【告别昂贵的公有云:如何用 MinIO 快速搭建自己的高性能 S3 存储?】
在云原生与 AI 时代,如何既能享受阿里云 OSS / AWS S3 的便捷,又能摆脱昂贵的流量费与供应商绑定?本文将带你深度走进 MinIO —— 全球领先的高性能开源对象存储系统。从独立开发者的存储痛点出发,本文不仅解析了 MinIO 底层的“硬核黑科技”(如纠删码、全对称架构与位衰减保护),还手把手教你如何通过 Docker 实现分钟级部署,并利用 Python SDK 快速集成到业务逻辑中
【告别昂贵的公有云:如何用 MinIO 快速搭建自己的高性能 S3 存储?】
文章目录
1. 引言:开发者面临的“文件存储”难题
在当今的开发版图中,无论是构建轻量级的个人博客,还是打造复杂的 AI 视觉识别系统,开发者始终面临一个避无可避的核心命题:非结构化数据的持久化方案。 在实际决策中,开发者往往陷入两难境地:一边是简陋且难以扩展的本地存储,一边是功能完备却成本高昂的商业云服务。在“将就”与“昂贵”之间,寻找一个性能与成本的平衡点显得尤为迫切。
1.1 本地存储的“隐形地雷”
最初,我们习惯将文件直接存在服务器或本地电脑的硬盘里。但随着项目推进,弊端接踵而至:
- 硬件风险:硬盘是有寿命的。一次断电或硬件故障,可能让数月的代码素材和数据积累毁于一旦。
- 无法公网访问:存储在本地的文件没有直接的 URL 链接,无法轻易集成到前端页面或移动端 App 中。
- 管理混乱:成千上万的图片和文档散落在文件夹里,检索效率极低,更别提版本控制和权限管理了。
1.2 云厂商 OSS 的“账单压力”
为了突破这一瓶颈,许多开发者将目光投向了阿里云 OSS、腾讯云 COS 或 AWS S3 等公有云方案。不可否认,这些服务功能完备,但对于追求极致性价比的初创项目或非营利性实验而言,其背后的成本陷阱不容小觑:不仅要面对复杂的计费阶梯,还要承担数据外流带来的带宽溢价,这种“付费换便捷”的模式往往让预算受限的项目难以为继:
- 计费陷阱:除了基础的存储费,还有外网流出流量费、请求次数费。稍不留神,一个被刷流量的接口就能让你一夜之间“欠费停机”。
- 供应商锁定:一旦你的代码深度耦合了某个云厂商的私有 API,未来想要迁移到其他平台,重构成本极高。
1.3 开发环境与生产环境的“撕裂感”
这是最令开发者头疼的问题:在本地开发时,我们可能用的是本地路径;上线后又要改成云端配置。这种环境的不一致,往往是导致 Bug 的温床。我们迫切需要一种方案,既能像本地硬盘一样免费、可控,又能像云端 OSS 一样标准化、专业化。
