MySQL 基础教程 - 第八章:索引与性能优化基础
本文介绍了MySQL索引的基础知识,重点讲解了B+树索引结构及其优势,详细阐述了普通索引、唯一索引、主键索引等分类及创建方法。核心内容包括索引设计原则,特别是最左前缀法则的应用,强调组合索引必须从最左列开始匹配才能生效。文章还提供了环境准备SQL脚本,确保读者能通过EXPLAIN命令分析执行计划,帮助识别和优化慢查询问题。适用于MySQL 5.7.44版本,主要针对InnoDB存储引擎的性能优化。
MySQL 基础教程 - 第八章:索引与性能优化基础
摘要:本章将深入探讨 MySQL 数据库性能优化的核心——索引。我们将从底层 B+ 树数据结构讲起,详细介绍索引的分类、创建方法及设计原则(如最左前缀法则、覆盖索引)。同时,通过
EXPLAIN命令深入分析 SQL 执行计划,帮助你识别并解决慢查询问题。本章内容基于 MySQL 5.7.44 版本,重点关注 InnoDB 存储引擎。
8.1 前置准备:数据与索引
为了确保本章的 EXPLAIN 示例能输出预期的执行计划,我们需要确保 users 和 orders 表中包含足够的数据和正确的索引结构。请在开始本章学习前,执行以下 SQL 脚本进行环境校准。
⚠️ 说明:此脚本会尝试补充缺失的字段、索引和数据,不会删除您现有的表结构(除非使用 DROP 重建)。
USE shop_biz;
-- 1. 确保 users 表结构与索引完整
-- 如果 users 表不存在,请参考前面章节创建。这里重点检查索引。
-- 尝试添加索引 (如果已存在可能会报错,可忽略 Duplicate key name 错误,或者使用可视化工具检查)
-- 为了演示 8.4.3 节的 ref 类型查询
ALTER TABLE users ADD INDEX idx_username (username);
-- 2. 确保 orders 表包含 create_time 字段 (用于演示最左前缀)
-- 如果报错 Duplicate column name,说明字段已存在,忽略即可
ALTER TABLE orders ADD COLUMN create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '下单时间';
-- 3. 确保 orders 表包含复合索引 (用于 8.3.1 节)
ALTER TABLE orders ADD INDEX idx_user_time (user_id, create_time);
-- 4. 数据补充 (确保有数据可查)
-- 插入 users 测试数据
INSERT IGNORE INTO users (user_id, username, email, age, gender) VALUES
(1, 'alice', 'alice@example.com', 25, 'female'),
(2, 'bob', 'bob@example.com', 30, 'male'),
(3, 'charlie', 'charlie@example.com', 22, 'male'),
(4, 'david', 'david@example.com', 35, 'male'),
(5, 'eve', 'eve@example.com', 28, 'female');
-- 插入 orders 测试数据
INSERT IGNORE INTO orders (order_id, user_id, total_amount, order_status, create_time) VALUES
(1, 1, 100.00, 1, '2023-10-01 10:00:00'),
(2, 1, 50.00, 1, '2023-10-02 11:00:00'),
(3, 2, 200.00, 0, '2023-10-01 12:00:00'),
(4, 3, 300.00, 2, '2023-10-03 09:00:00'),
(5, 1, 120.00, 1, '2023-10-05 14:00:00');
8.2 索引概述
8.2.1 什么是索引?
索引(Index)是帮助 MySQL 高效获取数据的数据结构。
如果不使用索引,MySQL 必须从第一行记录开始扫描整个表(Full Table Scan),直到找到符合要求的记录。表越大,查询越慢。
使用索引后,MySQL 可以像查字典一样,通过目录快速定位到数据所在的位置。
- 优点:
- 极大提高数据检索效率(O(logN) vs O(N))。
- 通过索引列对数据进行排序,降低数据排序的成本(降低 CPU 消耗)。
- 代价:
- 空间成本:索引本身也是表,需要占用磁盘空间。
- 时间成本:当对表进行 INSERT、UPDATE、DELETE 操作时,MySQL 不仅要保存数据,还要维护索引(如 B+ 树的分裂与合并),会降低写操作的性能。
8.2.2 索引的数据结构:B+ Tree
在 MySQL 的 InnoDB 存储引擎中,索引的底层实现是 B+ 树(多路平衡搜索树)。
-
结构特点:
- 非叶子节点(内部节点)只存储键值(Key)和指针,不存储实际数据行。这使得每个节点能容纳更多的键值,降低树的高度。
- 叶子节点(Leaf Nodes)存储了所有的键值和对应的数据(或主键 ID)。
- 双向链表:所有叶子节点通过指针连接成一个双向链表。这使得范围查询(Range Scan,如
BETWEEN,>,<)非常高效,只需找到起点,然后顺着链表遍历即可。
-
为什么不用二叉树或 Hash?
