华为Atlas 900 A3 SuperPoD 超节点网络架构
·
Atlas 900 A3 SuperPoD 超节点网络架构详细分析
📚 目录
🎯 一句话理解
Atlas 900 A3 = 384个AI计算节点 + 华为自研高速网络 + 7层并行通信
详细细节见官网https://support.huawei.com/enterprise/zh/ascend-computing/atlas-900-a3-superpod-pid-261207247?category=operation-maintenance&subcategory=user-guide
📊 架构简化图
┌─────────────────────────────────────────┐
│ L2层:56台总线设备(高速公路收费站) │
│ 负责:节点之间的通信 │
└─────────────────────────────────────────┘
↕ 光纤/铜缆
┌─────────────────────────────────────────┐
│ 超节点总线(城市主干道) │
│ 负责:汇聚和转发 │
└─────────────────────────────────────────┘
↕
┌─────────────────────────────────────────┐
│ L1层:48个计算节点(48栋大楼) │
│ ┌──────────┐ ┌──────────┐ │
│ │ 节点1 │ │ 节点48 │ │
│ │ ┌──────┐ │ │ ┌──────┐ │ │
│ │ │L1交换│ │ │ │L1交换│ │ │
│ │ │7个芯片│ │ │ │7个芯片│ │ │
│ │ └──────┘ │ │ └──────┘ │ │
│ │ CPU CPU │ │ CPU CPU │ │
│ │ NPU×8 │ │ NPU×8 │ │
│ └──────────┘ └──────────┘ │
└─────────────────────────────────────────┘
架构概述
什么是Atlas 900 A3 SuperPoD?
Atlas 900 A3 SuperPoD 是华为推出的AI训练集群解决方案,可以理解为:
- 超级计算机集群:由多个计算节点组成的大型AI训练系统
- 高性能网络:使用华为自研的灵衢网络实现超低延迟通信
- 可扩展架构:支持64/96/192/384超节点等多种配置
为什么需要这种复杂架构?
在AI训练中,需要:
- 大量计算节点:384个节点同时工作
- 高速通信:节点之间需要频繁交换数据(模型参数、梯度等)
- 低延迟:延迟越低,训练速度越快
- 大带宽:需要足够的带宽传输大量数据
类比理解:
- 就像384个工人同时建造一栋大楼
- 工人之间需要频繁沟通和传递材料
- 沟通越快、通道越宽,建造速度越快
核心概念解释
1. 灵衢网络(LingQu Network)
什么是灵衢网络?
- 华为自研的高速互联网络技术
- 专门为AI训练集群设计
- 提供超低延迟、高带宽的通信能力
类比:
- 普通网络 = 普通公路(有红绿灯、限速)
- 灵衢网络 = 高速公路(专用通道、无红绿灯、高速通行)
2. LQC协议(灵衢总线协议)
什么是LQC?
- LQC = LingQu Cache-coherent(灵衢缓存一致性)
- 是一种处理器内部总线的向外延伸
- 支持多个芯片的紧耦合、极致低时延互联
关键特点:
- 缓存一致性:多个芯片可以共享内存,就像它们在一个芯片内部一样
- 低延迟:延迟极低,接近芯片内部通信
- 高带宽:支持大容量数据传输
类比理解:
- 普通网络 = 两个房间的人通过电话沟通(有延迟)
- LQC协议 = 两个人在同一个房间面对面沟通(几乎无延迟)
3. 平面组网(Plane Networking)
什么是平面?
- 将网络分成7个独立的通信平面
- 每个平面可以独立工作
- 7个平面并行工作,获得更大带宽
为什么是7个平面?
