AI大模型应用开发-框架入门:PyTorch 安装、张量(“高级数组”)、简单神经网络搭建(用现成模块)
PyTorch 入门知识点(安装 + 张量 + 简单神经网络搭建),全程步骤清晰、代码可直接复制
一、 第一部分:PyTorch 安装(小白友好,无坑版)
PyTorch 是目前最流行的深度学习框架之一,对新手友好、文档完善,支持快速搭建神经网络,无需复杂配置,直接用pip安装即可。
核心目标
成功安装 PyTorch,验证环境可用,为后续张量操作和网络搭建铺路。
步骤 1:确认 Python 环境
确保你的电脑已安装 Python(3.8~3.11 版本最佳,兼容性最好),打开 cmd 输入以下命令验证:
python --version
- 若显示
Python 3.x.x(x 在 8~11 之间),符合要求;若未安装,先安装对应版本 Python 并配置环境变量。
步骤 2:选择 PyTorch 安装命令(关键:适配 CPU 版本,无需 GPU)
小白入门无需 GPU(显卡要求高、配置复杂),优先安装CPU 版本,足够完成基础学习和简单项目。
- 打开 PyTorch 官网:PyTorch Official Website
- 官网自动适配环境,选择以下配置(小白直接照抄):
PyTorch Build:Stable(稳定版)Your OS:WindowsPackage:PipLanguage:PythonCompute Platform:CPU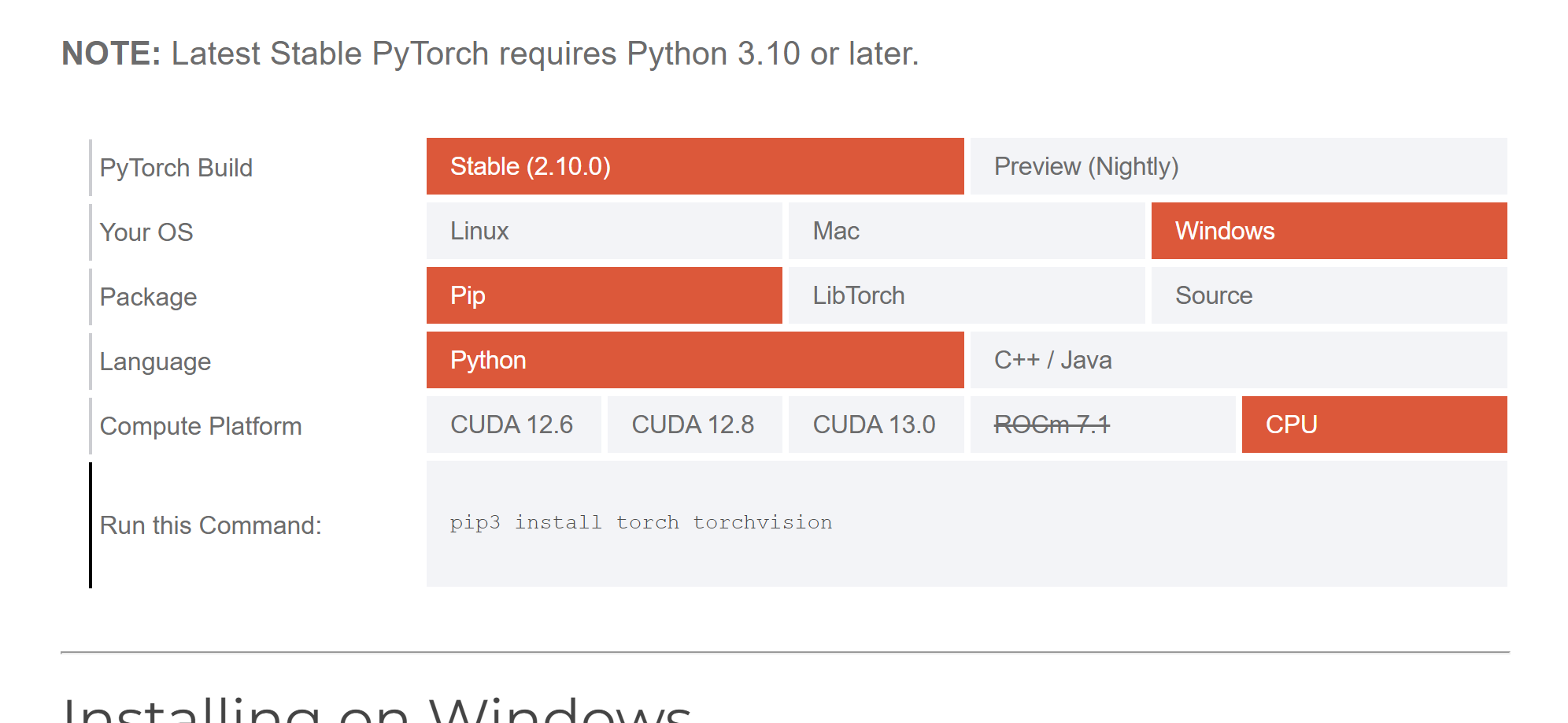
- 复制官网生成的安装命令(如果下载速度慢可使用国内镜像优化版,避免下载超时):
# 核心安装命令(清华镜像源,加速下载)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤 3:执行安装命令
打开 cmd,粘贴上述命令并回车,等待安装完成(约 5~10 分钟,取决于网络速度),无报错即说明安装进度正常。
步骤 4:验证 PyTorch 安装成功
- cmd 中输入
python,进入 Python 交互环境。 - 依次输入以下两行代码,无报错且输出
True,说明安装成功:
import torch
print(torch.cuda.is_available()) # CPU版本输出False,GPU版本输出True,均正常
- 输入
exit()退出 Python 交互环境。
小白常见安装问题解决
- 安装报错「TimeoutError」:网络波动导致,重新执行安装命令即可,或切换到手机热点下载。
- 导入报错「No module named 'torch'」:安装未成功,检查 Python 版本是否符合(3.8~3.11),重新执行安装命令。
- 提示 “缺少依赖”:先升级
pip,命令:python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple,再重新安装 PyTorch。
二、 第二部分:张量(Tensor)—— PyTorch 的 “高级数组”
核心目标
理解张量的本质(高级数组)、常用操作,掌握 “张量是 PyTorch 中数据处理的核心载体”,后续神经网络的输入、计算、输出都是以张量为基础。
1. 小白通俗理解
张量 = PyTorch 中的 “数据容器”,高级版的 Numpy 数组,核心功能是 “存储数据 + 支持深度学习所需的各种计算(如矩阵乘法、梯度计算)”。
- 类比:Numpy 数组是 “普通行李箱”,只能装普通数据;张量是 “智能行李箱”,不仅能装数据,还支持深度学习所需的 “自动称重、自动整理” 等高级功能(梯度计算、GPU 加速)。
- 核心区别:张量支持自动求梯度(神经网络训练的核心需求),Numpy 数组不支持;张量可迁移到 GPU 上加速计算,Numpy 数组不可。
2. 张量的常见维度(小白必懂,无需深究术语)
张量有不同维度,对应不同的数据类型,入门只需掌握 3 种最常用的:
