警惕!“越聊越笨“:深度解析LLM多轮对话性能崩塌的四大元凶
微软研究院最新研究揭示,大模型(LLM)在多轮对话中可靠性会从单轮的95%骤降至45%,但能力仅下降15%。主要原因是注意力机制的U型偏置、计算复杂度指数增长、错误累积效应及对话历史碎片化表示。实验显示GPT-4o等多轮准确率下降超30%。应对策略包括对话压缩、RAG增强记忆、结构化Prompt设计和定期会话重启。研究强调需理解模型物理限制,采用工程化方法管理对话状态,以提升AI系统的可靠性。
标签: 大模型 LLM Transformer 注意力机制 上下文学习 AIGC
TL;DR 微软研究院最新论文(2025.05)通过20万次实验证实:多轮对话时,模型的 可靠性(Reliability) 会从单轮的95%暴跌至45%,而 能力(Aptitude) 仅下降15%。这不是模型变"笨"了,而是系统性的注意力漂移、错误累积和物理约束共同作用的结果。
一、现象:从"聪明助手"到"糊涂话痨"
你是否遇到过这种情况?
- 第1-3轮:模型逻辑清晰,引用准确,完美理解上下文
- 第5-8轮:开始忽略你之前的约束条件,重复已解决的问题
- 第10轮+:出现幻觉(Hallucination),逻辑混乱,甚至推翻之前的正确结论
这不是错觉。微软研究院在2025年5月的论文《LLMs Get Lost In Multi-Turn Conversation》中1,通过20万次多轮对话模拟证实:多轮对话会显著降低LLM的可靠性,但影响程度因任务类型而异。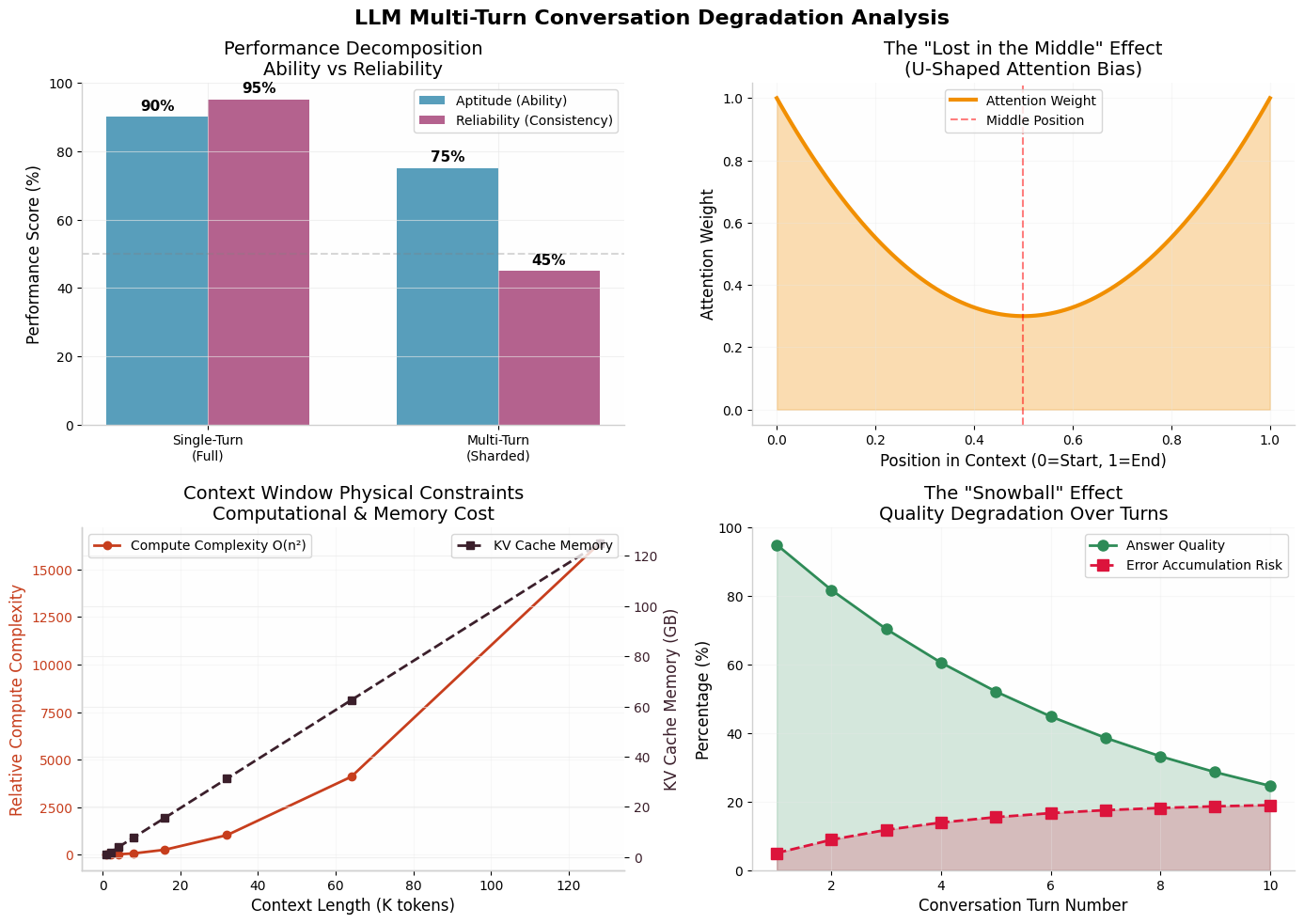
图1:多轮对话性能下降的四个维度分析。左上图显示能力与可靠性的分解;右上图展示"Lost in the Middle"注意力U型偏置;左下图呈现上下文窗口的物理约束;右下图揭示错误累积的雪球效应。
二、元凶一:注意力机制的"U型偏置"(Lost in the Middle)
2.1 核心机制
Transformer的Softmax注意力机制天然存在位置偏置2。当上下文变长时:
- 头部(Head):最开始的系统提示和关键定义,注意力权重保持高位
- 中部(Middle):中间轮次的历史对话,注意力权重显著下降(“迷失”)
- 尾部(Tail):最近的几轮对话,注意力权重再次升高
这导致模型"记得"你是谁,也"记得"你刚才说了什么,但忘了第3轮时你纠正过的重要约束。
2.2 数学解释
注意力权重计算:
Attention(Q, K, V) = softmax(QK^T / √d_k) V
当序列长度 n n n增加时,Softmax的指数特性使得:
- 靠近当前token的key获得高权重(局部性)
- 远离的key被"淹没"在指数求和的分母中
- 即使使用RoPE、ALiBi等位置编码,也只能缓解,无法根除
三、元凶二:推理复杂度的指数级增长 O ( n 2 ) O(n^2) O(n2)
多轮对话的hidden state交互遵循:
计算复杂度 ∝ (上下文token数)²
内存占用 ∝ 上下文token数
这带来两个工程现实3:
| 上下文长度 | 相对计算量 | KV Cache内存 |
|---|---|---|
| 4K tokens | 1x | 2 GB |
| 32K tokens | 64x | 16 GB |
| 128K tokens | 1024x | 64 GB |
当对话超过10轮(约8K-16K tokens),模型必须在信息压缩和精确召回之间做权衡。大多数实现会选择近似注意力(如Windowed Attention、Sparse Attention),这 inevitably 引入信息损失。
四、元凶三:错误累积的"雪球效应"
