大语言模型如何重塑金融研究?一份全景式综述(下)
本文综述了大语言模型(LLMs)在金融研究中的最新进展,涵盖其在金融预测、量化交易和风险管理等领域的应用。重点讨论了代理模型、多智能体系统的兴起,以及模型幻觉、可解释性和因果推断等挑战。最后,展望了未来研究方向,包括数据质量提升、模型可解释性增强和监管合规性等关键问题。
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者:丁闪闪 (lianxhcn@163.com)
曾咏新 厦门大学 (zengyongxinhpe@163.com)
参考资料: Nie, Y., Kong, Y., Dong, X., Mulvey, J. M., Poor, H. V., Wen, Q., & Zohren, S. (2024). A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges (Version 1). arXiv. Link, PDF, Google.
提要:本文综述了大语言模型(LLMs)在金融研究中的最新进展,涵盖其在金融预测、量化交易和风险管理等领域的应用。重点讨论了代理模型、多智能体系统的兴起,以及模型幻觉、可解释性和因果推断等挑战。最后,展望了未来研究方向,包括数据质量提升、模型可解释性增强和监管合规性等关键问题。
- Title: 大语言模型如何重塑金融研究?一份全景式综述(下)
- Keywords: 大语言模型, 金融预测, 量化交易, 风险管理, 代理模型, 多智能体系统, 模型幻觉, 可解释性, 因果推断
- 查看本系列推文:大语言模型如何重塑金融研究?
在 大语言模型如何重塑金融研究?一份全景式综述(上) 中,我们介绍了 LLMs 在金融 NLP 任务中的应用,包括文本摘要、信息提取、情感分析、知识图谱构建等核心技术。
本文(下篇)将聚焦 LLMs 在金融应用层面的前沿进展,重点探讨三个方面:
- LLMs 在金融预测与分析中的应用,包括股价预测、信用风险评估、异常检测等任务;
- LLMs 在量化交易、投资组合管理和风险监管中的实践;
- LLMs 面临的核心挑战和未来研究方向,特别是数据质量、模型可解释性、计算成本和监管合规等关键问题。
1. 金融预测与分析
1.1 时间序列分析的新范式
时间序列分析 是金融研究的核心任务,传统方法如 ARIMA、GARCH 等统计模型在处理线性关系时表现良好,但面对金融市场的非线性、高维度、时变特征时常常力不从心。深度学习模型如 LSTM、GRU 虽然能够捕捉时序依赖,但需要大量标注数据,且可解释性差。LLMs 的出现为时间序列分析提供了新思路。
LLMs 应用于时间序列分析的理论基础在于:其 Transformer 架构本质上就是为处理序列数据设计的,文本序列和时间序列在结构上存在相似性——都是按时间顺序排列的离散观测值。Zhou et al. (2024) 开创性地证明了基于 GPT-2 的模型可以处理多种时间序列任务,包括预测、异常检测、分类和缺失值填补。他们的关键洞察是:虽然 LLMs 是在文本数据上预训练的,但其学到的模式识别和序列建模能力具有跨模态的泛化性。
