推荐系统浅学与实践
最近学习了一下推荐系统,把自己的所得分享出来。本人才疏学浅,如有不对的地方,还望指正~1.系统架构推荐系统的目的只有一个:把用户可能感兴趣的产品推荐给他们。推荐系统可以说是AI落地最成功的一个领域,它和我们的日常生活相关,我们每天刷短视频,新闻,逛pdd淘宝都会与他打交道。推荐系统是一个极具综合性的系统,涉及前端、后端、大数据、算法、机器学习等等技术,它没有固定的格式,针对不同的场景可以有灵活的搭
最近学习了一下推荐系统,把自己的所得分享出来。本人才疏学浅,如有不对的地方,还望指正~
1.系统架构
推荐系统的目的只有一个:把用户可能感兴趣的产品推荐给他们。推荐系统可以说是AI落地最成功的一个领域,它和我们的日常生活相关,我们每天刷短视频,新闻,逛pdd淘宝都会与他打交道。推荐系统是一个极具综合性的系统,涉及前端、后端、大数据、算法、机器学习等等技术,它没有固定的格式,针对不同的场景可以有灵活的搭配和设计。这里我把业界常见的推荐系统进行抽象,为了方便大家理解,做了一定的简化,形成了一个由下至上的三层系统架构,供大家学习和参考。
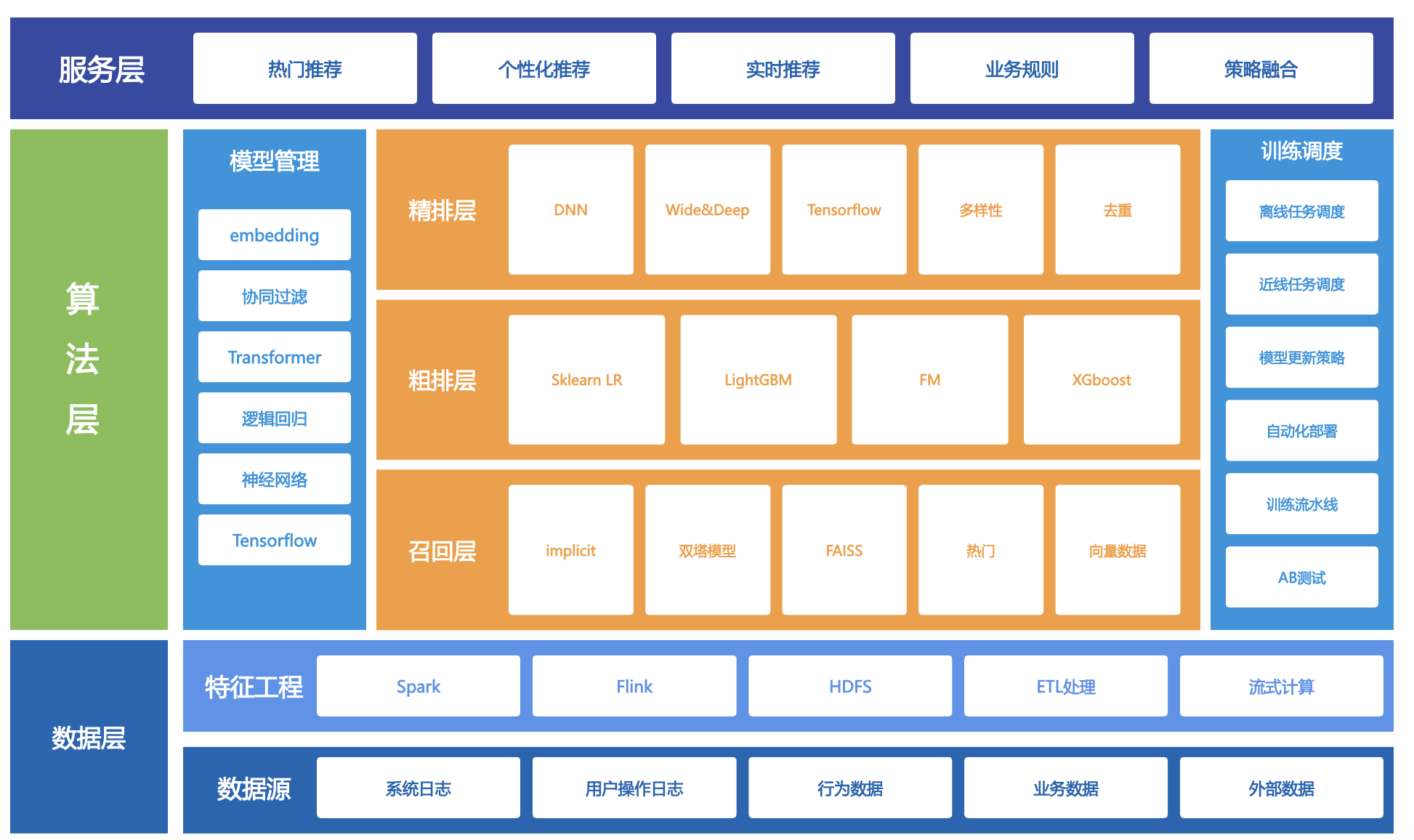
1.1数据层
数据层是推荐系统的底座,没有数据,你不知道有哪些内容可以推荐,推荐给谁。这里不可或缺的就是三组数据,用户信息(user)、产品信息(item)、用户操作日志(action)。前两者不用多说,action日志主要记录了用户对产品的各种操作信息,比如在短视频app中,用户观看的视频列表,观看的时长,是否点赞等等。有了这个数据,算法才能从中学到用户到底喜欢什么样的产品。这些日志和信息并不能直接被算法使用,需要做一些脏数据和归一化的处理,分解或合并一些字段,通过特征工程形成算法容易处理的格式,这里通常用到的是hadoop/spark/flink这类大数据生态技术,用于处理大量的离线或实时数据,当数据量较小时,也可以使用pandas/numpy进行数据处理。在企业级的实际应用中,除了上述这三组数据,还可能引入节假日信息,企业运营信息,商业策划信息等以丰富数据的维度。
1.2算法层
算法层的本质是选择,从大量的产品中选出用户感兴趣的产品。这是推荐系统的核心,也是我们要重点关注的部分,通过各式各样的AI技术,我们可以从数据层中提炼出关键信息,让数据真正产生价值。然而你想一蹴而就,一下子就从海量产品中挑出用户心仪的那一个,且不说算法层面难以实现,光网络。所以我们通常使用分层筛选的架构,用一个漏斗式的设计,将海量数据一层一层减少,最终滤除我们想要的东西。
需要注意的是,我们不能等到用户点击进入app时才开始走筛选流程,如果等到用户失去耐心退出app之后推荐的结果才出来,那只能是亡羊补牢为时已晚。所以一部分的模型是以离线调度形式提前算好,比如每天或每小时一次计算,这些模型用到全量数据,会比较耗时。同时为了补足用户的实时性需求,还有一部分的模型以近线或在线的方式进行调度。当用户点开推荐页的时候,把已经筛初步选好的数据再结合一些轻量的在线算法和融合策略,这样就能快速的给出最终结果。
注:下面涉及的算法每一个单拉出来都可以写篇大论文,要想研究明白都需要进行深入的学习,由于篇幅有限且本人水平有限,这里我们都只做简单的介绍。
1.2.1召回层
召回层的目:把百万量级的大海洋缩到几千量级的小水库,保证别漏掉用户真正感兴趣的东西。这一层不求“精准到小数点后三位”,而是追求“别错过、别太慢、别太偏”。召回层就像“超市进货”——货架上能摆的商品再多,也得先有人把货从仓库里挑出来、搬到前场,否则顾客连看都看不到,更谈不上买。短视频 App 同理:库里躺着 100 万个视频,手机一次却只放得下 10 个卡片,如果一次把 100 万全推给后面的排序模型,光网络传输就能把服务器挤爆,所以必须有一个“先筛一遍”的环节,这就是召回层。
