你的 AI 编程助手太贵太慢?这篇 ShortCoder 论文给出了代码生成“瘦身”秘籍
更极端的方法如SimPy,直接设计了一套AI导向的语法,用特殊的编程语言替代标准Python,确实能减少token数量,但代价是代码可读性大打折扣,违背了"代码即文档"的基本原则。HumanEval是代码生成领域的"试金石",包含164个精心设计的Python编程问题,每个问题都有对应的测试用例来验证生成代码的正确性。这是Python的增强赋值运算符,用+=、-=、*=、/=等替代冗长的"x =
引言:一场关于"瘦身"的探索
想象一下,你让ChatGPT帮你写一个排序算法,它慷慨激昂地写下了200行代码,用了三个类、五个辅助函数,还贴心地加上了二十行注释。你看着这段"大制作",陷入了沉思:我就想要一个快速排序啊!
这并非个例。在AI代码生成领域,"冗长"几乎成了一种通病。大型语言模型们在追求"准确"的道路上,似乎把"简洁"这个美德遗忘在了某个角落。它们生成的代码往往像老太太的裹脚布——又长又臭,还振振有词:"我这叫可读性好!"
但现在,一篇来自中山大学、华为和重庆大学联合研究的论文,提出了一位名叫ShortCoder的"代码瘦身师":它不仅能让AI生成的代码长度减少近两成,还能保持同样的功能和更好的可读性。让我们走进这篇论文,理解新时代。
问题的诞生:代码生成为何越来越"胖"
在深入ShortCoder的神奇框架之前,我们有必要先理解一下问题的根源。
2.1大型语言模型的"基因缺陷"
代码生成任务旨在将用户的自然语言需求自动转换为可执行的程序代码。这项技术被誉为软件工程自动化的"圣杯"之一,能显著减少手动编码的工作量,加速开发周期。近年来,以CodeLlama、ClaudeCode为代表的大型代码语言模型(Code LLMs)在这一领域取得了突破性进展,它们能够理解编程语义、掌握语法模式,甚至在一些基准测试上超过了人类程序员的表现 。
然而,这些"庞然大物"们有一个致命的弱点:它们太"能写"了。基于Transformer架构的代码生成模型采用自回归机制逐个token地生成代码,每一个token的输出都需要完整的推理过程,需要在内存中持续保留上下文信息。这就像一个话痨朋友,你问他一个问题,他能从盘古开天地开始讲起,直到你昏昏欲睡。生成代码越长,所需的计算步骤和资源消耗就越大,处理时间和运营成本呈非线性增长 。
2.2现有"减肥"方法的困境
面对这一挑战,学术界和工业界已经尝试了多种"减肥"策略,但效果不尽如人意。
提示压缩试图通过移除冗余信息来加速推理,但这无异于"因噎废食"——删掉的可能恰恰是关键信息,导致输出质量下降 。模型量化通过降低数值精度来减少计算开销,但代价是任务准确性的损失,"捡了芝麻丢了西瓜" 。更极端的方法如SimPy,直接设计了一套AI导向的语法,用特殊的编程语言替代标准Python,确实能减少token数量,但代价是代码可读性大打折扣,违背了"代码即文档"的基本原则 。
于是,研究者们陷入了一个两难困境:想要代码生成更快更省资源,就得牺牲准确性或可读性;想要保证质量和可读性,就得忍受高昂的计算成本。这个困局,直到ShortCoder的出现才有了转机。
ShortCoder的解题思路:知识注入
其核心思想可以用一个词概括:精简,而非压缩。
压缩是"删掉多余的",而精简是"用更少表达同样的意思"。这就像两个人讲同一个故事:普通人可能需要半小时,而高手只需要五分钟——不是删掉了什么,而是用更精炼的语言传递了同样的信息。
具体而言,ShortCoder提出了一个知识注入框架,通过三个创新组件实现代码生成的效率优化:
1.十条语法级简化规则:专门为Python设计的代码精简模式,基于抽象语法树(AST)保持的转换,确保语义等价 。
2.混合数据合成管道:结合规则重写和LLM引导精炼,构建高质量的训练数据集ShorterCodeBench 。
3.基于LoRA的微调策略:将简洁性"注入"基础模型,使其在生成代码时自然地采用更简洁的表达方式 。
这套方法的关键在于:它不是在生成后再压缩代码,而是让模型从"根"上学会写简洁的代码。
值得一提的是,ShortCoder始终坚守一条底线:保持甚至提升代码可读性。
这与市面上一些"效率优先"的技术方案形成了鲜明对比。那些方案为了几个百分点的效率提升,往往把代码改得面目全非,让后续维护者痛苦不堪。ShortCoder认为,代码不仅是给机器执行的,更是给人看的。
3.1技术细节:十条"瘦身"规则大揭秘
ShortCoder团队花费了大量精力,系统性地设计了10条代码简化规则。这些规则不是随便想想的"拍脑袋"决定,而是经过严格验证的"最佳实践"。规则的制定经历了三个阶段:手动规则提取(从代码库中发现简化机会)、专家驱动扩展(根据Python官方文档补充)、验证驱动最终确定(跨数据集验证和负采样) 。
让我们逐一检视这些规则,看看它们是如何让代码"瘦身"的。
规则一:多变量赋值简化
当多个变量被赋予相同值时,完全可以将它们"串联"起来。

