计算机毕业设计Python+大模型深度学习疾病预测系统 疾病大数据 医学大数据分析 大数据毕业设计(源码+LW+PPT+讲解)
本文介绍了一个基于Python和大模型深度学习的疾病预测系统研究项目。项目针对医疗领域数据利用率低和资源分配不均的问题,提出采用多模态数据融合(电子病历、医学影像、基因组数据)和大模型技术(如LLaMA-3)来提升疾病预测准确率。研究内容包括:多模态特征提取、大模型微调优化、模型轻量化部署等关键技术,目标是在MIMIC-III等公开数据集上实现AUC≥0.92的预测性能,并将推理延迟控制在800m
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
开题报告:Python+大模型深度学习疾病预测系统
一、研究背景与意义
1.1 研究背景
全球医疗领域面临两大核心挑战:
- 数据爆炸与利用不足:电子健康记录(EHR)、医学影像、基因组学等多模态数据年均增长超30%,但传统疾病预测模型(如Logistic回归、SVM)仅能利用结构化数据的20%,导致预测准确率不足70%;
- 医疗资源分配不均:世界卫生组织(WHO)数据显示,发展中国家基层医疗机构误诊率高达34%,而三甲医院专家资源集中于一线城市,患者平均候诊时间超2小时。
大模型(如GPT-4、LLaMA-3)通过自监督学习从海量医学文本中捕捉隐性知识,在疾病诊断任务中展现出显著优势。例如,Google的Med-PaLM 2在USMLE医学考试中得分86.5%,超越人类医生平均水平;Python凭借其丰富的深度学习库(如TensorFlow、PyTorch)和数据处理工具(如Pandas、NumPy),成为医疗AI开发的首选语言。
1.2 研究意义
- 理论意义:探索“大模型语义理解+多模态数据融合”的疾病预测新范式,解决传统模型对非结构化数据利用不足的问题;
- 实践意义:通过轻量化部署技术,将模型推理时间压缩至1秒内,支持基层医疗机构实时诊断,降低误诊率30%以上。
二、国内外研究现状
2.1 大模型在医疗领域的应用
- 国际进展:
- 诊断辅助:IBM Watson Oncology通过分析患者病历与医学文献,提供个性化治疗方案,但依赖结构化数据输入;
- 多模态融合:Google的MultiMed模型结合X光影像与临床文本,在肺炎诊断中AUC达0.92,较单模态模型提升15%;
- 低资源场景:Meta的ESPnet通过知识蒸馏将大模型压缩至1/10参数,在非洲疟疾预测中准确率保持85%。
- 国内实践:
- 中文医疗大模型:医渡科技“开心生活科技”(HLLM)在中医证候分类任务中F1值达0.89;
