Linux文本处理命令详解:从cat/nano到管道符,一篇吃透终端基础工具


前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、cat指令
cat 是 concatenate(连接)的缩写,是 Linux/Unix 系统中最基础的文件操作命令之一,核心作用是连接文件内容并打印到终端(标准输出),同时也支持创建新文件、追加内容等实用功能。
一、基本语法
cat [可选参数] [文件1] [文件2] ...
- [可选参数]:控制输出格式或操作行为(非必选);
- [文件…]:要操作的文件路径(可指定多个,也可省略以从标准输入读取内容)。
二、核心用法与示例
1. 最基础:查看文件内容
直接输出文件的全部内容到终端,适合查看小文件(大文件会刷屏,推荐用 less/more 分页查看)。
# 查看当前目录下的 notes.txt 文件内容
cat notes.txt
补充:文件 = 属性 + 内容,ls -l查看属性(文件大小,文件类型,创建时间等),cat查看内容
2. 合并多个文件内容
将多个文件的内容按顺序连接,并输出到终端或重定向到新文件。
# 把 file1.txt 和 file2.txt 的内容合并,输出到 combined.txt(覆盖已有文件)
cat file1.txt file2.txt > combined.txt
# 合并后追加到已有文件末尾(不覆盖原有内容)
cat file3.txt >> combined.txt
3. 创建新文件
通过标准输入(键盘)快速创建小文件,输入内容后按 Ctrl+D 结束输入。
# 创建新文件 todo.txt 并输入内容
cat > todo.txt
# 输入内容:比如 "1. 学习Linux指令\n2. 整理笔记"
# 按 Ctrl+D 保存并退出
4. 追加内容到已有文件
和创建文件类似,但用 >> 符号,内容会追加到文件末尾而非覆盖。
# 向 todo.txt 追加新内容
cat >> todo.txt
# 输入:"3. 写技术博客"
# 按 Ctrl+D 保存
三、常用参数
二、nano指令
再补充一个nano指令,nano是 Linux 新手、需要快速在终端编辑小文件 / 配置文件的首选工具,适合修改系统配置、编写简单脚本、编辑文本笔记等场景。
保存之后按回车自动退出
一、基本语法
nano [可选参数] [文件名/文件路径]
- 无参数直接跟文件名:若文件存在则打开该文件,若文件不存在则创建新文件并打开;
- 可选参数:控制编辑模式(如只读、语法高亮、关闭自动换行等);
- 支持绝对路径 / 相对路径:比如编辑系统配置文件
sudo nano /etc/hosts,编辑当前目录文件nano test.txt。
基础打开 / 创建示例
# 创建并打开当前目录的 newfile.txt(文件不存在)
nano newfile.txt
# 打开已存在的系统配置文件(需管理员权限,否则无法保存)
sudo nano /etc/profile
# 打开文件并直接定位到第10行(编辑大文件时实用)
nano +10 bigfile.txt
二、核心编辑操作
nano 无需模式切换,打开文件后直接进入可编辑状态,和 Windows 记事本、Mac 文本编辑的操作逻辑一致,可以认为是一个Linux下的记事本。输入、删除、光标移动(方向键 / 鼠标点击)都可直接操作,核心只需记住保存、退出等关键快捷键(终端底部会默认显示常用快捷键,新手看底部即可)。
该软件也是存在于系统路径下的
若是没有,下面是centOS和ubentu下的安装指令
yum/apt install -y nano
🔑 核心快捷键(nano 操作核心,底部提示可直接看)
nano 的快捷键以 ^(代表 Ctrl 键)、M(代表 Alt 键) 开头,无记忆负担,以下是最常用的核心快捷键(终端底部默认显示前 4 个,掌握这几个就能完成 90% 的操作):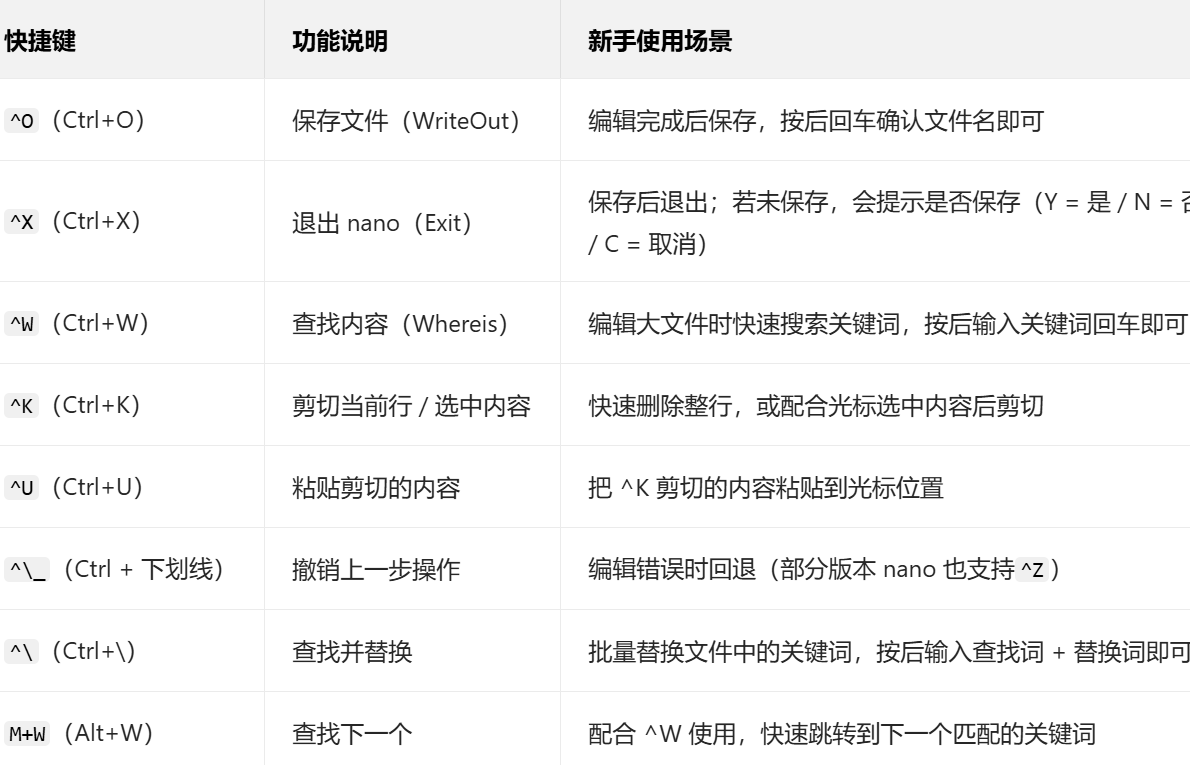
新手编辑完整流程(以编辑 test.txt 为例)
- 执行
nano test.txt打开 / 创建文件,直接输入内容(方向键移动光标,Backspace 删除); - 编辑完成按
^O保存,终端底部提示File Name to Write: test.txt,直接回车确认; - 按
^X退出 nano,回到终端命令行; - 若编辑中误操作,按
^\_撤销,若需删除整行按^K。
三、常用实用参数
- +行号 打开文件并直接定位到指定行
nano +20 config.conf(定位到 20 行) - -w 关闭自动换行
nano -w script.sh(编辑代码 / 配置文件时,避免自动换行导致格式错乱) - -v 以只读模式打开文件
nano -v /etc/fstab(仅查看文件,防止误编辑) - -s 语法 开启语法高亮(支持
sh/c/python/html等)nano -s sh shell.sh(shell 脚本语法高亮)、nano -s py test.py(Python 语法高亮) - -l 显示行号
nano -l code.c(编辑代码时方便定位行号)
参数组合示例
# 编辑Python文件,开启行号+语法高亮+关闭自动换行
nano -l -s py -w demo.py
三、tac指令
tac 是 cat 的反向拼写,核心作用是反向读取文件内容并输出到终端:
- cat 是从文件第一行到最后一行正向显示内容;
- tac 则是从文件最后一行到第一行反向显示内容。
它的设计初衷是解决 “快速查看末尾内容” 的场景(比如日志文件最新条目在末尾),无需翻页就能直接从最后一行开始看,是 cat 的互补工具。
二、基本语法
tac [可选参数] [文件1] [文件2] ...