这不是简单的语法糖,而是Python的原生特性,既简洁又清晰 。
规则二:return语句简化
return语句后的括号完全是多余的,删掉它不仅代码更短,还更符合Python的惯用写法 。

规则三:赋值操作简化
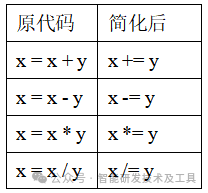
这是Python的增强赋值运算符,用+=、-=、*=、/=等替代冗长的"x = x op y"形式,省了两个字符,更重要的是表达更清晰——明确表示"在原值基础上操作" 。
规则四:条件语句简化
三元表达式是Python的”点睛之笔”,对于简单的条件赋值,一行代码胜过四行”啰嗦”的if-else。

规则五:多条件语句简化
elif是Python应对多条件分支的”神器”,它能把”金字塔”结构的嵌套if-else”扁平化”。

规则六:for循环简化
列表推导式是Python最优雅的特性之一,不仅代码更短,执行效率通常也更高。

字典推导式示例:

规则说明:Python对这种模式有专门的优化,是Pythonic风格的典型体现。
规则七:del语句简化
删除多个变量时,用逗号分隔写在一行里。

规则八:字典访问简化
dict.get()是Python提供的优雅解决方案,何必自己写if-else呢?
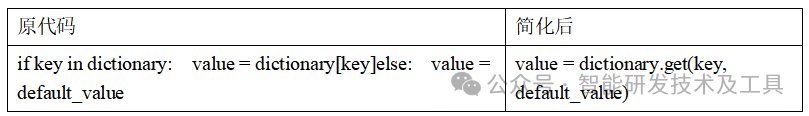
规则说明:堪称”字典访问的瑞士军刀”,代码更简洁,逻辑更清晰。
规则九:字符串格式化简化
字符串拼接用+不仅麻烦,还容易出错。

