【Azure 架构师学习笔记】 - Azure AI(3)-数据工程在AI系统中的设计(ADF+ADLS)
AI 时代很多东西都不是技术层面的内容,比如数据治理,数据工程等。试想一下你去面试,面试官考察的不是“你用了什么工具”,而是“你为什么这样设计”例如:❌ 工具操作:“我创建了三个容器”✅ 工程思维:“我设计三层容器,因为Raw层满足合规审计,Processed层隔离脏数据风险,Curated层支持特征复用——这是微软Azure数据架构指南推荐的分层模式”数据工程原则ADF+ADLS实践专业体现1.
本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 Azure 架构师学习笔记 - Azure AI(2)-Azure机器学习 (Azure ML) 工作区架构
前言
AI 时代很多东西都不是技术层面的内容,比如数据治理,数据工程等。 试想一下你去面试,
面试官考察的不是“你用了什么工具”,而是“你为什么这样设计”
例如:
❌ 工具操作:“我创建了三个容器”
✅ 工程思维:“我设计三层容器,因为Raw层满足合规审计,Processed层隔离脏数据风险,Curated层支持特征复用——这是微软Azure数据架构指南推荐的分层模式”
而这些通常以各种原则出现,下面整理了一下如果使用Azure的ADF和ADLS ,通常会如何表现:
| 数据工程原则 | ADF+ADLS实践 | 专业体现 |
|---|---|---|
| 1. 可追溯性 | Raw层保留原始CSV(带时间戳) | 任何模型问题可回溯到原始数据快照(审计刚需) |
| 2. 可复现性 | 文件名时间戳 = 物理版本号 | 无需复杂元数据,文件系统即版本库(简单可靠) |
| 3. 可维护性 | 三层容器职责隔离 | 修改清洗逻辑不影响原始数据(降低维护风险) |
| 4. 可扩展性 | ADF流水线模板化 | 新增数据源只需复制流水线(非重写代码) |
| 步骤 | 本文操作 | 数据工程专业体现 |
|---|---|---|
| 步骤1:数据湖设计 | 创建 raw-data / processed-data / curated-data 三层容器 |
