SeqWalker:基于分层规划的序贯-视野视觉语言导航
26年1月来自东北大学、中科院沈阳自动化所、东南大学、中科院大学和穆罕默德·本·扎耶德AI大学(MBZUI)的论文“SeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning”。序贯-视野的视觉语言导航(SH-VLN)提出一种具有挑战性的场景:智体需要在复杂、长视野的语言指令引导下,
26年1月来自东北大学、中科院沈阳自动化所、东南大学、中科院大学和穆罕默德·本·扎耶德AI大学(MBZUI)的论文“SeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning”。
序贯-视野的视觉语言导航(SH-VLN)提出一种具有挑战性的场景:智体需要在复杂、长视野的语言指令引导下,按顺序执行多任务导航。现有的视觉-语言-导航模型在处理此类多任务指令时性能显著下降,因为信息过载会削弱智体关注与观察相关的细节的能力。为了解决这个问题,SeqWalker是一种基于分层规划框架的导航模型。SeqWalker的特点包括:i)一个高层规划器,它基于智体当前的视觉观察,动态地将全局指令分解为与上下文相关的子指令,从而降低认知负荷;ii)一个底层规划器,它采用探索-验证(Exploration-Verification)策略,利用指令固有的逻辑结构来纠正轨迹误差。为了评估 SH-VLN 的性能,扩展 IVLN 数据集并建立一个新的基准数据集。
如图展示 SeqWalker 的流程,其整体导航步骤如下: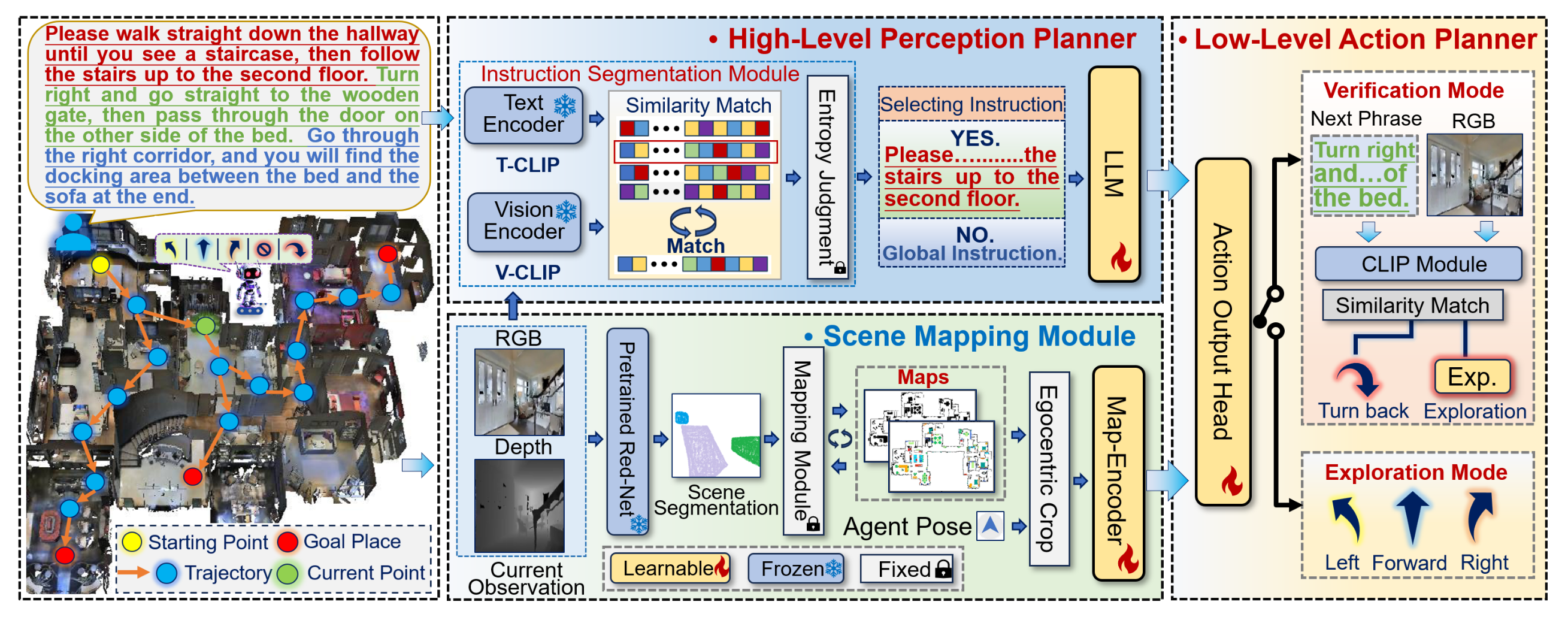
步骤 I. 高级感知规划器。SeqWalker 智体将 RGB 图像 Ri_t 与指令 Ii 进行匹配,并根据智体的当前状态和观测结果,选择最合适的短语 Si_j,从而高效地理解指令。
步骤 II. 导航场景制图。借鉴迭代VLN IVLN-CE 的方法,为了实现智体在持久大型场景中的长期规划,用场景制图模块 (SMM) 创建并保存场景地图,包括语义地图 Mi_t[sem] 和占用地图 Mi_t[ocu]。然后,根据智体的当前姿态,将这些保存的场景地图裁剪成局部地图 Mci_t[sem] 和 Mci_t[ocu],并使用 Map-Encoder Encoder_map 对地图嵌入 Zm_t 进行高效编码。
