大模型智能体开发:如何实现“记住用户“的双路记忆系统
文章介绍智能体持久性记忆系统的实现,通过双路记忆堆栈(情节记忆+语义记忆)解决智能体"健忘"问题。使用向量数据库存储对话历史,图数据库管理实体关系,实现"交互-检索-生成-编码"闭环。提供完整代码实现,使智能体能够记住用户信息并提供深度个性化交互,从"工具"转变为"伴侣"。
文章介绍智能体持久性记忆系统的实现,通过双路记忆堆栈(情节记忆+语义记忆)解决智能体"健忘"问题。使用向量数据库存储对话历史,图数据库管理实体关系,实现"交互-检索-生成-编码"闭环。提供完整代码实现,使智能体能够记住用户信息并提供深度个性化交互,从"工具"转变为"伴侣"。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
在前面的系列文章中,我们已经为智能体装上了“大脑”(Planning)、“双手”(Tool Call)甚至是“质检员”(PEV)。然而,即便这些功能再强大,标准智能体仍然面临一个致命的局限:健忘。
目前的对话智能体大多是“短时记忆”的产物,它们的记忆仅存在于当前会话。一旦对话重置,它们便会忘记你的名字、偏好以及你们曾共同探讨的深刻见解。
今天,我们将攻克智能体走向进化的关键一环——持久性记忆(Persistent Memory)。我们将模仿人类的认知架构,实现一个双路记忆堆栈:情节记忆(Episodic Memory)+ 语义记忆(Semantic Memory)。
一、 情节与语义:模仿人类的记忆分层
人类的记忆并非一团乱麻,而是有序分层的。在认知心理学中,长期记忆主要分为两类:
- 情节记忆(Episodic Memory):
- 定义:对特定事件或过去交互的记忆。
- 回答:“发生了什么?”(例如:“上周用户问过关于英伟达股价的问题”)。
- 实现方式:我们使用向量数据库(Vector DB),通过语义相似度检索相关的历史对话片段。
- 语义记忆(Semantic Memory):
- 定义:从事件中提炼出的结构化事实、概念和关系。
- 回答:“我知道什么?”(例如:“用户 Alex 是一位保守型投资者”、“Alex 对科技股感兴趣”)。
- 实现方式:我们使用图数据库(Neo4j),因为它擅长管理和查询实体间的复杂关系。
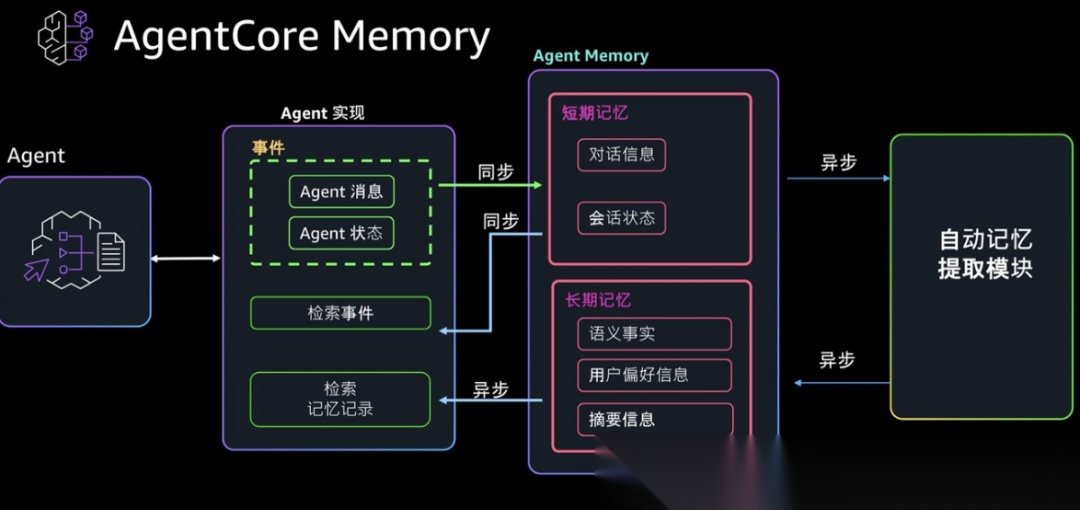
▲ Agent记忆系统核心功能示例
通过这两者的结合,Agent 不仅能回想起过去的对话“剧情”,还能在脑海中构建一张关于用户的“知识图谱”,从而实现深度定制的个性化交互。
二、 记忆增强智能体的工作流
整个记忆堆栈遵循“交互-检索-生成-编码”的闭环:
- 交互(Interaction):接收用户输入。
- 检索(Recall):
- 在情节向量库中搜索相似的对话历史。
- 在语义图数据库中查询与当前话题相关的实体事实。
- 增强生成(Augmented Generation):将检索到的双路记忆注入提示词,生成具备“历史记忆”的响应。
- 编码(Encoding):对话结束后,后台进程启动:
- 总结对话回合(生成新的情节记忆)。
- 提取实体关系(生成新的语义事实)。
- 存储(Storage):将新记忆持久化到向量库和图数据库。
三、 代码实战:构建双路记忆堆栈
3.1 环境准备
我们将使用 openai 的推理服务,以及****Neo4j 作为图数据库核心。需要在env文件中写入llm推理模型配置和embedding模型配置
# 安装必要库
!pip install -q -U langchain-openai langchain langgraph neo4j faiss-cpu tiktoken
import os, uuid, json
from typing import List, Dict, Any, Optional
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import FAISS
from langchain.docstore.document import Document
from langgraph.graph import StateGraph, END
# 初始化 LLM 与 嵌入模型
llm = ChatOpenAI(
base_url=os.environ.get("base_url"),
api_key=os.environ.get("api_key"),
model=os.environ.get("model"),
temperature=0,
)
embeddings = llm = ChatOpenAI(
base_url=os.environ.get("base_url"),
api_key=os.environ.get("api_key"),
model=os.environ.get("embedding_model"),
)
# 初始化情节记忆(向量库)
episodic_vector_store = FAISS.from_texts(["初始引导文档"], embeddings)
# 初始化语义记忆(图数据库)
graph = Neo4jGraph(
url=os.environ.get("NEO4J_URI"),
username=os.environ.get("NEO4J_USERNAME"),
password=os.environ.get("NEO4J_PASSWORD")
)
3.2 记忆制造者:Memory Maker
这是系统的核心,负责将对话“消化”并转化为记忆。
from pydantic import BaseModel, Field
class Node(BaseModel):
id: str = Field(description="节点唯一标识,如人名、公司代码或概念")
type: str = Field(description="节点类型,如 'User', 'Company', 'InvestmentPhilosophy'")
properties: Dict[str, Any] = Field(default_factory=dict)
class Relationship(BaseModel):