当然,从大海洋抽水到小水库所用到的水“管通”通常不止一条,多条“水管”一起放水,每条水管用一种算法,各自搬一批货,最后把各家的货合起来,再去重、过滤,就得到几百条候选。接下来给大家介绍一些常见的“水管”。
热门召回
人都有从众心理,这种现象在互联网上被无限放大,无论事件本身的属性是否符合用户兴趣,只要是热门事件或热搜新闻,大家都忍不住会想看一眼。系统会把最近 1 小时全局播放量、点赞率最高的视频拎出来,通常只有几百到几千个,却可能占据整体播放量的 20%。
向量召回
向量召回,也叫“双塔召回”。想象市场门口站着一位“用户口味侦探”和一位“商品性格侦探”,他们各自把顾客和商品用同样长度的“口味向量”来描述。顾客向量可能写着[0.8篮球,0.7美食 ,0.1搞笑],商品向量写着[0.7NBA,0.4食品,0.2娱乐]。两位侦探只要把信息一对照,就会发现这两个向量非常接近,就会把这些相似的向量对应的产品捞出来。用户每次刷新,侦探都会根据他刚才的点击把口味向量稍微挪动一点,所以“越刷越懂你”。
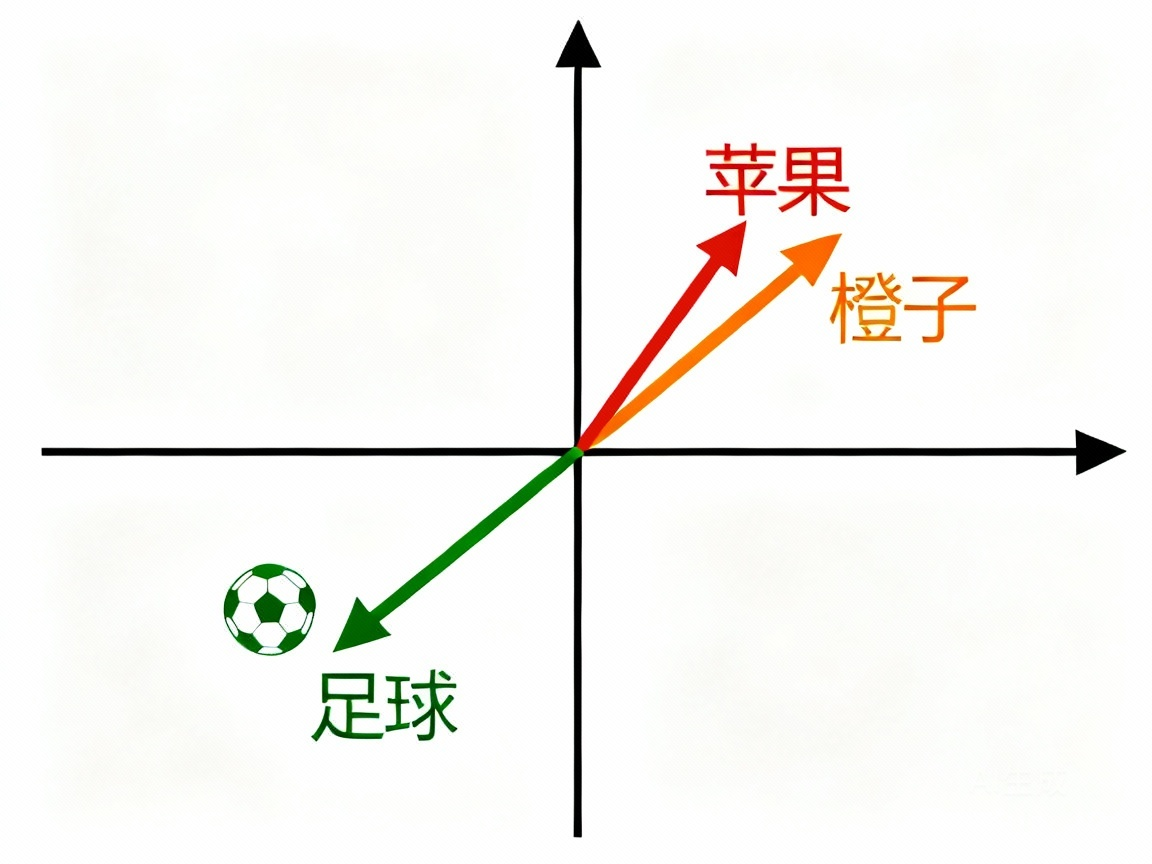
这里不得不提到一个技术叫embedding。对于人来讲,很容易理解“篮球”和“NBA”,“苹果”和“橙子”这些内容是相似的,电脑只认识数字,文字、图片、声音它都看不懂。通过embedding,我们把所有的东西都转化成数字向量,比如苹果转化为[1,1,1],橙子转化为[1,1,0.8],这样机器他就能区分这些事物了。现在能区分事物了,那怎么知道这些他们之间相不相似呢,常用到的方法有点积和余弦相似度两种。假设我们有两个非零向量 A 和 B,点积就是AB,余弦相似度 cosine(A,B) 可以通过下面的公式计算:
![]()
余弦相似度表示了两个向量的角度,在二维坐标系,我们可以直观的感受到这些向量之间的关系。夹角越小,余弦相似度越大,表示两个向量很相似,点积的作用也类似。在实际工程上,我们通常会用点积以加快运算速度,毕竟比cos要少算一个向量长度,并且点积会考虑到兴趣强度,会让推荐内容更贴近用户属性,余弦相似度则更具公平性,使得模长小的长尾物品有机会和热门公平竞争。不过一般我们会在embedding或特征工程的时候就对向量做归一化,这时候点积就等于cos了。
协同过滤
"协同过滤”,俗称“臭味相投”法。市场里有 1000 个顾客,系统发现 A 和 B 过去 7 天点的视频 80% 都重合,于是直接把 B 最新点过的视频拿给 A,简单粗暴却有效。协同过滤有很多路径,类如u2i,u2i2i,u2u2i等等,本质上和向量召回一样,就是找相似。和你兴趣相似的人也喜欢什么,就给你推什么;喜欢这个物品的人也喜欢看什么,就给你推什么。系统通常先离线算好“用户→相似用户”或“物品→相似物品”这些大表,线上只要查表即可。
关注召回
这个很好理解,用户关注了 NBA 官方账号,官方一发新视频,这条水管立刻把新视频塞进候选池,保证粉丝第一时间看到,时效性最高,甚至能做到秒级。
除了这些常见的“水管”,还有其他小众“水管”:地域召回(广州用户优先推粤语视频)、新品召回(上传不到 2 小时的新视频给 10% 流量探冷)、运营活动召回(女神节美妆视频强制 1 坑)等等,根据不同的场景可以灵活组合。通过将这些水管的水汇到一起,专业来讲叫多路召回,我们得到几百条“种子货”,之后再交给后面的粗排和精排去细算分数。