- 无参数 + 文件名:反向显示单个文件的内容;
- 多个文件:按指定顺序,先反向显示第一个文件,再反向显示第二个,以此类推;
- 省略文件:从标准输入(键盘 / 管道)读取内容并反向输出。
三、核心用法与示例
1. 基础用法:反向查看单个文件
这是 tac 最常用的场景,尤其适合日志文件(最新日志在末尾)。
示例1:
# 准备测试文件(先创建一个有3行内容的test.txt)
echo -e "第一行内容\n第二行内容\n第三行内容" > test.txt
# 用cat正向查看(对比参考)
cat test.txt
# 输出:
# 第一行内容
# 第二行内容
# 第三行内容
# 用tac反向查看
tac test.txt
# 输出:
# 第三行内容
# 第二行内容
# 第一行内容
示例2: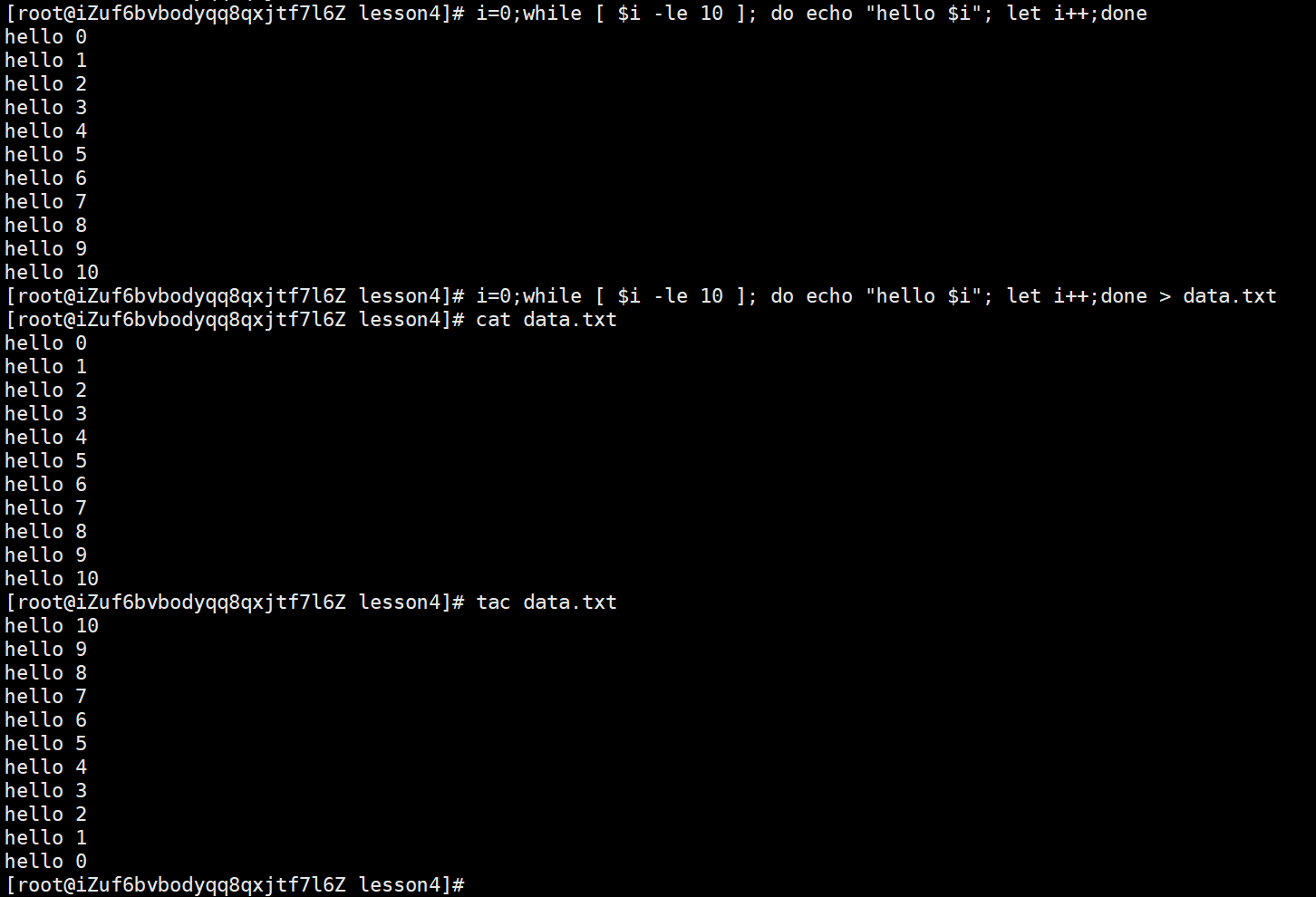
i=0;while [ $i -le 10 ]; do echo "hello $i"; let i++;done
这是一条终端单行 while 循环脚本,用分号分隔多个命令,直接在终端执行:
i=0:初始化变量 i 的值为 0while [ $i -le 10 ]:循环判断条件-
[ ]是 Linux 内置的 test 命令简写
-
-le是 “小于等于” 的比较运算符,意思是当 i ≤ 10 时,继续执行循环
do echo "hello $i":循环体,每次执行时输出 hello 和当前变量 i 的值(如 hello 0、hello 1)let i++:让变量 i 自增 1(等价于i=$((i+1))),避免无限循环done:结束循环
执行效果:终端会逐行输出 hello 0 到 hello 10。
i=0;while [ $i -le 10 ]; do echo "hello $i"; let i++;done > data.txt
这条命令在原循环基础上,增加了重定向符号 >:
> data.txt:将循环原本要输出到终端的内容,覆盖写入到 data.txt 文件中-
- 如果 data.txt 不存在,会自动创建
-
- 如果 data.txt 已存在,会清空原有内容再写入
执行效果:终端没有直接输出,所有 hello 0 到 hello 10 的内容都被保存到了 data.txt 文件里。
2. 反向查看多个文件
tac 会按文件顺序,分别反向显示每个文件的内容:
# 创建两个测试文件
echo -e "a1\na2" > file1.txt
echo -e "b1\nb2" > file2.txt