| 张量维度 | 通俗名称 | 对应数据类型 | 示例 |
|---|---|---|---|
| 0 维张量 | 标量 | 单个数值(如 10、3.14) | 一个学生的成绩:95 |
| 1 维张量 | 向量 | 一维数组(如 [1,2,3]) | 一个学生的各科成绩:[85, 90, 79] |
| 2 维张量 | 矩阵 | 二维数组(如 [[1,2],[3,4]]) | 3 个学生的各科成绩:[[85,90],[92,86],[78,93]] |
3. 小白实操:张量的常用操作(直接复制运行)
新建pytorch_tensor_demo.py文件,粘贴以下代码,用python pytorch_tensor_demo.py运行,直观理解张量的创建、转换、基本计算。
python
# 步骤1:导入PyTorch库
import torch
import numpy as np
# 步骤2:创建张量(5种常用方式,小白重点掌握前3种)
print("=== 1. 张量的创建 ===")
# 方式1:从Python列表创建
tensor1 = torch.tensor([1, 2, 3, 4, 5])
print("从列表创建的1维张量:", tensor1)
# 方式2:创建全0张量(常用作初始化)
tensor2 = torch.zeros((2, 3)) # 2行3列的二维张量
print("全0二维张量:\n", tensor2)
# 方式3:创建全1张量
tensor3 = torch.ones((3, 2)) # 3行2列的二维张量
print("全1二维张量:\n", tensor3)
# 方式4:从Numpy数组转换(常用,衔接之前学的Numpy)
np_array = np.array([[6, 7], [8, 9]])
tensor4 = torch.from_numpy(np_array)
print("从Numpy数组转换的张量:\n", tensor4)
# 方式5:创建随机张量(数值在0~1之间,常用作神经网络权重初始化)
tensor5 = torch.rand((2, 2))
print("随机二维张量:\n", tensor5)
# 步骤3:张量的基本属性(查看维度、形状、数据类型)
print("\n=== 2. 张量的基本属性 ===")
print("张量1的维度:", tensor1.dim())
print("张量2的形状(行×列):", tensor2.shape)
print("张量3的数据类型:", tensor3.dtype)
# 步骤4:张量的简单计算(加减乘除,和Numpy数组用法类似)
print("\n=== 3. 张量的简单计算 ===")
a = torch.tensor([10, 20, 30])
b = torch.tensor([1, 2, 3])
print("张量a + 张量b:", a + b)
print("张量a × 张量b:", a * b)
# 1. 将1维张量a转为2维列矩阵
a_2d = a.unsqueeze(dim=1)
# 2. 使用a_2d.mT进行矩阵转置,再做矩阵乘法
print("张量a的矩阵乘法(与自身转置):", torch.matmul(a_2d, a_2d.mT))
# =================================
# 步骤5:张量与Numpy数组的转换(双向转换,衔接旧知识)
print("\n=== 4. 张量与Numpy数组转换 ===")
# 张量 → Numpy数组
tensor_to_np = tensor1.numpy()
print("张量转Numpy数组:", tensor_to_np, type(tensor_to_np))
# Numpy数组 → 张量
np_to_tensor = torch.from_numpy(tensor_to_np)