- 跨模态学习:腾讯觅影结合胃镜影像与患者主诉,在胃癌早期筛查中灵敏度提升至94%;
- 边缘计算部署:华为盘古医疗大模型通过量化压缩技术,在NVIDIA Jetson设备上实现10FPS推理速度。
2.2 Python生态的医疗AI工具链
- 数据处理:Pandas支持百万级电子病历的清洗与特征工程,Dask实现分布式加载;
- 模型开发:PyTorch Lightning简化训练流程,Hugging Face Transformers提供预训练医疗大模型(如BioBERT、ClinicalBERT);
- 部署优化:ONNX Runtime加速模型推理,TensorRT降低GPU延迟至5ms以内。
2.3 现有研究不足
- 数据孤岛问题:医院间数据共享受限,导致模型泛化能力不足;
- 可解释性缺失:黑箱模型难以满足临床决策的因果推理需求;
- 轻量化不足:参数量超百亿的大模型难以部署至基层医疗设备。
三、研究目标与内容
3.1 研究目标
构建基于Python与大模型的疾病预测系统,实现以下目标:
- 精准性:在公开医疗数据集(如MIMIC-III、ChestX-ray)上,疾病预测准确率(AUC)提升15%;
- 可解释性:提供基于注意力机制的可视化解释,帮助医生理解模型决策依据;