- 二叉树:树高度太高,导致磁盘 I/O 次数过多(索引通常存储在磁盘上,每一层访问都可能产生一次 I/O)。
- Hash:只适合等值查询(
=),不支持范围查询(>,<),不支持排序。
8.3 索引分类与创建
8.3.1 按功能逻辑分类
-
普通索引 (Normal Index)
- 最基本的索引,没有任何限制。
- 创建:
CREATE INDEX index_name ON table(column);或ALTER TABLE table ADD INDEX index_name(column);
-
唯一索引 (Unique Index)
- 索引列的值必须唯一,但允许有空值(NULL)。
- 创建:
CREATE UNIQUE INDEX index_name ON table(column); - 作用:除了加速查询,更主要用于约束数据的唯一性(如
email字段)。
-
主键索引 (Primary Key)
- 一种特殊的唯一索引,不允许有空值。
- 聚簇索引 (Clustered Index):在 InnoDB 中,主键索引的叶子节点直接存储了整行数据。
- 每个表只能有一个主键。
-
全文索引 (Fulltext Index)
- 用于全文搜索,解决
LIKE '%word%'效率低的问题。 - MySQL 5.7 InnoDB 支持全文索引,但对中文支持需要配置 ngram 解析器(此处不展开,通常建议使用专门的搜索引擎如 ES)。
- 用于全文搜索,解决
-
组合索引 (Composite Index)
- 在多个字段上创建的索引,如
KEY idx_user_time (user_id, create_time)。
- 在多个字段上创建的索引,如
8.3.2 索引管理实战
场景:假设我们需要经常根据 order_status 查询订单。
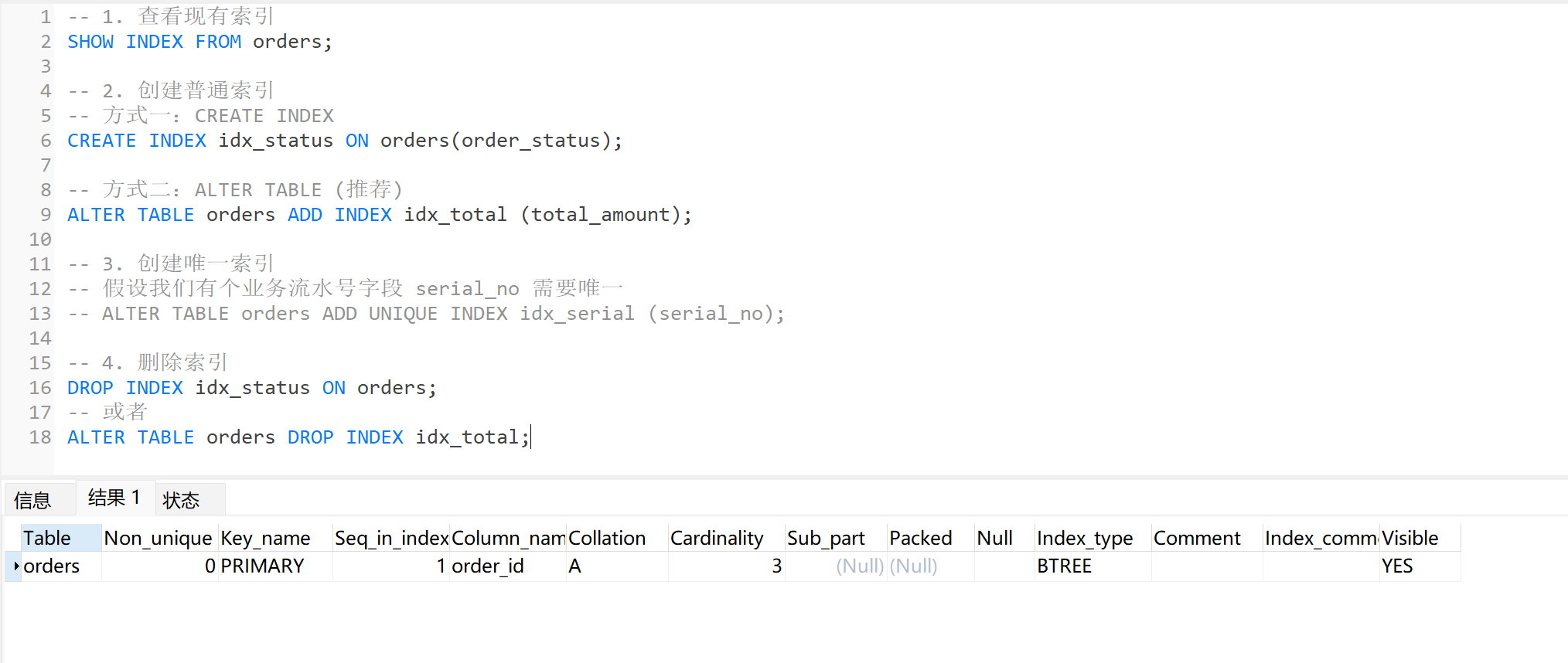
-- 1. 查看现有索引
SHOW INDEX FROM orders;
-- 2. 创建普通索引
-- 方式一:CREATE INDEX
CREATE INDEX idx_status ON orders(order_status);
-- 方式二:ALTER TABLE (推荐)
ALTER TABLE orders ADD INDEX idx_total (total_amount);
-- 3. 创建唯一索引
-- 假设我们有个业务流水号字段 serial_no 需要唯一
-- ALTER TABLE orders ADD UNIQUE INDEX idx_serial (serial_no);
-- 4. 删除索引
DROP INDEX idx_status ON orders;
-- 或者
ALTER TABLE orders DROP INDEX idx_total;
8.4 索引设计原则 (核心)
这是面试和实战中最重要的部分。索引不是越多越好,设计不当反而拖慢系统。
8.4.1 最左前缀法则 (Most Left Prefix)
⚠️ 前置检查:本节演示需要
orders表包含create_time字段和idx_user_time索引。
如果你一直跟随教程操作,请先执行以下 SQL 补充结构:-- 1. 补充 create_time 字段 ALTER TABLE orders ADD COLUMN create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '下单时间'; -- 2. 补充测试数据 (可选,为了演示效果更好) UPDATE orders SET create_time = '2023-10-01 10:00:00' WHERE order_id = 1; -- 3. 创建复合索引 (核心) ALTER TABLE orders ADD INDEX idx_user_time (user_id, create_time);
对于组合索引(例如 idx_user_time (user_id, create_time)),查询时必须从索引的最左边列开始匹配。
-
有效的情况:
