计算机毕业设计Django+LLM大模型知识图谱古诗词情感分析 古诗词推荐系统 古诗词可视化 大数据毕业设计(源码+LW+PPT+讲解)
《基于Django+LLM大模型+知识图谱的古诗词情感分析系统》摘要 本项目结合Django框架、大语言模型(LLM)和知识图谱技术,构建了一个智能古诗词情感分析系统。系统通过LLM(如LLaMA-2/ChatGLM)解析诗词深层语义,利用Neo4j知识图谱存储诗人、朝代、典故等关联信息,采用Django+Bootstrap实现前后端交互。主要功能包括诗词情感分类(悲/喜/怀古等)、关键词解释和关
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
以下是一份关于《Django + LLM大模型 + 知识图谱古诗词情感分析》的任务书模板,结合了Web开发、大语言模型和知识图谱技术,供参考:
任务书:基于Django + LLM大模型 + 知识图谱的古诗词情感分析系统
一、项目背景与目标
-
背景
古诗词是中华文化的重要载体,其情感表达(如悲喜、思乡、壮志等)具有丰富的文学和历史价值。传统情感分析方法多依赖规则或浅层机器学习,难以捕捉诗词的隐喻、典故和复杂语境。结合大语言模型(LLM)的语义理解能力、知识图谱的结构化知识推理能力,以及Django的快速Web开发框架,可构建一个高效、可解释的古诗词情感分析系统。 -
目标
- 设计并实现一个Web系统,支持用户输入古诗词文本或选择经典诗词,自动分析其情感倾向(如“悲”“喜”“怀古”等)。
- 结合LLM(如LLaMA、ChatGLM)提取诗词的深层语义特征,利用知识图谱(如诗人关系、历史背景、典故知识)增强情感分析的可解释性。
- 提供可视化结果展示(如情感分布图、关键词解释、诗人关联分析)。
- 验证系统在经典诗词数据集上的准确率和可解释性。
二、任务内容与分工
1. 系统架构设计
- 技术选型
- Web框架:Django(后端)+ Bootstrap(前端)。
- 大语言模型:LLaMA-2/ChatGLM(用于语义理解和特征提取)。
- 知识图谱:Neo4j(存储诗人、朝代、典故等实体关系)。
