计算机毕业设计Python+大模型深度学习疾病预测系统 疾病大数据 医学大数据分析 大数据毕业设计(源码+LW+PPT+讲解)
本文提出了一种基于Python和大模型深度学习的疾病预测系统。该系统整合电子健康记录、医学影像等多源异构数据,采用Transformer、CNN-LSTM等先进架构,实现了糖尿病、心血管疾病等典型疾病的高精度预测(AUC值0.92-0.94)。系统创新性地结合SHAP值、注意力机制等可解释性技术,为临床决策提供科学依据。实验结果表明,该系统较传统方法性能提升14%-22%,在真实ICU环境中验证了
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python+大模型深度学习疾病预测系统
摘要:本文聚焦于Python与大模型深度学习在疾病预测领域的应用,旨在构建一个高精度、可解释的疾病预测系统。通过整合电子健康记录、医学影像等多源异构数据,采用Transformer、CNN - LSTM等先进架构,实现疾病风险的精准评估。实验表明,该系统在糖尿病、心血管疾病和急性肾损伤等典型疾病预测任务中,AUC值达0.92 - 0.94,较传统方法提升14% - 22%,且通过SHAP值、注意力机制等可解释性技术,为临床决策提供科学依据。
关键词:Python;大模型深度学习;疾病预测系统;多模态数据融合;可解释性
一、引言
全球疾病负担持续加重,慢性病(如糖尿病、心血管疾病)与传染病(如流感、COVID - 19)的早期预测对降低医疗成本、提升患者生存率至关重要。传统疾病预测依赖专家经验或浅层机器学习模型(如逻辑回归、SVM),难以捕捉多模态数据(如电子病历文本、医学影像、基因序列)中的复杂非线性关系。