✅ 分层架构设计 - Raw层:保留原始数据(满足GDPR审计) - Processed层:清洗后数据(隔离脏数据) - Curated层:特征就绪数据(供多模型复用) |
| 步骤2:ADF流水线构建 | 复制活动:staging → raw-data(文件名带时间戳) | ✅ 物理版本控制设计 - 文件名表达式: sales_@{formatDateTime(utcNow(),'yyyyMMdd_HHmmss')}.csv- 每次运行生成唯一文件(防覆盖) - 时间戳 = 物理版本号(可追溯) |
环境搭建
除了前面提到的Azure ML 之外(本文暂不涉及),还可以使用Azure Data Factory和Storage account (ADLS Gen2)来实现数据工程的思想。因此我们先创建这两个资源。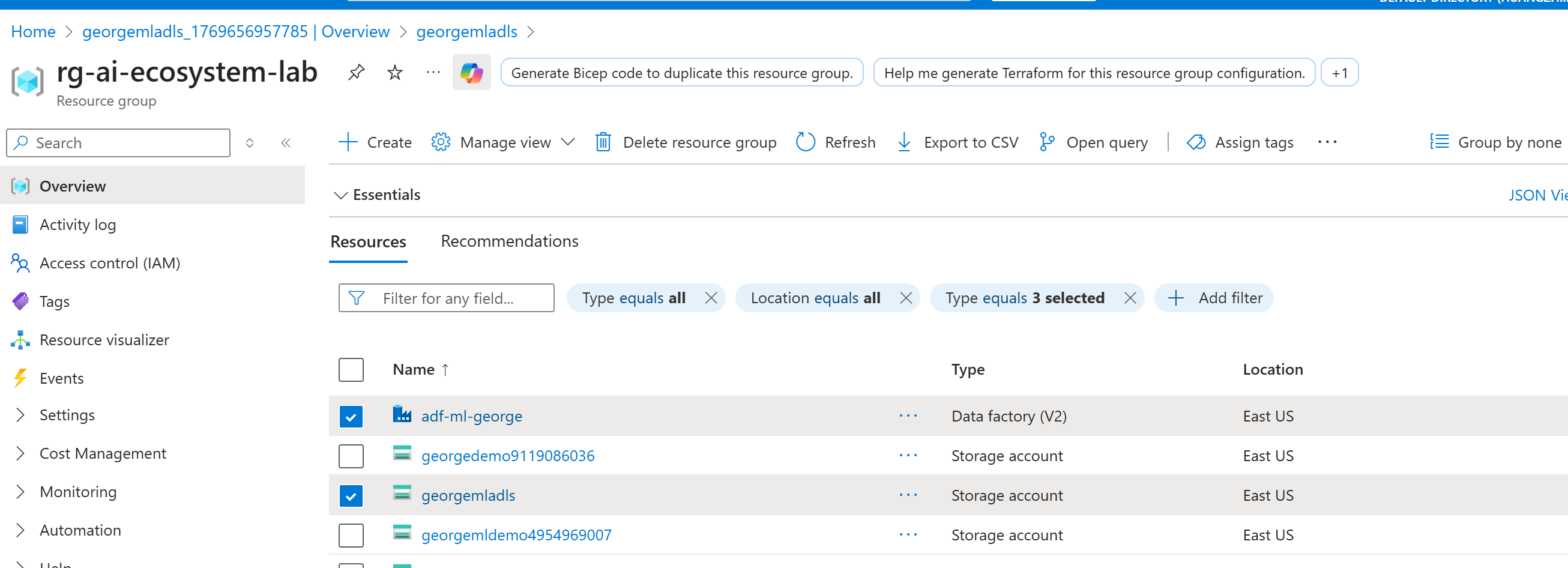
步骤1
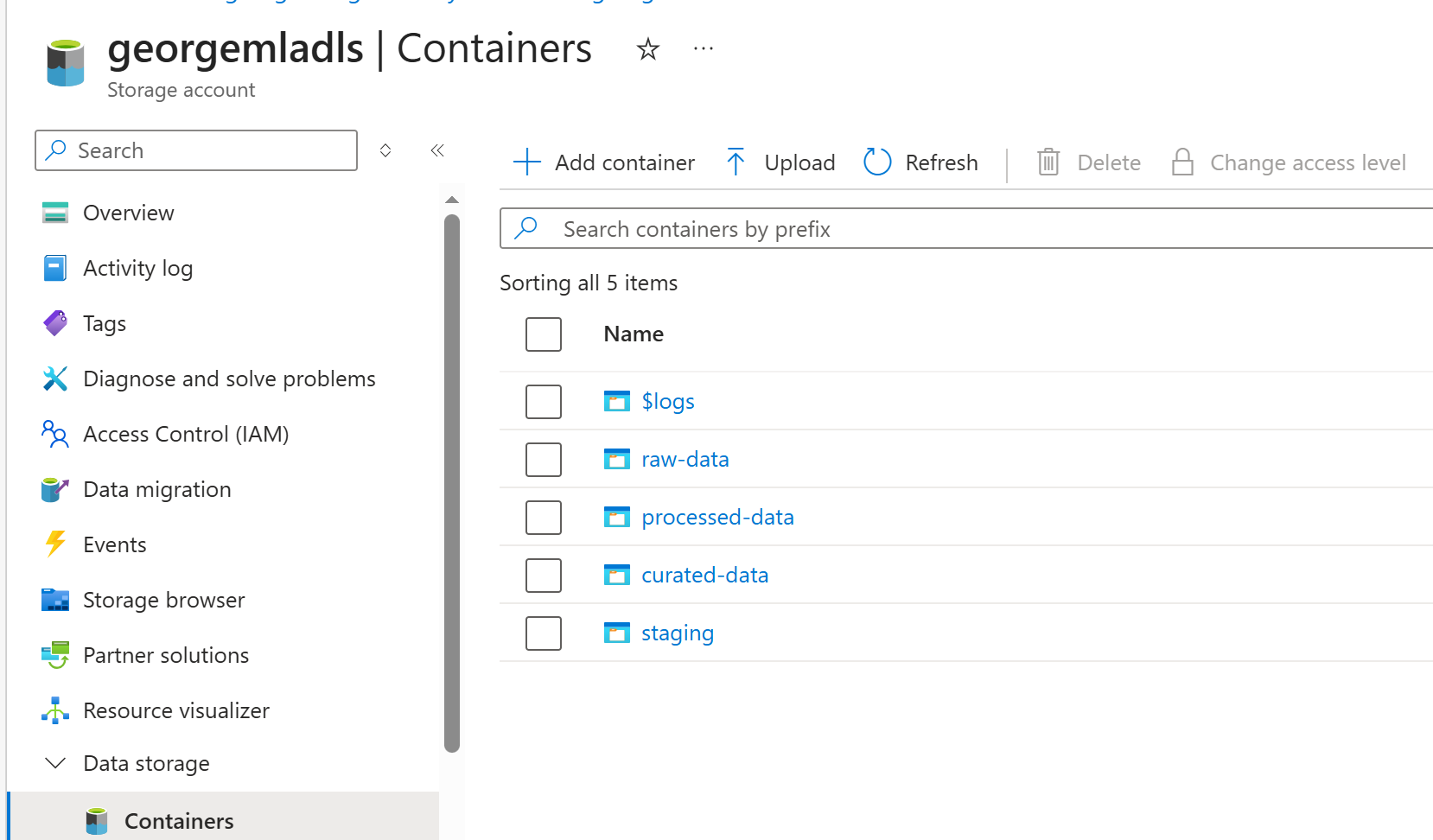