多轮对话是一个马尔可夫过程,当前轮次依赖前一轮的输出:
State_t = f(State_{t-1}, User_Input_t)
如果第2轮模型产生了微小幻觉(概率5%),第3轮基于这个幻觉推理,错误概率上升到15%,第4轮可能达到40%…这就是错误级联(Error Cascade)4。
更严重的是确认偏误(Confirmation Bias):模型倾向于维护之前轮次的立场,即使面对矛盾证据,导致"嘴硬"现象。
五、元凶四:对话历史的"碎片化"表示
现代LLM API(如GPT-4、Claude)的对话历史通常以JSON数组形式传入:
[
{"role": "system", "content": "你是专业助手..."},
{"role": "user", "content": "问题1"},
{"role": "assistant", "content": "回答1"},
{"role": "user", "content": "问题2"}
]
这种**分片(Sharded)表示与单轮完整提示(Full)**存在本质差异:
- 信息熵增加:JSON标点、role标签挤占有效上下文
- 注意力掩码干扰:系统必须区分"历史 assistant 输出"和"当前待生成内容"
- 位置编码错乱:绝对位置编码下,历史对话的相对位置关系被破坏
微软论文发现,在同等token数下,分片对话的可靠性比单轮完整提示低27%1。
六、量化评估:不是变"笨",而是变"不稳定"
使用WikiMQ(微软提出的多轮问答基准测试)评估主流模型1:
- GPT-4o:多轮准确率下降 31.4%(单轮83% → 多轮51.6%)
- DeepSeek-V3:下降 22.9%(单轮82.6% → 多轮59.7%)
- RAG增强版:引入外部知识检索后,性能可恢复60-70%
关键洞察:模型的核心能力(Aptitude)并未显著下降,但稳定性(Reliability)崩溃了。这意味着模型"会做这道题,但在长对话中有时会做对,有时做错"。
七、工程师的应对策略
7.1 对话压缩(Dialogue Compression)
定期使用LLM自身总结历史对话,提取关键约束:
def compress_dialogue(history, max_tokens=2000):
"""
滑动窗口压缩:保留系统提示+最近2轮+摘要
"""
if not history or len(history) < 4:
return history
# 保留系统提示和最近轮次
compressed = [history[0]] # system prompt
# 中间部分用LLM总结
middle = history[1:-2]
summary_prompt = f"Summarize the following dialogue into key constraints and facts: {middle}"
summary = llm_generate(summary_prompt)
compressed.append({"role": "system", "content": f"Previous context summary: {summary}"})
compressed.extend(history[-2:]) # 保留最近2轮
return compressed
7.2 RAG增强记忆(外部知识库)
将关键信息外置到向量数据库,避免依赖模型记忆:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 每轮对话提取重要事实存入向量库
def update_memory(user_input, assistant_output):
