论文阅读:Bert: Pre-training of deep bidirectional transformers for language understanding
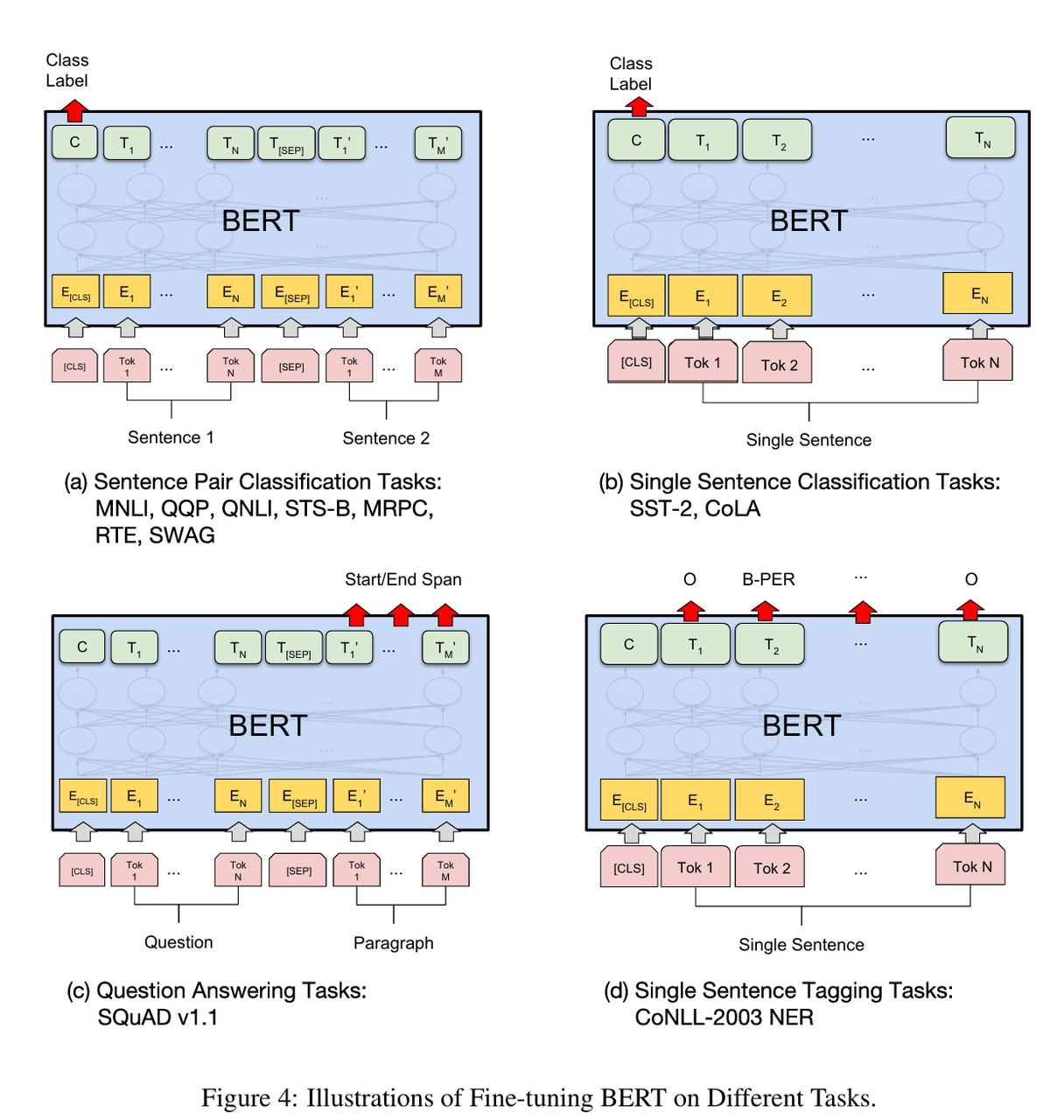
将特定任务的句子对(如假设-前提、问题-段落)作为句子 A 和 B 输入,对于序列标注、问答等token粒度的任务,将 Token 表示输入到输出层,对于情感分析等分类任务,将[CLS]的表示输入到输出层。作者认为现有技术限制了预训练表示的能力,主要局限在于标准语言模型的单向性,例如,OpenAI GPT 使用从左到右的架构,Transformer中的每个Token只能关注其之前的Token,这种
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019: 4171-4186.