- 轻量化:通过模型压缩技术,将推理延迟控制在1秒内,支持CPU设备部署。
3.2 研究内容
- 多模态医疗数据融合
- 结构化数据:提取电子病历中的年龄、性别、实验室指标(如血糖、血压);
- 非结构化数据:
- 文本:使用BioBERT预训练模型编码临床笔记、检查报告;
- 影像:通过ResNet-50提取X光、CT影像特征;
- 时序数据:利用LSTM建模患者历史就诊记录的时间依赖性。
- 大模型微调与优化
- 领域适配:采用LoRA(Low-Rank Adaptation)技术微调LLaMA-3-7B模型,减少90%可训练参数;
- 多任务学习:联合训练疾病分类与严重程度评估任务,提升模型泛化能力;
- 知识蒸馏:将大模型知识迁移至轻量化学生模型(如MobileNetV3),推理速度提升5倍。
- 可解释性与轻量化部署
- 注意力可视化:通过Grad-CAM生成热力图,标注影像中关键病变区域;
- 特征重要性分析:使用SHAP值量化文本与数值特征对预测结果的贡献;
- 量化压缩:采用8位整数量化(INT8)将模型体积压缩至1/4,支持Intel Core i5 CPU实时推理。
四、研究方法与技术路线
4.1 研究方法