1.2.2粗排层
召回层从海量物品中捞出几千个候选,精排层算力消耗大、耗时长,没法直接处理这么多。粗排层就是夹在中间的"过滤器"——用较小的计算成本,快速把几千个候选砍到几百个,既要筛掉明显不好的,又要留住有潜力的,让精排层能精细打磨。
简单说:召回管"找得到",粗排管"筛得快",精排管"排的准"。
双塔模型(主流)
是不是有点熟悉,双塔模型不是已经在召回层用过了吗。你没看错,双塔模型在粗排层同样适用,正如我之前所说,推荐系统没有固定的技术架构,依据企业的不同需求,双塔模型有时会应用在召回层,有时则可以在粗排层,当然你也可以两边都用,因为粗排面临的问题和召回类似——都需要快。虽然粗排候选集已经从百万降到几千,但依然无法承受精排那种复杂的实时特征交叉。双塔的向量点积计算极轻量,正好填补这个空档。不过,同样叫双塔模型,这两层肯定还是有区别的,召回的双塔通常更轻(向量维度低、网络浅),追求极致速度;粗排的双塔可以稍重(维度高一点、特征多一点),追求更好的区分能力。
轻量级特征交叉(如FM、浅层DeepFM)
双塔模型有个缺点:用户和物品特征在各自塔里独立处理,直到最后才交互,可能错过一些精细的交叉信号。有些场景会在粗排引入轻量级的特征交叉,比如用FM(因子分解机)做二阶特征组合,或者用最浅层的DeepFM。但会严格控制网络深度和宽度,只保留最关键的交叉(比如用户实时兴趣标签与物品类目的匹配度),绝不像精排层那样做复杂的高阶组合。
知识蒸馏(Teacher-Student框架)
既然粗排模型要小、要快,效果难免不如精排大模型。知识蒸馏就是让"老师"(精排大模型或离线复杂模型)提前给样本打分,然后用这些分数教"学生"(粗排小模型),让小模型不仅学习真实的点击标签,还学习大模型的排序偏好和概率分布。就像学霸先做完试卷,把解题思路教给普通学生,让普通学生考得更好。这样粗排能在保持轻量的同时,尽可能逼近精排的排序质量。
逻辑回归
直接把用户特征和物品特征拼在一起(比如用户年龄+物品类目+用户历史标签+物品标签等),过一层LR算点击概率,按概率排序筛选。虽然LR(逻辑回归)在粗排已经算"老古董"了,但由于其完全没特征交叉能力,比如"年轻用户+游戏类物品"这种组合信号抓不到,效果天花板太低,现在大厂基本不再使用。虽然过时,但依旧经典,下面是案例:
"""
粗排主脚本:LR模型,快速过滤候选
"""
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
# 读取召回结果和特征
recall = pd.read_csv('data/recall_result.csv')
users = pd.read_csv('data/users_feat.csv')
videos = pd.read_csv('data/videos_feat.csv')
inter = pd.read_csv('data/interactions.csv')
# 构造训练样本(正样本:like;负样本:曝光未互动 + 负采样补充)
pos = inter[inter['action'] == 'like'][['user_id', 'video_id']].copy()
pos['label'] = 1
# 曝光未互动(这里用 view 作为曝光,未点赞视作负)
exposure = inter[inter['action'] == 'view'][['user_id', 'video_id']].copy()
exposure = exposure.merge(pos[['user_id', 'video_id']], on=['user_id', 'video_id'], how='left', indicator=True)