1.4 破局者:MinIO 私有化存储
正是在这种背景下,MinIO 成为了开发者圈子里的“存储明星”。
它是一个基于 Go 语言开发的高性能对象存储系统。简单来说,它能让你在自己的笔记本、宿舍的旧服务器或者几块钱一个月的轻量云服务器上,瞬间搭建出一个功能完全等同于 Amazon S3 的存储中心。

为什么要关注 MinIO?
- 100% 开放源代码:基于 GNU AGPL v3 协议,社区活跃,完全透明。
- S3 兼容性:它严格遵循 AWS S3 API 标准。这意味着你针对 MinIO 写的代码,未来可以无缝迁移到世界上任何主流云存储服务上。
- 软件定义:它不依赖特定的硬件,普通商用服务器甚至 Docker 容器就能跑出惊人的性能。
无论你是想为自己的 Python 爬虫项目找个安稳的家,还是想为毕设项目搭建一个专业的资源服务器,MinIO 都是目前最值得学习和投入的对象存储方案。
2. 为什么选择 MinIO?(优势与对比)
在了解了 MinIO 的背景后,你可能会问:“市面上存储方案那么多,为什么开发者圈子偏偏对 MinIO 情有独钟?”答案可以概括为三个关键词:快、准、稳。
2.1 极致的性能:为 AI 与大数据而生
对于大多数开发者来说,“对象存储”往往意味着“慢速归档”。但 MinIO 彻底颠覆了这一认知。
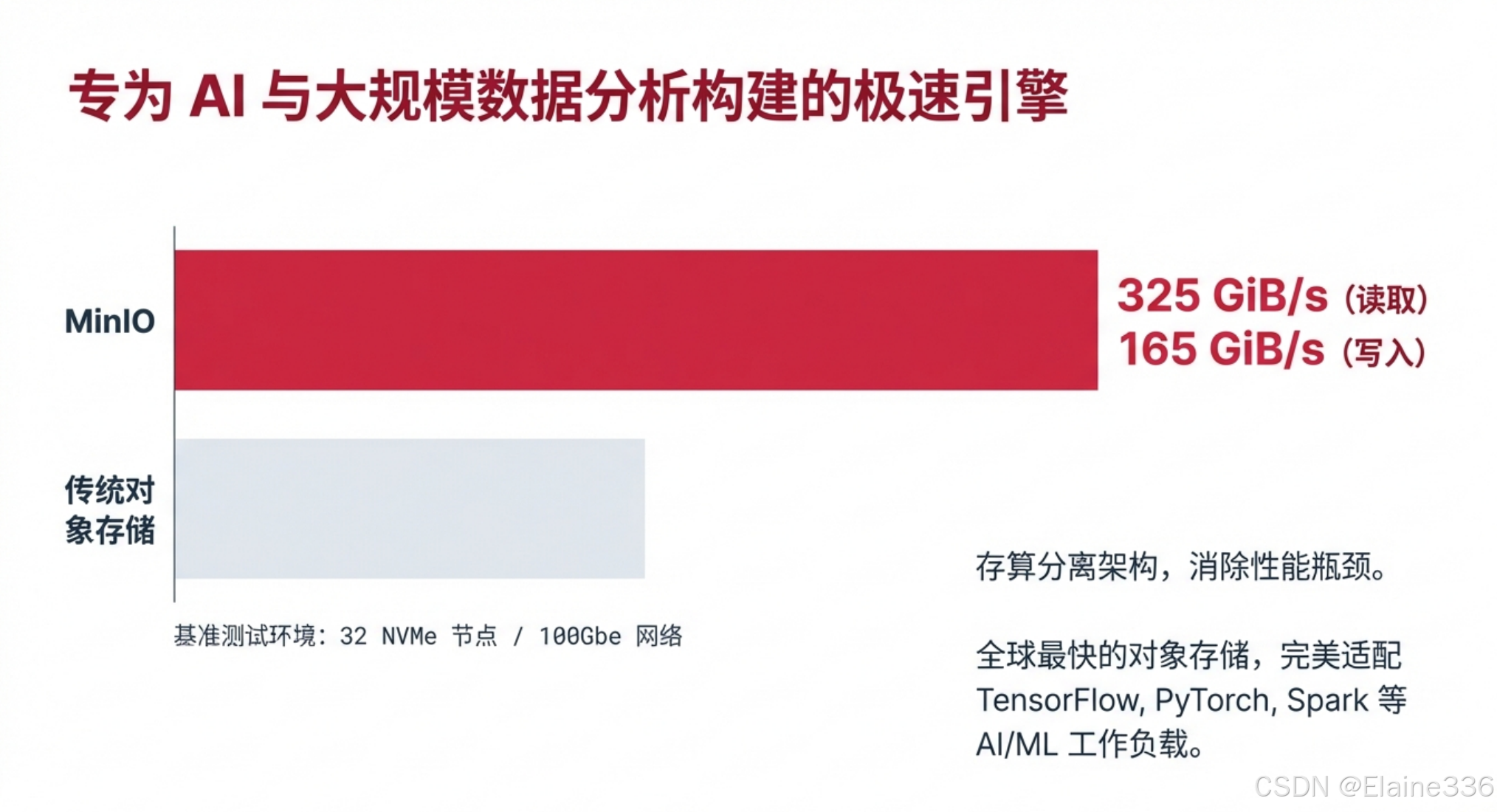
在 AI 训练、深度学习或海量日志分析场景下,存储的吞吐量直接决定了任务的成败。MinIO 采用了存算分离的现代化架构,消除了传统存储系统的性能瓶颈。
根据官方在标准环境(32 NVMe 节点 / 100Gbe 网络)下的基准测试,MinIO 的读取速度达到了惊人的 325 GiB/s,写入速度也高达 165 GiB/s。
- **赋能 Python 开发生态:**在计算机视觉或大数据处理场景下,IO 往往是拖慢进度的元凶。将 MinIO 作为底层数据源,其极致的并行读写能力可确保 GPU 始终处于满载状态,从根源上杜绝了“算力等数据”的资源浪费,从而成倍缩短模型迭代与训练的周期。
2.2 S3 协议标准:一次编写,到处运行
对于独立开发者而言,最担心的莫过于被特定的云厂商“绑架”。
MinIO 的灵魂在于它对 Amazon S3 API 的深度兼容。S3 协议已经成为了对象存储的事实标准。这意味着:
- 零成本迁移:你在本地用 MinIO 开发的 Python 代码,上线时可以直接切换到 AWS S3 或阿里云 OSS,不需要修改任何逻辑代码。
- 生态繁荣:几乎所有主流的开发工具、库和中间件(如 Python 的
boto3库、Spark、Flink)都原生支持 S3 接口。
2.3 无论数据位于何处,体验始终如一
MinIO 的另一个杀手锏是它的灵活性。它不像云厂商的存储服务那样必须依赖特定的云环境,MinIO 是“软件定义”的,这意味着它可以在任何硬件上跑出同样的体验。
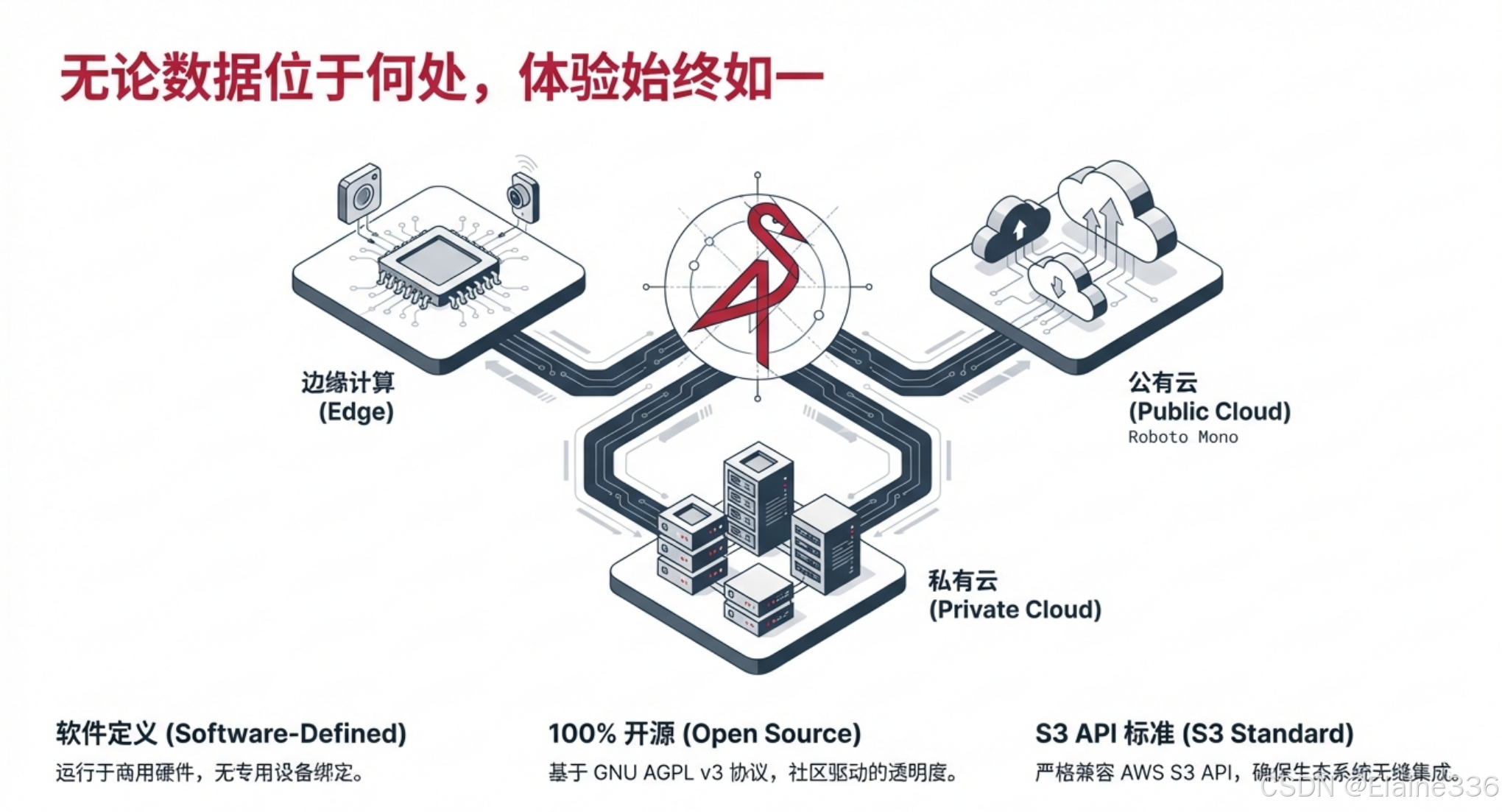
- 边缘计算 (Edge):可以部署在树莓派或工业网关上,处理传感器数据。
- 私有云 (Private Cloud):部署在公司或实验室的内网服务器,保护数据隐私,节省公网带宽费。
- 公有云 (Public Cloud):作为云原生应用的标准存储层,实现跨云的数据同步。
2.4 与传统存储的直观对比
为了让你更清晰地理解 MinIO 的优势,我们来看一下这个简表:
| 维度 | 传统文件系统 (如 FTP/NFS) | 主流云厂商 OSS | MinIO (私有化部署) |
|---|---|---|---|
| 读写性能 | 低(小文件处理能力弱) | 中等(受限于公网带宽) | 极高(内网环境吞吐量巨大) |
| 可扩展性 | 难(单机瓶颈) | 极强(付费即可) | 强(支持从单机到集群横向扩展) |
| 成本支出 | 维护成本高 | 流量费/存储费昂贵 | 完全免费(仅需服务器成本) |
| 开发标准 | 私有接口,兼容性差 | S3 兼容(部分厂商有私有协议) | 100% 严格兼容 S3 API |
3. 底层硬核技术:数据安全与高可用
MinIO 之所以能在极高的读写速度下保持数据稳如泰山,得益于其精简而强悍的底层架构设计。不同于传统存储系统的复杂堆叠,MinIO 在设计之初就选择了“去中心化”与“软件定义数据保护”的技术路径。
3.1 去中心化对称架构
传统的分布式存储系统(如 HDFS)通常依赖“元数据服务器(NameNode)”来管理文件索引。这种设计存在明显的单点瓶颈:一旦元数据服务器出现故障,整个集群将陷入瘫痪。
MinIO 采用了全对称架构。在集群中,所有节点的功能完全对等,没有主从之分。
- 无元数据数据库:数据与元数据原子化地一同写入对象,消除了检索时的性能瓶颈。