# 反向查看file1和file2
tac file1.txt file2.txt
# 输出:
# a2
# a1
# b2
# b1
3. 自定义分隔符(-s 参数)
tac 默认以换行符 \n 作为行分隔符,-s 参数可指定自定义分隔符,适合非换行分隔的文本(如 CSV、自定义格式文件):
# 创建以逗号分隔的文件
echo "北京,上海,广州,深圳" > city.txt
# 按逗号分隔反向显示
tac -s "," city.txt
# 输出:深圳,广州,上海,北京
四、more 和 less 指令
cat/tac 会一次性输出文件全部内容,查看大文件(如日志、配置文件)时会瞬间刷屏,无法逐页阅读;而 more 和 less 是分页阅读器,将文件内容按屏幕大小拆分,支持逐页 / 逐行查看,是查看大文件的首选工具:
- more:基础版分页工具,仅支持向下翻页,功能简单、上手即会;
- less:增强版分页工具(被称为 “less is more”),支持上下自由翻页、搜索、跳转,几乎兼容 more 所有功能,是 Linux 中最常用的文件查看工具。
一、more 指令:基础分页查看
1. 核心定义
more 是 “按页显示文件内容” 的基础工具,只能向下浏览(无法回退到上一页),适合快速查看大文件的前半部分,或不需要回翻的场景。
2. 基本语法
more [可选参数] 文件名/文件路径
3. 基础用法示例
# 分页查看大日志文件
more /var/log/syslog
# 从第20行开始分页查看文件(跳过前19行)
more +20 large_file.txt
# 指定每页显示15行(默认按屏幕高度显示)
more -15 config.conf
4. 核心操作快捷键(查看时按对应按键)
more 无模式切换,查看过程中按以下按键即可操作,记住核心的 3 个就够用: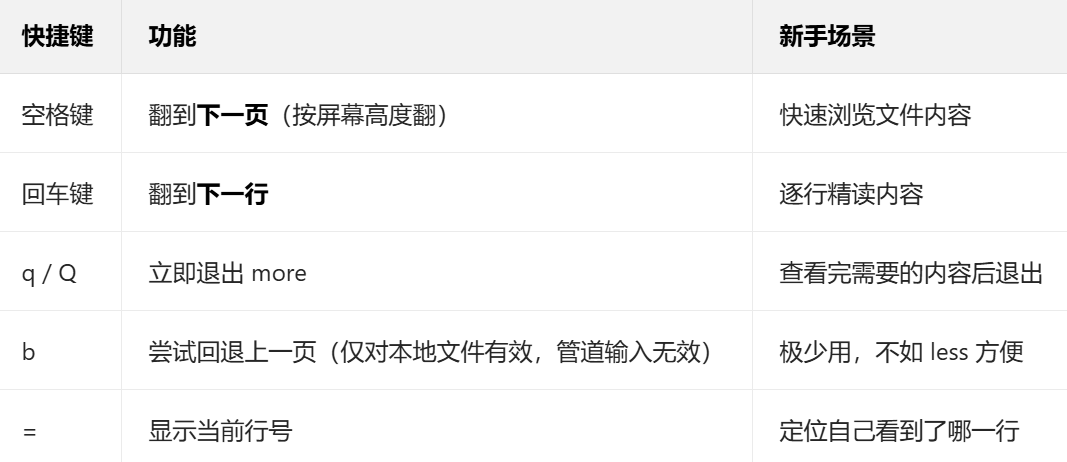
二、less 指令:增强版分页查看(推荐优先使用)
1. 核心定义
less 是 more 的升级版,核心优势是:
- 支持上下自由翻页(向前 / 向后);
- 无需加载整个文件(打开超大文件时比 more/cat 快得多);
- 支持关键词搜索、行号显示、内容跳转;
- 兼容 more 的所有操作,是 Linux 中查看文件的 “主力工具”。
2. 基本语法
less [可选参数] 文件名/文件路径
3. 基础用法示例
# 分页查看超大日志文件(推荐用法)
less /var/log/messages