- 带宽叠加:7个平面 = 7倍带宽
- 冗余容错:一个平面故障,其他平面仍可工作
- 负载均衡:数据可以分散到不同平面传输
类比理解:
- 单平面 = 一条车道
- 7平面 = 7条并行车道
- 7条车道同时通车,总通行能力是单条车道的7倍
4. L1层和L2层
L1层(第一层交换)
- 位置:在每个计算节点内部
- 作用:节点内部的CPU、NPU之间的通信
- 设备:灵衢总线板(集成在计算节点内)
类比:
- L1层 = 大楼内部的电梯和走廊(节点内部通信)
L2层(第二层交换)
- 位置:总线设备柜中(独立机柜)
- 作用:不同计算节点之间的通信
- 设备:灵衢总线设备(LingQu 630 V1交换机)
类比:
- L2层 = 城市之间的高速公路(节点间通信)
超节点总线(Super Node Bus)
- 位置:连接L1和L2的中间层
- 作用:汇聚L1的流量,转发到L2
类比:
- 超节点总线 = 城市的主干道(连接内部道路和高速公路)
分层架构详解
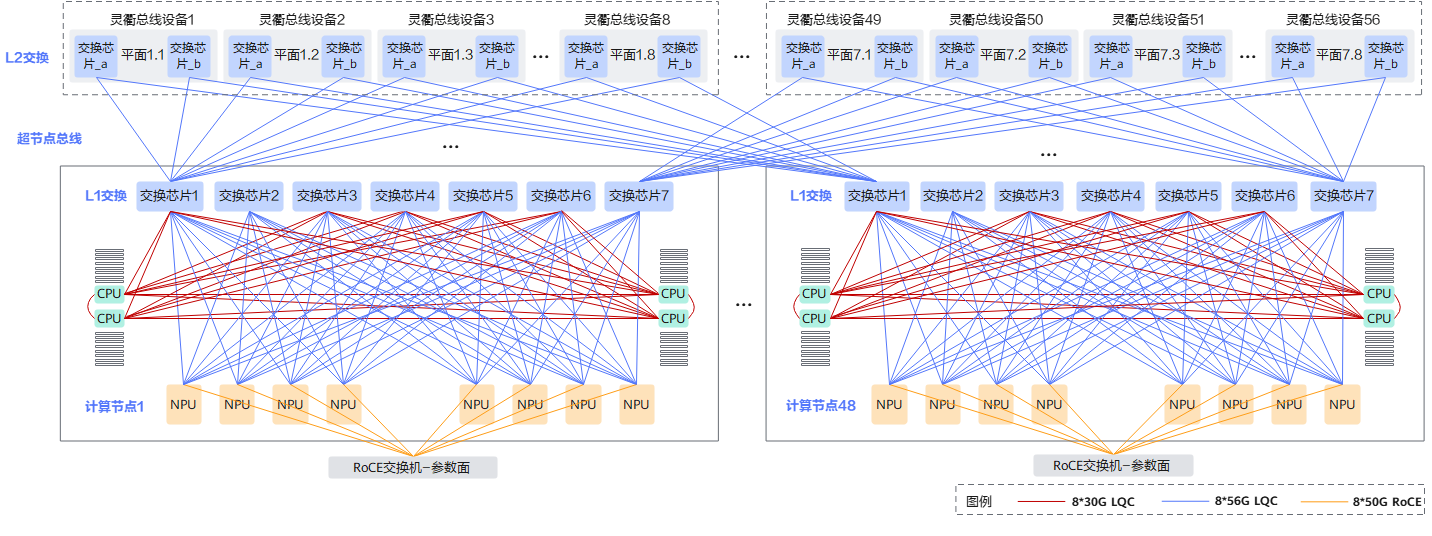
整体架构图(从下往上)
┌─────────────────────────────────────────────────┐
│ L2层:灵衢总线设备(56台) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 总线设备1 │ │ 总线设备2 │ │ ...设备56│ │
│ │ 交换芯片a │ │ 交换芯片a │ │ │ │
│ │ 交换芯片b │ │ 交换芯片b │ │ │ │
│ │ 平面1.1 │ │ 平面1.2 │ │ 平面7.8 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────┘
↕ 光纤/铜缆
┌─────────────────────────────────────────────────┐
│ 超节点总线(Super Node Bus) │
│ (汇聚和转发层) │
└─────────────────────────────────────────────────┘
↕
┌─────────────────────────────────────────────────┐
│ L1层:计算节点内部交换(48个节点) │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ 计算节点1 │ │ 计算节点48 │ │
│ │ ┌──────────┐│ │ ┌──────────┐│ │
│ │ │L1交换层 ││ │ │L1交换层 ││ │
│ │ │交换芯片1 ││ │ │交换芯片1 ││ │
│ │ │交换芯片2 ││ │ │交换芯片2 ││ │
│ │ │ ... ││ │ │ ... ││ │
│ │ │交换芯片7 ││ │ │交换芯片7 ││ │
│ │ └──────────┘│ │ └──────────┘│ │
│ │ │ │ │ │
│ │ CPU CPU │ │ CPU CPU │ │
│ │ │ │ │ │
│ │ NPU NPU ... │ │ NPU NPU ... │ │
│ │ (8个NPU) │ │ (8个NPU) │ │
│ │ │ │ │ │
│ │ RoCE交换机 │ │ RoCE交换机 │ │
│ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────┘
L2层详细结构
灵衢总线设备(LingQu 630 V1)
- 数量:56台(384超节点配置)
- 每台设备包含:
- 2个交换芯片(交换芯片_a 和 交换芯片_b)
- 对应2个平面(如平面1.1和平面1.2)
- 总平面数:56台 × 2 = 112个平面接口
- 实际使用:7个平面组网(每个平面使用多个接口)
平面分配示例:
总线设备1 → 平面1.1, 平面1.2
总线设备2 → 平面1.3, 平面1.4
...