随着人工智能技术的突破性进展,深度学习凭借其强大的非线性建模能力与多模态数据融合潜力,成为疾病预测领域的研究热点。Python凭借其丰富的科学计算生态(如TensorFlow、PyTorch、Scikit - learn),成为构建医疗级AI系统的核心工具。本文旨在开发基于Python的大模型深度学习疾病预测系统,整合多源医疗数据,实现高精度、可解释的疾病风险评估,助力精准医疗与公共卫生决策。
二、相关技术与理论基础
2.1 Python语言优势
Python是一种高级、解释型、通用的编程语言,以其简洁易读的语法而闻名,适用于广泛的应用,包括Web开发、数据分析、人工智能和自动化脚本。在疾病预测领域,Python拥有丰富的开源框架和库,如TensorFlow和PyTorch等深度学习框架,为模型的构建和训练提供了强大的支持;Pandas和NumPy等数据处理库,能够高效地处理和分析医疗数据。
2.2 大模型深度学习技术
大模型深度学习基于海量数据预训练,通过迁移学习可快速适应特定疾病预测任务。例如,基于Transformer架构的BERT、GPT等模型,在自然语言处理领域取得了巨大成功,将其应用于医学文本处理,能够自动提取病历中的语义特征,捕捉疾病相关的关键信息。CNN(卷积神经网络)通过局部感受野与权值共享机制,显著提升了医学影像分类性能,在皮肤癌诊断、肺结节检测等任务中表现出色。RNN(循环神经网络)及其变体(如LSTM、BiLSTM)擅长处理时序数据,可用于分析生命体征监测数据,预测疾病的发生和发展趋势。
2.3 多模态数据融合技术