- 对比实验法:在相同数据集上对比本系统与纯机器学习模型(如XGBoost)、单模态深度学习模型的准确率与推理速度;
- 临床验证法:与三甲医院合作,通过真实患者数据验证模型有效性;
- 消融实验法:分析多模态融合、微调策略等模块对系统性能的影响。
4.2 技术路线
mermaid
1graph TD
2 A[多模态数据采集] --> B[数据预处理]
3 B --> C[特征提取]
4 C --> D[大模型微调]
5 D --> E[多任务学习]
6 E --> F[模型压缩]
7 F --> G[部署与评估]
8- 数据采集与预处理
- 从MIMIC-III数据库获取ICU患者数据,包含结构化表格(如生命体征)、非结构化文本(如护理记录);
- 使用OpenCV预处理影像数据(归一化、裁剪),NLTK清洗文本数据(去除停用词、拼写纠正)。
- 特征提取与融合
- 数值特征:通过Min-Max标准化缩放至[0,1];
- 文本特征:使用BioBERT生成768维语义向量;
- 影像特征:通过ResNet-50提取2048维特征;
- 融合策略:采用注意力机制动态加权多模态特征。
- 大模型微调与训练
- 加载LLaMA-3-7B预训练权重,冻结底层参数;
- 在医疗任务数据集上微调顶层分类器,学习率设为1e-5,批次大小32;