然后按照“可维护性”也就是步骤1 ,创建三个containers(第四个是staging,一般用于存储真正的临时文件)。
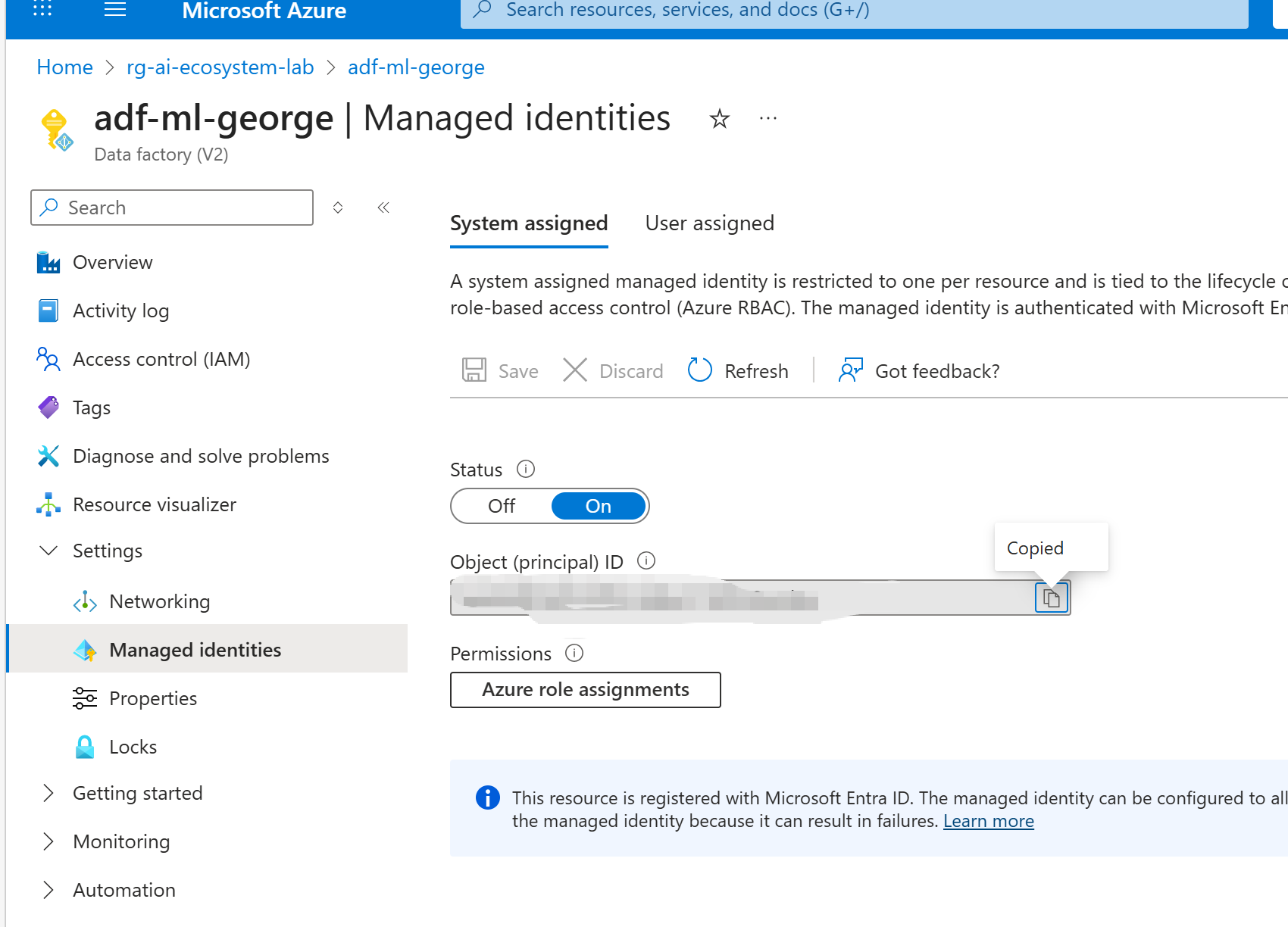
授权ADF 可以访问ADLS,最简单的方式就是使用ADF 的system assigned MI, 下面是确认已经开启了这个MI。
在ADLS 上为其授权,通常XX contributor已经可以在对应的服务上做几乎所有的事了,不过为了避免后续操作过程出现权限不够,这里直接给了owner。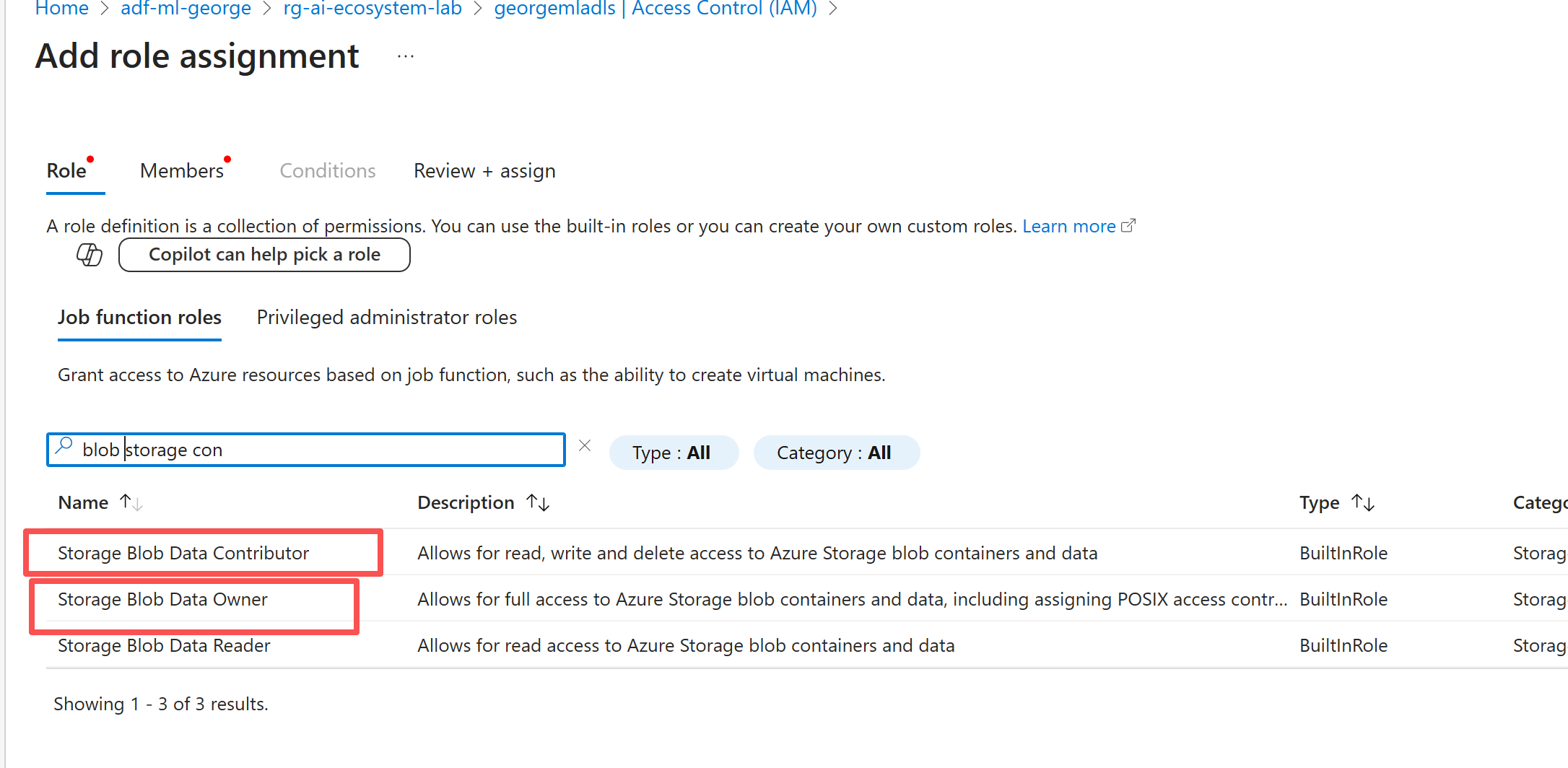
步骤2
搭建可扩展的ADF流水线:
使用【copy data tool】->配置源(这里需要先把测试文件上传到ADLS staging container)->使用data flow 配置数据处理。
最终实现从staging把原始文件,复制到raw-data, 然后再进行预处理后,复制到processed-data.