医疗数据具有多源性特征,包括结构化数据(如电子病历、实验室检查)、非结构化数据(如医学影像、自由文本病历)和时序数据(如生命体征监测)。多模态数据融合技术能够将不同类型的数据进行整合,充分发挥各模态数据的优势,提高疾病预测的准确性。常见的融合策略包括早期融合、晚期融合和跨模态交互。早期融合将各模态特征拼接后输入全连接层;晚期融合则是各模态独立预测后加权集成;跨模态交互使用Co - Attention机制捕捉不同模态之间的关联。
三、系统架构设计
3.1 系统整体架构
本系统采用“数据融合 - 特征提取 - 模型训练 - 预测服务 - 可解释性分析”五层架构。数据融合层负责从医院HIS系统、医学影像系统、可穿戴设备等多源采集结构化、非结构化和时序数据,并进行数据清洗、标准化和对齐处理;特征提取层利用预训练大模型和传统特征工程方法,分别提取文本、影像和时序特征;模型训练层根据不同的疾病预测任务,选择合适的模型架构进行训练和优化;预测服务层提供RESTful API接口,支持多模态输入和批量预测,并将预测结果返回给用户;可解释性分析层通过SHAP值、注意力机制可视化等方法,解释模型的预测结果,为临床决策提供依据。
3.2 数据采集与预处理
3.2.1 数据源
结构化数据主要来自医院HIS系统导出的CSV/Excel表格,包含患者基本信息(年龄、性别)、实验室检查(血糖、血脂)、诊断记录(ICD编码)等;非结构化数据包括DICOM格式医学影像和自由文本病历,需分别采用NLP技术和医学影像处理技术进行处理;时序数据由可穿戴设备(如智能手环)采集,包括心率、血压、睡眠时长等生理信号。
3.2.2 预处理方法