exposure = exposure[exposure['_merge'] == 'left_only'][['user_id', 'video_id']]
exposure['label'] = 0
# 负采样:补充“未曝光”负样本
all_videos = videos['video_id'].unique().tolist()
all_videos_set = set(all_videos)
user_hist = inter.groupby('user_id')['video_id'].apply(set).to_dict()
neg_samples = []
neg_ratio = 3 # 每个用户采样的负样本数量(可调)
for uid in users['user_id']:
seen = user_hist.get(uid, set())
cand = list(all_videos_set - seen)
if not cand:
continue
sample_size = min(len(cand), neg_ratio)
for vid in np.random.choice(cand, size=sample_size, replace=False):
neg_samples.append({'user_id': uid, 'video_id': vid, 'label': 0})
neg = pd.DataFrame(neg_samples)
train_df = pd.concat([pos, exposure, neg], ignore_index=True).drop_duplicates(['user_id', 'video_id'], keep='last')
# 合并特征:用户与视频侧特征拼接
train_df = train_df.merge(users, on='user_id', how='left').merge(videos, on='video_id', how='left')
# 简单特征:数值型统计特征
feat_cols = ['age','register_days','is_male','user_view_cnt','user_like_cnt','user_share_cnt',
'publish_days','tag_count','video_view_cnt','video_like_cnt','video_share_cnt']
train_df = train_df.fillna(0)
# 训练LR:轻量粗排模型
X = train_df[feat_cols]
y = train_df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lr = LogisticRegression(max_iter=200)
lr.fit(X_train, y_train)
auc = roc_auc_score(y_test, lr.predict_proba(X_test)[:,1])
print(f'粗排LR模型AUC: {auc:.4f}')
粗排层的核心矛盾是效率和效果的平衡——模型要比召回层复杂(具备一定的区分能力,能识别粗粒度的用户兴趣),但要比精排层轻量(能毫秒级完成打分)。它解决的是工业界"算不起"的现实问题:没有粗排,精排面对几千候选会拖垮在线服务;粗排做得太重,又会成为新的瓶颈。好的粗排设计,是在有限的计算预算内,尽可能保留精排层需要的那部分信息,让漏斗每一层都发挥最大价值。