规则说明:更清晰、更灵活、更强大,避免了类型转换的麻烦。
规则十:文件操作简化
with语句是Python的上下文管理器,能自动处理文件的打开和关闭。

规则说明:即使发生异常也能保证资源被正确释放。
这十条规则看似简单,却涵盖了Python编程中最常见的"冗余"场景。更重要的是,它们都基于一个共同原则:保持语义等价,同时提升可读性。这正是ShortCoder区别于其他"压缩"技术的关键所在。
3.2数据集构建:ShorterCodeBench的诞生
混合数据合成策略
有了规则,还需要高质量的数据来"教会"模型如何应用这些规则。研究团队采用了混合数据合成策略,结合两种方法:
基于规则的数据合成:利用前述规则,将MBPP数据集中的原始代码转换为简化版本。对于同一个原始代码,可以应用不同规则的组合(独立简化或联合简化),产生多个训练样本。通过这种方法,研究团队生成了596对<原始代码, 简化代码>样本 。
基于LLM的数据合成:规则不是万能的,比如规则十(文件操作简化)在MBPP数据集中就"英雄无用武之地",因为大多数任务不涉及文件操作。为此,研究团队使用GPT-4,根据给定的简化规则,生成针对性的<问题描述, 原始代码, 简化代码>三元组。这就像请了一位"AI教练",专门针对每条规则设计练习题 。
质量控制
所有生成的样本都经过严格的质量控制,确保简化后的代码与原始代码在功能上完全等价。这不仅需要自动化验证(如AST对比、测试用例通过),还需要人工审核。研究团队公开发布的ShorterCodeBench数据集包含828个精心筛选的<原始代码, 简化代码>对,成为该领域的重要基准资源 。
3.3模型训练:让简洁成为一种"习惯"
LoRA微调技术
如果数据是"教材",那么训练过程就是"教学"。ShortCoder采用LoRA(Low-Rank Adaptation)技术进行参数高效微调。LoRA的核心思想是:不改动模型的基础权重,而是注入少量可训练的低秩矩阵 。
这样做的好处是:大幅减少训练参数和计算开销(相比全量微调可减少90%+的参数量),同时保持模型原有的通用能力不受损害 。
零样本简化能力
经过微调后的ShortCoder展现出了一个令人惊喜的特性:零样本简化能力。
这意味着在推理阶段,用户只需要提供问题描述,不需要任何关于简化规则的额外提示,模型就能自动生成既正确又简洁的代码。这与那些依赖复杂提示工程的"即时"方法形成了鲜明对比。ShortCoder不是"临时抱佛脚",而是"腹有诗书气自华"——简洁性已经融入了它的"基因" 。
实验验证:效果究竟如何?
4.1基准测试设置
研究团队在HumanEval基准上进行了全面评估。HumanEval是代码生成领域的"试金石",包含164个精心设计的Python编程问题,每个问题都有对应的测试用例来验证生成代码的正确性 。
评估采用两个维度:准确率(pass@k指标,衡量生成的代码能否通过测试)和效率(生成token数量、推理时间等)。
4.2性能对比
在准确率方面,ShortCoder的表现令人印象深刻:
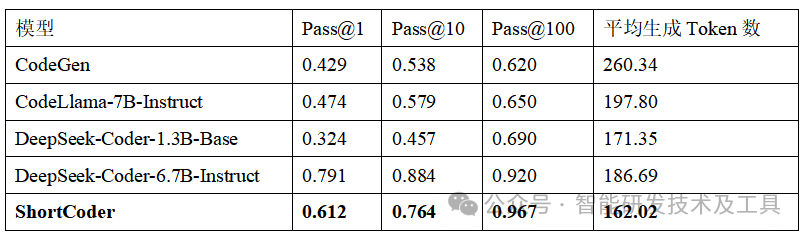
在效率方面,ShortCoder的优势更加明显:平均生成token数为162.02,比所有基线模型都少,token减少幅度达到18.1%-37.8%。