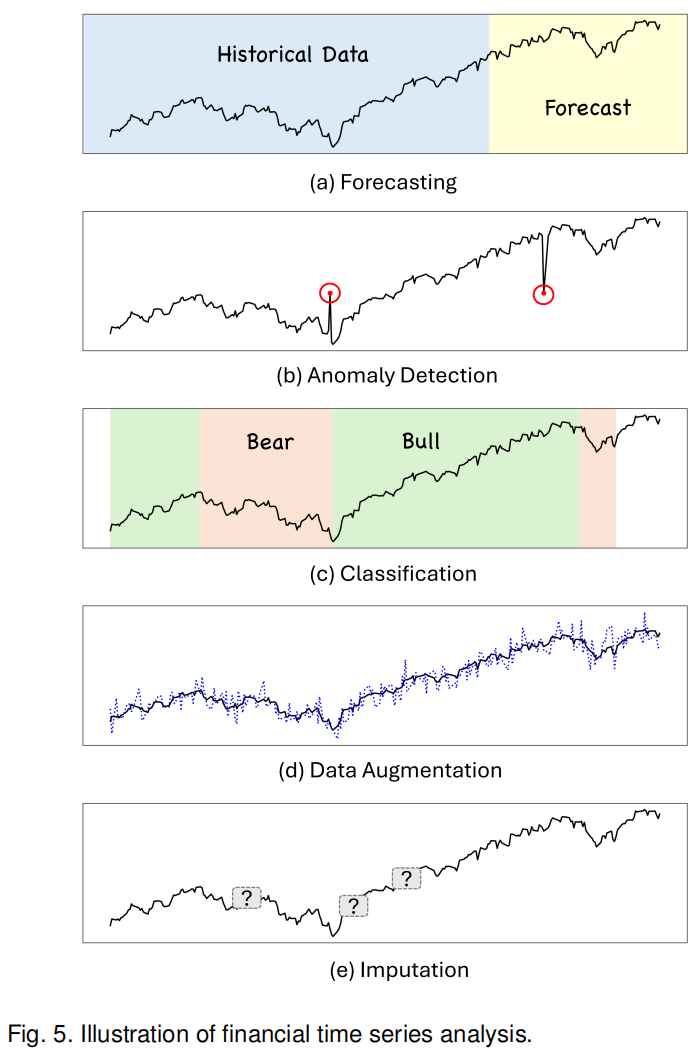
Gruver et al. (2024) 进一步探索了预训练 LLMs 的零样本时间序列预测能力。通过适当的数据标记化 (tokenization),将时间序列数值转换为 LLM 可理解的表示,他们发现 LLMs 能够隐式理解时间模式并生成预测,而无需在目标数据集上进行显式训练。这一发现对金融应用意义重大——意味着研究者可以用通用 LLM 直接处理金融时间序列,无需从头训练专用模型。
Jin et al. (2024) 提出的「重编程」(reprogramming) 技术进一步提升了 LLM 在时间序列预测中的表现。该方法将时间序列数据转换为 LLM 更易理解的表示形式,类似于为 LLM 设计了一种「金融语言」。实验表明,经过重编程的 LLM 在多个金融时间序列预测任务上达到了业界领先水平。
然而,LLMs 在时间序列分析中也面临挑战。最大的问题是 数值敏感性——LLMs 原本设计用于处理离散的词汇 tokens,对连续数值的表示能力有限。「5.2%」和「52%」在数值上相差十倍,但在文本嵌入空间中可能距离很近。研究者们正在探索混合架构,将 LLMs 的语义理解能力与专门的时间序列编码器结合,以充分发挥两者优势。
1.2 股价预测:整合多源信息
股价预测一直是金融研究的「圣杯」,也是检验新方法的试金石。传统的技术分析依赖历史价格和交易量,基本面分析关注财务指标和公司基本面,两者往往孤立使用。LLMs 的优势在于能够同时整合这些异质信息源,并加入文本数据(如新闻、社交媒体、财报)这一维度。
论文介绍的一项重要研究是针对 NASDAQ-100 股票的预测。研究者使用 LLMs 整合了多种数据源:历史价格数据、技术指标、财务报表、新闻报道、社交媒体讨论。关键创新在于使用指令微调 (instruction-based fine-tuning) 和思维链推理 (chain-of-thought reasoning)。模型不仅给出预测结果,还解释推理过程,例如:「考虑到公司最新财报显示营收超预期 15%,加上科技板块整体向好,以及社交媒体情绪转为积极,预测股价上涨概率为 68%」。
Chen et al. (2024) 提出的框架更进一步,将 ChatGPT 与图神经网络 (GNN) 结合。他们让 LLM 从财经新闻中提取公司间的关系网络(如供应链关系、竞争关系、合作关系),这些关系随时间演化,形成动态图结构。然后用 GNN 在这个知识图上进行信息传播,最终预测股价走势。实验表明,这种方法在年化累积收益率上显著优于基准方法,且波动率更低。
多模态分析 是另一个前沿方向。Wimmer and Rekabsaz (2024) 利用 CLIP 模型(一种视觉-语言多模态模型)同时分析财经新闻的文本和配图。他们发现,图片信息(如 CEO 的表情、产品发布会的场景、工厂照片)包含文本未能充分表达的信号。在预测德国股指 DAX 的任务中,多模态模型在准确率、F1 分数等指标上全面超越纯文本模型。这提示研究者:金融信息不仅存在于文字和数字中,视觉线索同样重要。