source: Node; target: Node
type: str = Field(description="关系类型,如 'IS_A', 'INTERESTED_IN'")
class KnowledgeGraph(BaseModel):
relationships: List[Relationship]
def create_memories(user_input: str, assistant_output: str):
conversation = f"User: {user_input}\nAssistant: {assistant_output}"
# 1. 提取情节记忆(总结)
summary_prompt = f"请为以下对话生成一句简明扼要的摘要:\n{conversation}"
episodic_summary = llm.invoke(summary_prompt).content
episodic_vector_store.add_documents([Document(page_content=episodic_summary)])
# 2. 提取语义记忆(图谱提取)
extractor_llm = llm.with_structured_output(KnowledgeGraph)
extraction_prompt = f"从以下对话中提取关键实体及其关系,侧重用户偏好和事实:\n{conversation}"
kg_data = extractor_llm.invoke(extraction_prompt)
if kg_data.relationships:
for rel in kg_data.relationships:
# 将提取出的关系写入 Neo4j
graph.add_graph_documents([rel], include_source=True)
3.3 记忆增强型 Agent 的逻辑
通过 LangGraph 构建一个包含“检索-生成-更新”的循环流程。
class AgentState(TypedDict):
user_input: str
retrieved_memories: Optional[str]
generation: str
def retrieve_memory(state: AgentState):
user_input = state['user_input']
# 检索情节记忆
docs = episodic_vector_store.similarity_search(user_input, k=2)
episodic = "\n".join([d.page_content for d in docs])
# 检索语义记忆(Cypher 查询)
semantic = str(graph.query("""
UNWIND $keywords AS keyword
CALL db.index.fulltext.queryNodes("entity", keyword) YIELD node, score
MATCH (node)-[r]-(related)
RETURN node.id, type(r), related.id LIMIT 5
""", {'keywords': user_input.split()}))
return {"retrieved_memories": f"【情节回顾】:\n{episodic}\n\n【已知事实】:\n{semantic}"}
def generate_response(state: AgentState):
prompt = f"""你是一个个性化金融助手。利用以下记忆来定制你的回复:
{state['retrieved_memories']}
用户问题:{state['user_input']}"""
response = llm.invoke(prompt).content
return {"generation": response}
# 构建 Graph 略(见系列前文)
四、 深度演示:Agent 如何“认识”你?
让我们模拟一个三轮对话,看看 Agent 记忆的成长。
第一轮:播种
用户:你好,我是 Alex,我是一个保守型投资者,主要对老牌科技股感兴趣。
Agent 响应:你好 Alex!专注于基本面稳健的老牌科技公司是很明智的。
后端变化:
- 情节记忆:存入“用户 Alex 介绍自己是保守型投资者,关注老牌科技股”。
- 语义图谱:创建节点
(User: Alex)->[:HAS_GOAL]->(Philosophy: Conservative)。
第二轮:深入
用户:你觉得苹果(AAPL)怎么样?
Agent 响应:对于保守型投资者,AAPL 是基石。它有巨额现金流和持续的分红…
后端变化:
- 语义图谱:增加关系
(User: Alex)->[:INTERESTED_IN]->(Company: AAPL)。
第三轮:记忆测试
用户:“基于我的目标,除了那支股票,还有什么好的替代方案?”
Agent 响应:“当然,Alex。基于你偏好的保守投资风格(语义记忆检索),既然你已经关注了苹果,微软(MSFT)是一个绝佳选择(逻辑推理)。它同样是科技巨头,但业务更多元化…”
注意:在第三轮中,用户没有提到自己的名字、风格和苹果公司,但 Agent 完美通过了“记忆测试”。
五、 总结与展望
在本文中,我们成功构建了一个具备情节+语义双路记忆的智能体。
- 无状态的失败:标准 Agent 会在第三轮对话中抓瞎,因为它不记得 Alex 也不记得 Apple。
- 记忆增强的成功:我们的 Agent 能够“检索发生了什么”(情节)并“提取已知事实”(语义),从而生成深度的个性化推荐。
这种结合是智能体从“工具”转变为“伴侣”的关键。虽然在规模化管理中还面临**记忆膨胀(Memory Bloat)和修剪(Pruning)**的挑战,但我们今天搭建的底层架构已经为未来的持续学习奠定了坚实基础。
智能体架构实战系列仍在继续,下一篇我们将探讨如何让 Agent 拥有“自我进化”的能力,敬请期待!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)