print("Numpy数组转张量:", np_to_tensor, type(np_to_tensor))4. 运行结果解读
- 终端依次输出不同方式创建的张量,能直观看到 0 维 / 1 维 / 2 维张量的形态差异。
- 张量的属性和计算结果与 Numpy 数组高度相似,小白容易上手,无需重新学习新的语法。
- 重点体会:张量是 PyTorch 中数据的 “标准格式”,后续搭建神经网络时,所有输入数据都必须转换成张量格式。
5. 小白必记:张量的核心作用
- 数据存储:承载神经网络的输入数据(如图片像素、特征值)、权重参数、输出结果。
- 支持高级计算:提供矩阵乘法、转置等深度学习必备的计算功能,比 Numpy 更高效。
- 自动求梯度:这是张量最核心的优势,神经网络训练时,能自动计算参数的梯度,实现权重的自动更新(小白暂时不用深究,知道这个功能即可)。
三、 第三部分:用 PyTorch 搭建简单神经网络(用现成模块,无需手写)
核心目标
掌握 PyTorch 搭建神经网络的固定流程,用现成模块(torch.nn)快速搭建一个简单的二分类神经网络,理解 “层的堆叠” 和 “前向传播”,无需手动编写神经元和激活函数。
1. 搭建前的核心认知(小白必记)
PyTorch 提供了torch.nn模块(神经网络核心模块),封装了所有常用的网络层(如全连接层)、激活函数,小白只需 “像搭积木一样” 堆叠层,即可快速搭建神经网络。
- 核心模块:
torch.nn.Linear(全连接层,最基础的网络层,入门必用)。 - 核心激活函数:
torch.nn.ReLU(隐藏层激活函数)、torch.nn.Sigmoid(二分类输出层激活函数)。 - 固定流程:定义网络类 → 创建网络实例 → 准备张量输入 → 前向传播输出结果。
2. 小白实操:搭建简单神经网络(判断学生是否及格)
新建pytorch_nn_demo.py文件,粘贴以下代码,直接运行,全程注释详细,小白能看懂每一步的作用。
python
# 步骤1:导入所需库
import torch
import torch.nn as nn # 神经网络核心模块
# 步骤2:定义神经网络类(继承nn.Module,固定写法)
# 任务:根据学生的3科成绩(输入),判断是否及格(输出:0=不及格,1=及格)
class SimpleNN(nn.Module):
def __init__(self):
# 调用父类构造函数,固定写法
super(SimpleNN, self).__init__()
# 搭建网络层:像搭积木一样堆叠层(全连接层+激活函数)
# 第一层:输入层 → 隐藏层(输入3个特征→10个神经元,ReLU激活函数)
self.layer1 = nn.Linear(in_features=3, out_features=10) # 全连接层
self.relu = nn.ReLU() # 隐藏层激活函数
# 第二层:隐藏层 → 输出层(10个神经元→1个输出,Sigmoid激活函数,输出0~1概率)
self.layer2 = nn.Linear(in_features=10, out_features=1)
self.sigmoid = nn.Sigmoid() # 二分类输出层激活函数
# 定义前向传播流程(数据的传递路径,固定写法)
def forward(self, x):
# 数据路径:输入x → 第一层全连接 → ReLU激活 → 第二层全连接 → Sigmoid激活 → 输出
out = self.layer1(x)
out = self.relu(out)
out = self.layer2(out)
out = self.sigmoid(out)
return out
# 步骤3:创建神经网络实例(相当于“造一个模型出来”)
model = SimpleNN()
print("=== 简单神经网络结构 ===")
print(model) # 打印网络结构,直观看到层的堆叠