- 情感分析模型:基于LLM微调的分类模型或结合知识图谱的推理规则。
- 模块划分
- 数据层:
- 诗词数据集(如《全唐诗》《全宋词》)、诗人知识图谱构建。
- LLM模型部署(通过FastAPI封装为服务)。
- 分析层:
- 诗词预处理(分句、分词、实体识别)。
- 调用LLM提取情感特征,结合知识图谱推理补充上下文。
- 展示层:
- Django提供API接口,前端展示情感分析结果和知识图谱关联信息。
- 数据层:
2. 具体任务分工
| 任务 | 负责人 | 技术栈 | 交付物 |
|---|---|---|---|
| 诗词数据集构建与清洗 | 张三 | Python、Scrapy、Pandas | 结构化诗词数据集(CSV/JSON) |
| 知识图谱设计与构建 | 李四 | Neo4j、Cypher、NLP实体识别 | 知识图谱模式定义、图数据导入脚本 |
| LLM模型部署与微调 | 王五 | Hugging Face、FastAPI、PyTorch | LLM服务接口文档、微调模型权重 |
| 情感分析算法实现 | 赵六 | Django、Scikit-learn/自定义规则 | 情感分析API、测试报告 |
| 前端交互与可视化 | 陈七 | HTML/CSS/JavaScript、ECharts | 情感分布图表、诗人关系图谱页面 |
三、技术路线
- 数据流设计
- 输入:用户提交的诗词文本或系统内置的经典诗词。
- 处理:
- 预处理:分句、分词、实体识别(如识别“长安”“明月”等关键词)。
- LLM分析:调用LLM接口提取情感特征(如“悲凉”“豪迈”)。
- 知识图谱推理:根据诗人、朝代、典故等实体关联,补充上下文(如“李白《静夜思》的思乡情感与盛唐游子文化相关”)。
- 综合判断:结合LLM输出和知识图谱推理结果,生成最终情感标签。
- 输出:情感分析报告(标签、关键词解释、关联知识图谱路径)。
- 关键技术点
- LLM微调:在古诗词领域数据上微调LLM,提升对隐喻和典故的理解能力。
- 知识图谱融合:将LLM提取的实体与知识图谱匹配,增强分析的可解释性。