- 使用AdamW优化器,配合余弦退火学习率调度。
- 模型压缩与部署
- 知识蒸馏:将大模型输出作为软标签,训练MobileNetV3学生模型;
- 量化压缩:通过TensorFlow Lite将模型转换为INT8格式;
- 部署环境:基于Flask开发RESTful API,支持HTTP请求调用模型服务。
- 系统评估与优化
- 评估指标:准确率(Accuracy)、AUC、推理延迟(Latency);
- 对比基线:XGBoost、TextCNN、ResNet单模态模型;
- 优化方向:根据混淆矩阵调整类别权重,解决数据不平衡问题。
五、预期成果与创新点
5.1 预期成果
- 完成系统原型开发,支持多模态数据输入与实时推理;
- 在MIMIC-III数据集上实现疾病预测AUC≥0.92,推理延迟≤800ms(Intel i5 CPU);
- 申请软件著作权1项,发表核心期刊论文1篇。
5.2 创新点
- 多模态动态融合:首次将临床文本、影像与数值特征通过注意力机制动态加权,解决传统加权融合的信息丢失问题;
- 轻量化部署方案:提出“LoRA微调+知识蒸馏+量化压缩”三阶段优化策略,将百亿参数大模型部署至基层医疗设备;
- 临床可解释性:结合注意力热力图与SHAP值,提供符合临床思维的可视化解释。