1.2.3精排层
粗排层筛出来的几百个候选,虽然相关度都不错,但谁排第一、谁排最后,直接影响用户点击率和业务收益。精排层就是这道"终极裁判"——用最强的计算能力、最丰富的特征、最复杂的模型,给每个候选算出一个精确的预估分数(比如点击率、转化率、停留时长),然后按分数高低排出最终展示顺序。精排层的结果决定了用户最终看到什么,可谓推荐系统核心中的核心。
DeepFM(自动特征交叉)
把Wide部分换成FM(因子分解机),自动学习二阶特征组合,不用人工设计交叉规则。神经网络部分继续挖高阶模式。相当于给模型配了个"自动编剧",自己发现哪些特征搭配效果好。
DIN(深度兴趣网络,阿里提出)
传统模型把用户历史行为压缩成固定向量,DIN用注意力机制给历史行为加权——用户刚点的视频权重高,三天前点的权重低。就像你逛商场,销售会根据你刚才多看两眼的商品重点推荐,而不是把你半年前的购物单翻出来。
DCN(深度交叉网络)
专门解决特征交叉问题。显式构造多层交叉层,让特征像"和面"一样反复揉合,自动学习任意阶的组合关系。比DeepFM的交叉更有针对性。
多目标建模(MMOE、PLE)
真实业务要同时优化点击、点赞、收藏、时长等多个目标。MMOE用多个"专家"网络分别学不同目标,再用门控网络动态组合;PLE则给每个目标配专属专家,减少目标冲突。就像餐厅既要菜好吃,又要上菜快,还要价格便宜,得平衡多个指标。
Transformer(多头注意力)
Transformer问世不算太久,但正在精排层快速普及,已经成为大厂标配之一。用户历史点击、购买、浏览是一个序列,传统方法(如DIN)用注意力加权,但只能捕捉局部关联。Transformer的自注意力机制能全局建模,这种序列数据刚好与其机制完美契合——比如用户三年前买过的手机和现在看的手机壳,远距离关联也能捕捉到。
"""
精排主脚本:Transformer 精排(序列建模)
"""
def build_transformer_ranker(video_vocab, author_num, category_num, num_dim, seq_len):
# Transformer 关键超参
emb_dim = 32 # embedding 维度
num_heads = 4 # 多头注意力头数
ff_dim = 64 # 前馈网络隐藏层维度
# 输入:用户最近行为序列 + 当前候选视频/作者/类目 + 数值特征
seq_in = keras.Input(shape=(seq_len,), dtype='int32', name='seq_ids')
video_in = keras.Input(shape=(), dtype='int32', name='video_id')
author_in = keras.Input(shape=(), dtype='int32', name='author_id')
cat_in = keras.Input(shape=(), dtype='int32', name='category_id')
num_in = keras.Input(shape=(num_dim,), dtype='float32', name='num_feat')
# 1) 序列 embedding(把视频ID序列映射成向量序列)
# mask_zero=True 表示0是padding,会被注意力忽略
item_emb_layer = keras.layers.Embedding(video_vocab + 1, emb_dim, mask_zero=True)