- 线性水平扩展:只需增加节点,存储容量和计算能力就能成比例增长。任何节点都可以处理客户端请求,这种设计极大地提升了系统的抗风险能力。
![---
**[此处插入图片:PPT 第 5 页 —— 展示去中心化的分布式拓扑图,配文:“全对称架构:所有节点功能对等,消除单点故障瓶颈”]**
---](https://i-blog.csdnimg.cn/direct/261505ecc79a48dc9da0ab714abbcf52.png)
3.2 纠删码(Erasure Coding):超越 RAID 的保护
在硬件领域,硬盘损坏是必然发生的。为了防止数据丢失,传统方案通常采用 RAID 冗余,但这往往伴随着极高的存储空间浪费和缓慢的重建速度。
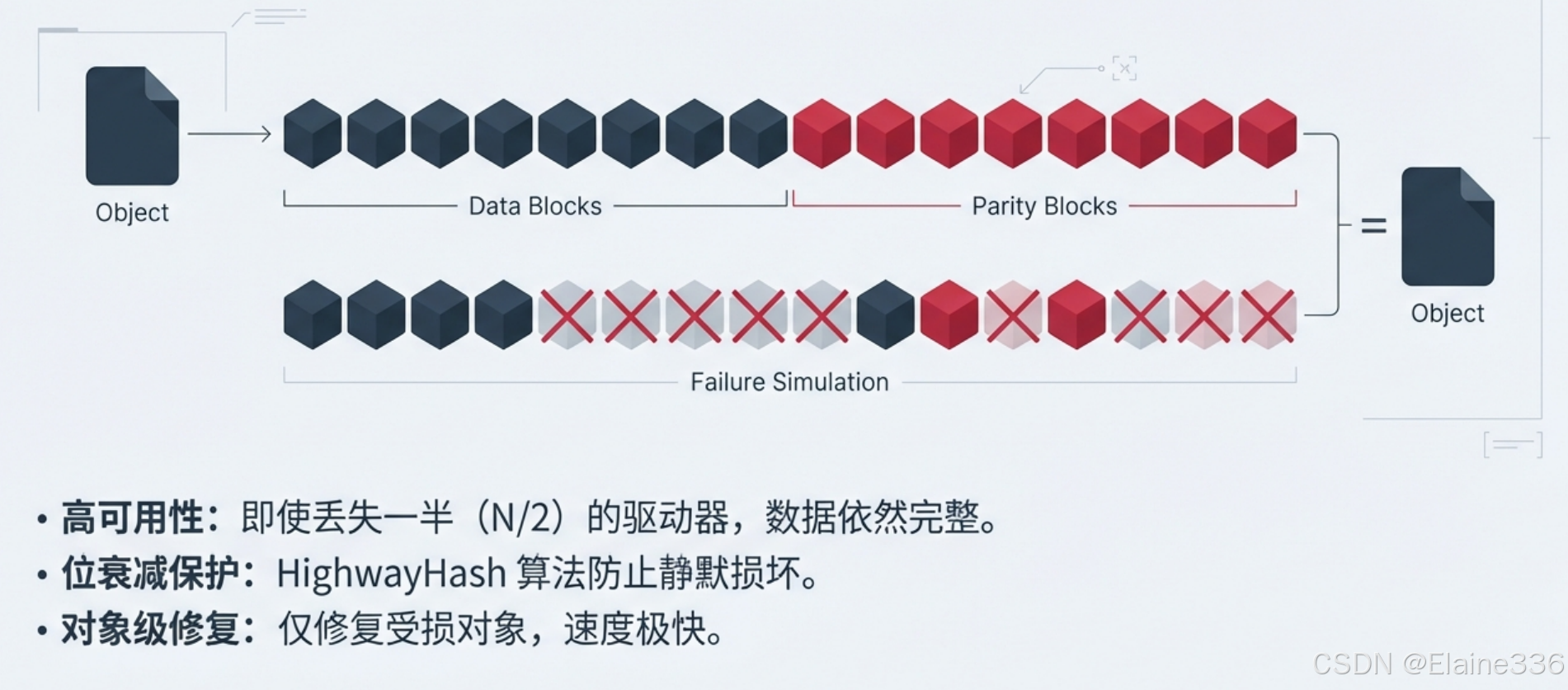
MinIO 引入了更先进的**纠删码(Erasure Coding)**技术(基于 Reed-Solomon 算法)。
- 高可用性:它将对象拆分为数据块和校验块。在标准的部署模式下,即使集群中丢失了一半(N/2)的驱动器,数据依然保持完整且可访问。
- 对象级修复:修复过程是在对象级别进行的,速度远快于传统的 RAID 磁盘镜像修复。
3.3 位衰减保护:对抗静默损坏
在长期存储中,由于磁介质老化或电磁干扰,数据可能会发生细微的错误(Bit Rot),且这种损坏通常难以察觉。
MinIO 通过 HighwayHash 算法 实现了位衰减保护。
- 实时验证:在读取时自动计算哈希并与写入时记录的哈希值比对,确保数据在传输和存储过程中未发生任何变异。
- 自动自愈:一旦发现数据块损坏,系统会利用纠删码的冗余信息自动完成修复。
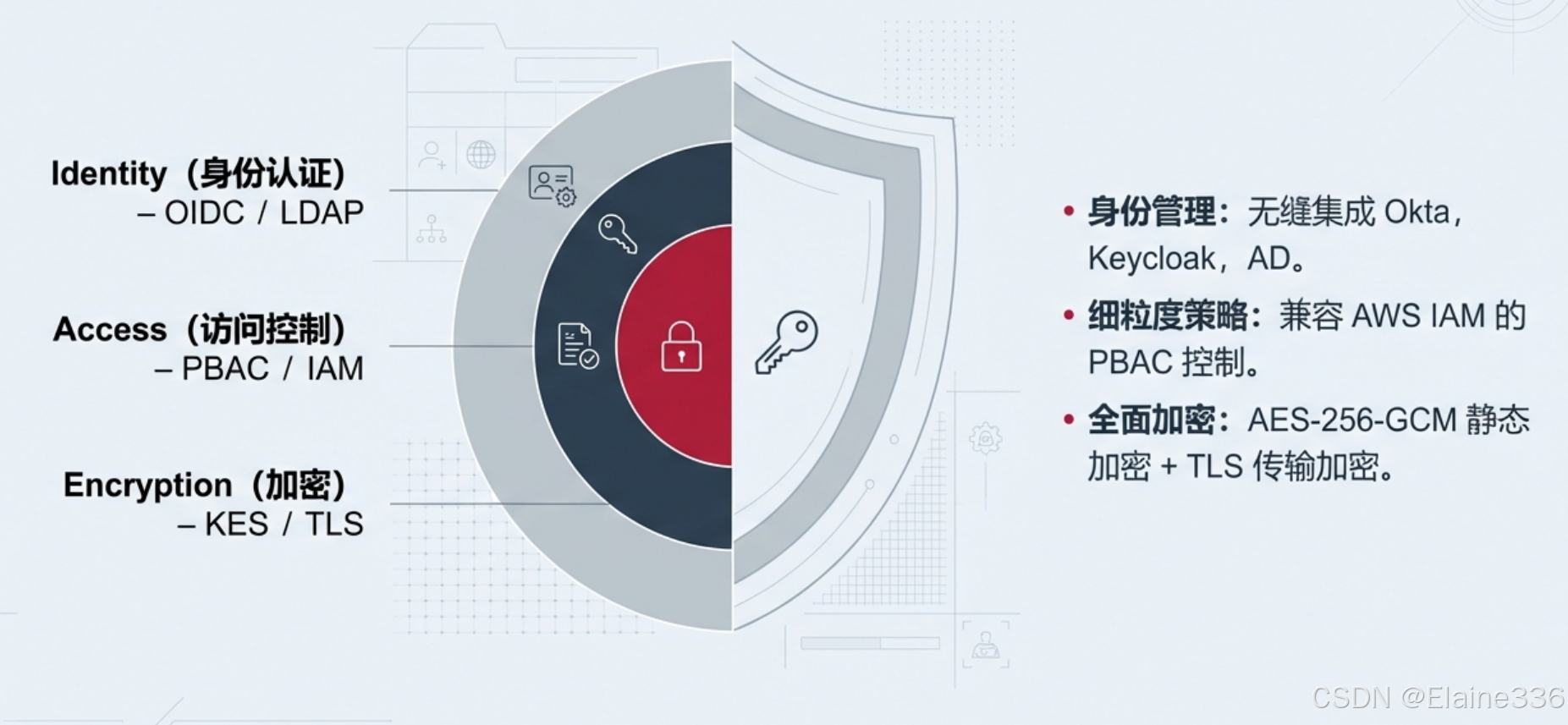
3.4 企业级安全体系
对于独立开发者和独立项目,安全性同样不可忽视。MinIO 构建了一套零信任的安全防御体系:
- 全面加密:支持 AES-256-GCM 等高性能加密算法,覆盖“传输中”与“静态存储”的全链路。
- 对象锁定与不可变性(WORM):通过设置锁定策略,可以防止数据被恶意勒索软件修改或意外删除,满足严苛的合规性要求。

4. 快速部署与可视化管理
在掌握了底层的“内功心法”后,MinIO 最令开发者惊喜的特性莫过于其极简的部署流程。作为一个不到 100MB 的静态二进制文件,它既可以运行在物理服务器上,也可以轻松地跑在 Docker 容器或 Kubernetes 集群中。
4.1 基于 Docker 的极简安装