特别值得注意的是:ShortCoder的pass@100得分(0.967)超越了当前最先进的DeepSeek-Coder-6.7B-Instruct(0.920),证明它不仅没有因为追求简洁而牺牲准确性,反而在某些指标上超越了更大的模型
与提示工程的对比
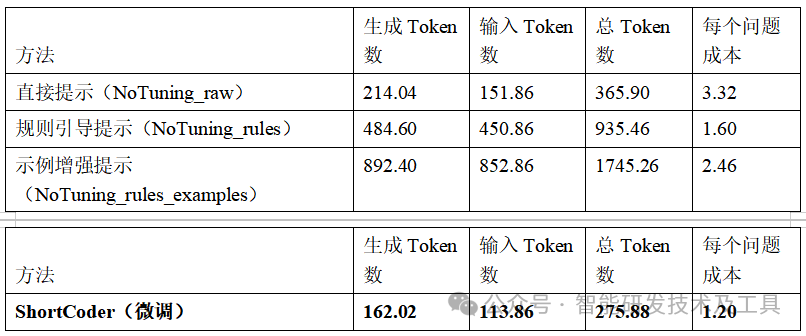
研究团队还特别对比了ShortCoder与各种"即时"提示工程方法的效果:
一个有趣的发现是:直接在提示中加入规则,反而让模型生成了更长的代码(规则引导提示和示例增强提示的token数反而增加了)。这可能是因为模型把规则本身当作"任务"来执行,而不是作为"指南"来遵循。这个结果恰恰证明了ShortCoder方法的价值:与其在提示中"说教",不如让模型真正"学会"简洁 。
可读性评估
代码简洁性的最终目的是让代码更好读。研究团队邀请了4位有三年以上经验的软件工程师作为评估者,从可理解性、清晰度、相关性三个维度对不同方法生成的代码进行评分(满分3分):
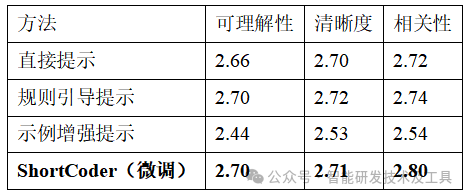
ShortCoder在"相关性"维度上表现最佳,说明它生成的代码与问题需求更加贴合,没有多余的"废话" 。
意义与展望
对学术界的贡献
ShortCoder的研究为代码生成领域贡献了三点重要成果:
1.ShorterCodeBench数据集:高质量的(原始代码, 简化代码)对数据集,为该领域的研究提供了重要资源 。
2.知识注入范式:证明了通过监督微调将领域特定知识(代码简洁性)注入LLM的有效性,为"如何让LLM学会特定技能"提供了可参考的路线 。
3.评估方法论:建立了准确率与效率并重的评估框架,推动学术界关注代码生成的"质"与"量"的双重优化 。
对工业界的启示
对于实际软件开发而言,ShortCoder的启示是深远的:
效率即价值:在资源受限的环境(如移动端、边缘计算)中,代码生成效率的提升意味着更低的成本和更好的用户体验。
可读性不可牺牲:任何以牺牲可读性为代价的"优化"都是短视的,代码是要被人维护的,不是只给机器跑的。
预训练优于即时工程:与其在每次使用时设计复杂的提示,不如花时间让模型"学会"正确的行为。
局限性与发展方向
当然,ShortCoder目前还有改进空间:
语言覆盖:当前规则主要针对Python,扩展到JavaScript、Java等语言需要额外的规则工程。
算法优化:当前关注的是语法层面的简化,对于算法效率(如时间复杂度优化)的涉及有限。
复杂场景:对于高度复杂的代码场景,自动简化可能存在风险,需要更严格的安全验证。
结语:代码的"断舍离"之道
回到文章开头的问题:为什么AI生成的代码总是那么"啰嗦"?
答案或许是:AI是在模仿人类,而人类写的代码本来就常常很啰嗦。我们习惯于"写清楚",往往就变成了"写冗余"。我们害怕遗漏,于是添上又一层注释、一段边界检查、一个辅助函数。
ShortCoder告诉我们:简洁不意味着粗糙,清晰不等于啰嗦。真正的简洁,是在表达完整意图的同时,去除一切不必要的繁文缛节。这不仅是一种编程技能,更是一种工程素养。
古语有云:"删繁就简三秋树,领异标新二月花。"代码之道,亦复如是。在这个AI日益成为编程主角的时代,让AI学会"瘦身",或许正是我们迈向更高效、更优雅软件工程的重要一步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)