如图所示:Map-Encoder 由四个 CBRAA 模块组成。具体来说,提取的特征依次经过每个 CBRAA 模块,通道数乘以 2,空间维度缩小到原始尺寸的一半。每个 CBRAA 模块包含:卷积层,其卷积核大小为 7,输出通道数和形状大小保持不变;批量归一化;ReLU 激活函数;平均池化层,其形状大小为原来的一半;以及用于更好地提取 Map 特征的空间注意力机制。提取的特征尺寸逐步减小,以实现高效编码。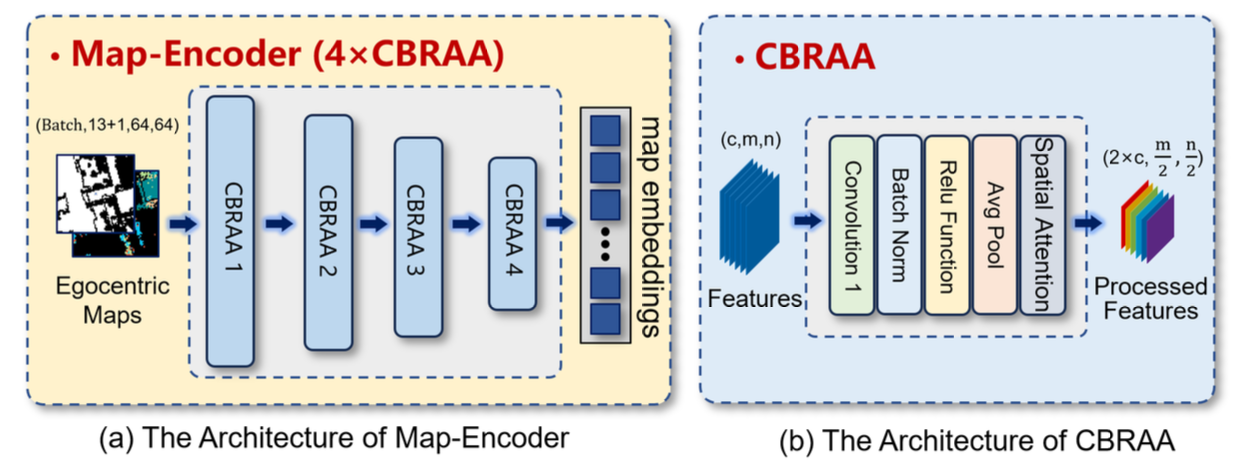
步骤 III:底层动作规划器:提出一种探索-与-验证(EaV)策略,以进一步提高序列视界导航的鲁棒性。EaV 提供两种不同的导航模式:探索模式主动引导智体到达目的地,而验证模式则及时验证并纠正轨迹错误。
SeqWalker 使用高级感知规划器来理解用户指令。在 SH-VLN 任务中,导航智体难以逻辑地理解和处理复杂的长指令,因此,提出一种指令分割模块 (ISM),用于分割全局指令,以降低理解冗余指令的难度。ISM 将序贯-视野指令解耦为一系列子短语,智体可以依次关注每个子短语,从而实现更精确的导航。
SeqWalker 使用底层动作规划器来提供特定的导航动作。在 SH-VLN 任务中,导航多轨迹较长且顺序严格。由于对某些指令语义的理解存在偏差,智体可能会选择错误的轨迹,而当前的错误往往会导致后续导航不可逆转地失败。为了提高导航轨迹的鲁棒性,进一步提出一种探索与验证策略作为导航的底层动作规划器。
序贯-视野数据集转换。为了评估所提出的 SH-VLN 任务,扩展 IVLN IR2R-CE 数据集(Krantz,2023),并提出了一个新的基准测试。构建该基准测试时考虑两个关键方面:如何将单阶段导航轨迹拼接成序贯-视野轨迹,以及如何生成具有更多区分细节且与导航场景紧密匹配的长指令。
a) 构建序贯-视野轨迹。与 IR2R-CE 中指令和轨迹的一一对应不同,序贯-视野导航任务涉及跨越多个轨迹的单个指令。为了构建此类轨迹,从 IR2R-CE 数据集中选择并连接起点和终点对齐的轨迹对。使用 LLM 将相应的指令连接起来,以确保语义一致性,即 LLaMa-13B(Touvron,2023)。