对于个人开发者或实验室环境,使用 Docker 部署是最高效的选择。只需一行命令,即可在本地或云服务器上搭建起完整的功能环境。
docker run -p 9000:9000 -p 9001:9001 \
--name minio \
-d --restart=always \
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=password123" \
-v /mnt/data:/data \
minio/minio server /data --console-address ":9001"
部署要点解析:
- 双端口机制:MinIO 区分了两个关键端口:9000 是 API 访问端口(用于程序代码调用),9001 是 Console 管理界面端口(用于浏览器访问)。
- 权限初始化:通过
MINIO_ROOT_USER和MINIO_ROOT_PASSWORD设置管理员账号密码。 - 数据持久化:使用
-v参数将宿主机的目录挂载到容器内的/data,确保容器重启或销毁时数据不会丢失。
4.2 现代化管理控制台(Console)
告别了传统存储系统枯燥的命令行操作,MinIO 自带了一个非常直观、美观的 Web 管理后台。通过浏览器访问 http://服务器IP:9001 即可进入。
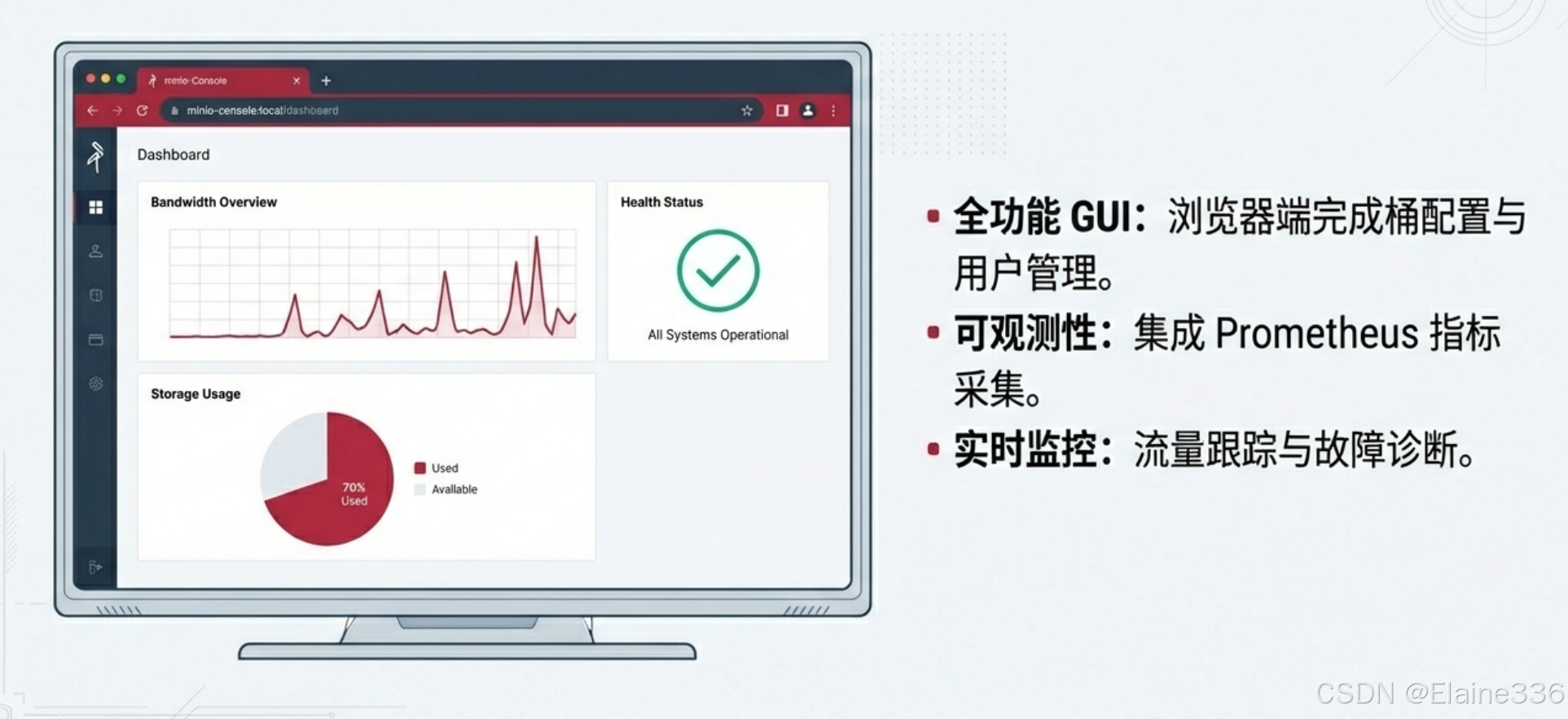
控制台核心功能:
- Bucket(存储桶)管理:只需点击几下即可创建、删除存储桶,并为不同的桶配置访问策略(Public/Private/Custom)。
- 可视化监控:控制台集成了带宽概览、存储使用率、系统健康状态等关键指标,支持与 Prometheus 等监控系统对接。
- 身份管理(IAM):支持细粒度的用户权限控制。可以为不同的项目成员创建独立的 Access Key 和 Secret Key,并分配特定的读写策略。
- 实时审计与日志:可以直观地查看到每一个 API 请求的来源、操作类型和结果,极大地方便了开发调试。
4.3 进阶部署:Kubernetes 原生支持
如果项目需要处理海量数据或实现高可用集群,MinIO 提供了完善的 Kubernetes Operator 模式。
在 K8s 环境下,MinIO 可以作为原生的“存储服务”运行,支持通过 CRD(自定义资源定义)进行自动化部署。这种模式下,系统能够实现多租户隔离,不同项目间的存储、计算和网络资源互不干扰,是构建企业级私有云存储的首选方案。