# 查看文件并显示行号(调试/配置文件必备)
less -N code.py
# 从第50行开始查看,且截断超长行(避免换行错乱)
less -N -S +50 big_data.log
# 查看压缩文件(less 可直接解析 gz 压缩包)
less log.tar.gz
4. 核心操作快捷键(重点掌握,覆盖 90% 场景)
less 操作更灵活,以下是最常用的快捷键,无记忆负担,按需求记即可: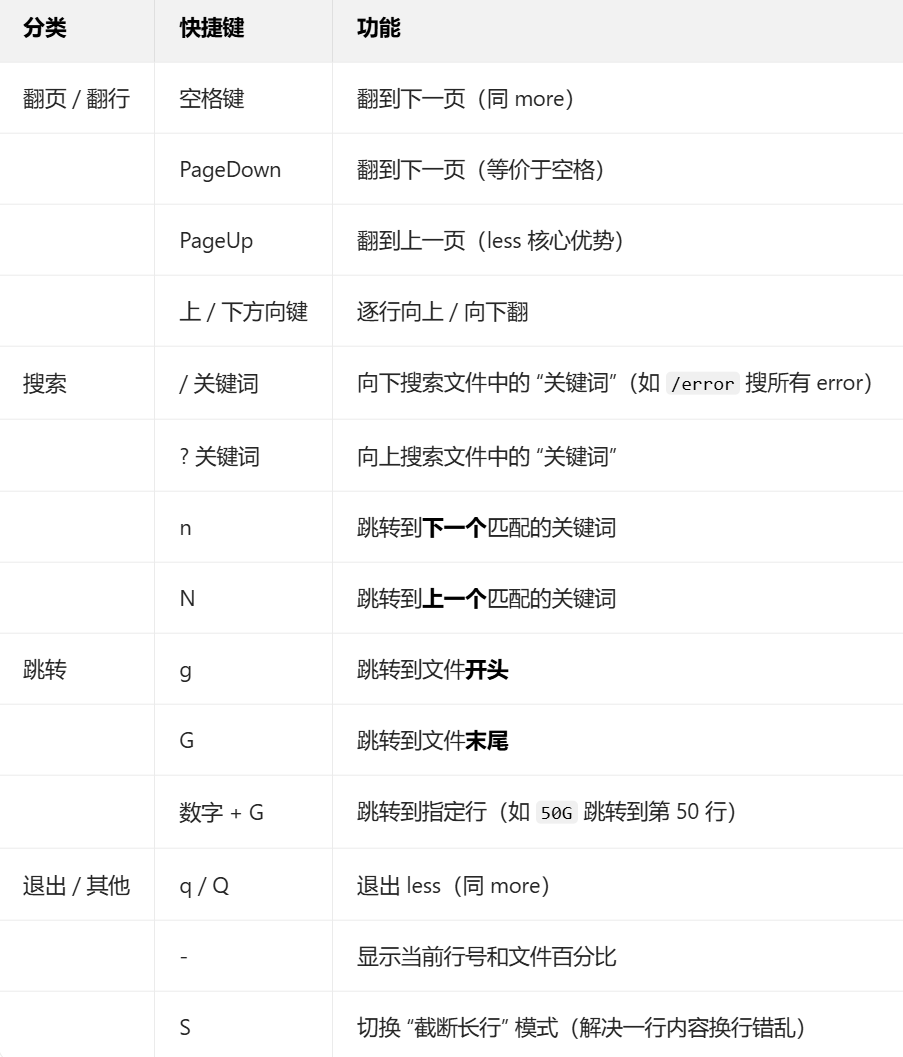
三、more vs less 核心区别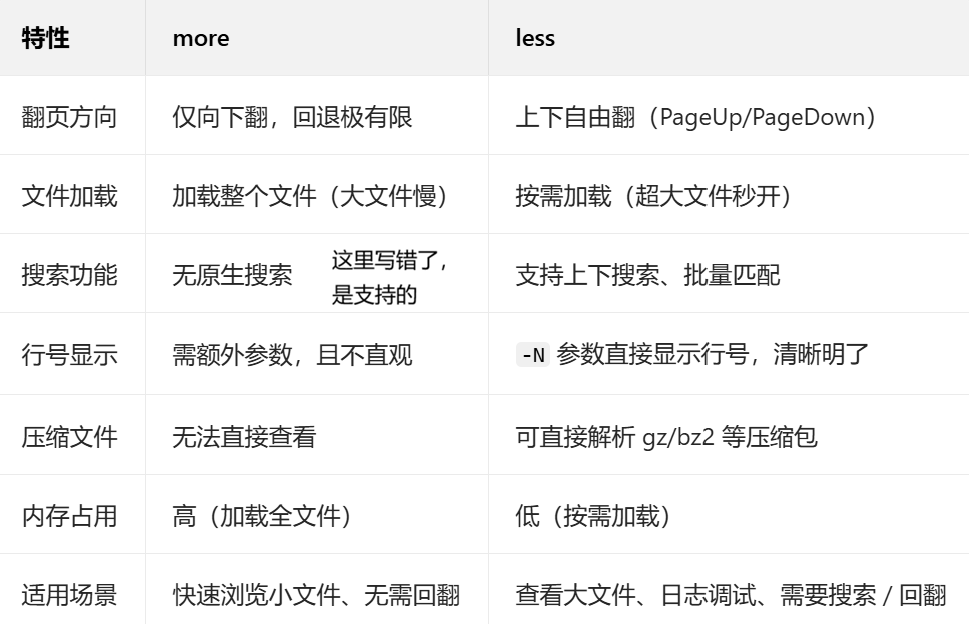
五、head 和 tail 指令
head 和 tail 是 Linux/Unix 系统中功能互补的文件内容查看工具,二者都无需加载整个文件,仅读取目标部分内容,处理大文件效率极高:
- head:专注查看文件开头部分(默认前 10 行),用于快速预览文件格式、开头内容。
tail:专注查看文件结尾部分(默认最后 10 行),是监控日志、追踪最新内容的核心工具。
一、head 指令:查看文件开头
核心功能
快速提取文件的前 N 行内容,默认显示前 10 行,适合预览文件格式、确认开头内容,或配合其他命令过滤输出。
基本语法
head [可选参数] [文件1 文件2 ...]
参数 作用 示例
-n N / -N 显示前 N 行(-n 可省略,直接写 -N) head -n 5 log.txt / head -5 log.txt
-n -N 显示除最后 N 行之外的所有内容 head -n -3 large_file.txt
-v 强制显示文件名(单文件也显示分隔符) head -v -4 config.conf
-q 隐藏文件名(多文件时默认显示分隔符,用 -q 关闭) head -q file1.txt file2.txt
实用示例
# 1. 默认查看前10行
head access.log
# 2. 指定查看前8行
head -8 access.log
# 3. 查看除最后2行之外的所有内容
head -n -2 access.log
# 4. 配合管道:查看当前目录前3个文件的详细信息(管道下面介绍)
ls -l | head -3
二、tail 指令:查看文件结尾(含实时监控)
核心功能
提取文件的最后 N 行内容,默认显示最后 10 行,最核心的扩展功能是实时监控文件更新(-f 参数),是排查日志、追踪程序输出的必备工具。
基本语法
tail [可选参数] [文件1 文件2 ...]