facts = extract_facts(f"{user_input}\n{assistant_output}")
vectorstore.add_texts(facts)
# 检索时带上相关历史
def retrieve_context(query, k=3):
relevant_history = vectorstore.similarity_search(query, k=k)
return format_context(relevant_history)
7.3 结构化Prompt设计
使用XML标签强制模型关注关键约束:
<system>
<critical_constraints>
- 用户是Python专家,不需要基础解释
- 必须使用Python 3.10+语法
</critical_constraints>
</system>
<current_turn>
<user>帮我优化这段代码...</user>
</current_turn>
7.4 定期"重启"会话
对于关键任务,每3-5轮主动开启新会话,并携带压缩后的上下文摘要。这是目前最有效的实践:
MAX_TURNS = 4
def chat_with_reset(user_input):
if len(session_history) >= MAX_TURNS * 2: # 每轮包含user+assistant
summary = generate_summary(session_history)
session_history = [
{"role": "system", "content": f"Session summary: {summary}"},
{"role": "user", "content": user_input}
]
else:
session_history.append({"role": "user", "content": user_input})
response = llm_chat(session_history)
session_history.append({"role": "assistant", "content": response})
return response
八、总结:与AI对话的工程化思维
"越聊越笨"不是模型退化,而是长序列建模的固有难题。作为工程师,我们需要:
- 理解物理限制: O ( n 2 ) O(n^2) O(n2)复杂度和有限的上下文窗口是铁律
- 设计防御性Prompt:关键约束要重复、置顶、结构化
- 管理会话状态:像管理数据库连接池一样管理对话历史
- 人机协作:超过5轮的关键任务,主动断开并重建上下文
只有理解这些底层机制,我们才能设计出真正可靠的AI Agent系统,而不是陷入"反复纠正AI"的低效循环。
参考链接:
-
Microsoft Research. (2025). LLMs Get Lost In Multi-Turn Conversation. arXiv preprint arXiv:2505.06120. ↩︎ ↩︎ ↩︎
-
Liu, N. F., et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172. ↩︎
-
Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017. ↩︎
-
Zhao, W. X., et al. (2023). A Survey of Large Language Models. arXiv:2303.18223. ↩︎

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)