5. Python SDK 快速集成
MinIO 的核心竞争力之一在于其卓越的**开发者优先(Developer First)**体验。由于完全兼容 S3 协议,它不仅支持官方提供的各种语言 SDK,还可以直接使用 AWS 官方的库(如 Python 的 boto3)。对于大多数项目而言,使用 MinIO 官方提供的轻量级 Python SDK 是最高效的选择。
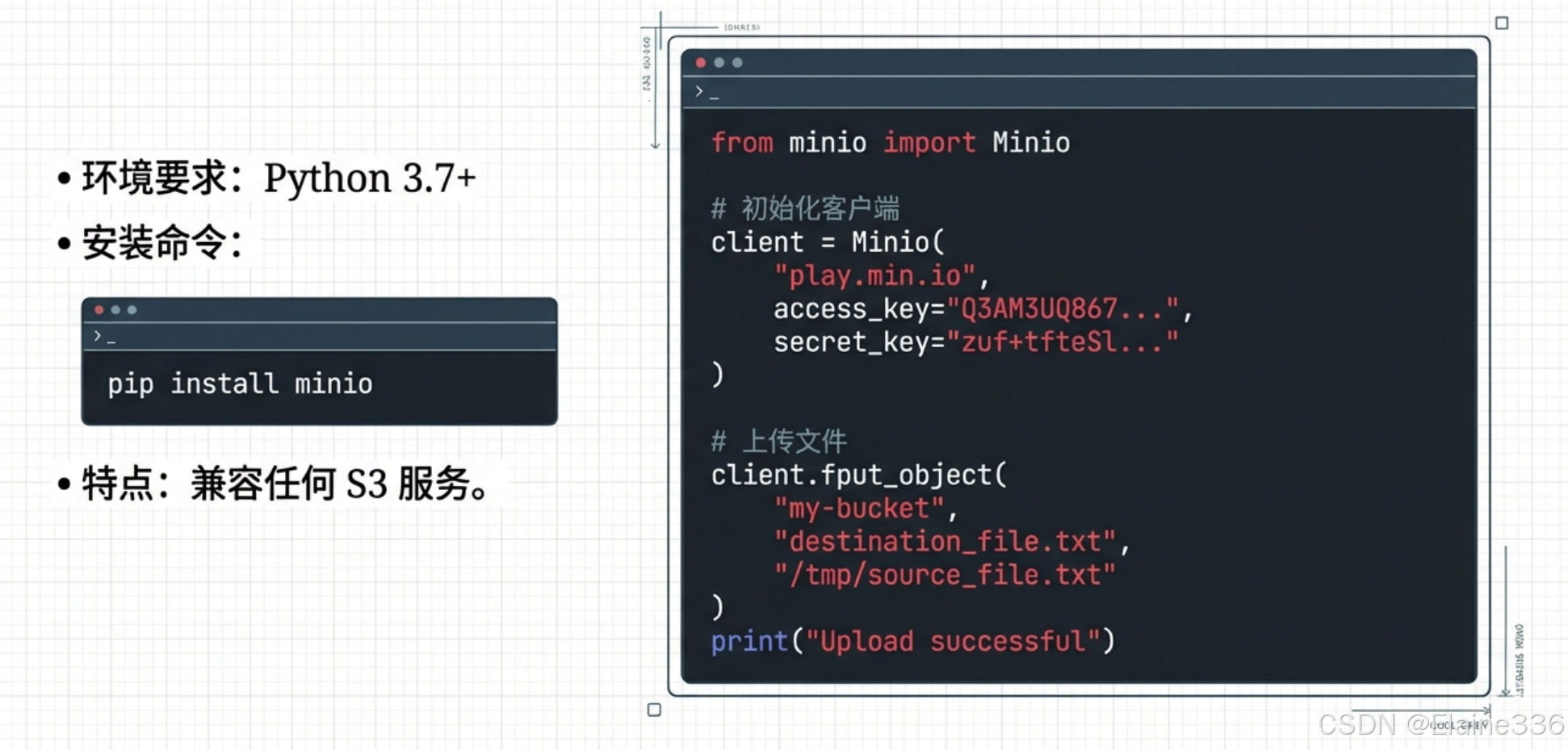
5.1 环境要求与安装
MinIO Python SDK 对环境的要求非常低,仅需 Python 3.7+ 版本即可运行。可以通过标准的包管理工具 pip 完成安装:
pip install minio
5.2 初始化客户端
在代码中调用 MinIO 服务,首先需要建立与服务器的连接。初始化过程需要提供 Endpoint(服务地址)、Access Key 和 Secret Key。
from minio import Minio
# 初始化客户端
client = Minio(
"127.0.0.1:9000", # API 端口
access_key="admin", # 访问密钥
secret_key="password123", # 安全密钥
secure=False # 学习环境通常不使用 HTTPS,设为 False
)
5.3 核心业务逻辑实现
一旦客户端初始化完成,文件的管理操作将变得异常简单。以下是几个最常用的操作场景:
- 确保存储桶(Bucket)存在:在上传文件前,通常需要检查目标桶是否存在,若不存在则自动创建。
- 文件上传:支持直接从本地路径上传文件(
fput_object),也支持通过文件流(Stream)上传。
一个典型的上传流程如下:
bucket_name = "project-data"
# 1. 检查并创建 Bucket
if not client.bucket_exists(bucket_name):
client.make_bucket(bucket_name)
# 2. 上传文件
client.fput_object(
bucket_name, # 目标存储桶
"images/avatar.png", # 对象名称(支持路径格式)
"/local/path/test.png" # 本地文件路径
)
print("Upload successful!")