参数 作用 示例
-n N / -N 显示最后 N 行(-n 可省略,直接写 -N) tail -n 6 syslog / tail -6 syslog
-n +N 从第 N 行开始显示到文件末尾 tail -n +20 data.csv(显示第 20 行及之后的内容)
-f 实时追踪文件更新(文件新增内容会自动输出到终端) tail -f /var/log/messages(监控系统日志)
-F 增强版实时追踪(即使文件被删除 / 重建,也能继续监控新文件) tail -F /var/log/nginx/access.log(适合日志轮转场景)
-v / -q 显示 / 隐藏文件名(同 head) tail -v -5 error.log
实用示例
# 1. 默认查看最后10行
tail error.log
# 2. 指定查看最后5行
tail -5 error.log
# 3. 实时监控系统日志(核心用法)
tail -f /var/log/syslog
# 4. 从第15行开始显示到文件末尾
tail -n +15 report.txt
# 5. 配合管道:查看最近3个活跃进程(管道下面介绍)
ps aux | tail -3
六、管道 |
前面都是查文件的头尾,若现在想要查文件的中间(例如5000行到5010行,现在共10w行),有两个解决方案
方案一:重定向
用head将文件(data.txt)内10w行的文件前5011行的内容提取出来再重定向到一个临时文件内,然后再用tail提取整个5010行的后10行,就可以提出中间部分