# 位置编码(让模型知道序列顺序)
pos_emb_layer = keras.layers.Embedding(seq_len, emb_dim)
seq_emb = item_emb_layer(seq_in)
pos_ids = tf.range(start=0, limit=seq_len, delta=1)
pos_emb = pos_emb_layer(pos_ids)
seq_emb = seq_emb + pos_emb
# 2) 多头自注意力:学习用户最近行为之间的关联
attn_out = keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=emb_dim)(seq_emb, seq_emb)
attn_out = keras.layers.Add()([seq_emb, attn_out])
attn_out = keras.layers.LayerNormalization()(attn_out)
# 3) 前馈网络:非线性变换
ff = keras.layers.Dense(ff_dim, activation='relu')(attn_out)
ff = keras.layers.Dense(emb_dim)(ff)
ff = keras.layers.Add()([attn_out, ff])
ff = keras.layers.LayerNormalization()(ff)
# 4) 池化成固定长度的用户序列向量
seq_vec = keras.layers.GlobalAveragePooling1D()(ff)
# 5) 当前候选视频侧特征 embedding
video_emb = item_emb_layer(video_in)
video_emb = keras.layers.Flatten()(video_emb)
author_emb = keras.layers.Embedding(author_num + 1, emb_dim)(author_in)
author_emb = keras.layers.Flatten()(author_emb)
cat_emb = keras.layers.Embedding(category_num + 1, emb_dim)(cat_in)
cat_emb = keras.layers.Flatten()(cat_emb)
# 6) 拼接:用户序列向量 + 视频向量 + 作者/类目 + 数值特征
x = keras.layers.Concatenate()([seq_vec, video_emb, author_emb, cat_emb, num_in])
x = keras.layers.Dense(64, activation='relu')(x)
x = keras.layers.Dense(32, activation='relu')(x)
out = keras.layers.Dense(1, activation='sigmoid')(x)
# 7) 输出点击/喜欢概率
model = keras.Model([seq_in, video_in, author_in, cat_in, num_in], out)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['AUC'])
return model