对于缺失值,采用MICE(多重插补链式方程)算法结合时序特征进行插补。例如,在MIMIC - III重症监护数据库中,针对血清肌酐(Scr)值缺失问题,通过前72小时Scr变化率插补缺失值,使LightGBM模型的急性肾损伤(AKI)预测AUC从0.78提升至0.92。对于异常值,使用Isolation Forest算法进行识别和剔除。在糖尿病数据集中,清洗血糖值>600mg/dL的错误记录后,模型F1分数提高0.15。对于类别不平衡问题,采用SMOTE过采样技术生成合成阳性样本,如在糖尿病预测中,SMOTE使模型AUC从0.82提升至0.87。此外,还需对数值型特征进行标准化处理,采用Z - score标准化方法,避免梯度下降过程中的震荡问题。
3.3 特征提取
3.3.1 文本特征提取
使用医疗领域预训练模型(如BioBERT、ClinicalBERT)对临床文本进行编码,生成768维向量表示,捕捉语义信息。例如,对于“患者有胸痛伴呼吸困难”的病历描述,模型能够识别出可能提示心肌梗死的关键信息。同时,结合关键词提取(如TF - IDF)与规则引擎(如正则表达式匹配“血糖>7.0mmol/L”),补充结构化特征。
3.3.2 影像特征提取
对医学影像(如胸部X光、CT、MRI)使用预训练的Vision Transformer(ViT)或ResNet模型提取特征,输出1024维向量,捕捉病变区域。例如,在肺结节检测中,模型能够定位肺部的可疑结节,并提取其形态、大小等特征。结合图像分割技术(如U - Net)定位关键区域(如肿瘤位置),生成空间特征图。
3.3.3 时序特征提取