总线设备8 → 平面2.1, 平面2.2
...
总线设备56 → 平面7.7, 平面7.8
为什么是56台?
- 384超节点需要足够的交换容量
- 56台设备提供足够的端口和带宽
- 支持全互联组网(每个节点都能直接通信)
L1层详细结构
每个计算节点的L1交换层
- 交换芯片数量:7个(交换芯片1到交换芯片7)
- 对应关系:每个交换芯片对应L2层的一个平面
- 连接方式:
- 向上:连接到超节点总线(8×56G LQC)
- 向下:连接到CPU和NPU(8×30G LQC 和 8×56G LQC)
L1交换芯片的作用:
- 汇聚流量:将CPU和NPU的流量汇聚
- 路由转发:根据目标地址转发到正确的L2平面
- 负载均衡:将流量分散到7个平面
计算节点内部结构
CPU连接
- 连接方式:通过8×30G LQC连接到L1交换芯片
- 每个CPU:连接到多个L1交换芯片(实现冗余和负载均衡)
- 作用:执行AI训练的控制逻辑、数据预处理等
NPU连接
- 数量:每个节点8个NPU
- 连接方式1:通过8×56G LQC连接到L1交换芯片
- 用于计算面通信(模型参数、梯度同步)
- 连接方式2:通过8×50G RoCE连接到RoCE交换机
- 用于参数面通信(参数服务器通信)
为什么NPU需要两种连接?
- LQC连接:超低延迟,用于紧耦合的同步通信
- RoCE连接:标准以太网,用于参数服务器等场景
RoCE交换机
- 位置:每个计算节点内部
- 作用:提供标准的以太网通信能力
- 连接:连接到8个NPU(8×50G RoCE)
384超节点组网方案
物理架构
┌─────────────────────────────────────────────────────┐
│ 总线设备柜(1套) │
│ ┌────┐ ┌────┐ ┌────┐ ... ┌────┐ │
│ │设备1│ │设备2│ │设备3│ │设备56│ │
│ └────┘ └────┘ └────┘ └────┘ │
│ ↕ ↕ ↕ ↕ │
│ 光纤/铜缆连接(全互联) │
│ ↕ ↕ ↕ ↕ │
│ ┌────┐ ┌────┐ ┌────┐ ... ┌────┐ │
│ │节点1│ │节点2│ │节点3│ │节点48│ │
│ └────┘ └────┘ └────┘ └────┘ │
│ 计算柜(多套) │
└─────────────────────────────────────────────────────┘
关键数字
| 组件 | 数量 | 说明 |
|---|---|---|
| 总线设备 | 56台 | L2层交换设备 |
| 计算节点 | 48台 | 实际部署数量(物理384,实际48) |
| L1交换芯片 | 48×7=336个 | 每个节点7个 |
| NPU总数 | 48×8=384个 | 每个节点8个NPU |
| 平面数 | 7个 | 并行通信平面 |
| 总带宽 | 7×单平面带宽 | 7个平面叠加 |
全互联组网
什么是全互联?
- 每个计算节点都能直接与其他所有节点通信
- 不需要经过多个跳转(hop)
- 延迟最低,带宽最大
实现方式:
- 通过56台总线设备提供足够的交换容量
- 每个节点通过L1交换层连接到所有L2平面
- 7个平面并行工作,提供冗余和负载均衡
类比:
- 非全互联:A到B需要经过C(2跳)
- 全互联:A直接到B(1跳)
网络连接详解
连接类型和带宽
1. CPU到L1交换芯片
- 类型:8×30G LQC
- 总带宽:8 × 30G = 240Gbps
- 用途:CPU与节点内部其他组件通信
- 特点:低延迟、缓存一致性
2. L2到超节点总线
- 类型:8×56G LQC
- 总带宽:8 × 56G = 448Gbps
- 用途:L2层设备之间的通信
- 特点:高带宽、低延迟
3. 超节点总线到L1交换芯片
- 类型:8×56G LQC
- 总带宽:8 × 56G = 448Gbps
- 用途:L2层到L1层的通信
- 特点:连接L1和L2的关键链路
4. NPU到L1交换芯片
- 类型:8×56G LQC
- 总带宽:8 × 56G = 448Gbps
- 用途:NPU的计算面通信(参数同步、梯度同步)
- 特点:超低延迟,用于AI训练的核心通信
5. NPU到RoCE交换机
- 类型:8×50G RoCE
- 总带宽:8 × 50G = 400Gbps
- 用途:NPU的参数面通信(参数服务器)
- 特点:标准以太网,兼容性好
连接拓扑
计算节点内部:
┌─────────────────────────────────────┐
│ CPU ──8×30G LQC──> L1交换芯片1 │
│ CPU ──8×30G LQC──> L1交换芯片2 │
│ ... │
│ CPU ──8×30G LQC──> L1交换芯片7 │
│ │