精排层不计成本追求精度——用实时特征(用户刚点的内容)、复杂交叉(几十上百维特征组合)、深度网络。需要注意的是,我们在工业场景下,通常不会只选择一种模型,而是通过组合提升排序效果。比如在底层用传统网络(DNN、DCN)做基础特征提取,在上层:Transformer专门处理行为序列或特征交叉,在输出端做多目标融合,这样能兼顾效率和效果。
1.2.4重排层
精排层算的是单个物品的分数,但没考虑物品之间的关系。重排层就是解决这个问题的——它像"总编辑",在精排结果基础上做最后调整,它的主要目保证多样性(别全是同一类)、避免重复(别推相似视频)、满足业务规则(插广告、提权重)。
常用技术及原理:
MMR(最大边际相关性)
每次选物品时,既看它和用户的匹配度,也看它和已选物品的相似度。相似度高的降权,强制挤出多样性。就像点菜,点了红烧肉,下一道就推清炒时蔬解腻。
DPP(行列式点过程)
用数学方法建模物品间的"相互排斥"关系,自动平衡相关性和多样性。比MMR更优雅,但计算复杂,大厂常用。
业务规则兜底
强制插广告、保量新内容、过滤敏感 item,这些硬规则也在重排层执行。
这个层我在上述的架构图里没有画出来,因为它是可选的,对于一些轻量级的项目,上面三层足够把用户想要的内容筛出来,也可以把它融合到精排层,在精排的同时做一些简单的业务规则,这些都是可以灵活调整的。
1.3服务层
服务层是推荐系统的“前台服务员”,本质上就是前后端,用户在前端做请求,后端接口负责把算法算好的推荐结果快速、稳定地送给用户。它要处理高并发请求、做缓存加速、调用召回和排序模型、拼装商品信息(如标题、图片),确保你刷到的内容又快又准又好看。这一块不是重点,了解即可不做过多描述。
2.简单实践:
根据上述架构我做了一个实验级的推荐系统项目,可以在普通的电脑上跑通,旨在方便大家通过动手实践更加深入地了解推荐系统:
https://github.com/qulei0316/easy-rec1
3.拓展思考
推荐系统旨在给用户推荐他们想要的信息或产品,它的价值非常巨大,对于几乎所有的内容发布平台,比如小红书、抖音、腾讯新闻、电商等等,可谓是核心中的核心,骨髓中的骨髓。想象一下,如果没有推荐系统,你每天打开某个短视频app,都是重复的内容,没有任何的推荐只能通过搜索找到,你马上就会放弃使用它,这个app很快就会没人使用。如果随时随地你打开这款app,都是你特别想看的,让你心潮澎湃的内容,你会恨不得从早刷到晚,欲罢不能。
推荐系统虽然价值巨大,但应用场景并不算很广,它集中应用在内容平台,只做一件事:推荐。我认为它有三个硬性条件:1.有源源不断的新用户 2.有源源不断的新内容 3.这两者流量都要够大。有大量的用户使用记录,推荐系统才有数据来源,才能通过计算得知用户的喜好。有不断的新内容,才能不断的吸引新老客户,让他们留在平台上产生使用数据。两者互为因果,形成良性循环才能推动平台的发展。在很多2B场景,用户固定就这么点,内容也很少更新,用户的操作行为一般很固定,推荐系统完全没有用武之地。再比如超市这类2C场景,一来超市的物品更新率没那么快,老的东西客户都知道,新的总共就那几样没必要搞个系统来推荐,二来用户可能就是想体验“逛”的过程,不需要你很快把他所有想要的东西一股脑推荐好放在购物车里,那用户开个把小时车过来图啥。
我一向认为技术要服务于业务,不能为了学而学,本文给大家简单介绍了一下推荐系统,算是抛出了一个引子,但在大家继续往下学习前还是建议各位花些时间思考一下,推荐系统是否真的能解决你目前的问题,你的平台是否符合这样的场景,是否有内容推荐的需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)