- 轻量化部署:通过FastAPI封装LLM服务,避免Django直接加载大模型导致的性能问题。
四、时间计划
| 阶段 | 时间 | 里程碑 |
|---|---|---|
| 需求分析与设计 | 第1-2周 | 完成系统架构设计、数据集和知识图谱规划 |
| 数据准备与图谱构建 | 第3-4周 | 诗词数据清洗完成,Neo4j图谱导入测试通过 |
| LLM模型部署与微调 | 第5-6周 | LLM服务接口开发完成,微调模型验证通过 |
| 核心算法开发与集成 | 第7-8周 | 情感分析API开发完成,前后端联调通过 |
| 系统测试与优化 | 第9周 | 性能测试(如响应时间≤1秒)、修复Bug |
| 验收与部署 | 第10周 | 系统上线,提交最终报告 |
五、预期成果
- 系统功能
- 支持用户输入诗词或选择经典作品进行情感分析。
- 展示情感标签(如“悲”“喜”“怀古”)及置信度。
- 提供关键词解释和关联知识图谱路径(如“杜甫→安史之乱→沉郁顿挫”)。
- 交付文档
- 《系统设计文档》(含架构图、API说明)
- 《知识图谱模式定义文档》
- 《LLM微调与部署指南》
- 《测试报告与用户手册》
六、风险评估与应对
| 风险 | 应对措施 |
|---|---|
| LLM对古诗词理解不足 | 结合领域数据微调模型,增加人工规则补充 |
| 知识图谱数据缺失 | 通过爬虫补充诗人、典故数据,手动标注关键实体 |
| 系统响应延迟 | 优化LLM调用方式(如缓存常用诗词结果) |
| 情感标签歧义 | 引入多标签分类,提供用户反馈修正机制 |
七、验收标准
- 系统支持至少500首经典诗词的情感分析,准确率≥80%(人工标注验证)。
- 知识图谱覆盖诗人、朝代、典故等核心实体,关联查询响应时间≤500ms。
- 代码规范,文档齐全,支持横向扩展(如增加诗词数据或知识图谱节点)。
负责人签字:__________
日期:__________
补充说明
- 数据集建议:可使用公开数据集如《中国古典诗歌数据库》(CCPC)或自行爬取诗词网站数据。
- LLM选择:若资源有限,可采用开源模型(如LLaMA-2 7B)或轻量化模型(如Alpaca)。