5.4 预签名链接(Presigned URL)
在 Web 项目或移动端应用中,直接将存储桶设置为 Public 往往存在安全风险。MinIO 提供的预签名 URL 功能是解决这一问题的专业方案:
- 临时授权:为私有存储桶中的文件生成一个具有时效性的 URL(例如 1 小时内有效)。
- 安全性:无需暴露服务器密钥,即可让前端用户安全地下载或预览受限资源。
5.5 “一次编写,到处运行”的优势
由于 MinIO 严格遵循 S3 标准,在开发阶段编写的这些 Python 代码具备极强的通用性。
- 环境无缝切换:在本地开发时连接私有 MinIO,上线时只需将
Endpoint和Keys修改为云厂商的参数,底层逻辑代码无需改动一行。 - 生态复用:可以使用
boto3、s3fs等成熟的 Python 生态库直接操作 MinIO,这为数据科学、自动化运维等复杂场景提供了极大的便利。
6. MinIO 能帮你解决哪些业务场景?
MinIO 不仅仅是一个简单的文件存储容器,它已经成为了现代数据基础设施中的核心组件。凭借其卓越的吞吐性能和 S3 兼容性,MinIO 在从个人项目到企业级架构的多种场景中都有着不可替代的地位。
6.1 AI 与机器学习(AI/ML)的“数据燃料库”
在人工智能和深度学习领域,模型的训练质量很大程度上取决于对海量非结构化数据(如图像、视频、音频、日志)的读取效率。
- 高吞吐数据层:MinIO 专为高吞吐量设计,能够支撑 TensorFlow、PyTorch 等主流框架进行快速的数据迭代。
- 存算分离架构:通过将存储与计算资源解耦,开发者可以灵活地扩展计算节点而无需担心存储瓶颈,这在处理大规模训练集时尤为关键。
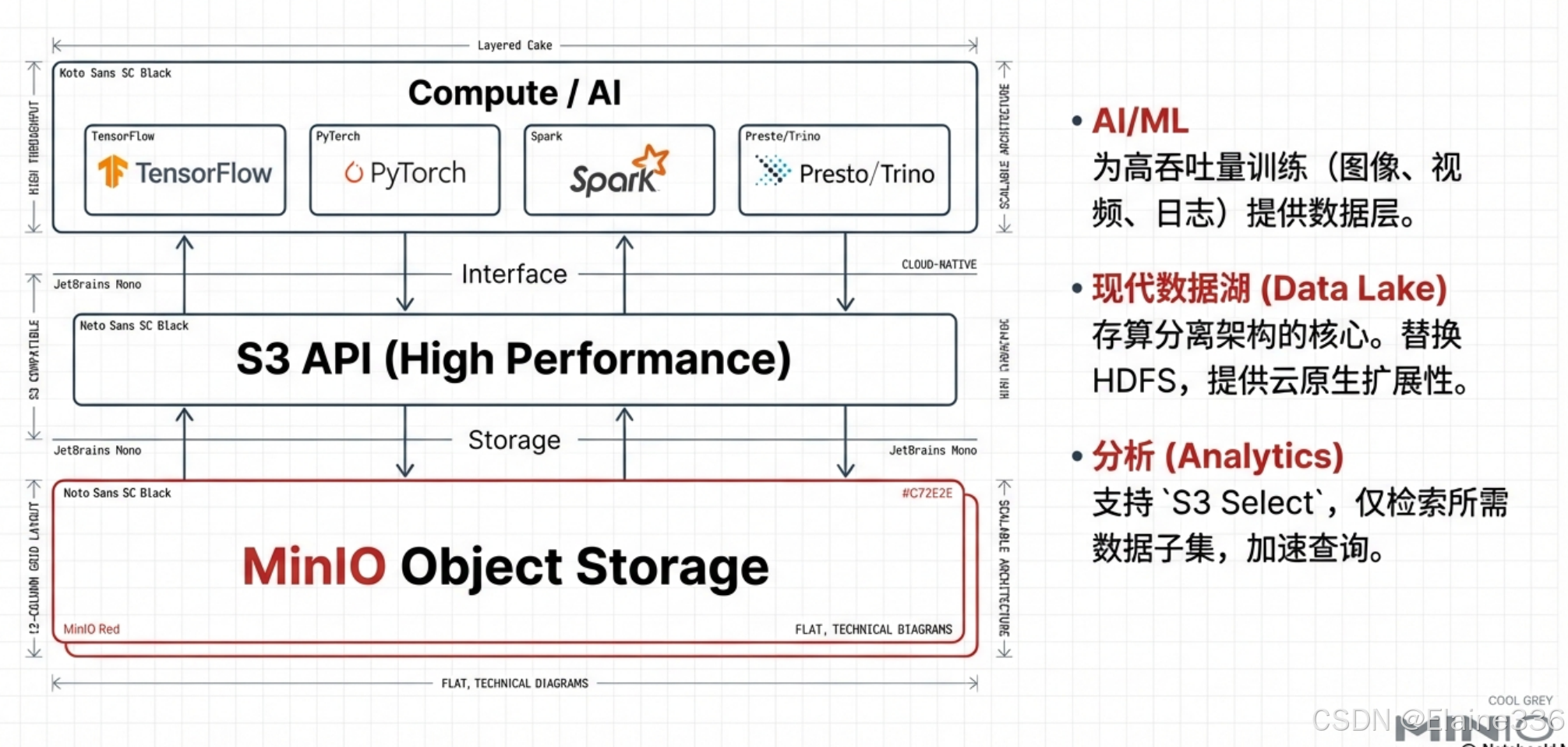
6.2 现代数据湖(Data Lake)与分析
随着大数据技术从传统的 HDFS 转向云原生架构,MinIO 成为了构建私有化数据湖的首选。
- 替代 HDFS:在很多现代大数据处理流程中,MinIO 凭借更轻量的部署和更强的扩展性,正在逐步替代复杂的 HDFS 系统。