head -5011 data.txt
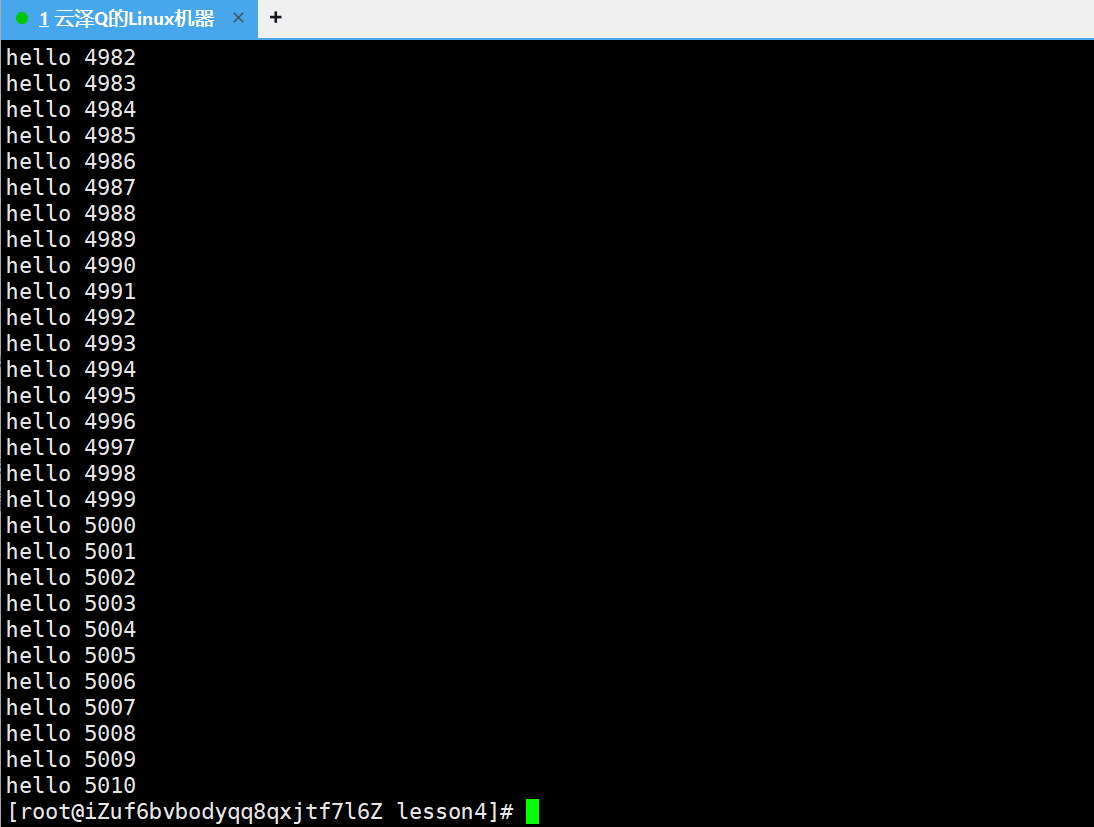
head -5011 data.txt > temp.txt
cat temp.txt
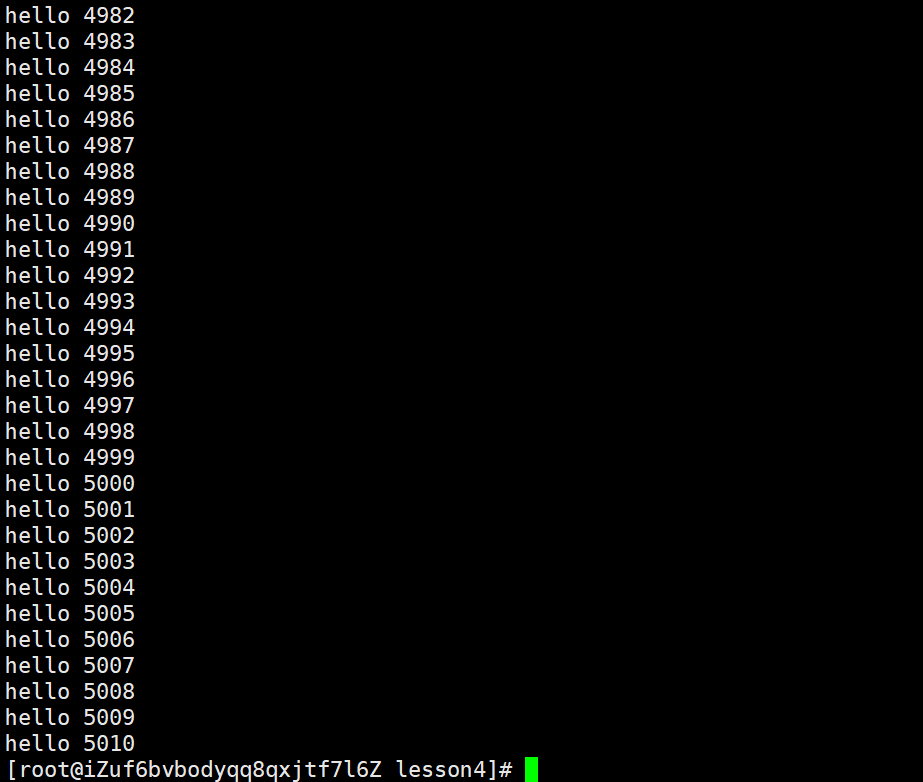
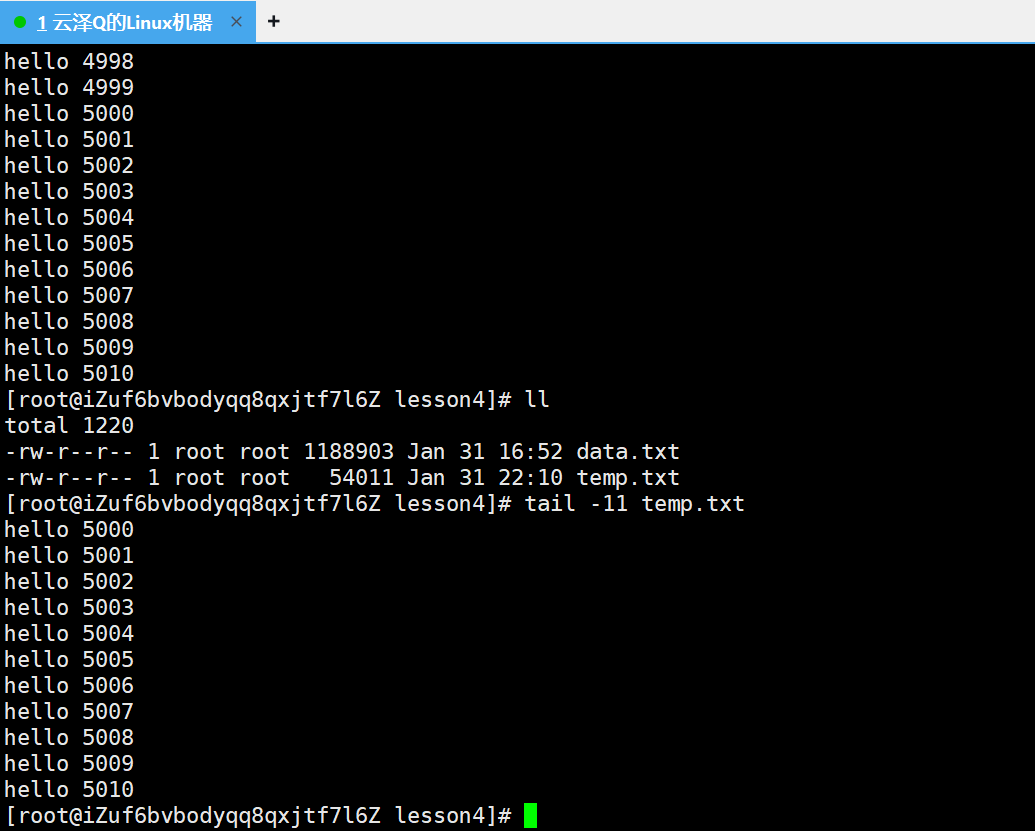
这样就利用重定向借助中间文件 temp.txt 将5000-5010行的内容拿出来了。
但是这样的作法就不优雅了,用起来很繁琐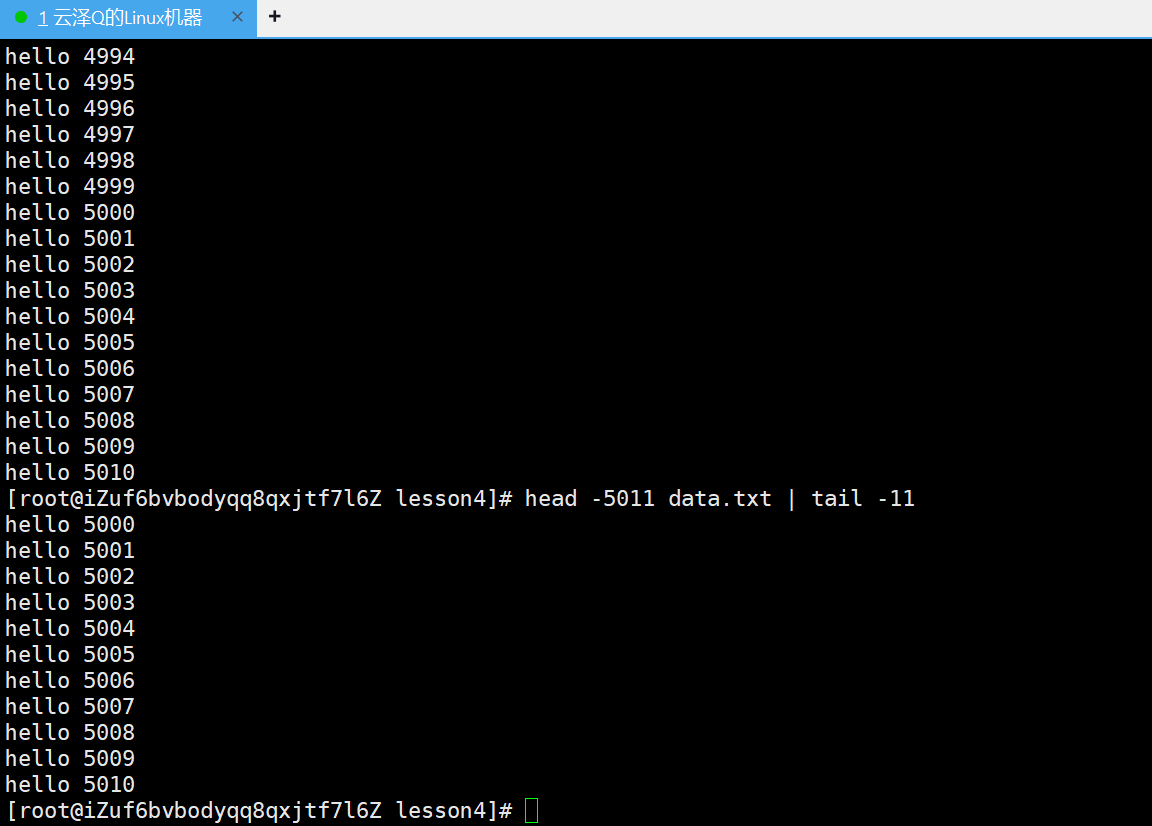
图中通过管道(|)达成了一样的效果,下面来介绍一下管道
因为Linux下一切皆文件,所以管道的本质可以将其认为是一个内存级的文件(管道文件),管道并非磁盘上的真实文件,而是 Linux 内核在内存中创建的临时缓冲区(大小通常为 4K/8K),所有数据传递都在内存中完成,无磁盘 IO(方案一新建的 temp.txt 是一个磁盘上的文件,关机重启该文件还在),效率极高。
1. 管道的官方定义
管道符(竖线 |)是 Linux I/O 重定向的重要实现,核心作用是:将前一个命令的「标准输出(stdout)」,直接作为后一个命令的「标准输入(stdin)」,实现多个命令的数据流无缝联动,全程无临时文件中转,所有操作均在系统内存中完成。
简单理解:管道就是命令之间的 “数据传送带”,前一个命令的输出,不用保存到文件,直接传给下一个命令处理。
2. 管道的底层工作原理
