agent系统”);
- 并行模式(群体智能):多个Agent同时执行同一任务的不同部分,汇总结果,适合提升效率的场景(如多文件并行代码审计、大规模文档解读);
- 顺序模式(流水线):Agent按预定义顺序协作,前一个的输出作为后一个的输入,适合流程固定的场景(如需求→开发→测试流水线);
- 网络模式(动态对话):Agent自由通信,无固定层级,根据任务进展动态决定协作方,适合复杂多变的场景(如智能研究、创意生成)。
A2A协议:Agent间的“通用通信语言”
当Agent数量增多时,需要标准化协议实现Agent间的高效通信,A2A(Agent-to-Agent)协议就是为此设计的,与工具调用的MCP协议互补,实现不同Agent系统的互操作。
简化落地(新手重点看):中小规模系统可不用直接引入A2A,参考AutoDev的实现思路——将Agent以MCP工具形式暴露,在不增加复杂度的前提下实现Agent协作,降低开发难度,快速落地多Agent场景。
4. 自我完善:Agent的“持续进化”能力
高级Agent的核心竞争力是“自我进化”——不用人工持续优化,就能通过经验积累提升能力,这依赖“反思-记忆-评价”的闭环,适合有基础的程序员落地:
- 反思机制:Agent回顾历史执行结果,识别错误并生成改进建议(如“上次代码修复遗漏了边界条件,下次需增加异常检测”);
- 记忆系统:持久化存储任务经验、上下文信息(如用Knowledge Graph、AGENTS.md),并通过加权检索(按新近度、相关性排序)为后续任务提供参考;
- 评价闭环:建立任务效果评价标准,根据评价结果优化提示词、规划策略和工具选择,形成“执行-评价-优化”的良性循环。
先进Agent架构的最终目标,是创建自我强化的飞轮:行动产生经验,反思提炼知识,记忆存储知识以改进未来行动,让Agent从静态程序转变为动态学习实体。
小结:Agent开发的核心认知+学习建议(小白/程序员必看)
系统提示词和上下文工程,是Agent开发的基础核心——开发者需要以“系统架构设计”的高度,对待提示词的模块化构建和上下文的精准管理,用标记语言组织指令,通过角色激活、行为规范、动态数据加载等技术,为Agent塑造稳定的“认知环境”,才能确保其行为可预测、可落地。
本文的四大学习路径,从基础的提示词工程,到进阶的上下文检索、工具设计,再到高级的规划与协作,形成了完整的Agent开发知识体系——建议收藏本文,小白可按“基础→进阶→高级”的顺序逐步实践,先从提示词、低代码工具入手,快速出效果,建立学习信心;程序员可针对性补弱,结合具体项目打磨技术,突破能力瓶颈,快速掌握AI Agent开发能力,抓住AI时代的技术红利。
最后提醒:AI Agent学习的核心是“理论+实战”,光看不动手很难掌握,建议每学习一个模块,就落地一个简单的小案例(比如小白先实现一个“自动生成代码注释”的单一Agent),逐步积累经验,慢慢就能落地复杂的Agent系统。
那么,如何系统的去学习大模型LLM?
到2026年,大型语言模型将不再是“实验性工具”,而将成为核心基础设施。 过去三年,大型语言模型(LLM)已从研究实验室走向生产系统,为客户支持、搜索、分析、编码助手、医疗保健工作流程、金融和教育等领域提供支持。但在这股热潮背后,一些重要的事情正在发生:
企业不再招聘“人工智能爱好者”,而是招聘大语言模型LLM工程师。在2026年迅速成为排名前五的科技职业之一。

我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
为了让大家不浪费时间踩坑!2026 年最新 AI 大模型全套学习资料已整理完毕,不管你是想入门的小白,还是想转型的传统程序员,这份资料都能帮你少走 90% 的弯路
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇

大模型资料包分享

1、 AI大模型学习路线图(含视频解说)

2、从入门到精通的全套视频教程

3、学习电子书籍和技术文档

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、各大厂大模型面试题目详解

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群


👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献345条内容
已为社区贡献345条内容

所有评论(0)