- 高效集成:它能够与 Spark、Presto、Trino 等分析引擎完美集成,利用“S3 Select”功能,甚至可以仅检索数据集中所需的子集,从而大幅加速查询过程。
6.3 现代化基础设施与全球生态集成
MinIO 的强大之处在于它极宽的生态护城河。无论是在本地数据中心、公网云还是边缘侧,它都能与现有的技术栈无缝集成。
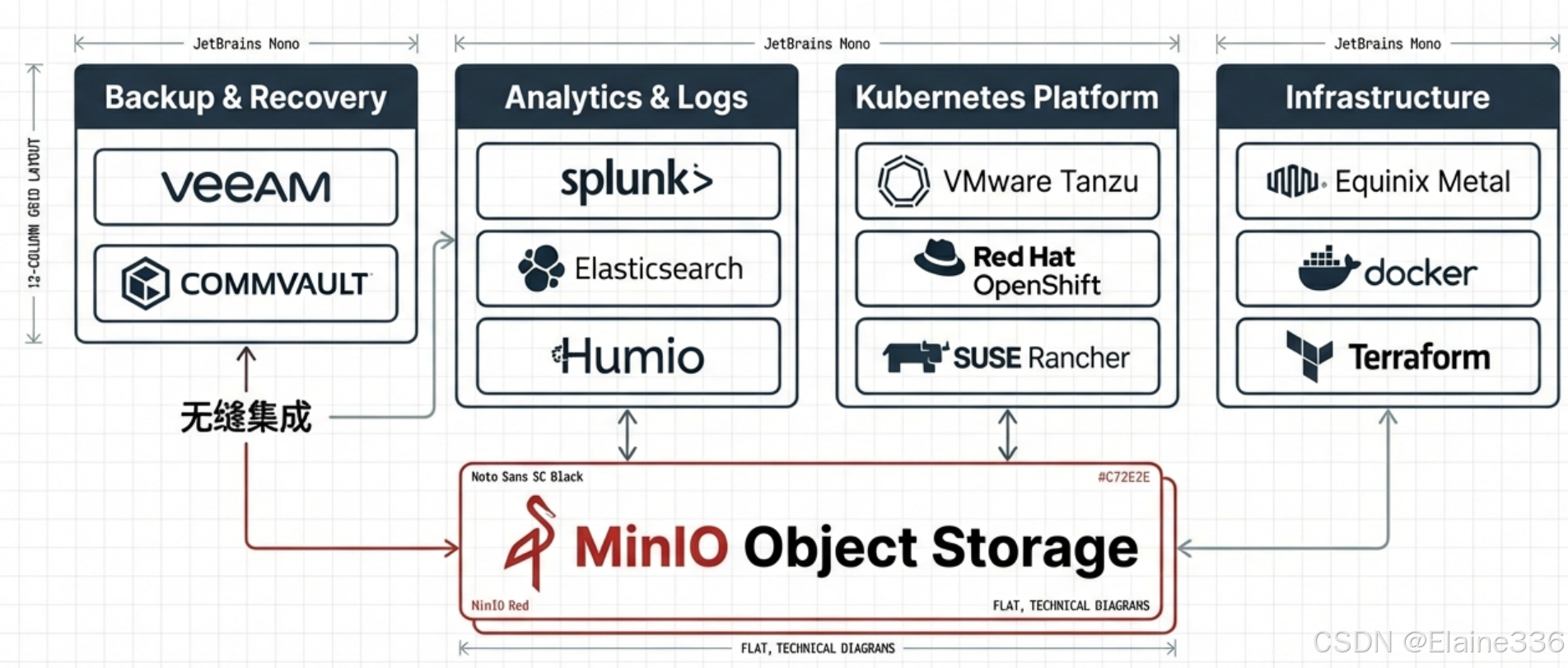
- 备份与灾备(Backup & Recovery):MinIO 常被用作高性能的备份目标,支持与 Veeam、Commvault 等专业备份软件集成,确保关键数据的安全冗余。
- 自动化运维:支持与 Terraform、Docker、Kubernetes 等基础设施即代码(IaC)工具配合,实现存储资源的快速编排与自动化交付。
- 日志与分析:可以作为 Splunk、Elasticsearch、Humio 等日志分析工具的冷热数据存储层,在降低成本的同时保证查询响应速度。
6.4 独立开发者的实用方案
对于个人项目或中小型团队,MinIO 同样提供了极具吸引力的解决方案:
- 私有图床与静态资源托管:配合 PicGo 等工具,可以搭建完全自控的私有图床,彻底告别公网 OSS 的流量支出。
- 数据库自动备份:通过简单的脚本,可以将定时生成的数据库镜像(如 MySQL/PostgreSQL dump)自动上传至 MinIO,并利用其生命周期管理功能实现旧数据的自动过期。
7. 总结:开启高性能存储之旅
7.1 给开发者的部署建议
- 学习与开发环境:推荐使用单节点 Docker 部署,仅需百兆内存即可运行。这能让开发者在不产生云端费用的情况下,完全掌握 S3 协议的开发技能。
- 生产环境:推荐至少使用 4 个节点构建分布式集群,以启用纠删码(Erasure Coding)保护。正如生产环境清单所示,应确保节点间的时间同步(NTP)及高性能 NVMe 驱动器的独占访问。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)