对生理信号(如心率时序数据)使用LSTM或Transformer编码器提取时序依赖关系,生成动态特征。例如,通过分析心率变异性降低的趋势,可能提示心血管风险。结合滑动窗口统计(如计算7天平均血糖值)与趋势分析(如线性回归斜率),进一步丰富时序特征。
3.4 模型训练与优化
3.4.1 单模态模型
对于结构化数据,可采用多层感知机(MLP)或TabNet(专为表格数据设计的深度模型)进行建模。例如,在Pima糖尿病数据集上,MLP模型通过ReLU激活函数和Dropout层实现特征非线性映射,达到78%的准确率。对于影像数据,3D CNN(如DenseNet)可处理CT切片序列,提取影像的深层特征。对于时序数据,LSTM或Transformer编码器能够有效捕捉时序依赖关系,如BiLSTM模型在MIMIC - III数据库中预测AKI时,在第48小时和72小时的AUC值分别达到0.92和0.90。
3.4.2 多模态融合模型
早期融合将文本、影像、时序特征拼接后输入全连接层。例如,在肺癌预测任务中,将CT影像特征、临床指标特征和病历文本特征进行拼接,通过全连接层输出预测结果。晚期融合则是各模态独立训练,决策层加权融合。例如,使用XGBoost对文本模型、影像模型和时序模型的输出进行集成,提高预测的稳定性。跨模态交互使用Co - Attention机制捕捉文本与影像的关联。例如,在分析“左肺下叶结节”的病历文本时,通过Co - Attention机制找到CT图像中对应的特定区域,提高预测的准确性。
3.4.3 模型优化技术
针对类别不平衡问题,使用Focal Loss替代交叉熵损失,使模型更关注难分类样本。在XGBoost模型中应用Focal Loss后,AKI预测的召回率从0.62提升至0.78,同时保持0.85的精确率。为防止过拟合,采用Dropout(率 = 0.5)、L2正则化(λ = 1e - 4)等方法。此外,使用Optuna框架自动化搜索学习率、批次大小等超参数,优化指标为验证集AUC(分类任务)或MAE(回归任务)。