引言
作者认为现有技术限制了预训练表示的能力,主要局限在于标准语言模型的单向性,例如,OpenAI GPT 使用从左到右的架构,Transformer中的每个Token只能关注其之前的Token,这种限制对句子级任务是次优的,对于需要结合双向上下文的Token级任务(如问答)甚至是极其有害的。
为了解决上述问题,论文提出了BERT,受完形填空(Cloze task)启发,BERT 通过使用 MLM 预训练目标来缓解单向性约束。MLM 随机掩盖输入中的一些 Token,目标是仅根据上下文预测被掩盖词的原始词汇 ID。这使得模型能够融合左右两侧的上下文,预训练深层双向 Transformer,除了 MLM,BERT 还使用“下一句预测”任务来联合预训练文本对表示。
BERT详解
BERT 的训练过程分为两步,且在不同任务间使用统一的架构。具体而言,在预训练阶段,BERT在大量无标记数据上训练模型,学习通用的语言表示;在微调阶段,使用相同的预训练参数初始化模型,然后在下游任务的标记数据上微调所有参数。
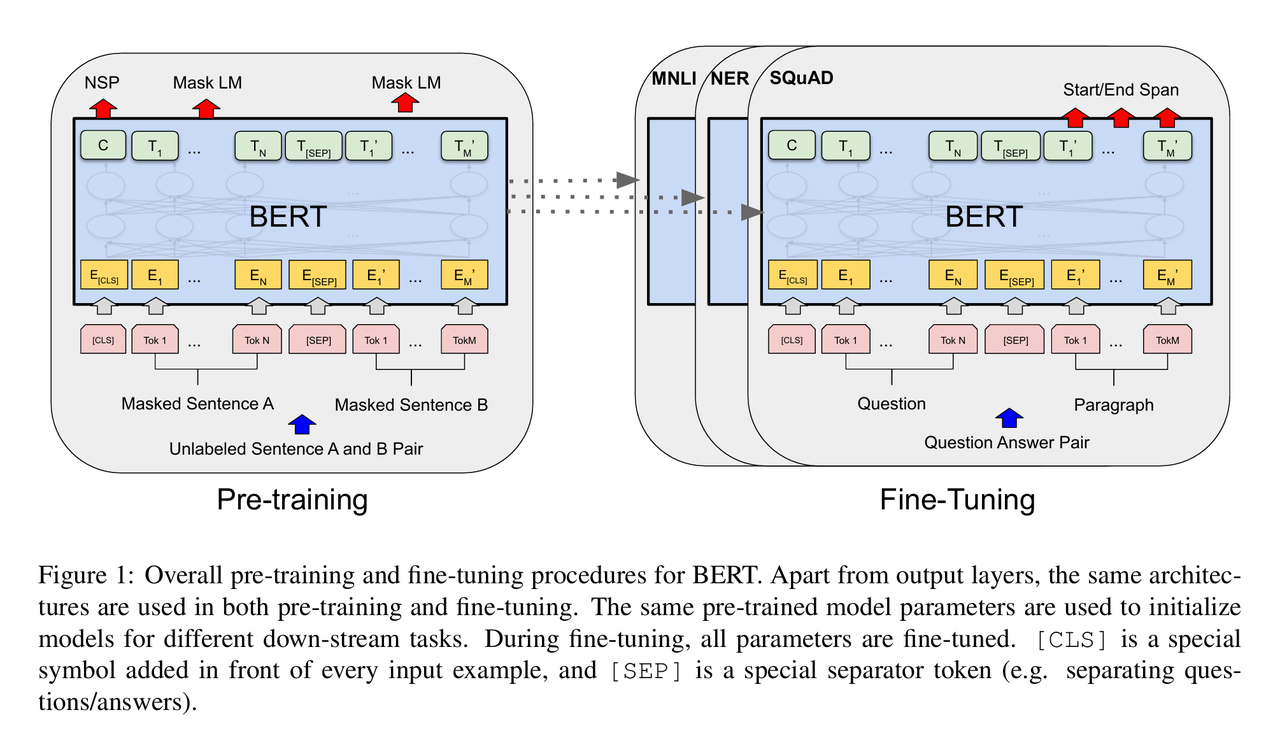
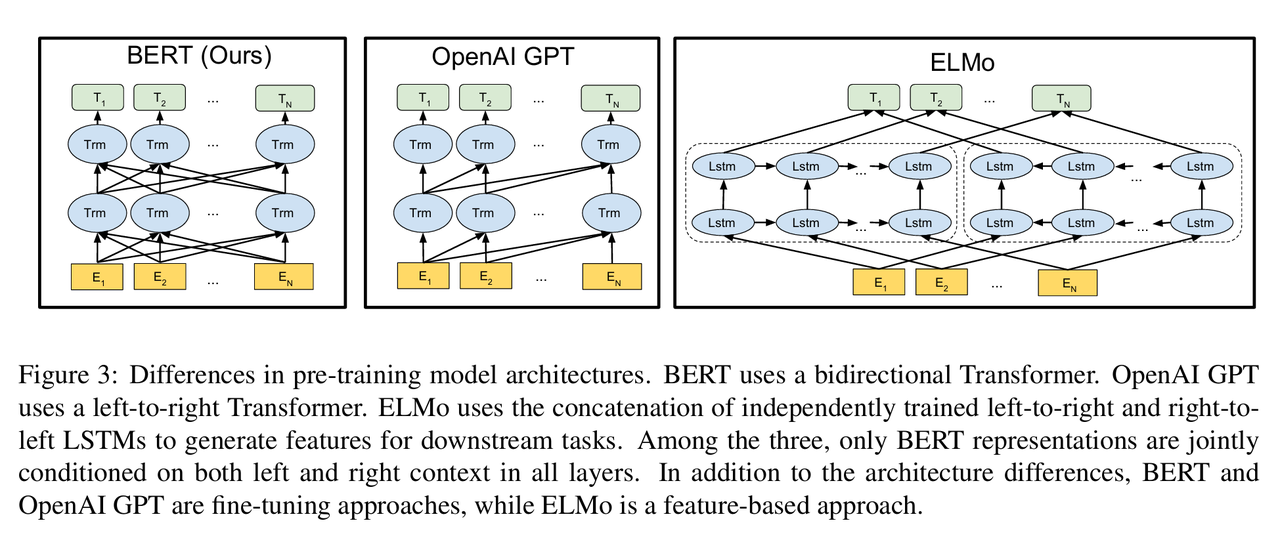
BERT 基于多层双向 Transformer 编码器【这是与GPT的关键区别】,BERT 使用双向自注意力机制(Bidirectional Self-Attention),而 GPT 使用受限的从左到右的自注意力机制。
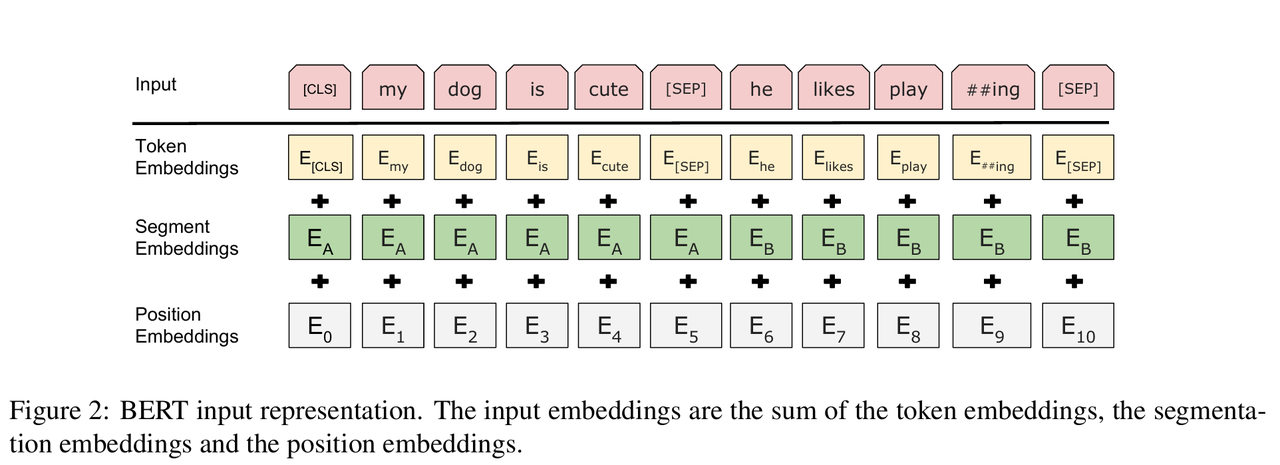