RiskLabs 框架展示了 LLMs 在整合多模态数据方面的潜力。该框架融合了三类数据:(1) 财报电话会议的文本和语音信息(语调、停顿、语速变化可能透露管理层信心);(2) 市场时间序列数据(价格、交易量、波动率);(3) 财报发布前后的新闻数据。通过多阶段处理流程,先用 LLM 分析文本和语音,再用时序模型处理价格数据,最后用多模态融合技术整合所有特征,进行金融风险预测(波动率和方差)。实证结果显示该框架在风险预测任务上表现优异。
但需要警惕的是,LLMs 在金融预测中的表现并非总是出色。Xie et al. (2024) 的研究给出了警示:他们测试 ChatGPT 的零样本多模态股价预测能力,发现其表现不如传统机器学习模型和其他深度学习方法。这说明 LLMs 不是万能的,在缺乏领域适配和充分训练的情况下,其预测能力可能有限。
Lopez-Lira and Tang (2023) 的研究则提供了更乐观的证据。他们让 GPT-4 根据新闻标题预测股票收益,发现 GPT-4 显著优于早期模型(GPT-2、BERT),尤其在处理负面新闻和预测小盘股时表现更好。他们用信息扩散理论、套利限制和投资者认知差异来解释这一现象:小盘股的信息不对称程度更高,散户投资者比例更大,对新闻的反应更慢也更情绪化,因此基于 LLM 的实时情感分析更有优势。
1.3 信用风险评估
信用风险评估是金融机构的核心任务,传统信用评分模型(如 FICO 评分)主要依赖结构化数据:收入、负债、还款历史等。这些模型简单高效,但忽略了大量非结构化信息——借款人的社交媒体行为、消费习惯描述、对财务问题的表述方式,这些「软信息」可能包含重要的信用信号。
Feng et al. (2024) 展示了 LLMs 在信用评分中的潜力。通过指令调优,LLMs 可以理解和整合多种信息源:不仅是传统的财务数据,还包括借款申请中的文本描述、历史沟通记录、甚至社交媒体公开信息(在合规前提下)。研究发现,LLM 驱动的信用评分模型在预测违约方面可以匹敌甚至超越传统模型。
更重要的是,LLMs 有潜力使信用评估更加 包容性。传统模型依赖信用历史,这对「信用白户」(如年轻人、新移民)不利。LLMs 可以利用替代数据源(如教育背景、就业稳定性、租金支付记录)进行评估,为这些群体提供公平的信贷机会。Feng et al. 的研究强调了这一点,但同时警告必须谨慎处理 LLMs 中可能存在的偏见,避免算法歧视。
Cao et al. (2024) 在 RiskLabs 框架中展示了 LLMs 在风险预测中的另一个维度。他们不仅预测违约概率,还预测市场风险(波动率)。通过分析财报电话会议的语言风格变化(如管理层用词是否更加谨慎、回避某些话题),LLM 能够捕捉传统模型遗漏的风险信号。实验表明,加入 LLM 提取的文本特征后,风险预测模型的准确性显著提升。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)