# 步骤4:准备输入数据(转换成张量格式,3科成绩:[语文, 数学, 英语])
# 输入:2个学生的3科成绩(二维张量:2行3列,对应2个样本,3个特征)
input_tensor = torch.tensor([[50, 60, 70], [80, 90, 85]], dtype=torch.float32)
print("\n=== 输入张量(2个学生的3科成绩)===")
print(input_tensor)
# 步骤5:前向传播(将输入数据传入模型,获取输出结果)
output = model(input_tensor)
print("\n=== 模型输出结果(及格概率)===")
print(output)
# 步骤6:结果解读(概率≥0.5判定为及格,<0.5判定为不及格)
print("\n=== 结果解读 ===")
for i, prob in enumerate(output):
result = "及格" if prob >= 0.5 else "不及格"
print(f"第{i+1}个学生,及格概率:{prob.item():.4f},判定结果:{result}")
3. 运行结果解读
- 终端先打印神经网络结构,能看到我们定义的两层全连接层和激活函数,清晰直观。
- 输入 2 个学生的成绩张量,模型通过前向传播输出两个概率值(0~1 之间)。
- 根据概率值判定是否及格,小白能直观看到 “输入→模型→输出” 的完整流程,这就是一个最简单的神经网络的工作过程。
4. 核心知识点解读(小白必懂)
- 网络类定义:必须继承
nn.Module(PyTorch 神经网络的基类),这是固定写法,无需修改。 __init__()方法:用于搭建网络层,nn.Linear(in_features, out_features)是全连接层,in_features是输入特征数,out_features是输出神经元数(隐藏层可自由设置)。forward()方法:定义数据的 “前向传播路径”,即数据在网络中的传递顺序,必须手动编写,这是神经网络的核心。- 激活函数的位置:隐藏层后用
ReLU,输出层后用Sigmoid(二分类任务),和之前学的神经网络基础知识点一致。 - 张量数据类型:输入张量必须是
float32类型(深度学习常用数据类型),否则会报错,用dtype=torch.float32指定即可。
5. 小白避坑指南
- 报错「Expected floating point type but got long」:输入张量的数据类型是整数,未指定
float32,添加dtype=torch.float32即可。 - 报错「size mismatch」:网络层的输入输出特征数不匹配(比如
layer1输出 10 个神经元,layer2输入应该也是 10),检查in_features和out_features的数值是否对应。 - 不理解 “前向传播”:简单理解为 “数据从输入层到输出层的单向传递过程”,就像水流过管道,从入口到出口,中途经过层层处理。
总结
- PyTorch 安装:小白优先安装CPU 版本,用官网提供的
pip命令 + 国内镜像源,验证安装的核心是import torch无报错且torch.cuda.is_available()输出False。 - 张量:PyTorch 的 “高级数组”,核心作用是存储数据 + 支持深度学习计算 + 自动求梯度,常用操作和 Numpy 相似,入门掌握创建、转换、简单计算即可。
- 简单神经网络搭建:固定流程「定义网络类→创建实例→准备张量输入→前向传播」,用
nn.Linear搭建全连接层,ReLU/Sigmoid作为激活函数,像搭积木一样堆叠层即可。 - 关键认知:PyTorch 封装了大量现成模块,小白无需手写神经元和复杂公式,专注于 “网络结构的设计” 和 “数据的传递流程”,为后续深度学习进阶铺路。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)