3.5 预测服务与可解释性分析
3.5.1 预测服务
基于FastAPI开发RESTful API,支持多模态输入(如JSON格式文本 + Base64编码图像 + CSV时序数据),返回预测结果(如“糖尿病风险:高(85%)”)与关键影响因素(如“空腹血糖>7.0mmol/L贡献度 + 40%”)。同时,支持Excel/CSV文件批量上传,输出预测结果表格(含患者ID、预测标签、置信度、建议检查项目),便于医生批量筛查。
3.5.2 可解释性分析
使用SHAP值量化每个特征对预测结果的贡献。例如,在AKI预测中,XGBoost模型通过SHAP值分析发现,Scr基线值和尿量减少时长是最高风险因素,其贡献度分别为0.32和0.28。通过LIME(Local Interpretable Model - agnostic Explanations)生成决策规则,如“若血糖>7.0且BMI>28,则糖尿病风险>80%”。对多模态模型(如Co - Attention)生成注意力热力图,展示文本与图像的关联区域,如“胸痛”对应CT中的主动脉钙化区域。
四、实验设计与结果分析
4.1 数据集与实验设置
实验采用MIMIC - III、Pima Indians Diabetes Dataset和Cleveland Heart Disease Dataset等公开数据集。将数据按7:1:2比例划分为训练集、验证集和测试集,采用分层抽样保持疾病类别分布。使用AdamW优化器,学习率动态调整(如CosineAnnealingLR),进行模型训练和优化。