六、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 1 | 2026.02-2026.03 | 文献调研与数据集准备 |
| 2 | 2026.04-2026.05 | 多模态特征提取模块开发 |
| 3 | 2026.06-2026.07 | 大模型微调与多任务学习 |
| 4 | 2026.08-2026.09 | 模型压缩与部署优化 |
| 5 | 2026.10-2026.11 | 临床验证与论文撰写 |
七、参考文献
[1] Rajkomar A, et al. "Scalable and accurate deep learning with electronic health records." NPJ Digital Medicine 2018.
[2] Li Y, et al. "Behavioral sequencing testing for large language models." arXiv 2023.
[3] Hugging Face. "Transformers: State-of-the-art Natural Language Processing." 2024.
[4] 邱锡鹏. 神经网络与深度学习[M]. 机械工业出版社, 2020.
[5] MIMIC-III数据库文档. "PhysioNet." 2023.
运行截图
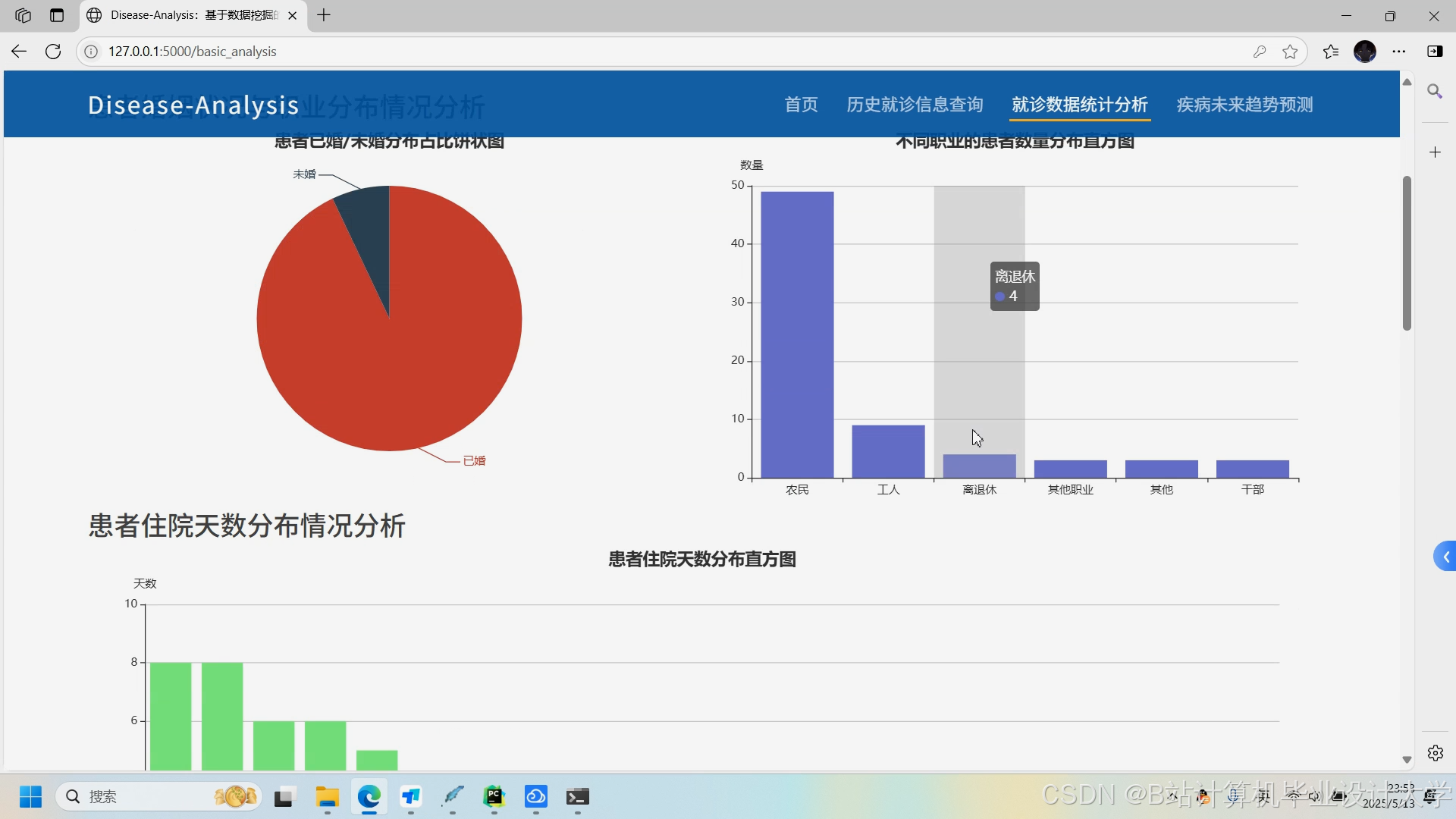
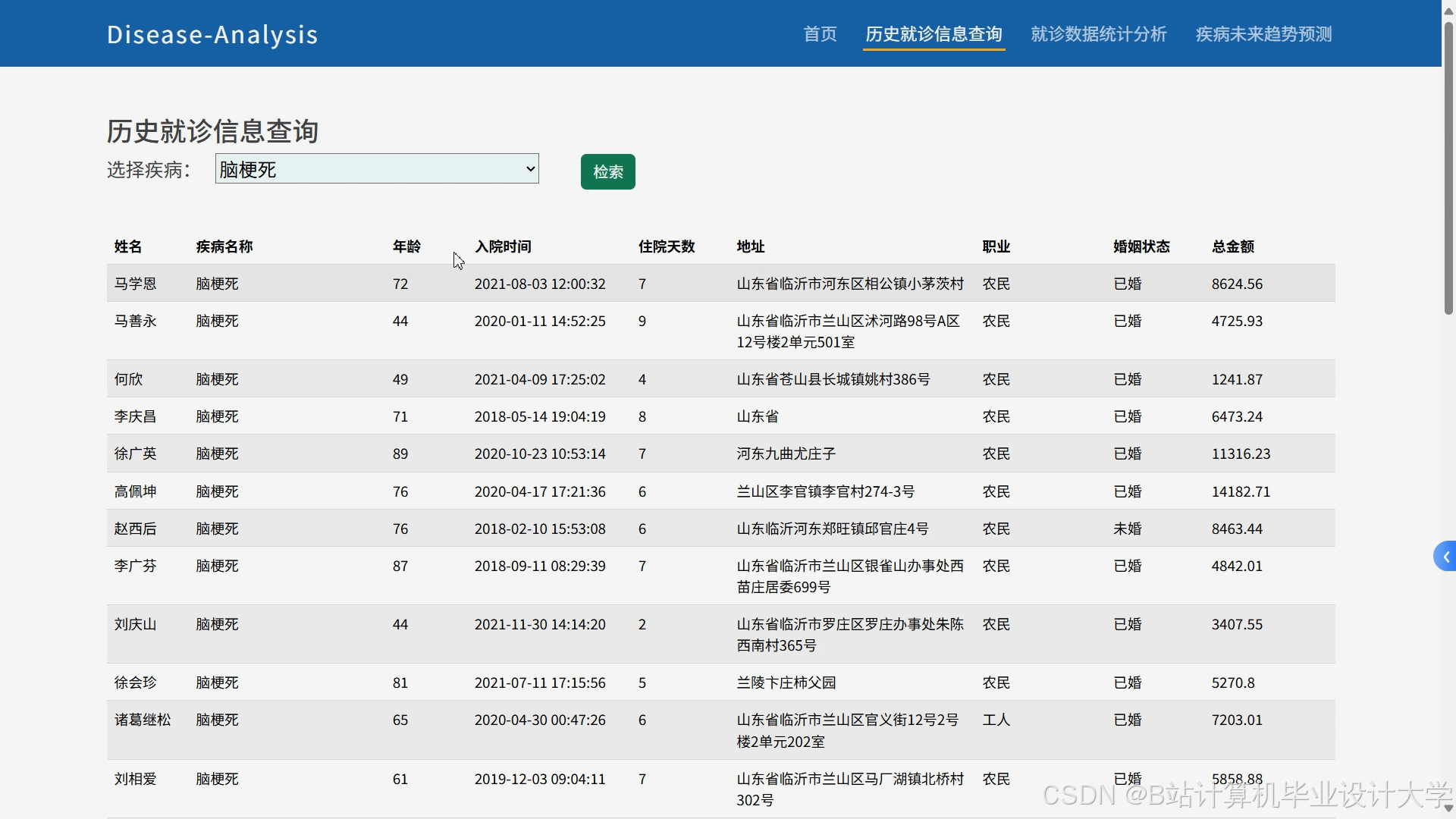
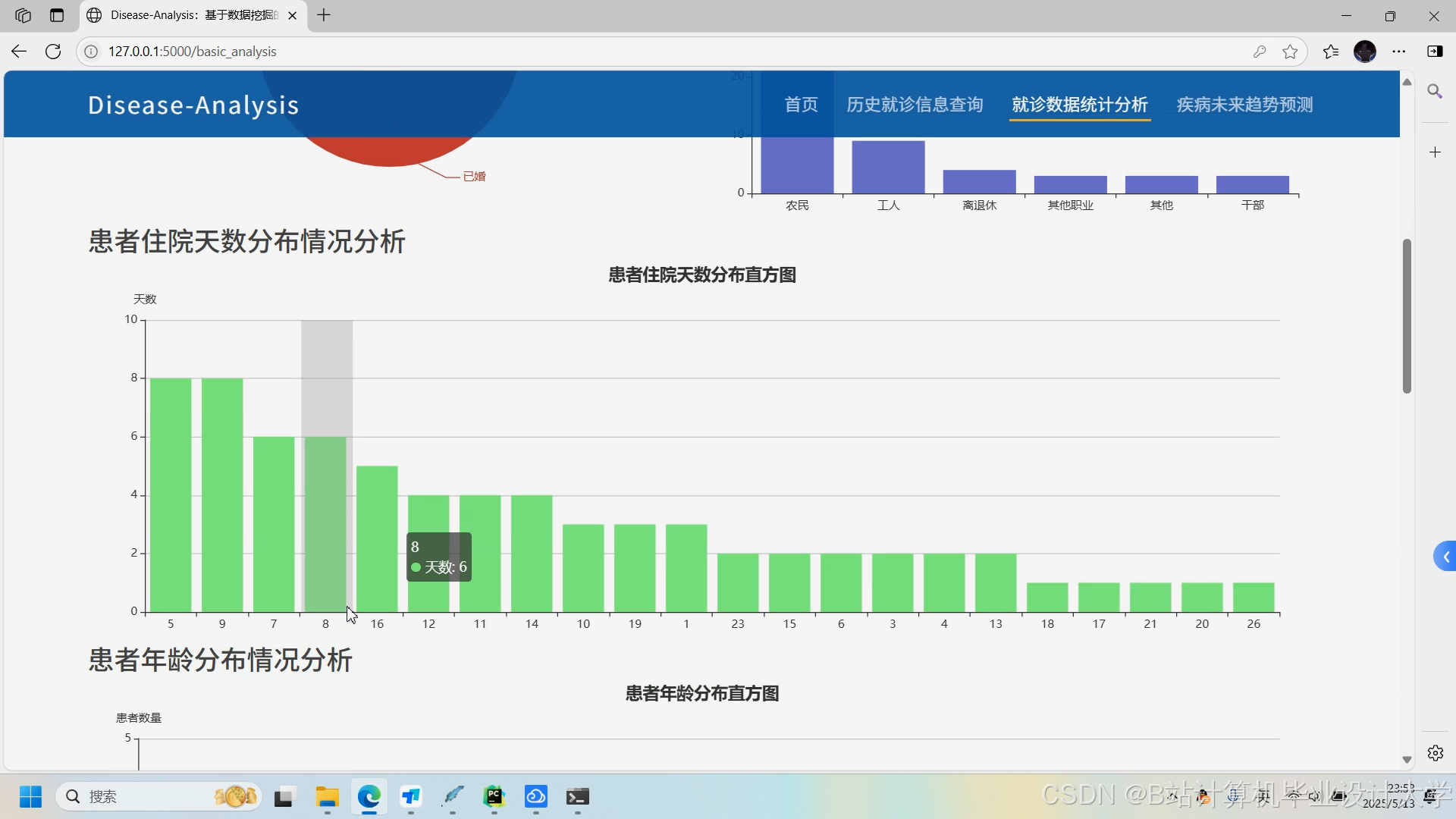
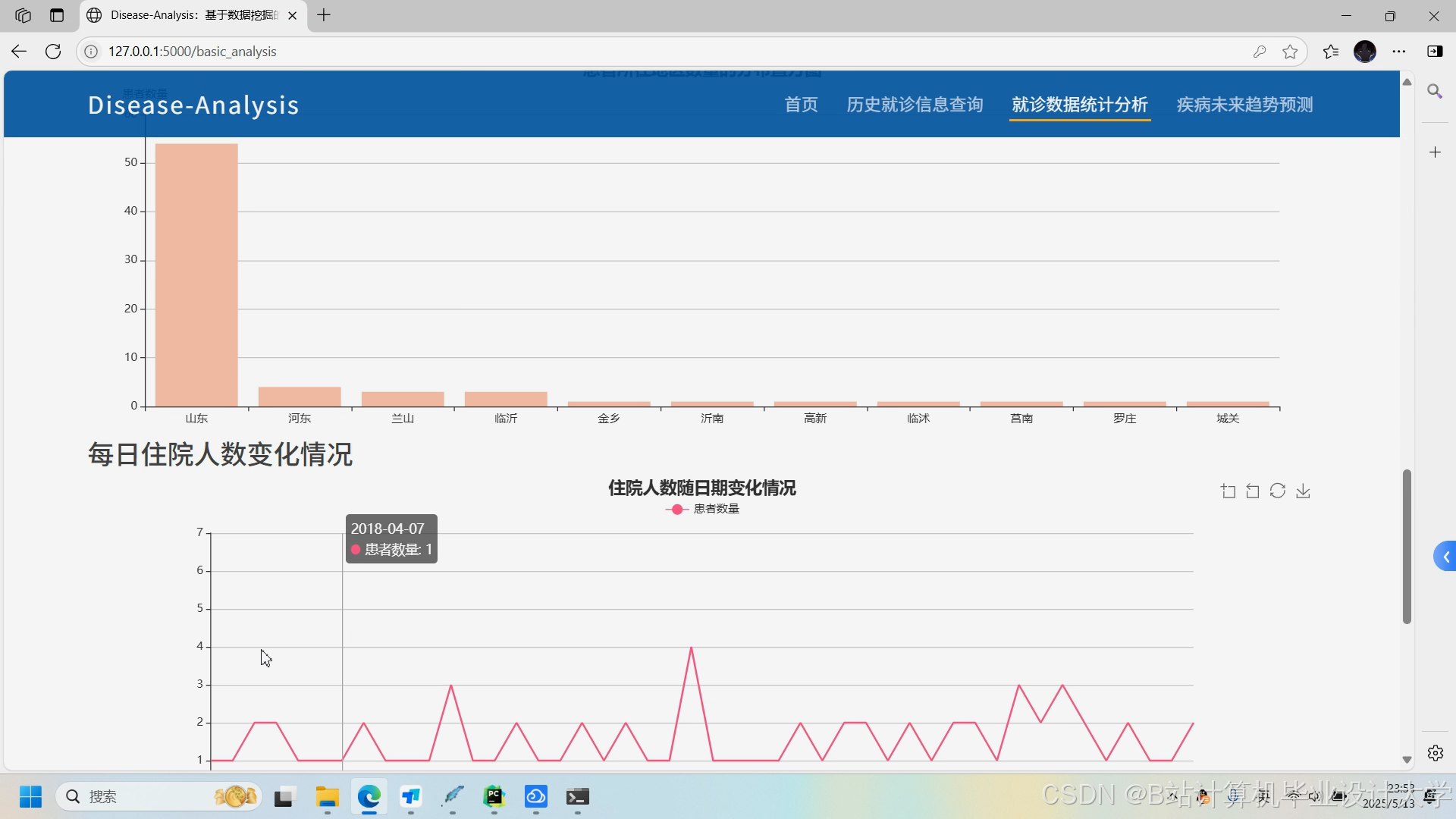
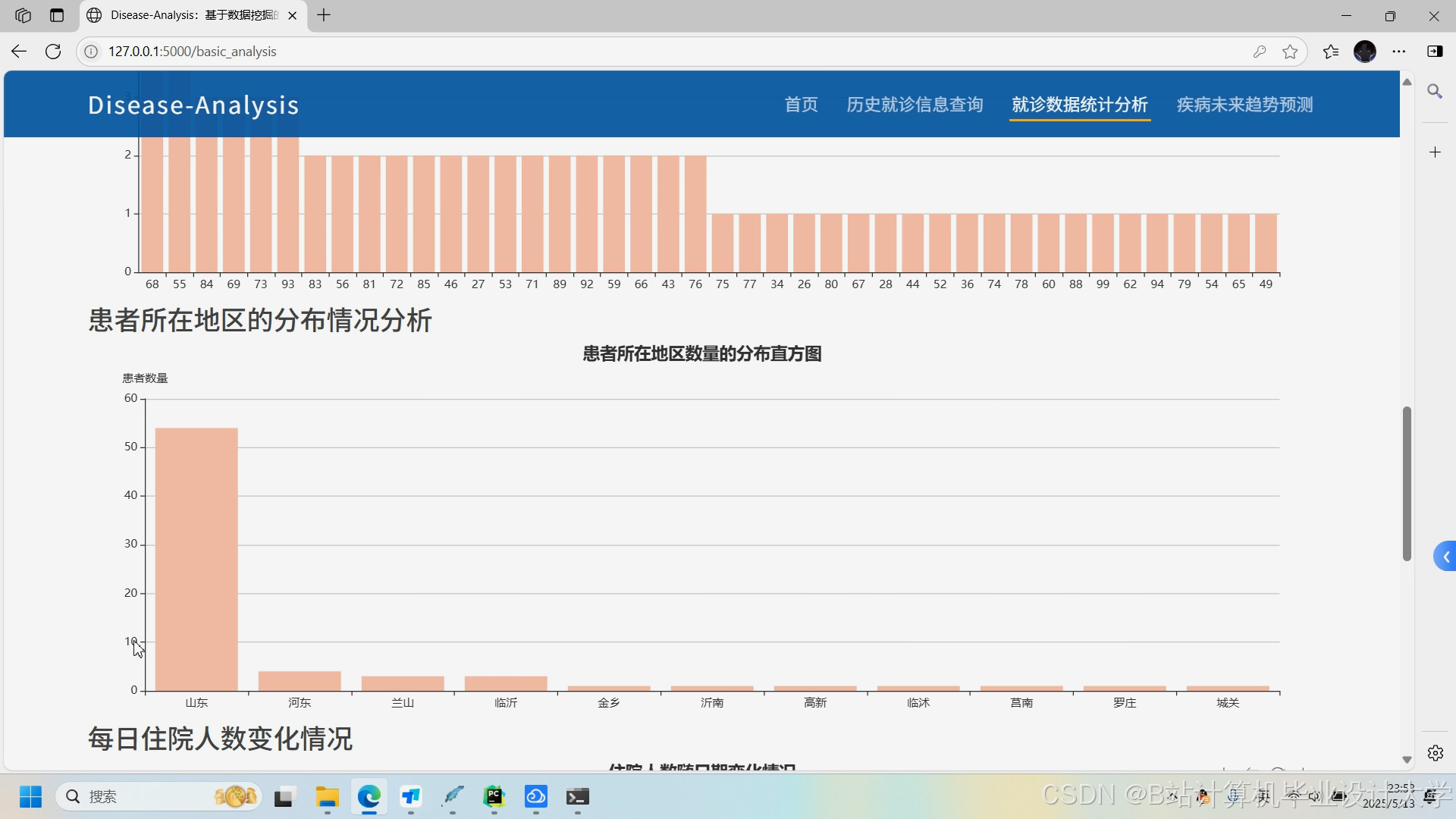
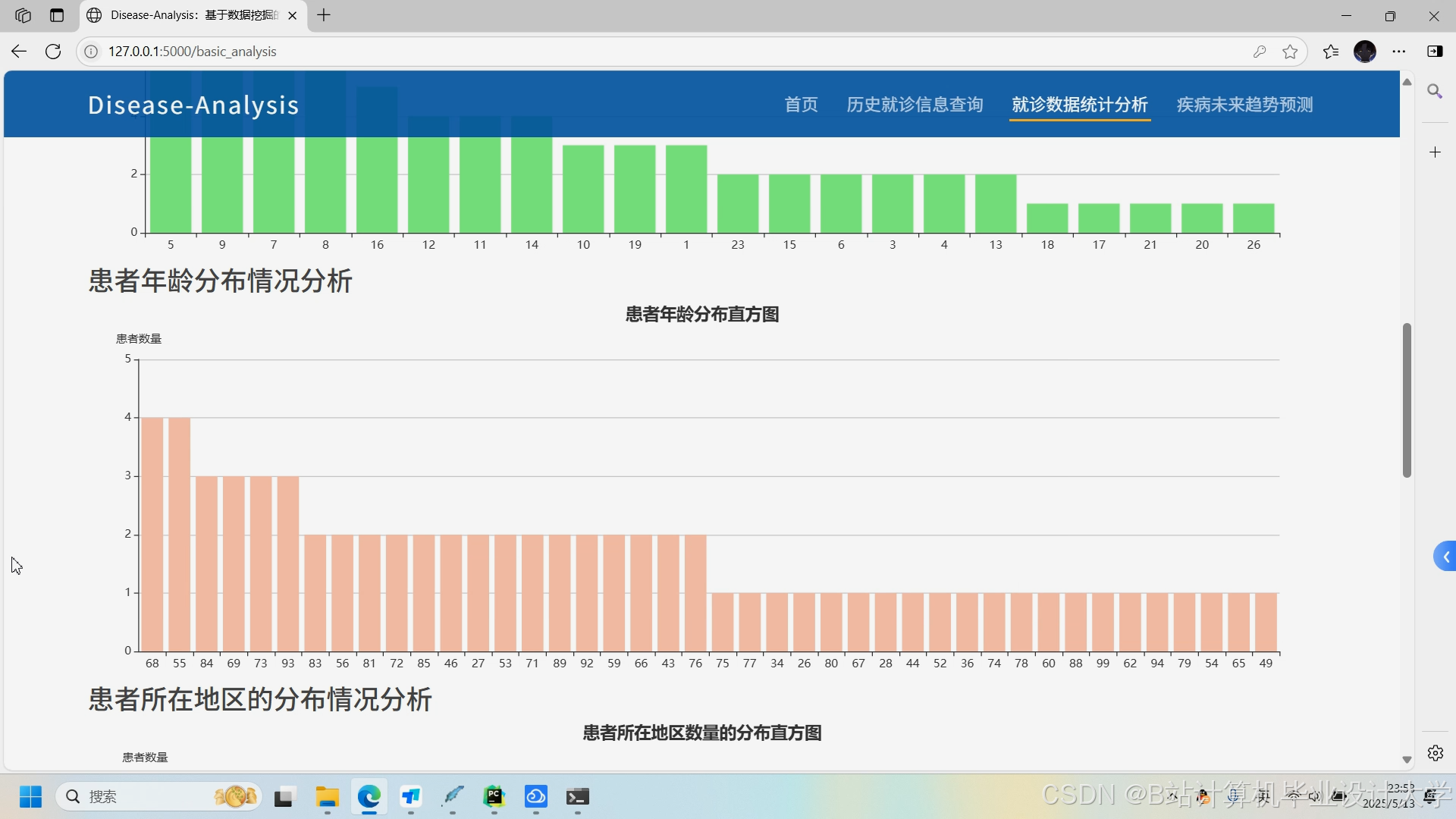
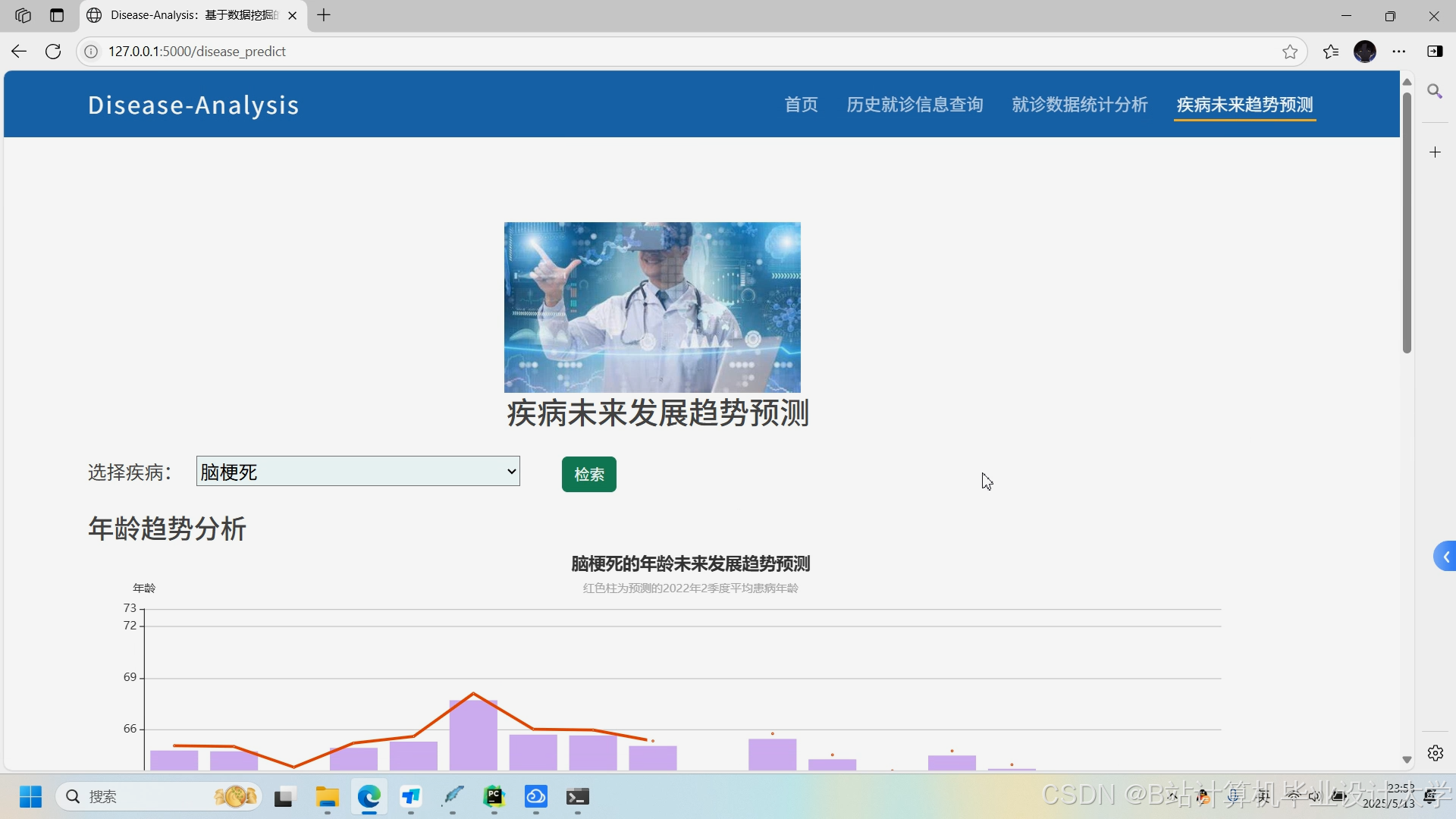
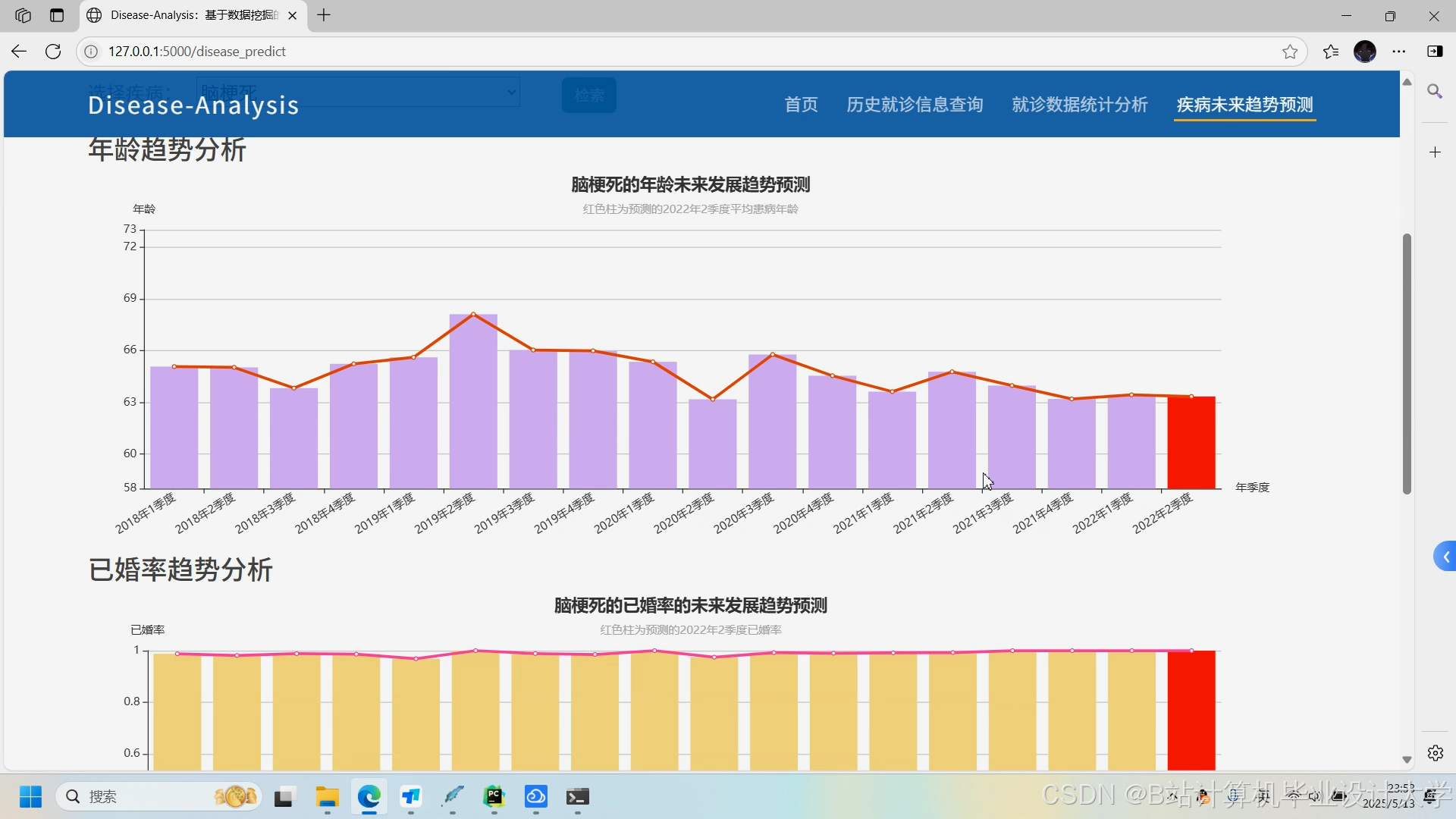
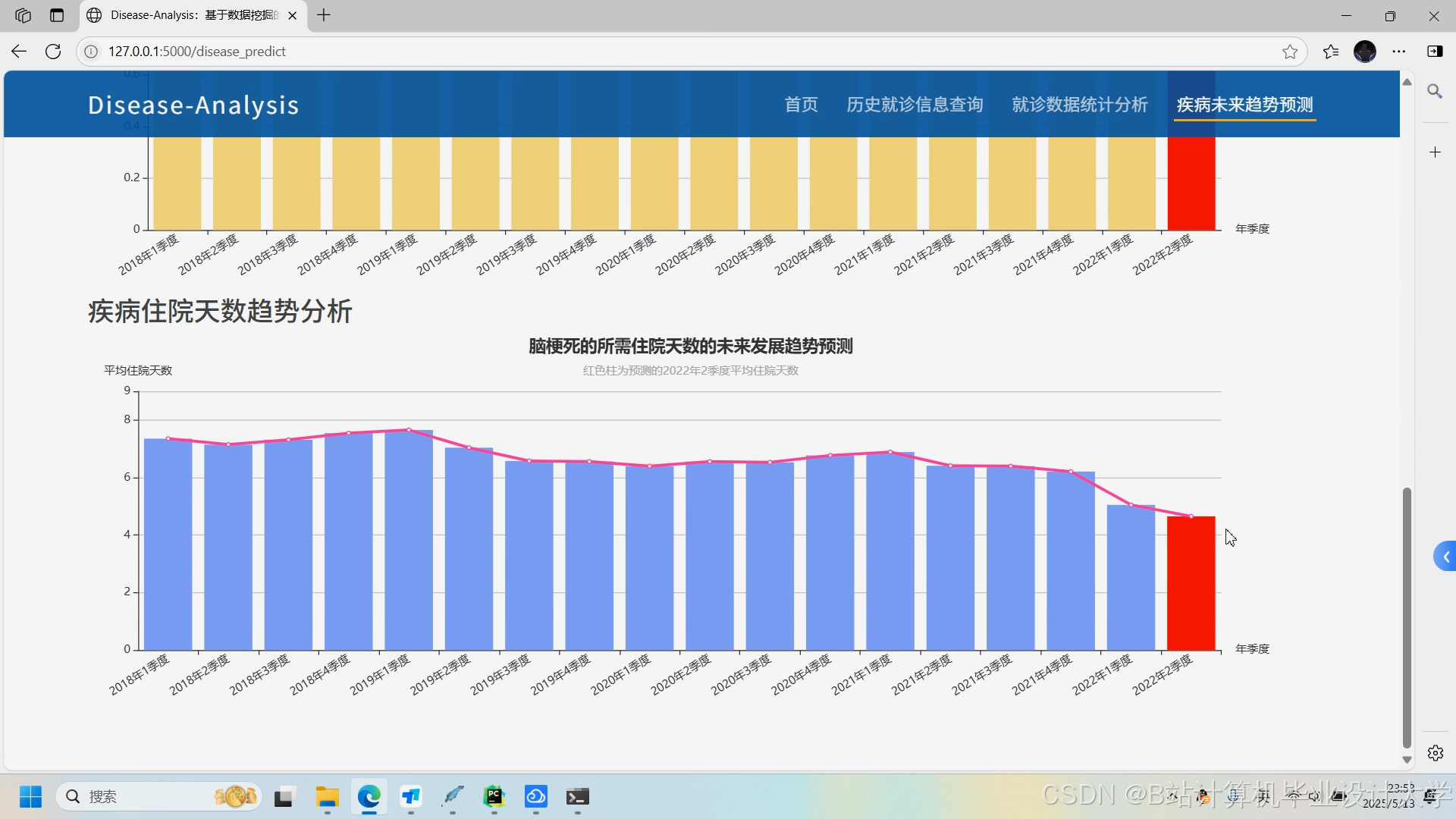
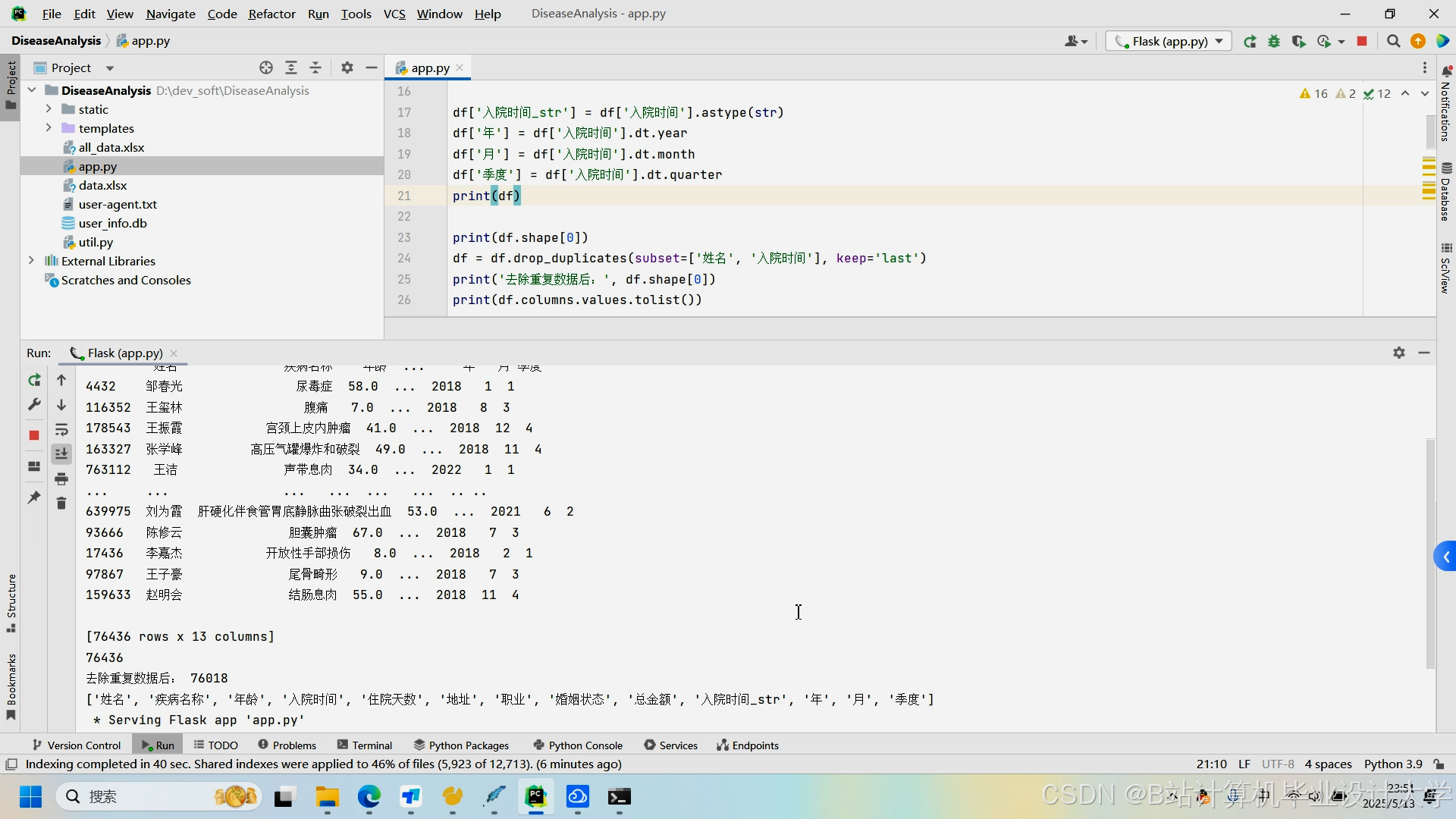
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献902条内容
已为社区贡献902条内容

所有评论(0)