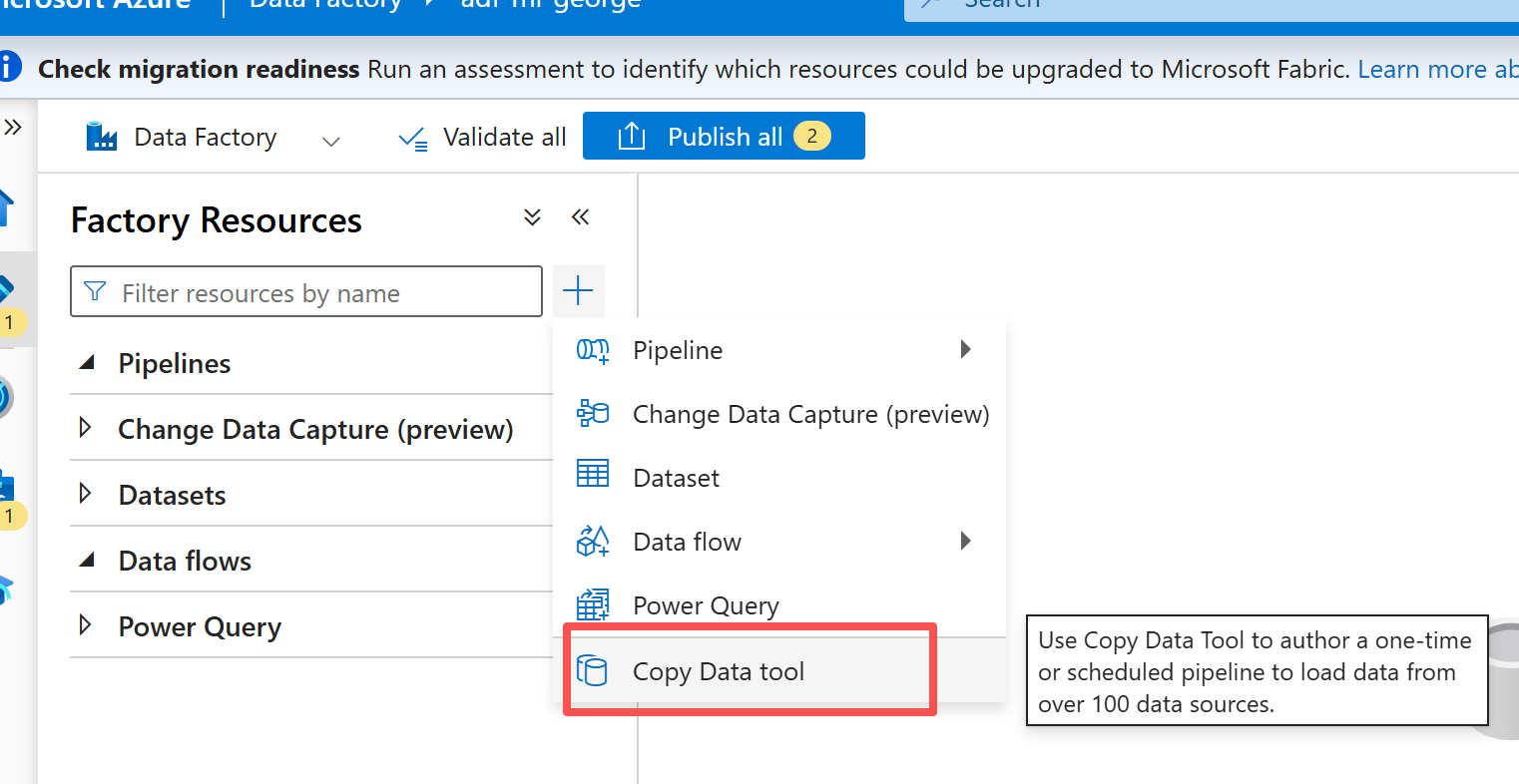
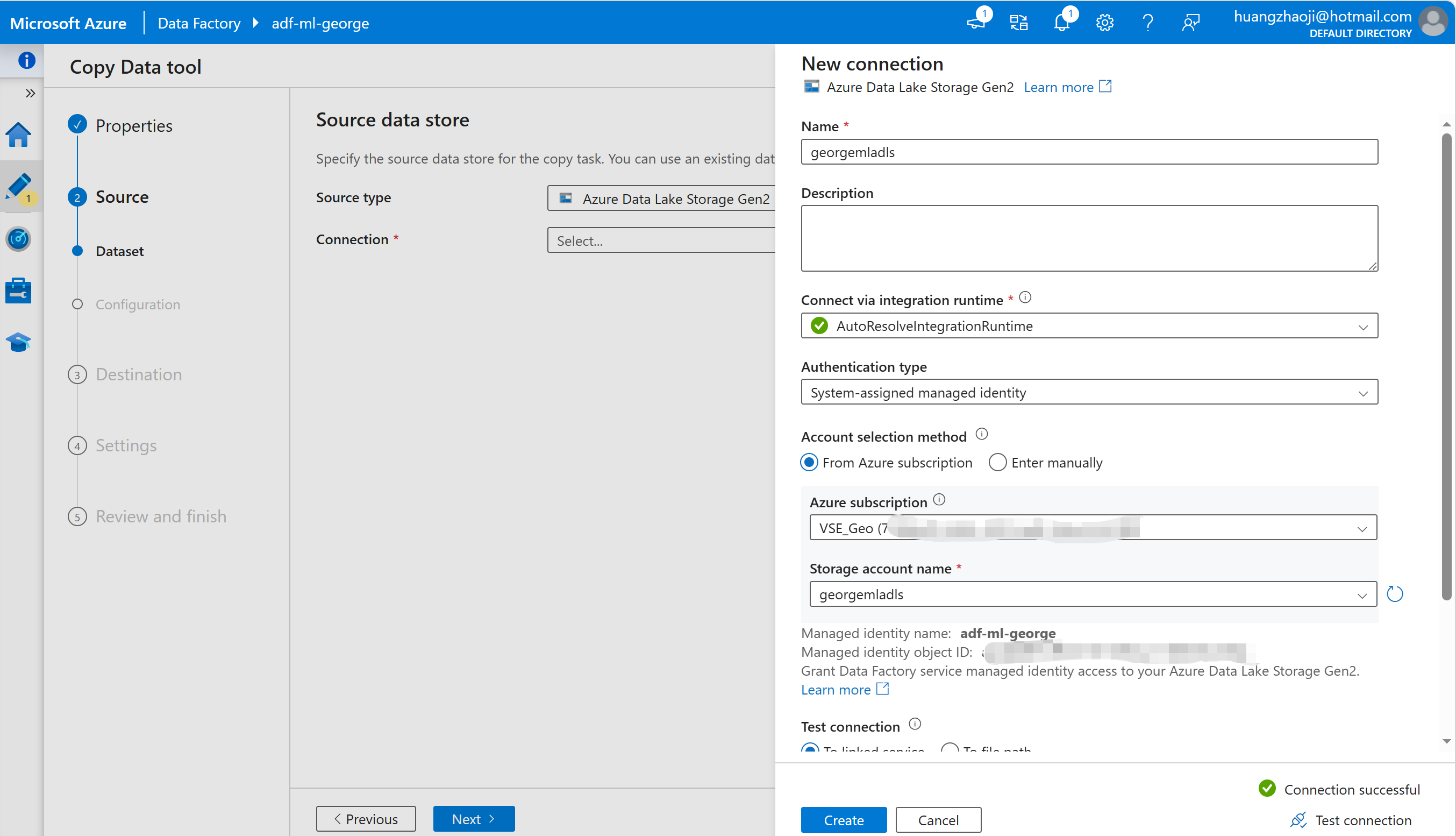
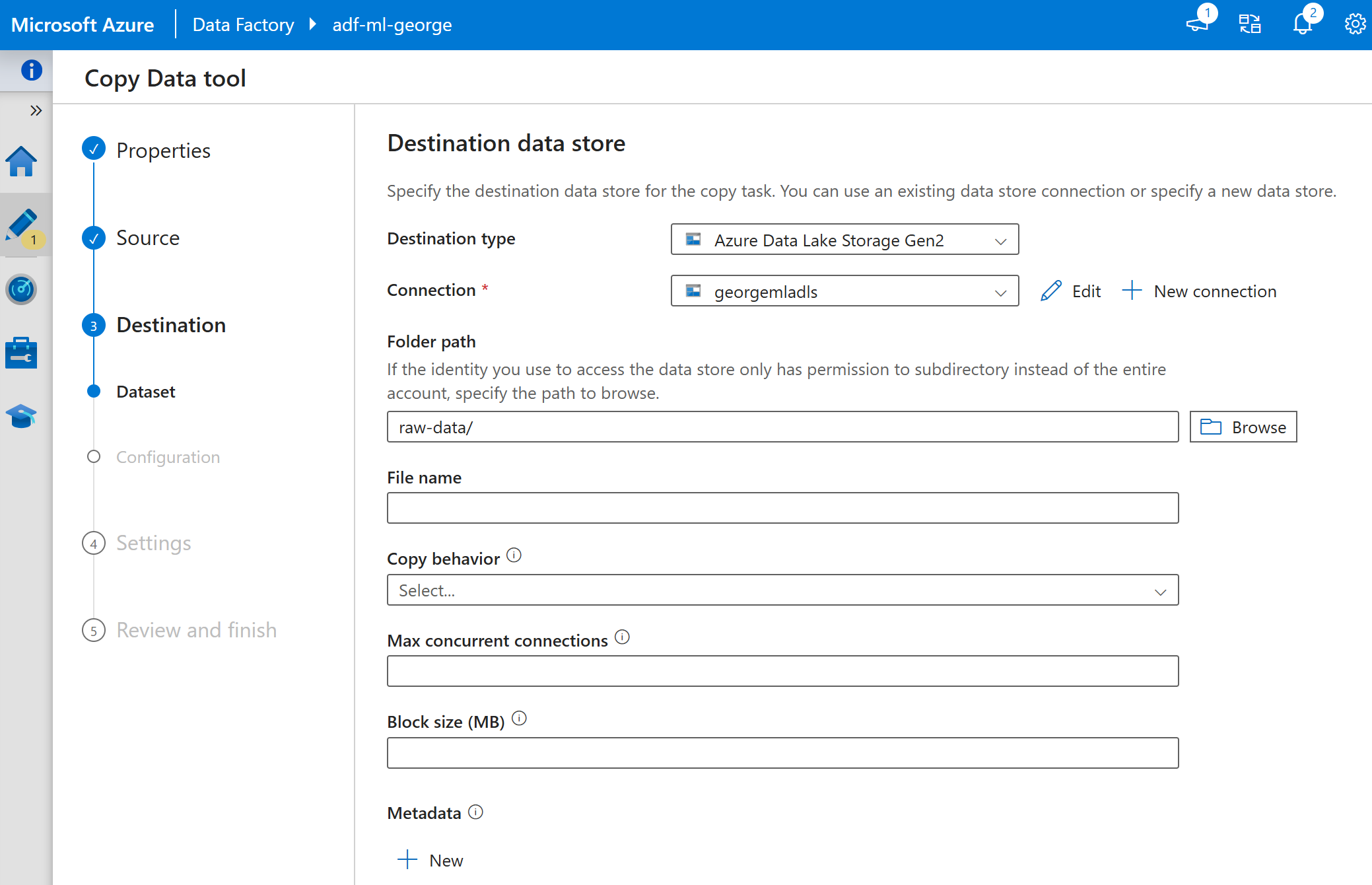
下面是这个流水线的JSON 代码
{
"name": "CopyPipeline_ybw",
"properties": {
"activities": [
{
"name": "Copy_data",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [
{
"name": "Source",
"value": "staging//my_sales.csv"