-- 1. 查询条件包含最左列 (user_id) SELECT * FROM orders WHERE user_id = 1; -- 走索引 -- 2. 查询条件包含前缀列 (user_id AND create_time) SELECT * FROM orders WHERE user_id = 1 AND create_time > '2023-10-01'; -- 走索引 -
失效的情况:
-- 1. 跳过最左列,直接查第二个列 SELECT * FROM orders WHERE create_time > '2023-10-01'; -- ❌ 不走 idx_user_time 索引(全表扫描),因为不知道 user_id,B+树无法定位 -
范围查询截断:
如果组合索引是(a, b, c),查询WHERE a=1 AND b>2 AND c=3:a用到了索引。b用到了索引(范围查询)。c无法使用索引。因为b是范围,后面的列在 B+ 树中不再有序。
8.4.2 覆盖索引 (Covering Index)
如果一个索引包含(覆盖)了所有需要查询的字段的值,MySQL 就不需要回表(Back Query)去查找整行数据。
-
回表:普通索引(二级索引)的叶子节点存储的是
主键ID。如果查询需要其他字段,MySQL 需先查普通索引拿到 ID,再去主键索引查整行数据。 -
覆盖索引示例:
现有索引idx_user_time (user_id, create_time)。-- 情况 A:需要回表 SELECT * FROM orders WHERE user_id = 1; -- 需要查 * (所有字段),索引里只有 user_id 和 create_time,需要回表查 total_amount 等。 -- 情况 B:覆盖索引 (高性能) SELECT user_id, create_time FROM orders WHERE user_id = 1; -- 只需要查 user_id 和 create_time,这些都在索引里,直接返回,不需要回表。 -- EXPLAIN 输出中 Extra 字段会显示 "Using index"。
8.4.3 索引失效的常见场景
- 在索引列上进行运算或函数操作:
-- ❌ 失效 SELECT * FROM users WHERE YEAR(create_time) = 2023; -- ✅ 优化:改写为范围查询 SELECT * FROM users WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31 23:59:59'; - 字符串不加单引号(类型隐式转换):
如果phone字段是VARCHAR,查询WHERE phone = 13800000000,MySQL 会自动做CAST(phone AS SIGNED),导致全表扫描。 - 模糊查询以 % 开头:
-- ❌ 失效 SELECT * FROM users WHERE username LIKE '%ice'; -- ✅ 有效 (最左匹配) SELECT * FROM users WHERE username LIKE 'ali%'; - OR 连接的条件:
如果WHERE a=1 OR b=2,除非a和b都有索引,否则索引会失效。
8.5 慢查询分析工具:EXPLAIN
EXPLAIN 是查看 SQL 执行计划的神器。它模拟优化器执行 SQL 语句,告诉我们 MySQL 是如何处理你的 SQL 的。
8.5.1 基本用法
EXPLAIN SELECT * FROM users WHERE user_id = 1;
执行后会返回一张表,包含以下关键字段:
8.5.2 关键字段详解
| 字段 | 含义 | 详细解释 |
|---|---|---|
| id | 选择标识符 | select 查询的序列号。id 越大越先执行;id 相同则从上往下执行。 |
| select_type | 查询类型 | SIMPLE (简单查询,不含子查询/UNION)、PRIMARY (主查询)、SUBQUERY (子查询) 等。 |
| type | 访问类型 (重要) | 性能从好到坏:system > const > eq_ref > ref > range > index > ALL |