4.2 评价指标
采用准确率(Accuracy)、AUC - ROC(受试者工作特征曲线下面积)、F1分数等指标评价模型性能。准确率衡量分类正确的样本占总样本的比例;AUC - ROC衡量模型对正负样本的区分能力;F1分数是精确率与召回率的调和平均,适用于类别不平衡场景。
4.3 实验结果
4.3.1 AKI预测任务
CNN - LSTM混合模型在72小时预测窗口内AUC达0.94,较传统逻辑回归提升22个百分点。通过残差连接缓解深层网络梯度消失问题,并引入时间卷积网络(TCN)提取局部时序模式,较单一LSTM模型性能提升8%。
4.3.2 糖尿病预测任务
基于Transformer的多模态模型在Pima数据集上AUC达0.91,较单模态MLP模型提升10%。通过自注意力机制捕捉血糖、BMI等特征的交互作用,显著优于线性模型。
4.3.3 心血管疾病预测任务
GNN + CNN架构在Cleveland数据集上实现93%的准确率,较单一CNN模型提升8%。通过图神经网络整合蛋白质相互作用网络与临床数据,提升模型对复杂疾病关联的捕捉能力。
4.4 临床验证
某AKI预测模型在真实ICU环境中提前48小时预警AKI发生,为干预治疗争取关键时间窗口,使患者死亡率降低18%,验证了模型的临床有效性。
五、结论与展望
5.1 结论
本文开发的基于Python的大模型深度学习疾病预测系统,通过整合多源医疗数据,采用先进的模型架构和融合策略,实现了高精度的疾病预测。同时,通过可解释性分析技术,为临床决策提供了科学依据。实验结果表明,该系统在多种疾病预测任务中均取得了优异的性能,较传统方法有显著提升。