当你执行 命令1 | 命令2 时,Linux 内核会做 3 件事:
- 创建一个管道缓冲区(内存中的临时区域,大小固定,一般为 4K/8K);
- 让命令1的标准输出不再打印到终端,而是写入这个管道缓冲区;
- 让命令2的标准输入不再从键盘读取,而是读取这个管道缓冲区的内容;
- 当命令1执行结束 / 管道缓冲区满,命令2会实时处理缓冲区数据,处理完后释放缓冲区,全程无磁盘 IO。
核心特点:管道是单向流动的(只能前→后),且是面向字节流的(数据按顺序传递,无格式限制)。
前面通过管道将5000-5010行内容提取出来之后如果想要逆置的话,也可以继续使用管道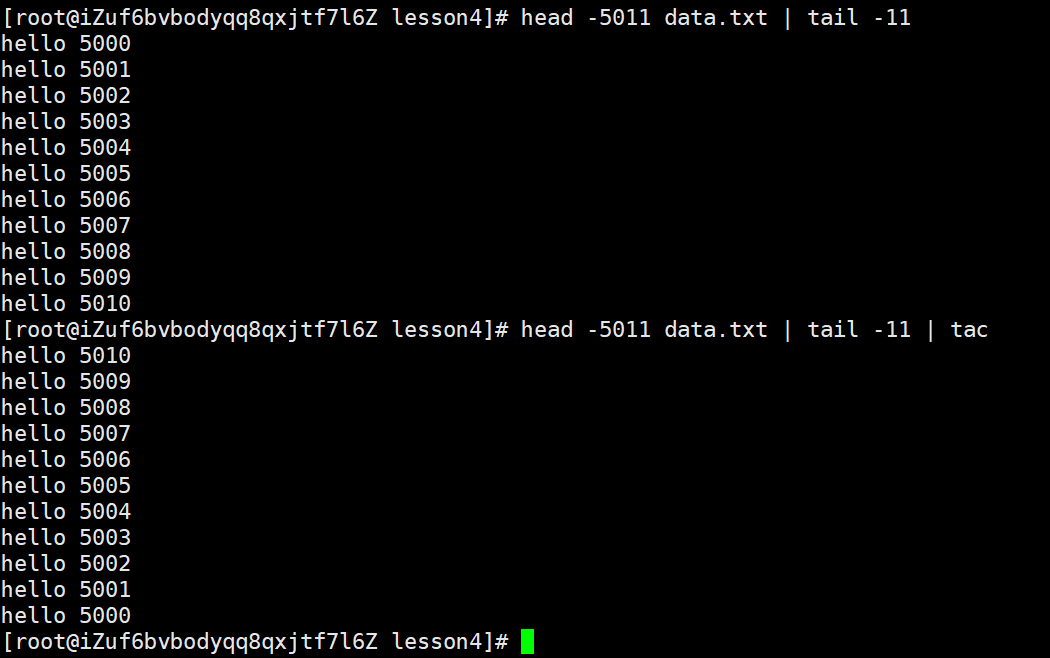
但是现在又想将4001 - 5000的内容打印出来,逆置之后再逐行阅读,依旧可以使用管道实现
还可以统计当前输出的文件内的行数,图中 wc 是 Word Count 的缩写,-l 就是 line 的意思,按行统计
head 提取5001行,tail 取这其中1000行,是没有问题的
管道又分为匿名管道和命名管道,匿名管道就是上面终端里的竖线 |,,是我们日常用得最多的管道形式。
- 特点:
-
- 随进程生命周期存在:命令执行结束后,管道会被内核自动回收,无残留。
-
- 无需提前创建,直接用 | 衔接命令即可(没有名字,路径不完整,该文件在文件系统中不直接存在,是个内存级文件,无法查找)。