│ NPU ──8×56G LQC──> L1交换芯片1 │
│ NPU ──8×56G LQC──> L1交换芯片2 │
│ ... │
│ NPU ──8×56G LQC──> L1交换芯片7 │
│ │
│ NPU ──8×50G RoCE──> RoCE交换机 │
└─────────────────────────────────────┘
↕ 8×56G LQC
┌─────────────────────────────────────┐
│ 超节点总线 │
└─────────────────────────────────────┘
↕ 8×56G LQC
┌─────────────────────────────────────┐
│ L2层:灵衢总线设备 │
└─────────────────────────────────────┘
数据流向分析
场景1:NPU到NPU通信(同节点)
NPU1 → L1交换芯片 → NPU2
(节点内部,最快)
特点:
- 延迟最低(微秒级)
- 带宽最高
- 用于节点内部的数据交换
场景2:NPU到NPU通信(跨节点)
节点1的NPU → L1交换 → 超节点总线 → L2交换 →
超节点总线 → 节点2的L1交换 → 节点2的NPU
特点:
- 延迟低(纳秒到微秒级)
- 通过7个平面并行传输
- 用于跨节点的参数同步
场景3:参数服务器通信
NPU → RoCE交换机 → 以太网 → 参数服务器
特点:
- 使用标准以太网协议
- 兼容性好
- 用于参数服务器的集中式通信
数据流优化
负载均衡:
- 数据自动分散到7个平面
- 避免单个平面过载
- 最大化利用带宽
路径选择:
- L1交换芯片根据目标地址选择最佳路径
- 优先选择负载较低的平面
- 实现最短路径转发
与配置管理的关系
为什么需要配置管理?
在这个复杂架构中,每个组件都需要配置:
1. L2层配置
- 总线设备配置:56台设备,每台需要配置
- 交换芯片参数
- 平面分配
- 路由表
- QoS策略
2. L1层配置
- L1交换芯片配置:48节点 × 7芯片 = 336个芯片
- 端口配置
- 路由规则
- 带宽限制
3. 计算节点配置
- CPU配置:每个节点的CPU参数
- NPU配置:384个NPU,每个需要配置
- 驱动版本
- 工作模式
- 通信参数
4. 网络配置
- IP地址分配:每个节点、每个接口
- 路由配置:跨节点通信路由
- VLAN配置:网络隔离
配置管理挑战
挑战1:配置数量庞大
- 384超节点 = 大量配置项
- 手动配置不现实
- 需要自动化配置管理
挑战2:配置差异化
- 不同节点可能有不同配置
- L1和L2层配置不同
- 需要节点级配置管理
挑战3:配置变更频繁
- 网络优化需要调整配置
- 故障恢复需要更新配置
- 需要支持配置热加载
配置管理方案
这正是我们之前设计的配置文件管理方案要解决的问题:
- 统一管理平台:在运维平台统一管理所有配置
- 节点识别:通过集群名、节点名自动识别
- 分层配置:
- 全局配置(所有节点共享)
- 集群配置(L2层、L1层)
- 节点配置(具体节点参数)
- 自动化部署:节点启动自动获取配置
- 配置热加载:配置变更无需重启
总结
架构特点
- 分层设计:L1(节点内)+ L2(节点间)+ 超节点总线
- 全互联:每个节点都能直接通信
- 多平面:7个平面并行,提供冗余和负载均衡
- 高带宽:LQC协议提供超低延迟、高带宽
- 可扩展:支持64/96/192/384超节点
关键优势
- 超低延迟:LQC协议实现接近芯片内部的通信延迟
- 高带宽:7个平面叠加,总带宽巨大
- 高可靠性:多平面冗余,单点故障不影响整体
- 灵活扩展:支持多种规模配置
配置管理需求
- 自动化:大量配置需要自动化管理
- 差异化:不同层级、不同节点需要不同配置
- 动态更新:支持配置热加载,无需重启
- 统一平台:在运维平台统一管理
附录:术语表
| 术语 | 英文 | 说明 |
|---|---|---|
| 灵衢网络 | LingQu Network | 华为自研的高速互联网络 |
| LQC协议 | LingQu Cache-coherent | 灵衢缓存一致性协议 |
| 超节点 | SuperPod | 大规模AI训练集群 |
| 计算节点 | Compute Node | 包含CPU和NPU的计算单元 |
| 总线设备 | Bus Device | L2层交换设备 |
| 平面 | Plane | 独立的通信平面 |
| RoCE | RDMA over Converged Ethernet | 基于以太网的RDMA协议 |
| 全互联 | Full Mesh | 所有节点直接相连的拓扑 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)