b) 增强长指令。除了生成序贯-视野轨迹外,还增强指令,以解决其区分语义相似子任务的粒度不足的问题,从而更好地处理多轨迹导航。具体来说,基于大型多模态语言模型 LLaVA-OneVision(Li,2024)扩展 IVLN 指令,该模型能够根据语言提示推理多视图图像。具体而言,在指令增强过程中,智体被强制按照真实轨迹进行逐步导航。对于每个短语“滑雪”对应的导航轨迹,收集观测的 RGB 图像,构建与该导航轨迹对应的第一视图多图像集。然后,将短语“滑雪”和多幅图像作为输入送入 LLaVA 中,以实现指令增强。其保存LLaVA提供的增强指令输出,并替换短语“滑雪”。重复此过程以扩展所有指令。
基于以上两个主要方面,构建序贯-视野IR2R-CE(SH IR2R-CE),并使用大规模的单轨迹及其对应的指令集进行训练和测试。
实现
用 Habitat(Savva,2019)作为仿真平台。SeqWalker 在所提出的 SH IR2R-CE 数据集上进行训练。用轻量级 LLM,即 Qwen-0.5b(Bai,2023),作为指令编码器来获取指令嵌入,并使用 CLIP ViT-B/32 作为高层感知规划器的图像-文本编码器。采用先前研究中使用的指标(Anderson,2018;Ilharco,2019;Krantz,2023)评估性能,这些指标包括:导航误差 (NE)、Oracle 成功率 (OS)、归一化动态时间规整 (nDTW)、成功率 (SR)、路径长度加权成功率 (SPL)、路径归一化动态时间规整 (t-nDTW) 和轨迹长度 (TL)。此外,还提出两个指标来评估子指令任务的完成情况:CP_sub T,即失败前已完成子任务的比例,CP_sub T = NS/NA,其中 NS 和 NA 分别为已完成子任务的数量和子任务总数。CP_sub I,即正确选择的子指令的比例,定义为 CP_sub I = NC/NT,其中 NC 是基于熵的正确选择次数,NT 为总步数。
训练策略。SeqWalker模型采用一种两阶段模仿训练策略,该策略参考Krantz(2020)的研究。训练的第一阶段使用教师强制方法,训练数据集为提出的SH-IR2R-CE数据集。在第二阶段,对第一阶段的模型进行微调,以使其在未见过的场景中获得更好的泛化性能。在两个训练步骤中都使用进度监视器辅助损失函数。SeqWalker模型中的模块是部分可训练的。冻结CLIP模型的参数,以保留其文本-图像匹配和理解能力。基于LLM的指令编码器、地图编码器和AOH在训练过程中进行联合训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)