| possible_keys | 可能用到的索引 | MySQL 猜测可能使用的索引列表。 |
| key | 实际使用的索引 | MySQL 实际决定使用的索引。如果为 NULL,则没用索引。 |
| key_len | 索引长度 | 使用了索引的多少字节。有助于判断组合索引是否被充分利用。 |
| rows | 扫描行数 | 预计扫描的行数(估算值),越小越好。 |
| Extra | 额外信息 | Using index (覆盖索引,好); Using where (需回表过滤); Using filesort (需要额外的排序操作,坏); Using temporary (使用了临时表,极坏)。 |
8.5.3 Type 详解与实战演示
我们通过具体的 SQL 看看 type 的变化。
-
const:通过主键或唯一索引命中一条记录。
EXPLAIN SELECT * FROM users WHERE user_id = 1; -- type: const, key: PRIMARY -
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。
EXPLAIN SELECT * FROM users WHERE username = 'alice'; -- type: ref, key: idx_username -- 注意:如果 username 不是唯一索引,则是 ref;如果是唯一索引,则是 const。 -
range:索引范围扫描,常见于
<, >, BETWEEN, IN。EXPLAIN SELECT * FROM users WHERE user_id > 1; -- type: range, key: PRIMARY -
index:全索引扫描 (Full Index Scan)。扫描遍历索引树,通常比 ALL 快,因为索引文件通常比数据文件小。
-- 查询 id (主键) 和 username (索引列),不需要回表,但需要扫描整个 username 索引树 EXPLAIN SELECT user_id, username FROM users; -- type: index, Extra: Using index -
ALL:全表扫描 (Full Table Scan)。最差的情况。
-- gender 字段没有索引 (虽然建表时可能有默认,假设这里没建或区分度低被优化器忽略) -- 或者查询非索引列 EXPLAIN SELECT * FROM users WHERE age = 25; -- type: ALL (假设 age 字段未建索引)
8.5.4 实战案例:Filesort 优化
假设我们要查询订单,按 total_amount 排序。
-- 场景:没有索引时的排序
EXPLAIN SELECT * FROM orders ORDER BY total_amount;
-- type: ALL, Extra: Using filesort
-- 说明 MySQL 无法利用索引完成排序,必须在内存中(或磁盘)进行额外的排序操作,性能差。
优化:添加索引。
ALTER TABLE orders ADD INDEX idx_amount (total_amount);
EXPLAIN SELECT total_amount FROM orders ORDER BY total_amount;
-- type: index, Extra: Using index
-- 此时直接读取索引树(本身有序),无需额外排序。
8.6 总结
- 索引是双刃剑:能极大提升读性能,但会降低写性能并占用空间。
- 设计原则:
- 高频查询的字段建索引。
- 区分度高(唯一性强)的字段适合建索引(如 ID、手机号);区分度低(如性别、状态)通常不适合。
- 利用最左前缀和覆盖索引减少回表。
- 分析习惯:写完复杂 SQL 后,习惯性用
EXPLAIN看一下执行计划,确保没有出现ALL或Using filesort(在数据量大时)。
下一章,我们将进入数据库事务的世界,探讨如何保证数据的一致性与隔离性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)