命名管道 是用 mkfifo 命令创建一个磁盘上的 “管道文件”(但数据仍在内存中,带有完整路径,可以查找),比如 mkfifo fifo。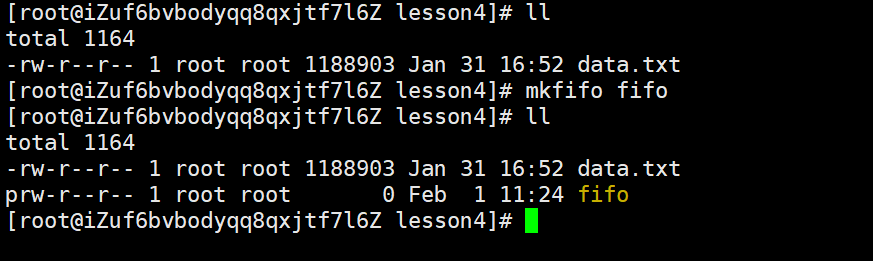
可以看到其是一种新的文件类型,以p(管道的英文单词:pipe)开头
- 特点:
-
- 是持久化的文件节点,即使没有进程使用,也会保留在磁盘上(直到被删除)。
二者的数据传递逻辑(内存级、单向、入口出口)完全一致,仅存在形式不同。
管道文件的级联不仅可以在一个终端下实现,命名管道还可以在多个终端下进行骚操作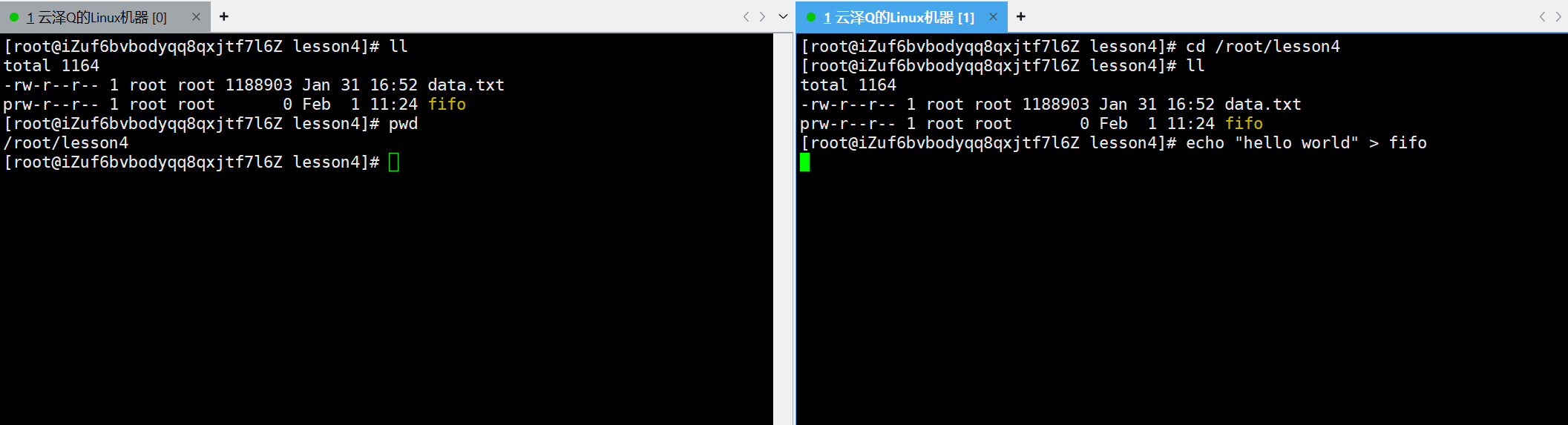
这里在新终端中将 hello world 重定向到管道文件中,新终端中的echo就卡在下一行了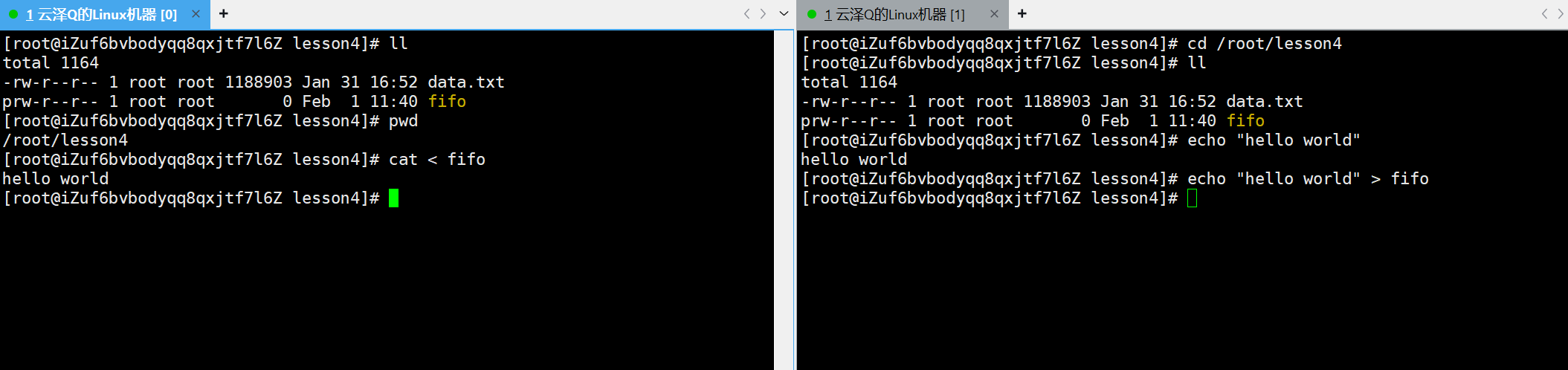
在旧终端中使用 cat 输入重定向,从 fifo 管道中读取数据,此时旧终端就拿到新终端的内容了
基于这个结论就可以玩出其他骚操作了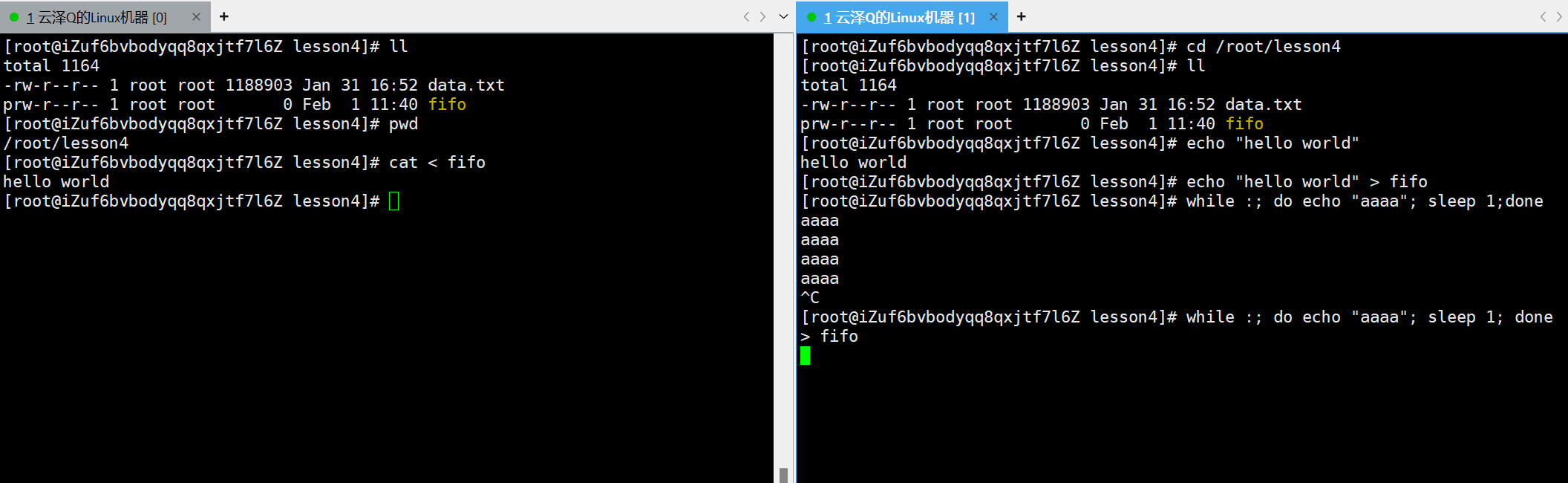
下图新终端中指令while :是一种死循环,do done是循环,整体指令的意思就是每隔一秒向显示器打印一条 aaaa 的消息,接下来继续把该消息重定向到管道内
另一侧旧终端继续用cat从管道中读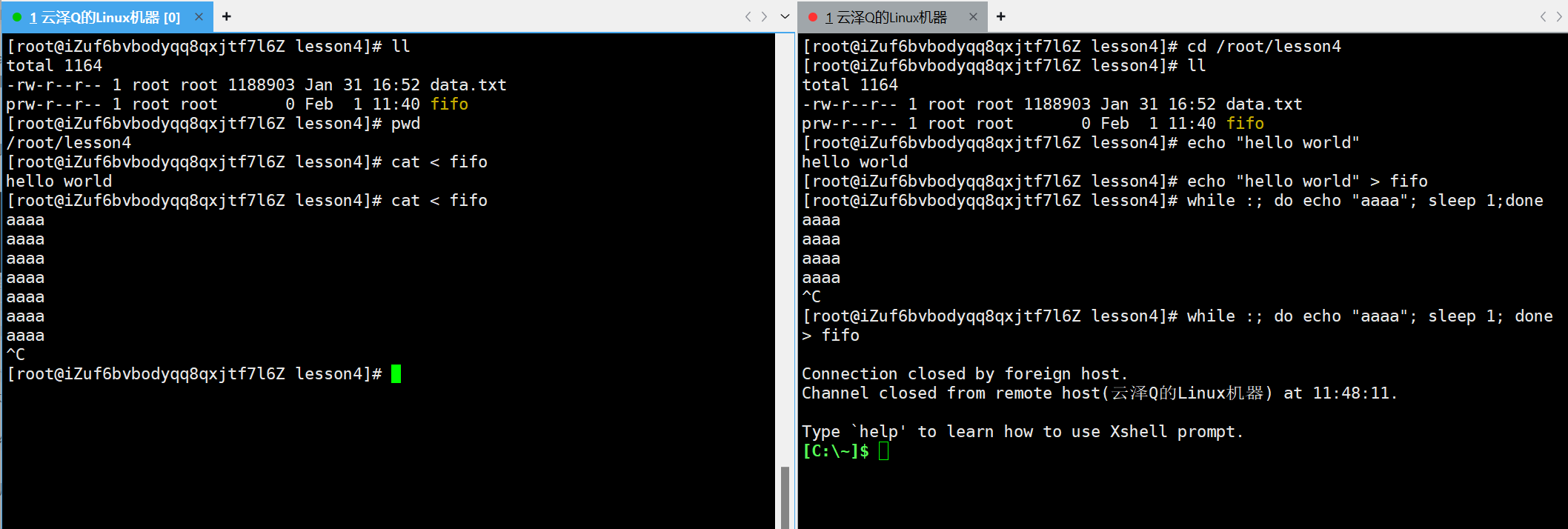
此时,新终端输出的内容就输出到旧终端中了
结语


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)