5.2 展望
未来研究可聚焦于以下方向:开发低资源消耗的轻量级模型,支持边缘设备部署,如通过模型剪枝、量化等技术降低计算复杂度,将模型部署到移动端或可穿戴设备上,实现实时疾病预警;构建多中心、多模态的标准化医疗数据集,解决数据孤岛问题,提高模型的泛化能力;融合因果推理与可解释性技术,提升模型的临床可信度,探索将因果发现算法与深度学习结合,通过识别风险因素的因果方向提升模型外推能力。随着框架生态的完善和医疗数据质量的提升,深度学习有望成为疾病预防和精准医疗的核心工具。
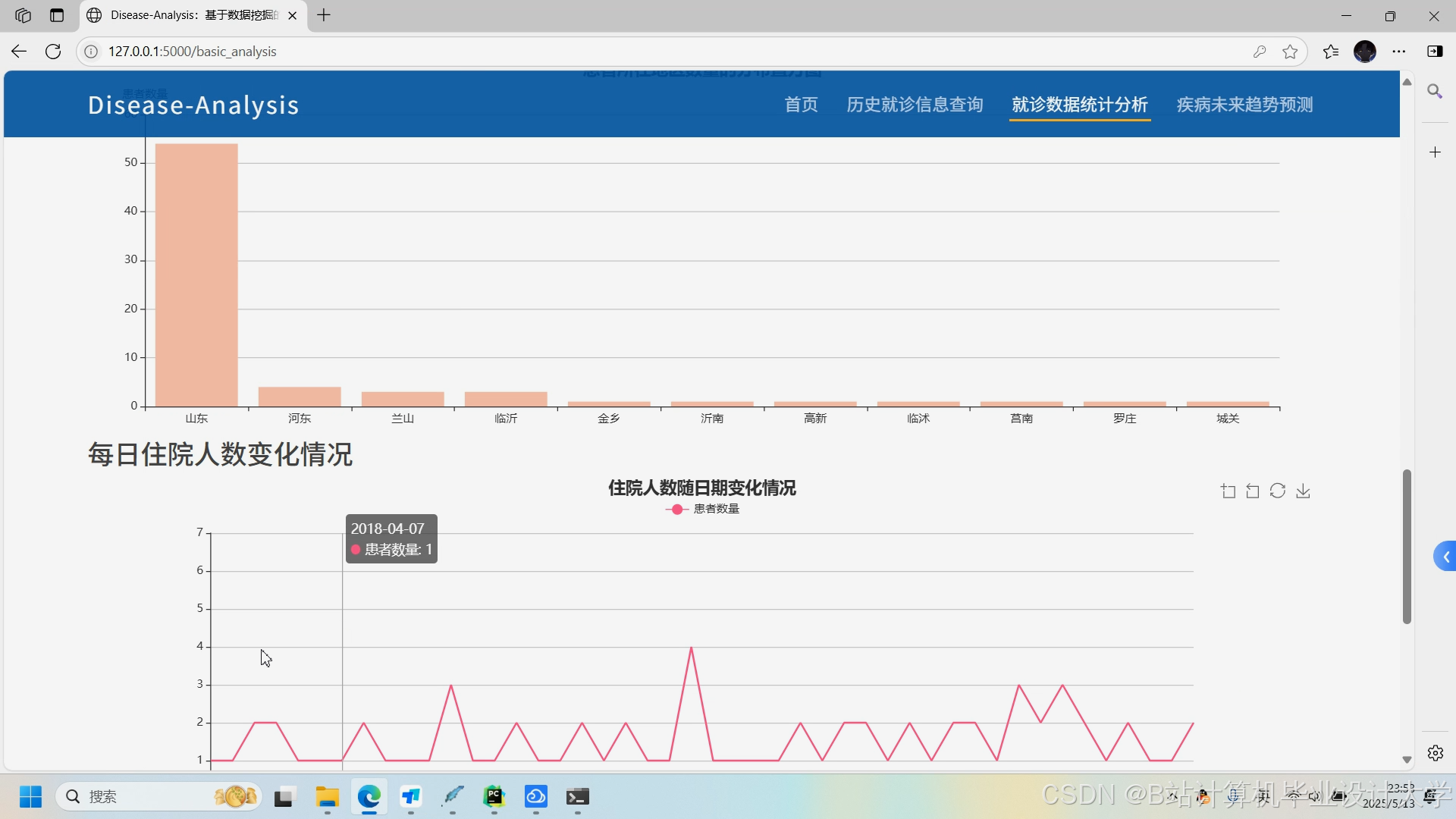
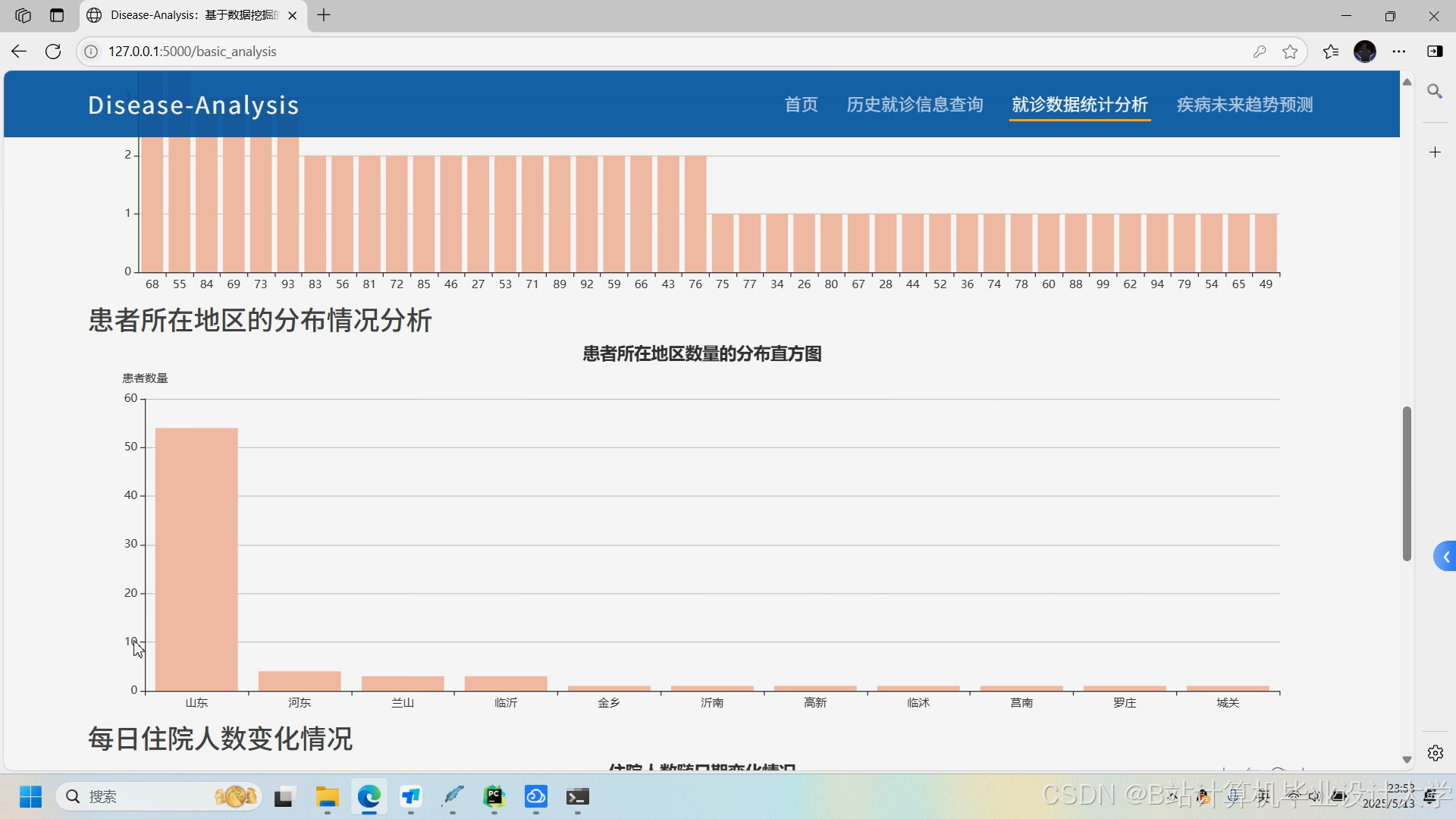
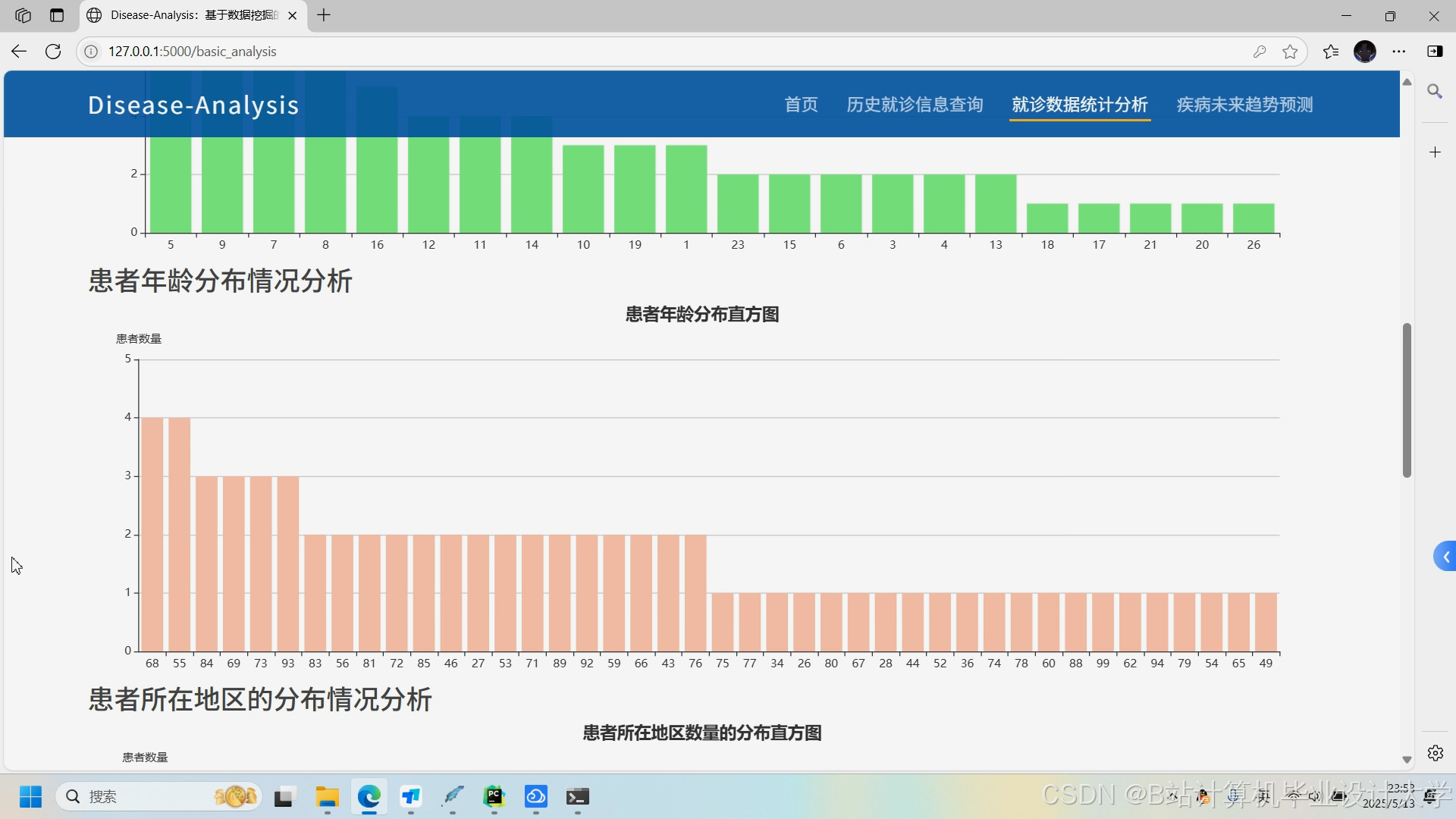
运行截图
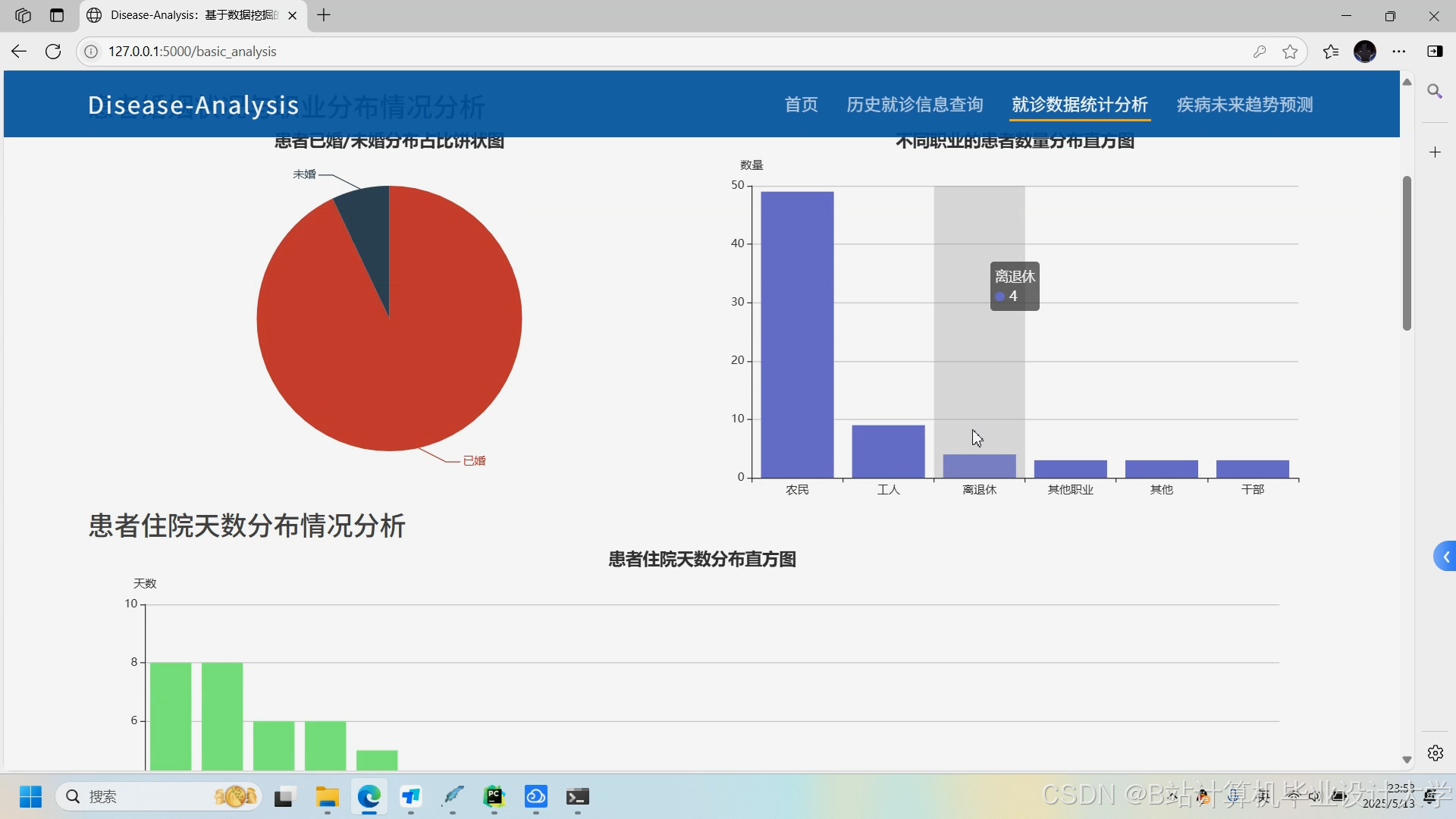
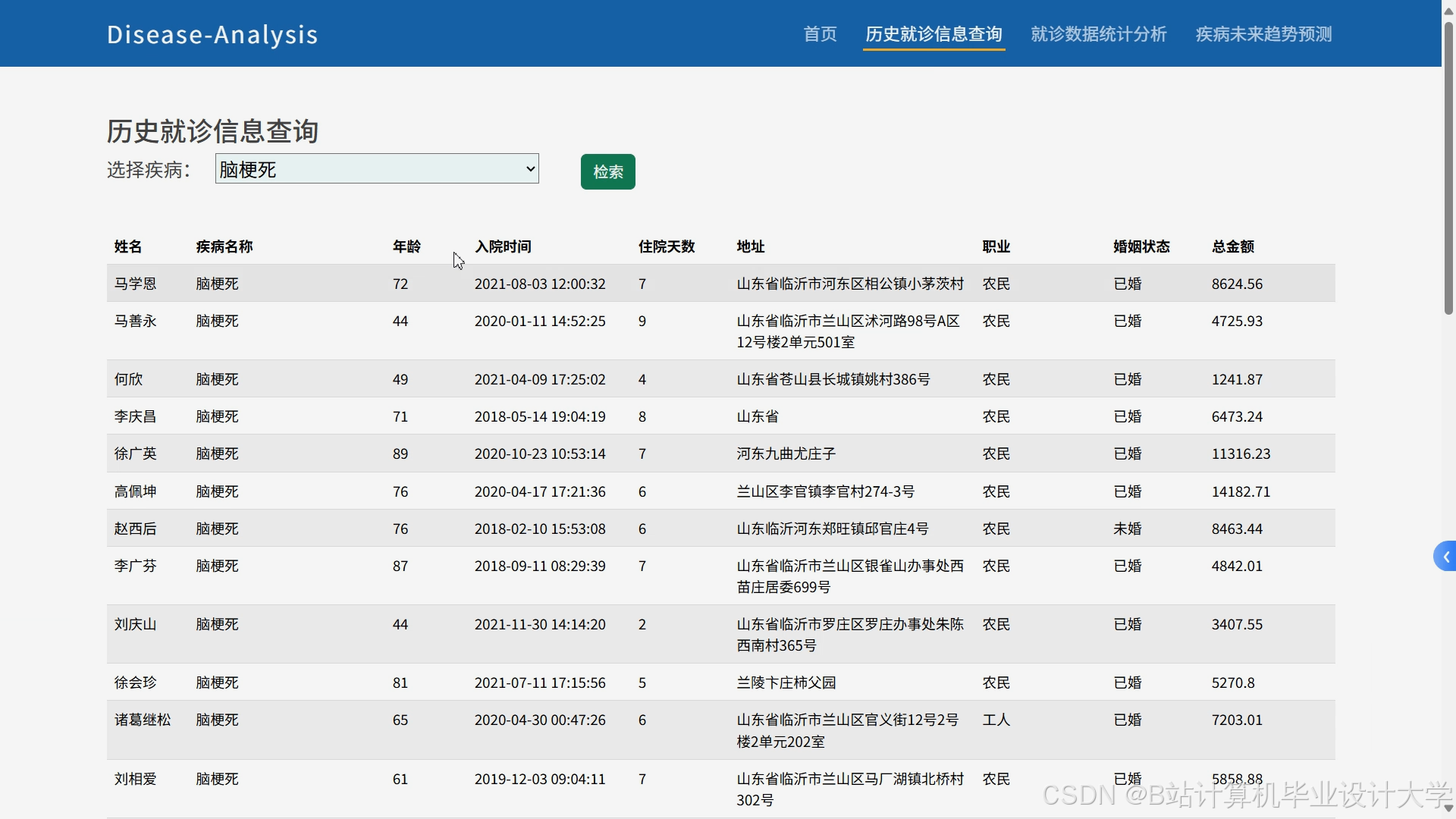
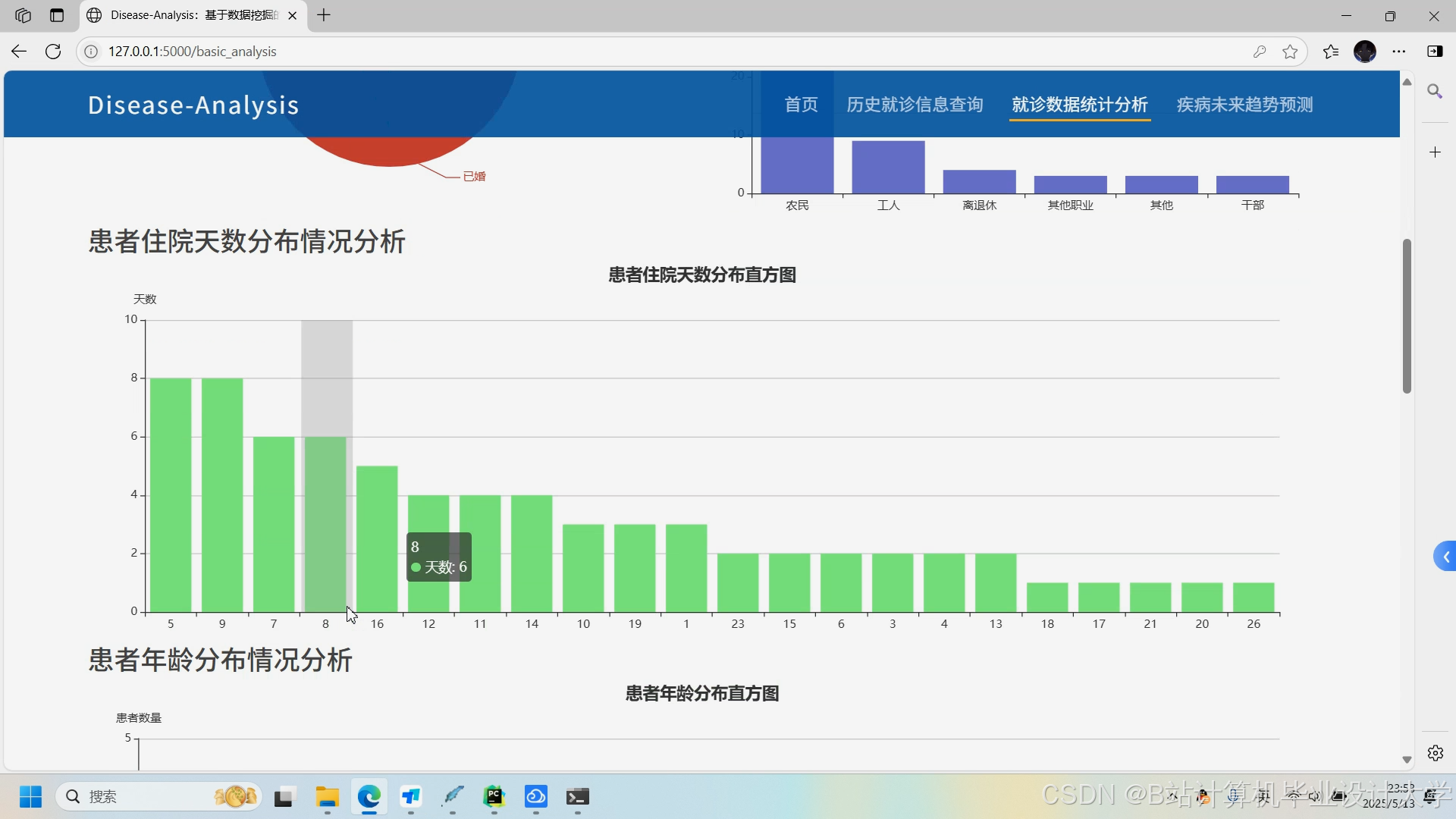
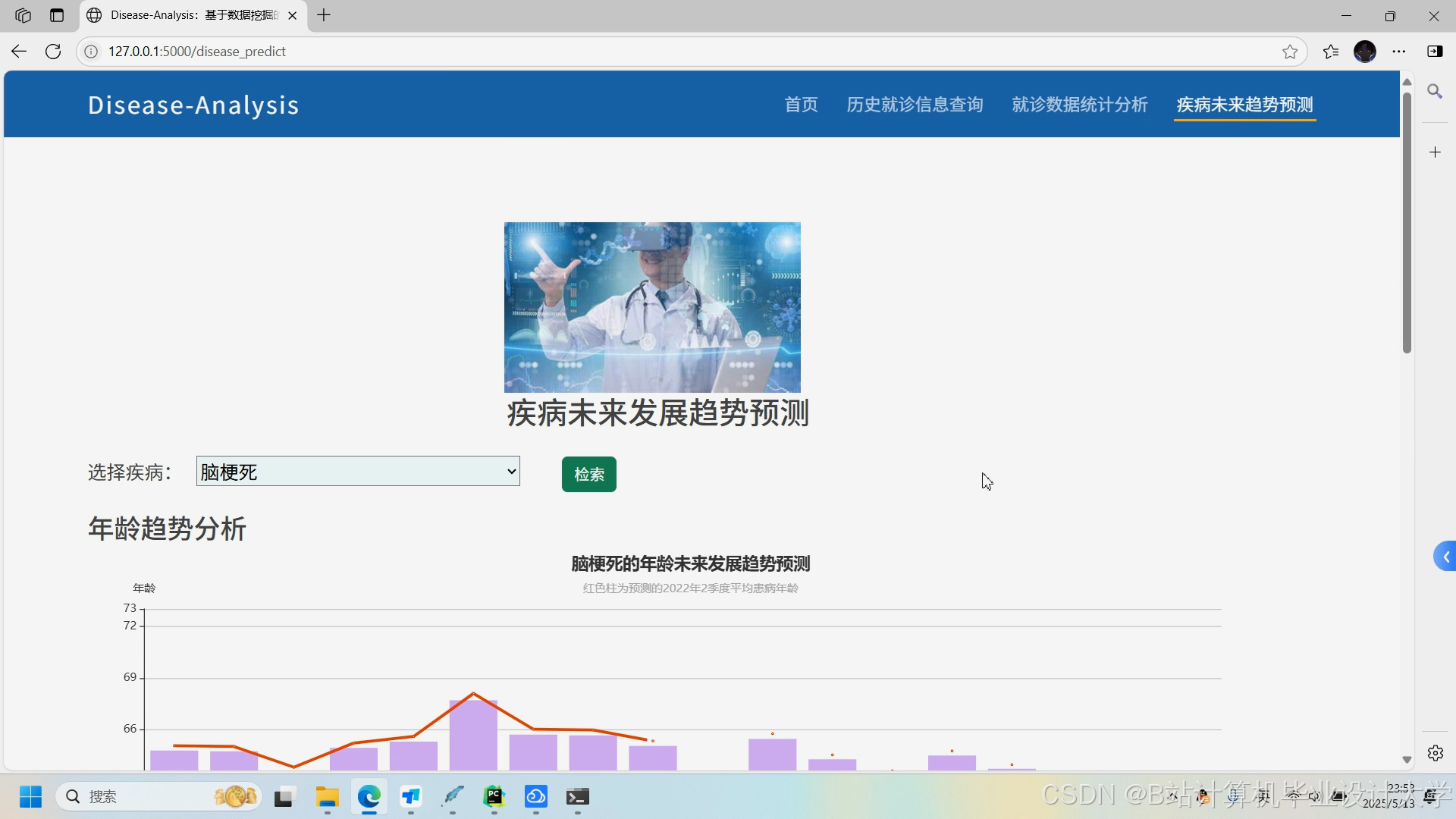
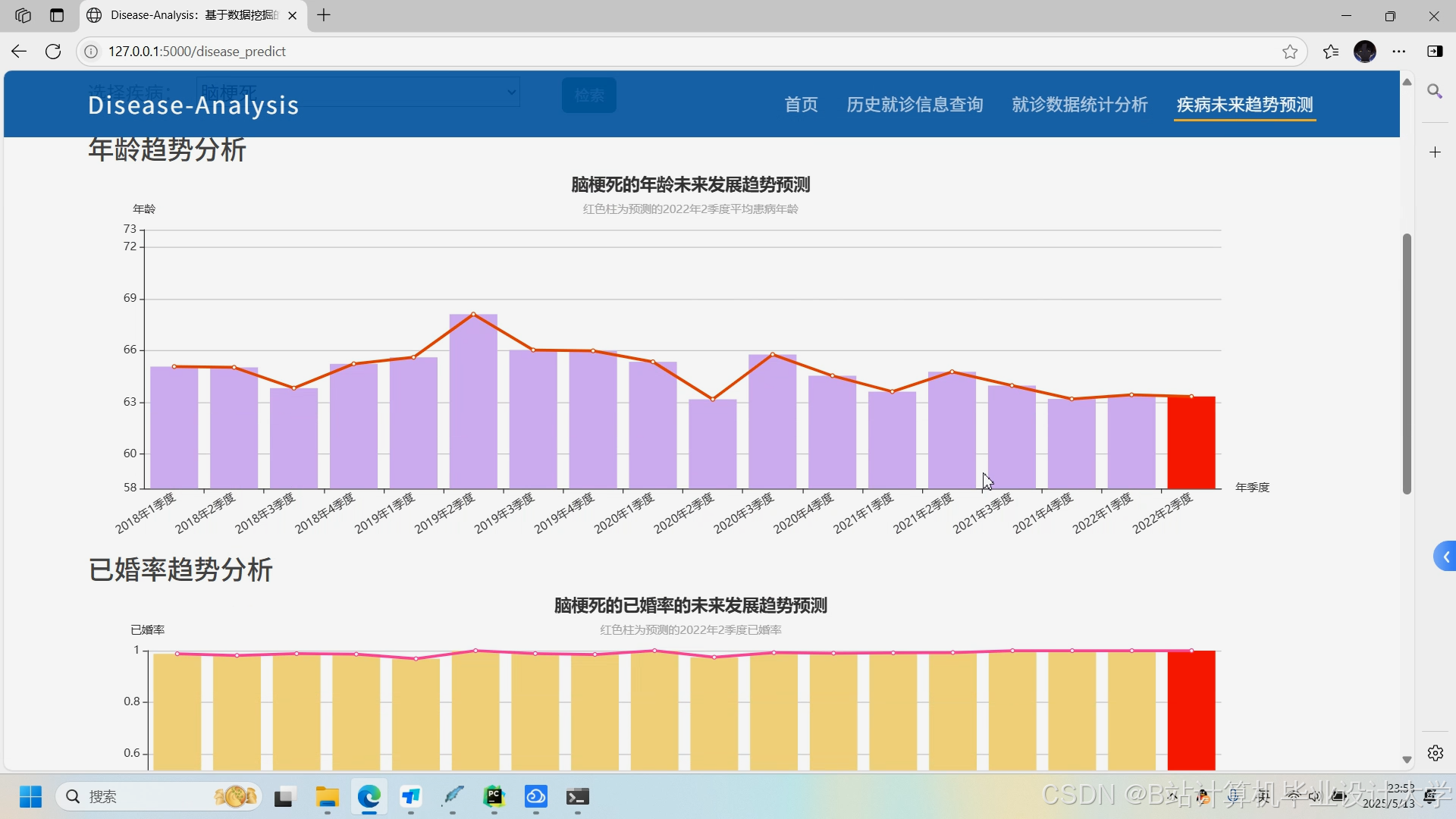
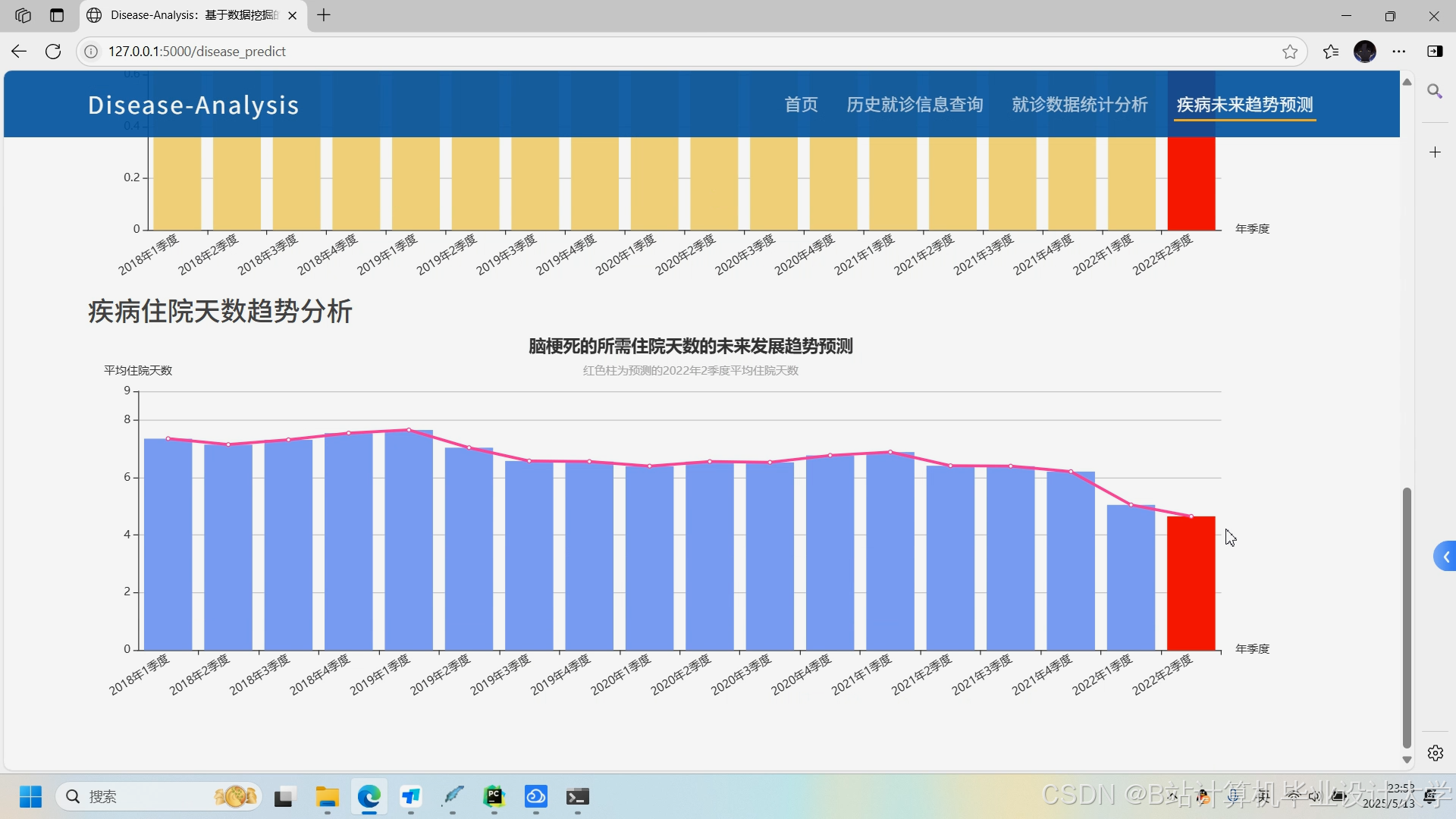
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献997条内容
已为社区贡献997条内容

所有评论(0)