- 知识图谱扩展:未来可加入诗词意象(如“梅花→高洁”)或诗人社交关系(如“李白与杜甫的交往”)。
可根据实际需求调整技术细节和分工,例如增加移动端适配或引入更多NLP技术(如BERT嵌入增强特征提取)。
运行截图
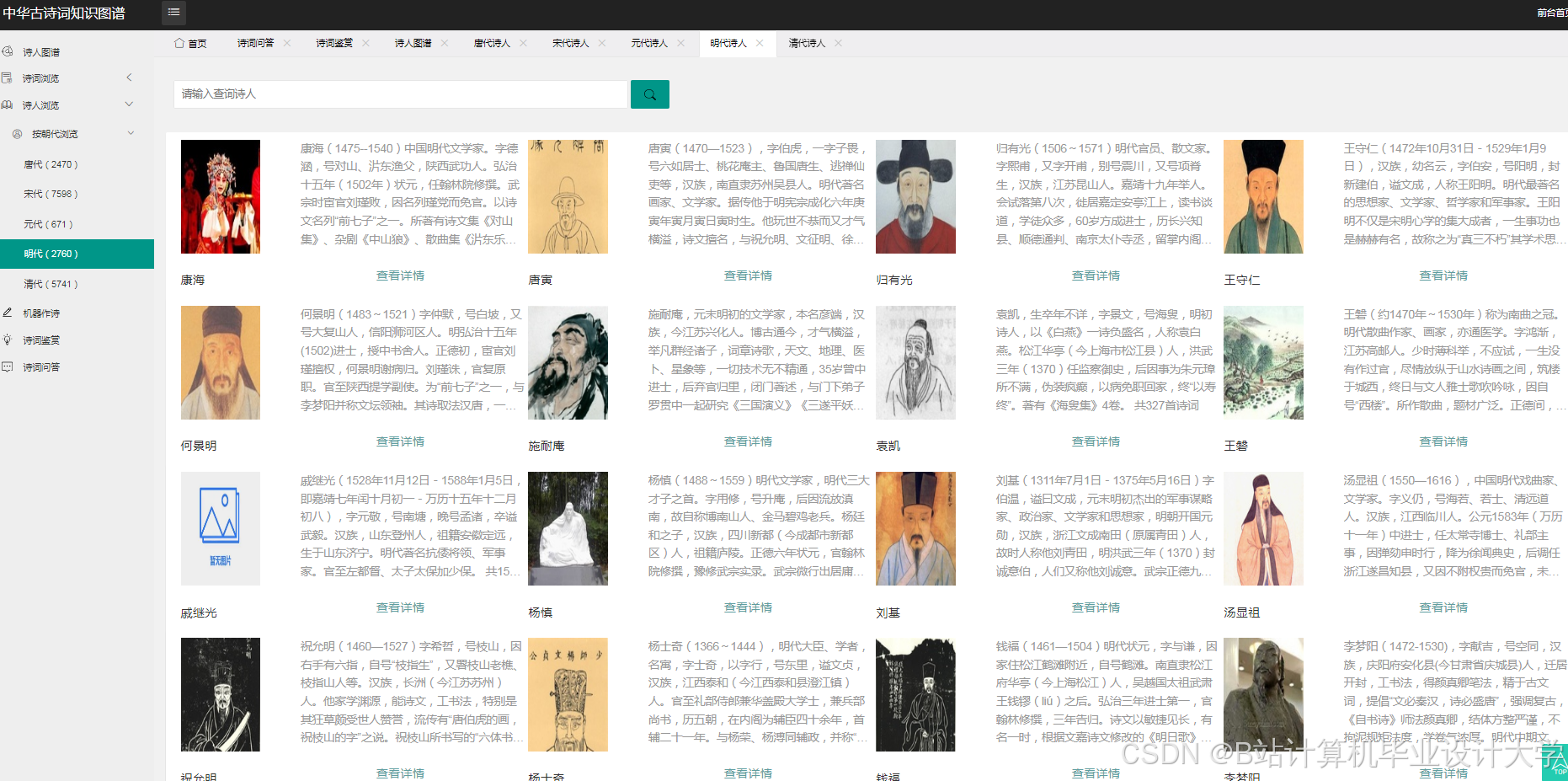
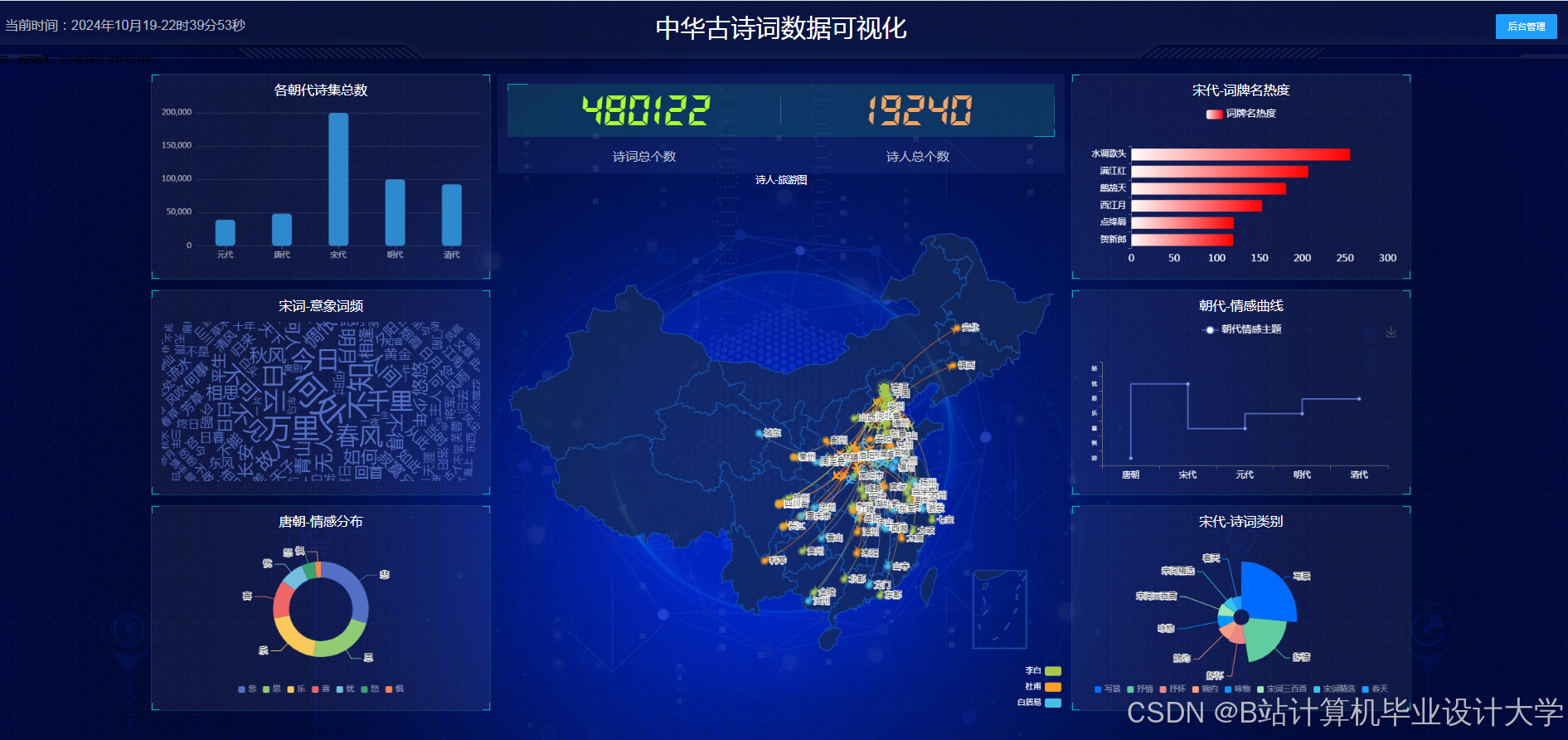
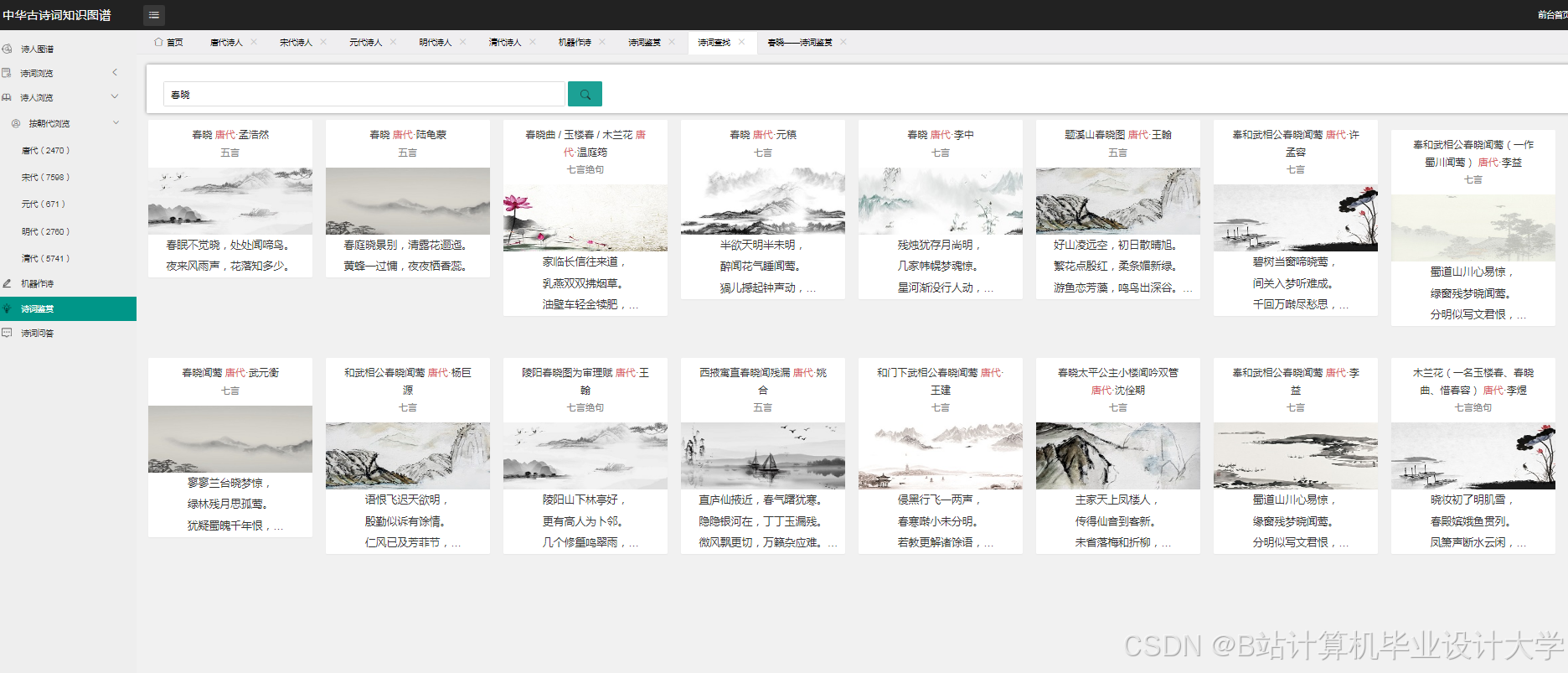
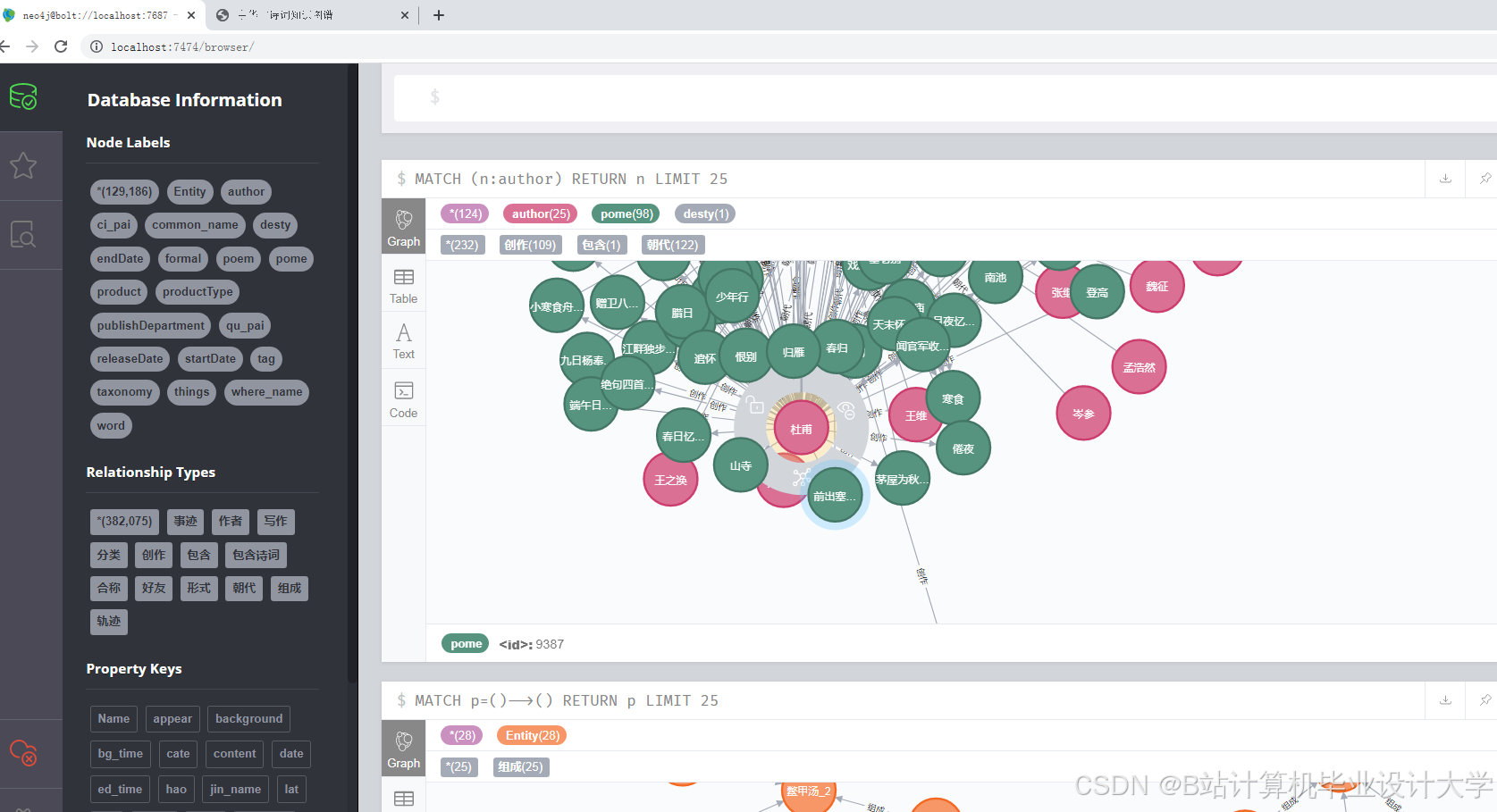
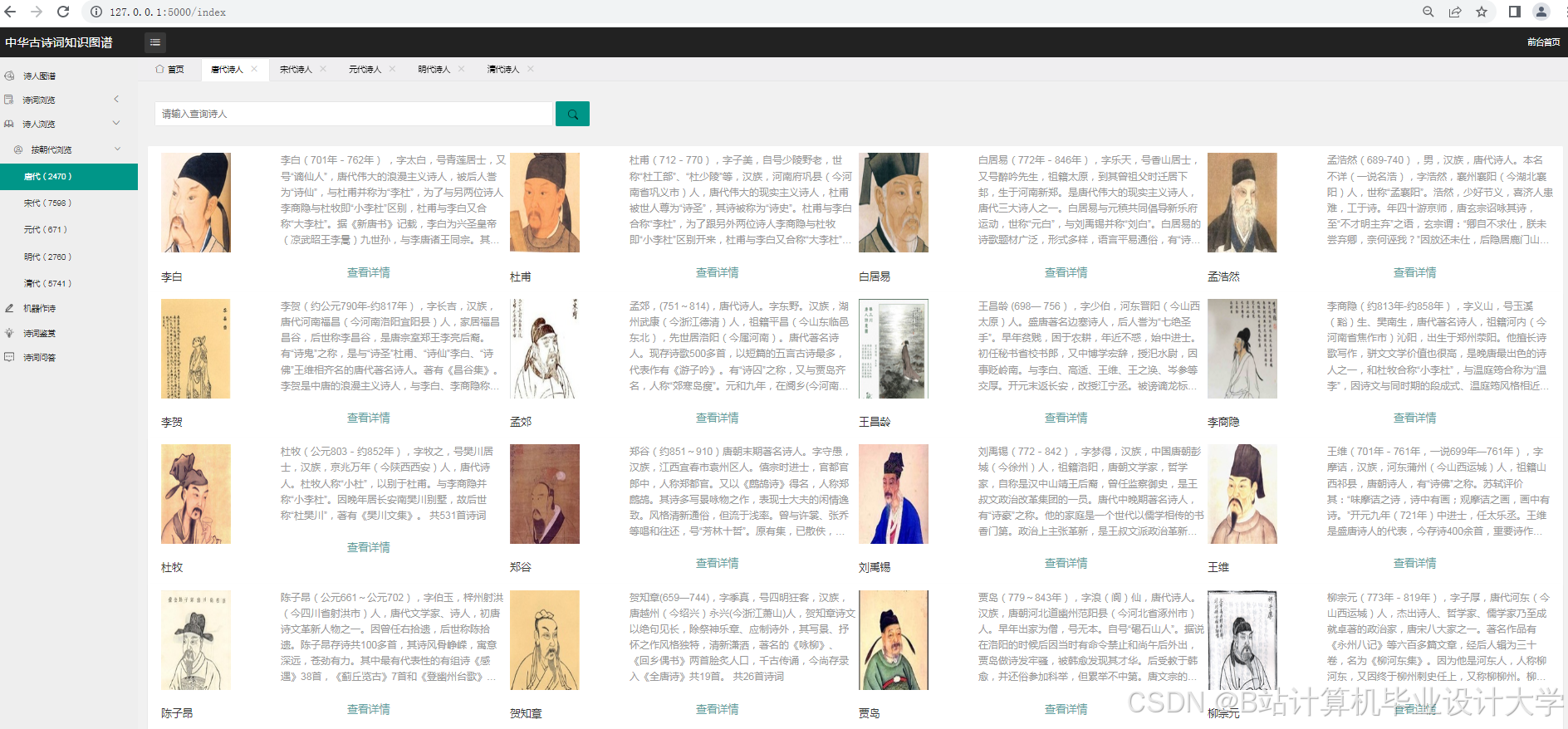
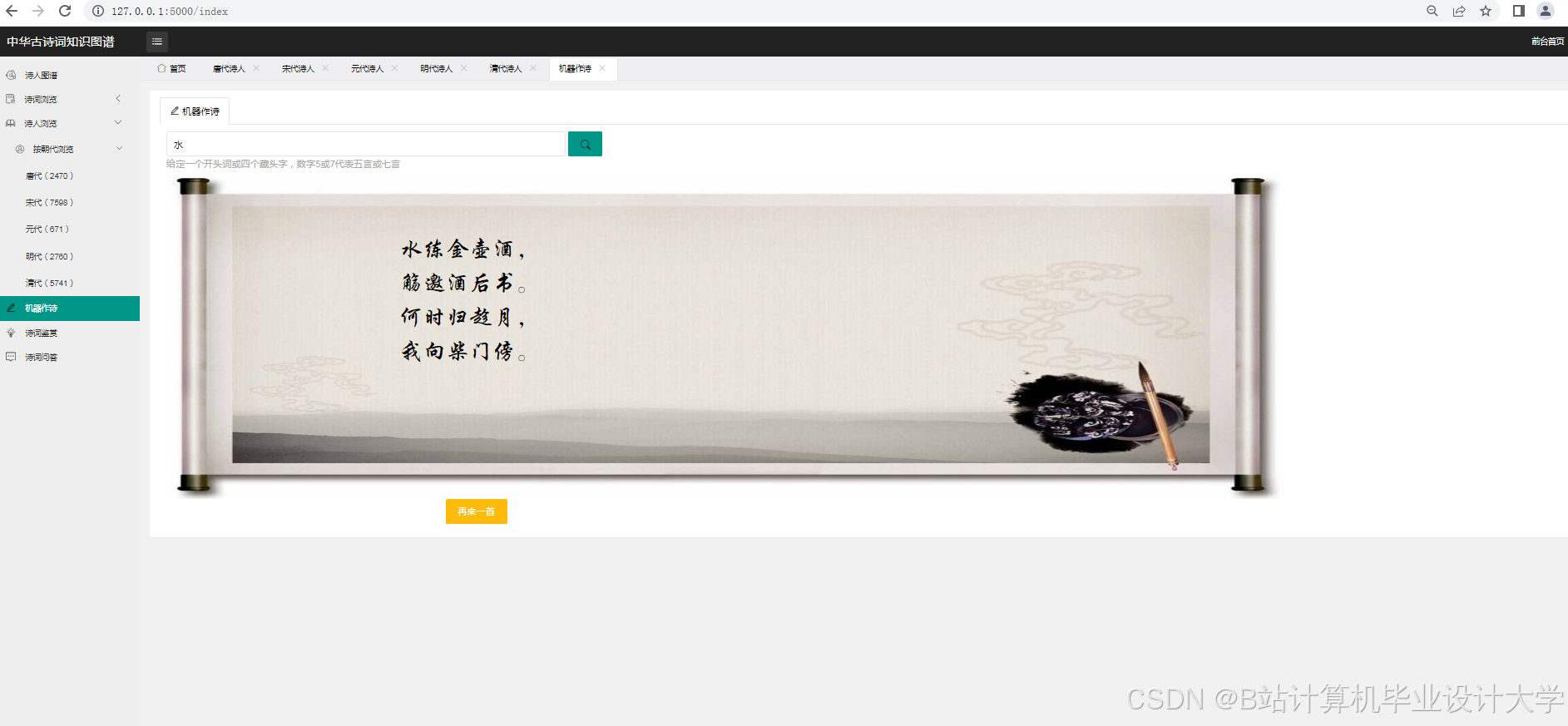
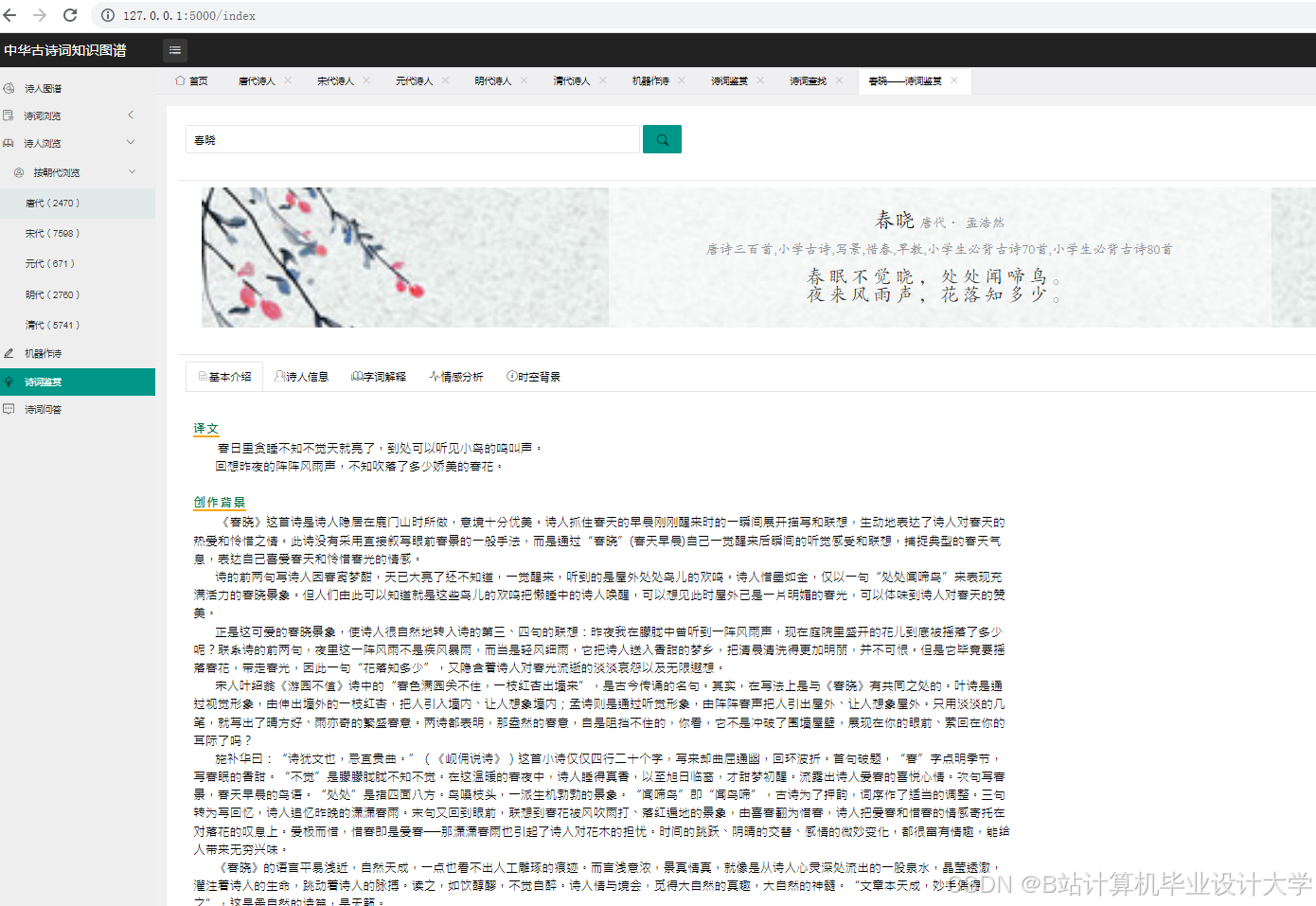
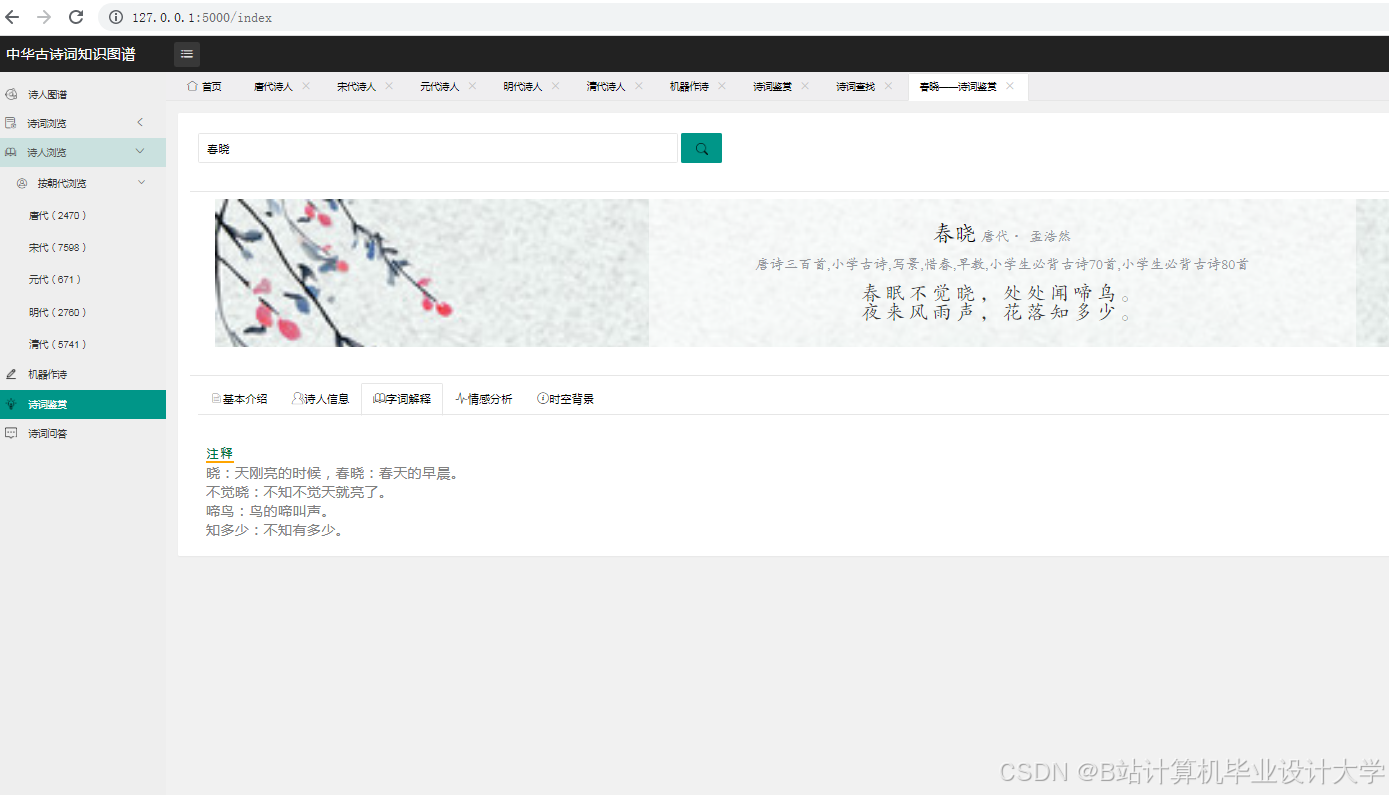
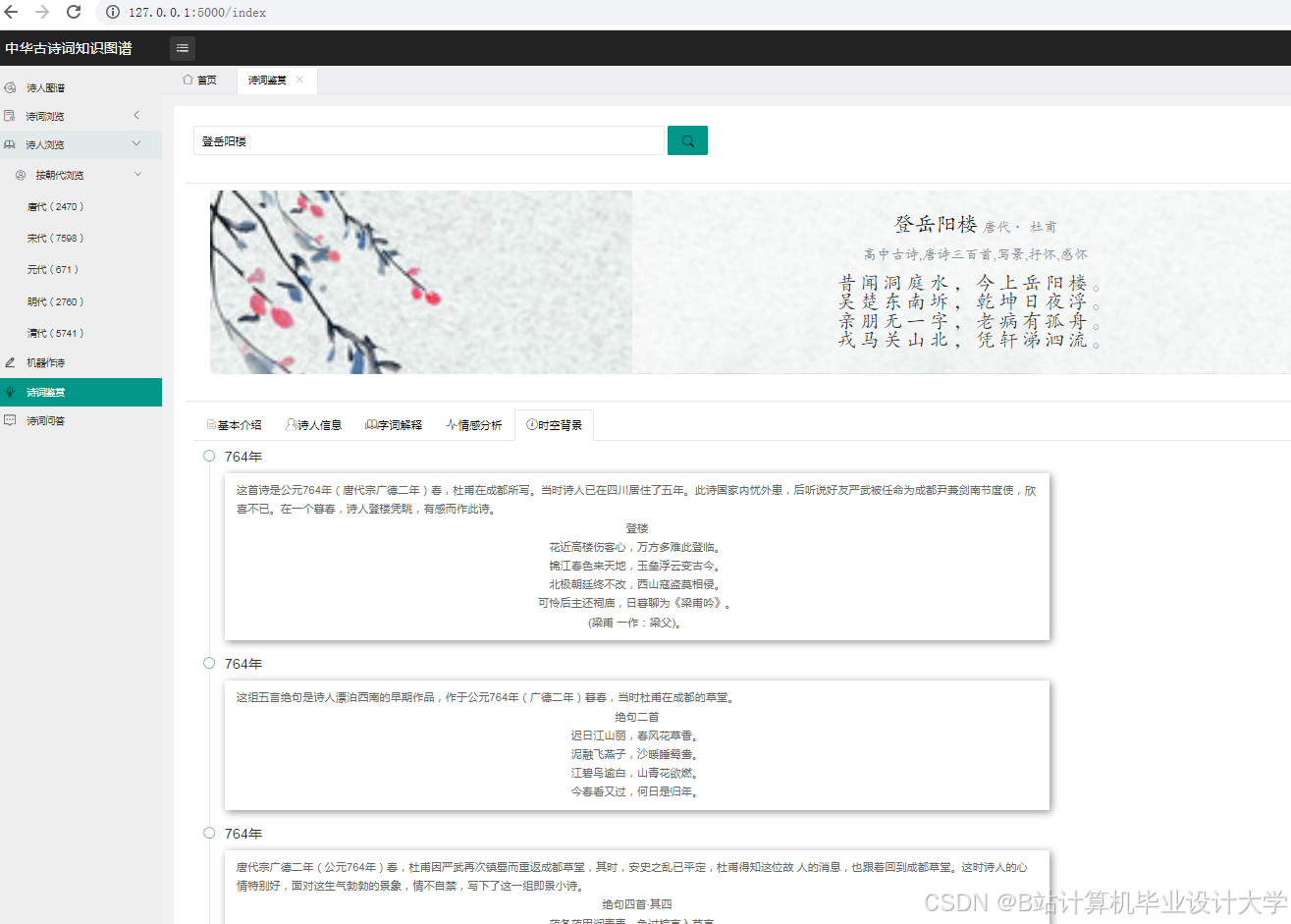