在输入/输出表示方面,BERT 的输入设计使其能够在一个 Token 序列中明确地表示单个句子或句子对,每个序列的第一个 Token 始终是专门的分类 Token。其最终的隐藏状态被用作分类任务的聚合序列表示,记为[CLS],进一步,引入专门的token[SEP]用于分隔两个句子。对于给定的 Token,其输入表示由三部分相加而成:一是词向量token embedding,二是段向量segment embedding(属于哪个句子),三是position embedding(token在序列中的位置)
BERT 不使用传统的从左到右或从右到左的语言模型,而是通过两个无监督任务进行预训练。其一是掩码语言模型(MLM)任务,为了训练深度双向表示,BERT 随机掩盖输入中的部分 Token,然后预测这些被掩盖的 Token(每个序列中的15%),为了减轻预训练(有 [MASK])和微调(无 [MASK])之间的不匹配,BERT 并不总是用[MASK] 替换被选中的词,80%会替换成[MASK],另有10%替换为随机token,而10%不变。其二是下一句预测任务(NSP),这是一个二分类任务。在预训练样本中,选择句子A和B,50%的时候B是A的下一句,而另外的时候就是随机句子。
微调过程非常直接,BERT 使用自注意力机制将两个阶段(编码文本对)统一起来,有效地包含了两个句子之间的双向交叉注意力。将特定任务的句子对(如假设-前提、问题-段落)作为句子 A 和 B 输入,对于序列标注、问答等token粒度的任务,将 Token 表示输入到输出层,对于情感分析等分类任务,将[CLS]的表示输入到输出层。
这部分需要补充的内容:
1.关于segment embedding,需要澄清的是bert的输入分为一个/两个**部分**(注意这个部分可以是若干个句子),Segment Embedding 是一个可学习的向量,用于标识当前 Token 属于“句子 A”还是“句子 B”。如果是两个句子(如预训练时的 NSP 任务,或微调时的问答/推理任务),第一个句子所有 Token 使用EA,第二个句子使用EB;如果是单个句子(如情感分析),通常只使用EA。
2.关于position embedding,针对输入 BERT 的整个“序列”进行计数的,不会因为换了句子(碰到[SEP])而重置
3.关于MLM的loss计算:是一个多分类问题,只针对被 Mask 的位置计算 Loss,使用CE loss计算对比预测概率与原始真实词的 One-hot 编码,对于[CLS] the man [MASK] to the store [SEP],找到经过bert之后,里面[MASK]位置得到的东西,然后分别和mask之前这个地方的内容进行比对并计算损失。
4.关于NSP的loss计算:实际上就是取[CLS]过分类头进行计算
消融实验
NSP 对于理解句子间关系至关重要;GPT等LTR 模型在所有任务上的表现都比 MLM 模型差,LTR 模型的 Token 级隐藏状态无法利用右侧上下文,导致无法准确找到答案边界;除了直接进行微调之外,使用预训练BERT作为特征提取器同样能够work;[MASK]、随机词和原词的配比也是work的,因为可以确保模型从未见过真实的输入词。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)