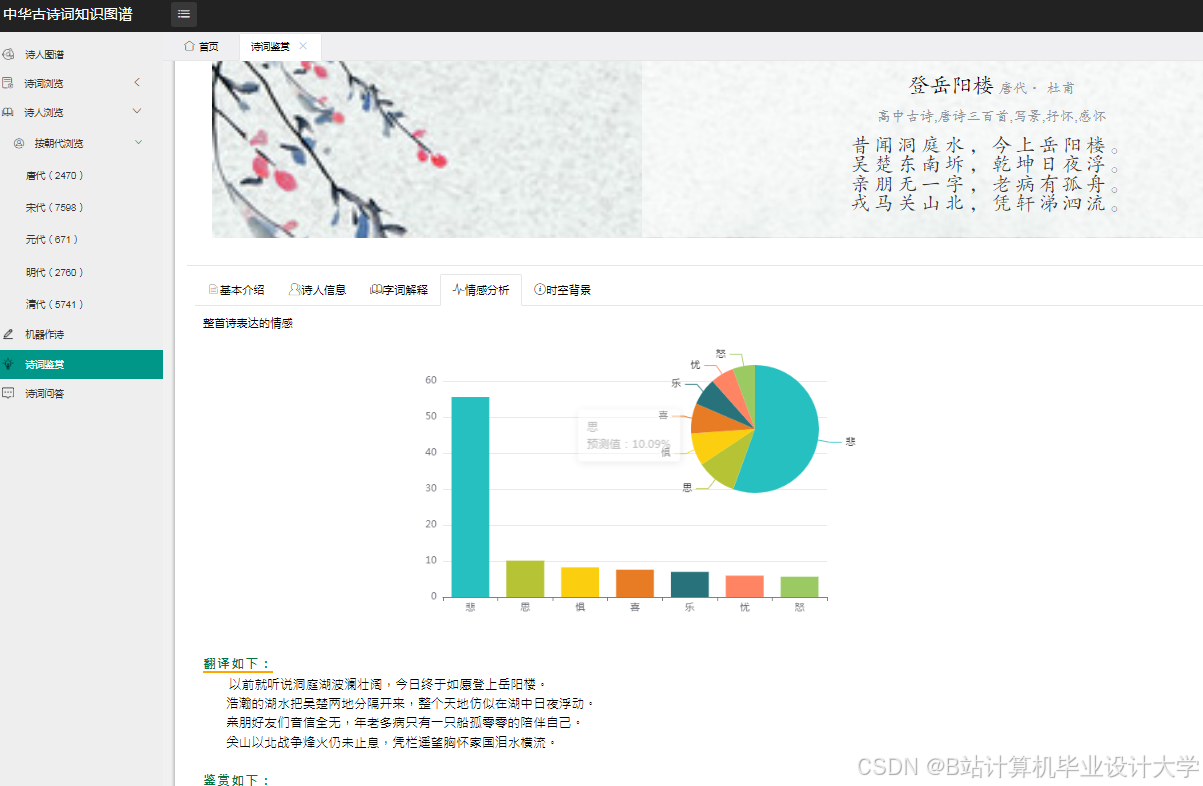
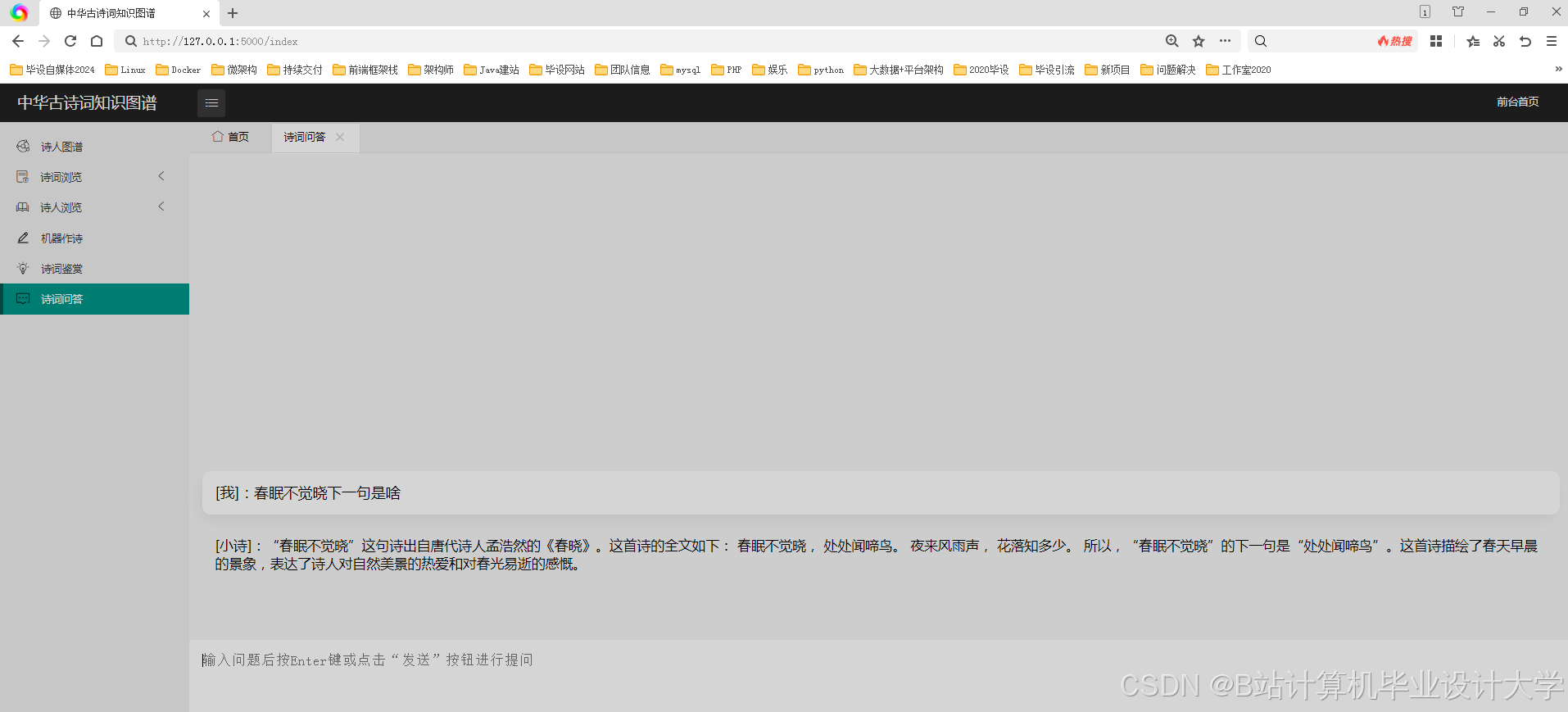
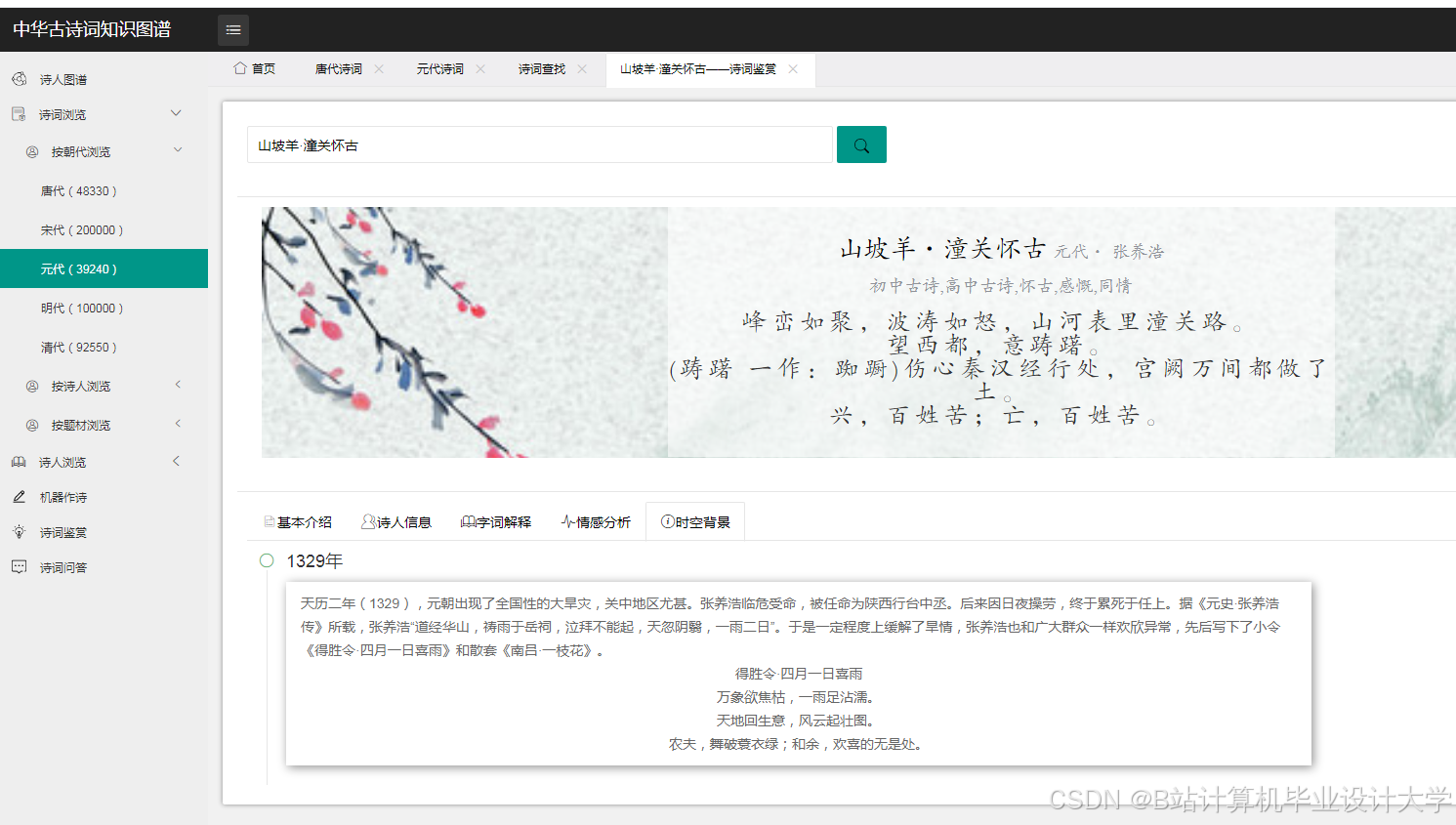
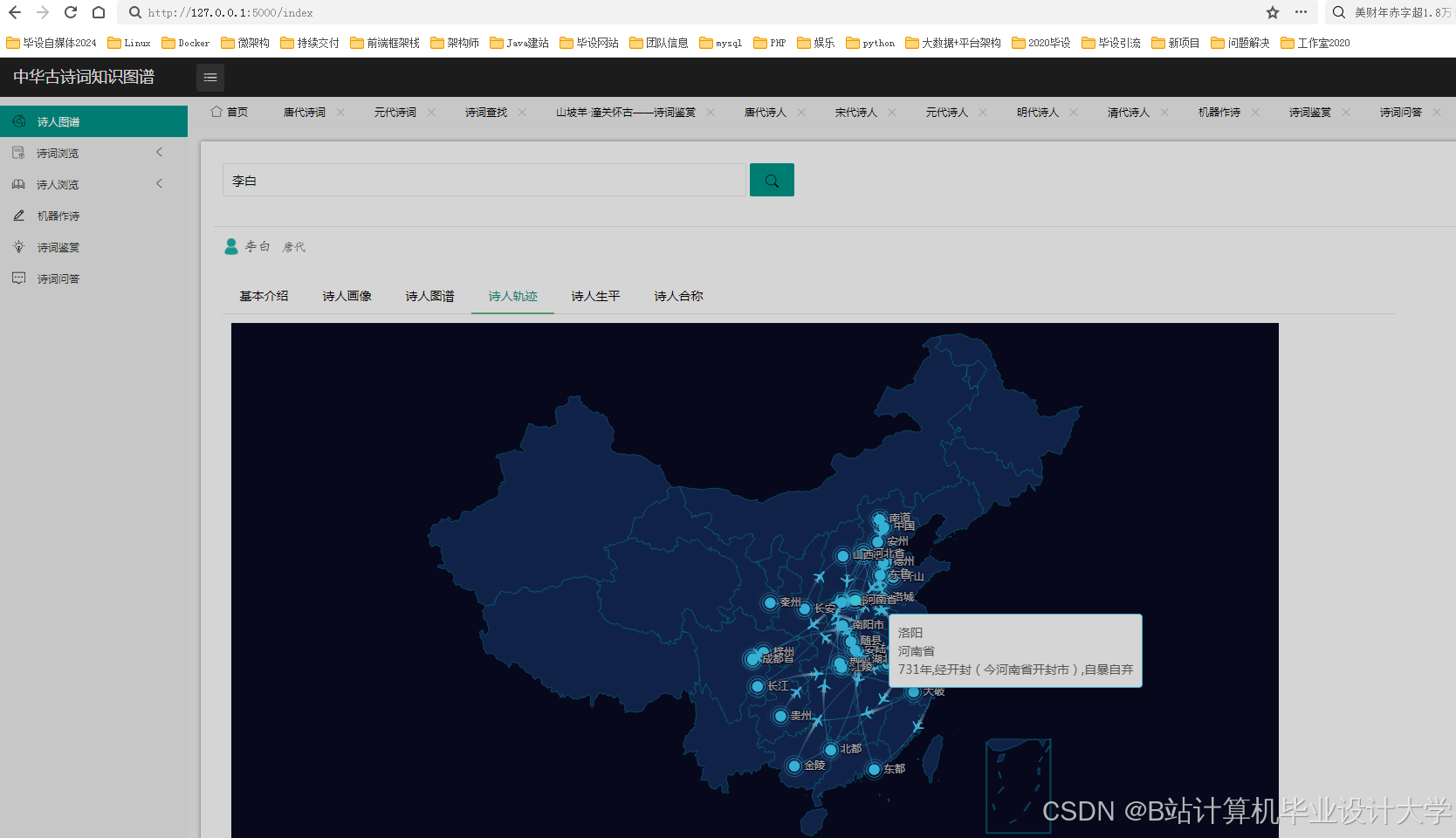
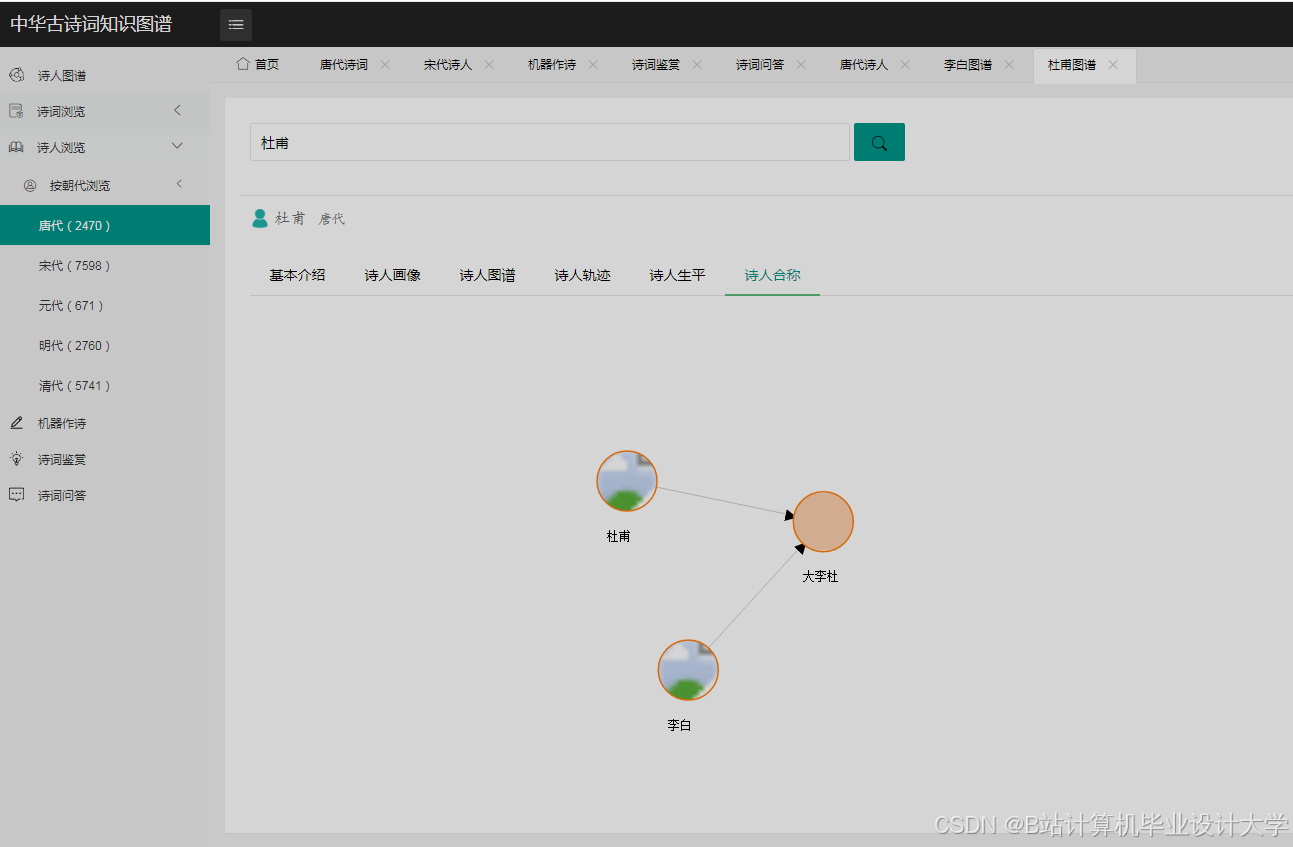
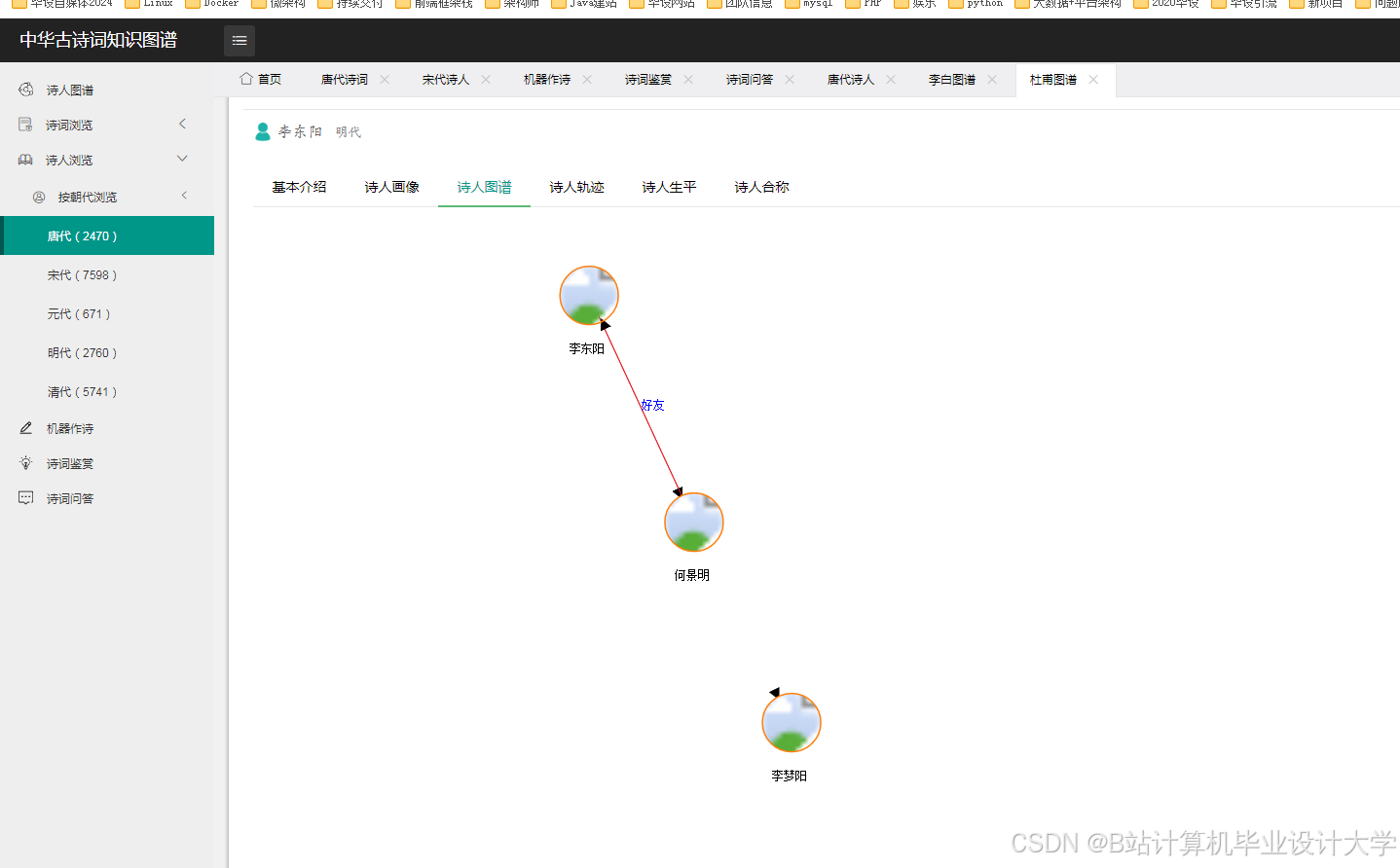
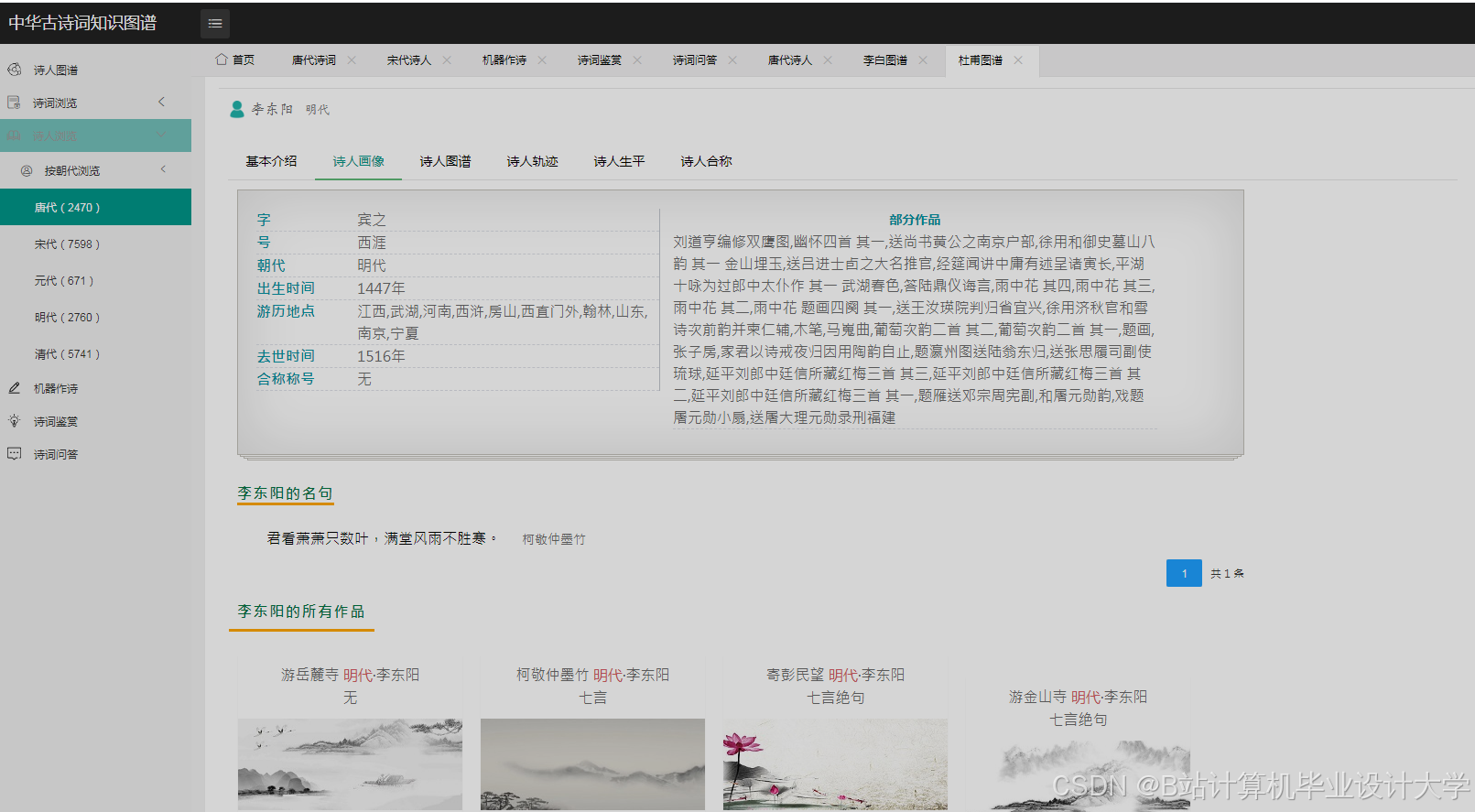
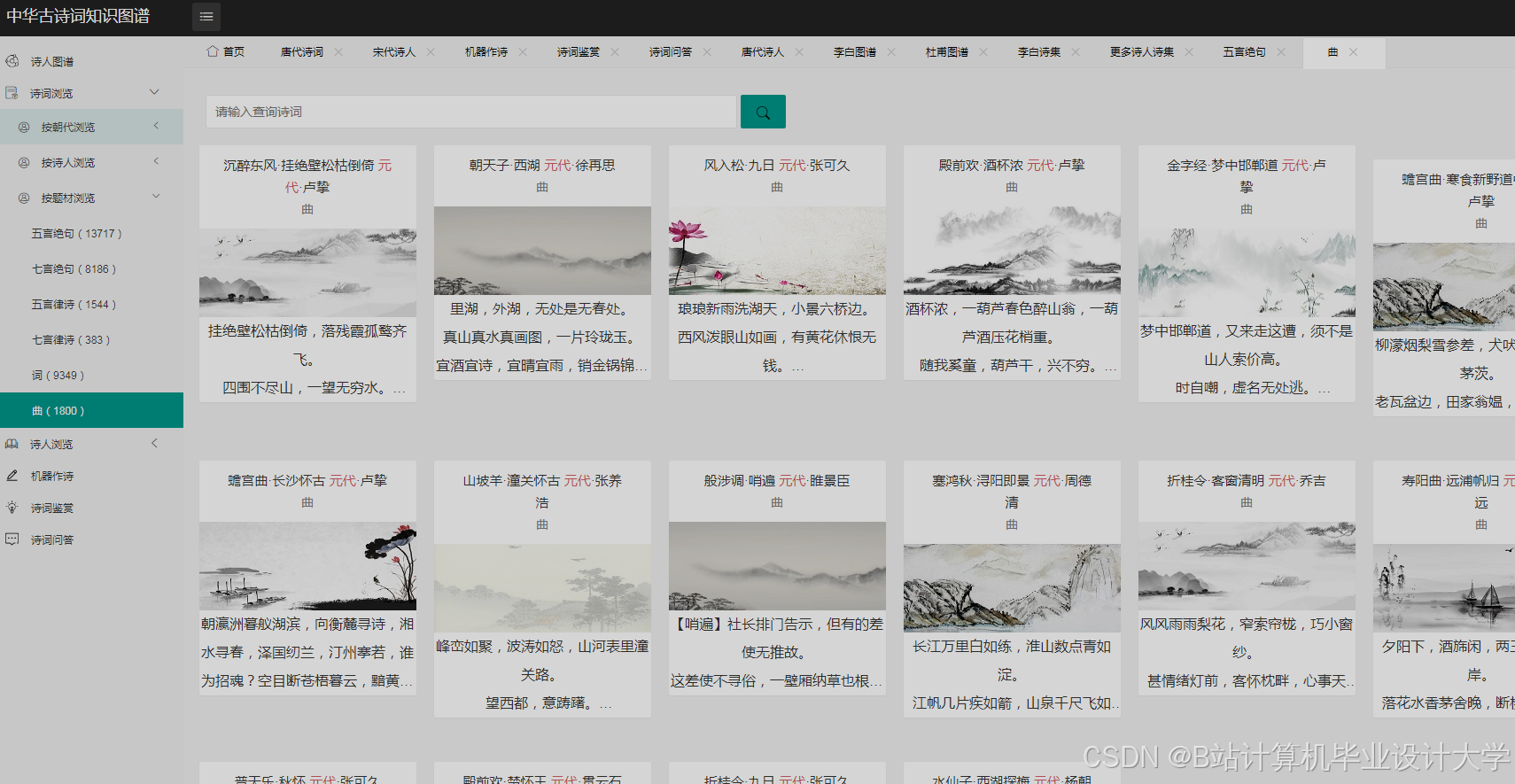
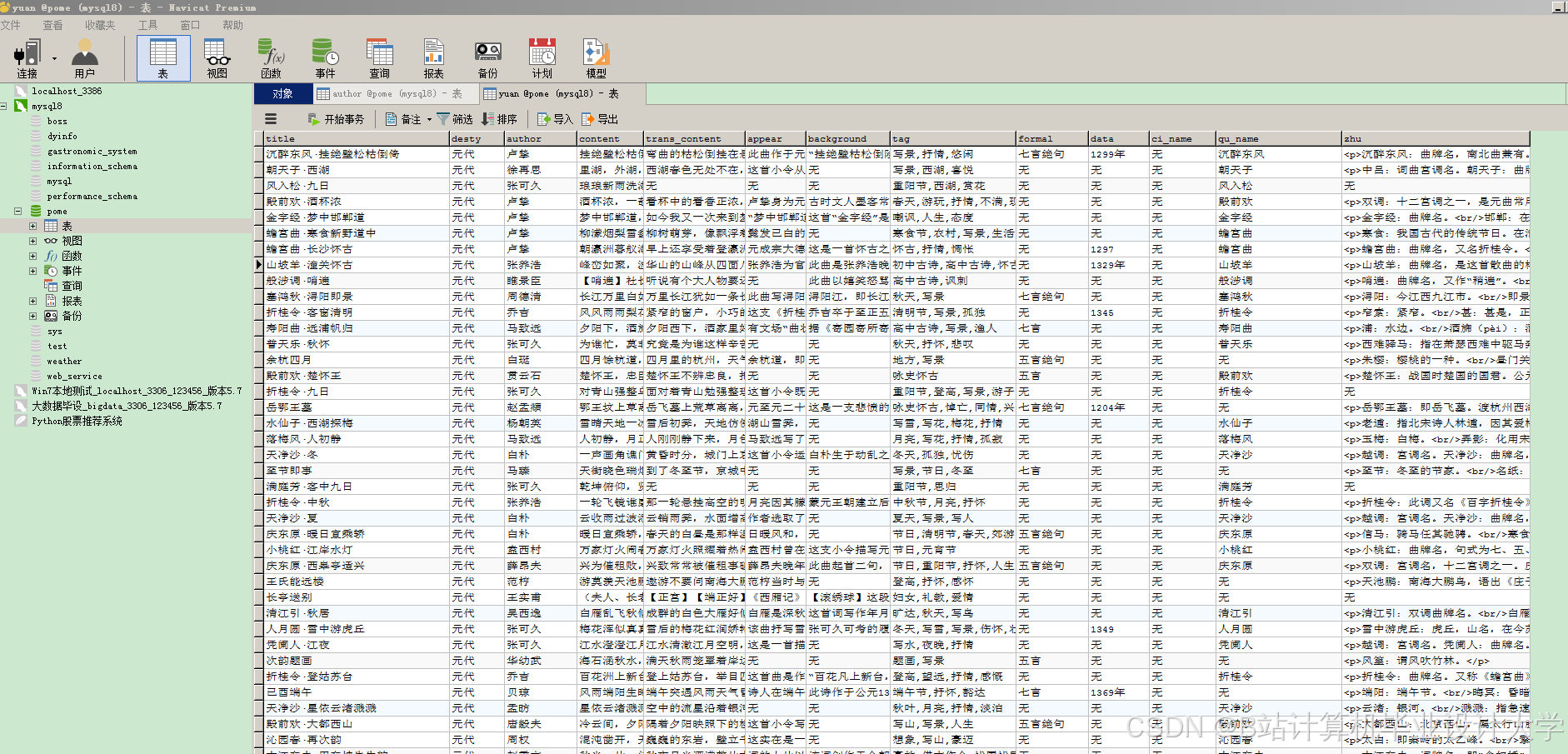
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献898条内容
已为社区贡献898条内容

所有评论(0)