},
{
"name": "Destination",
"value": "raw-data//"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 0
}
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"validateDataConsistency": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "SourceDataset_ybw",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "DestinationDataset_ybw",
"type": "DatasetReference"
}
]
},
{
"name": "TransformSalesData",
"type": "ExecuteDataFlow",
"dependsOn": [
{
"activity": "Copy_data",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"dataflow": {
"referenceName": "dataflow1",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine"
}
}
],
"annotations": [],
"lastPublishTime": "2026-01-29T14:10:56Z"
},
"type": "Microsoft.DataFactory/factories/pipelines"
}
搭建好之后应该类似这个样子:
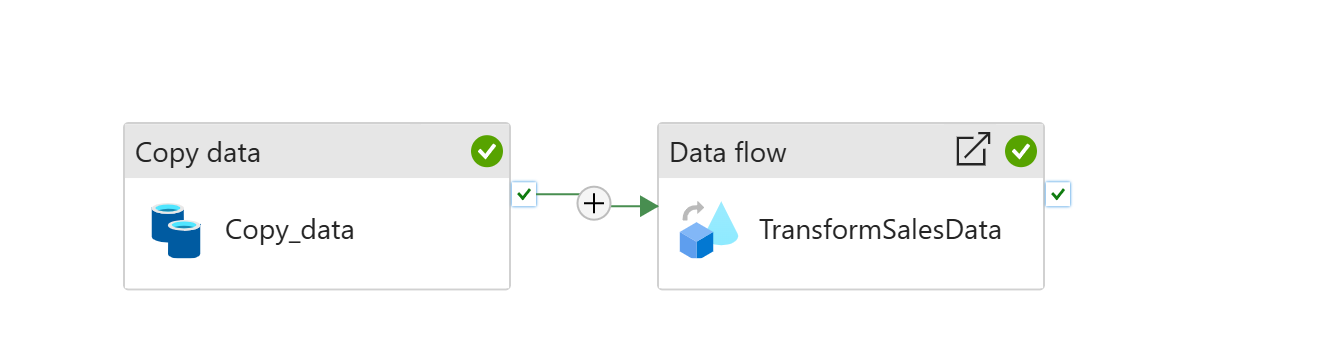
Data Flow内部, 做了一些数据预处理,不过内容不是非常重要。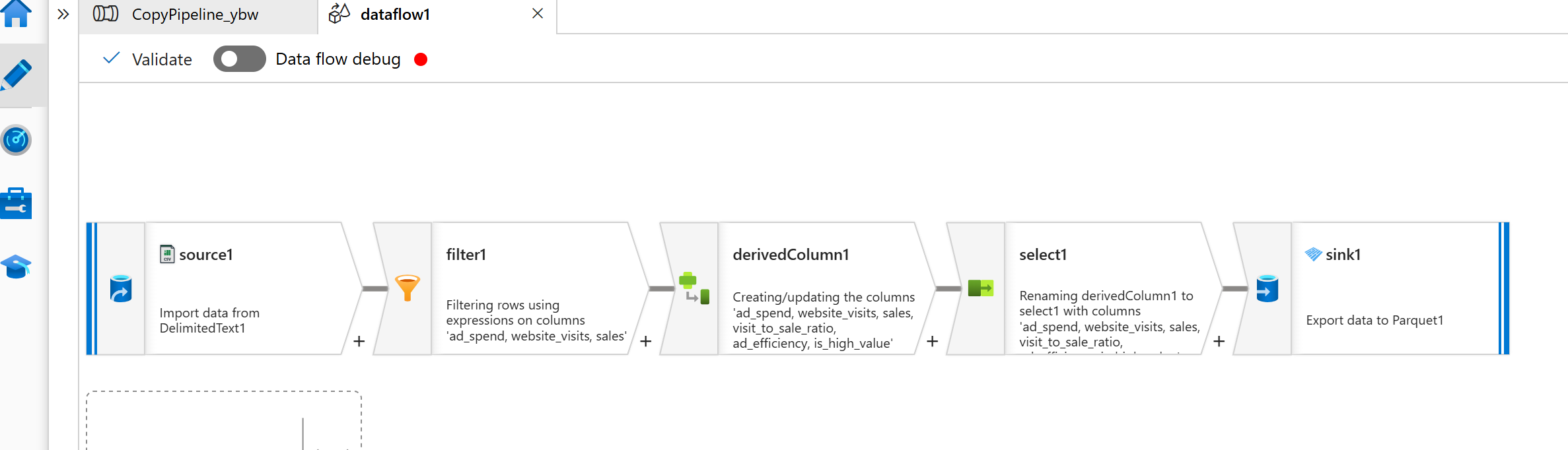
执行成功之后可以看到
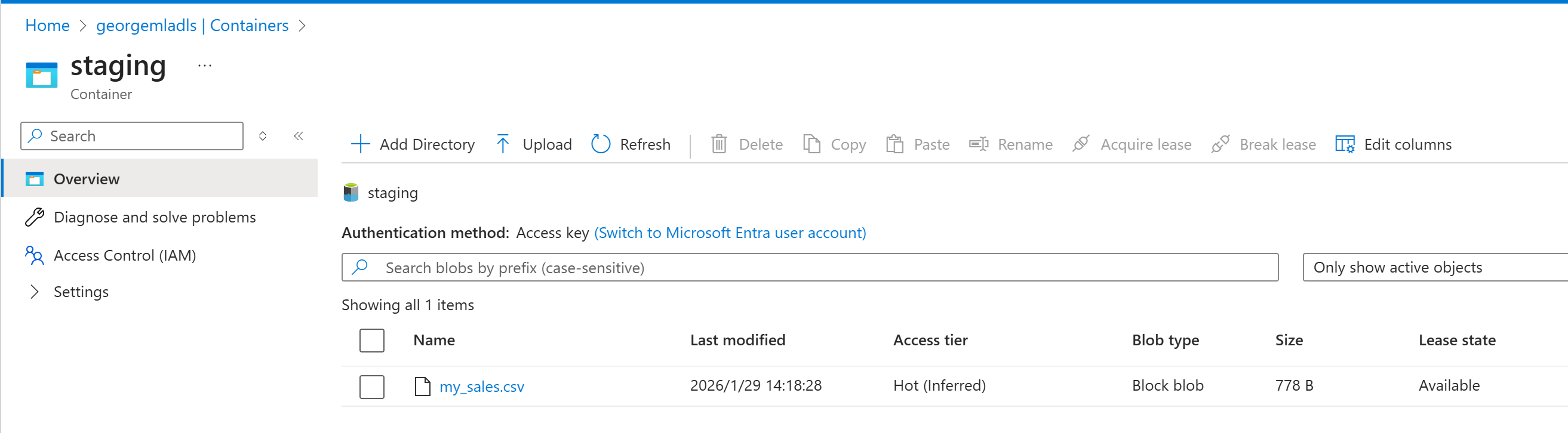
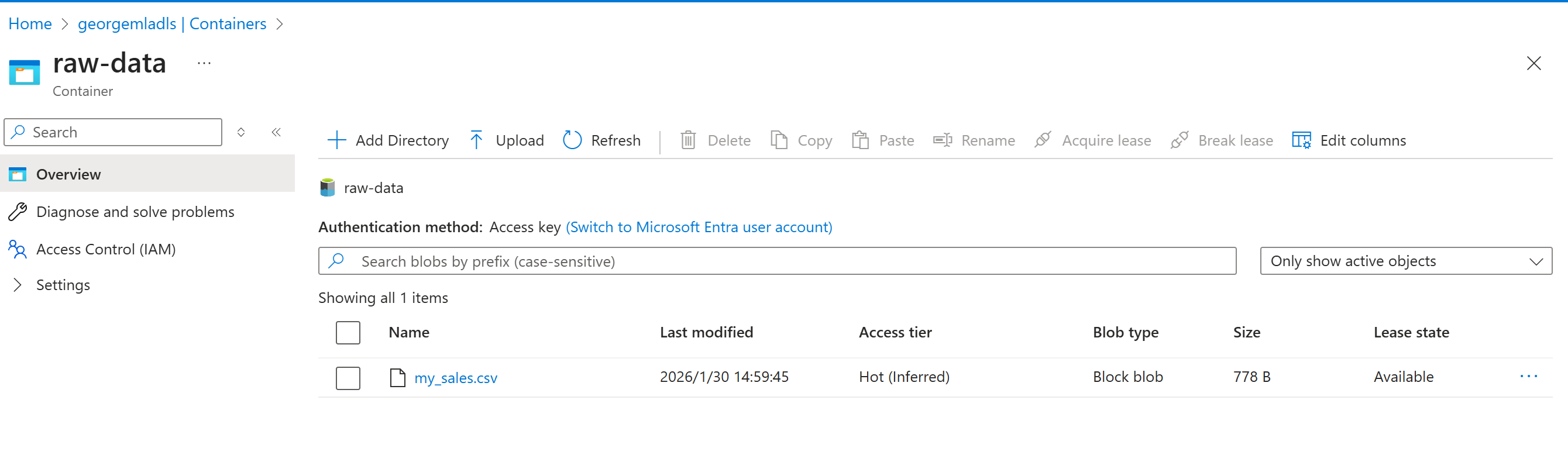
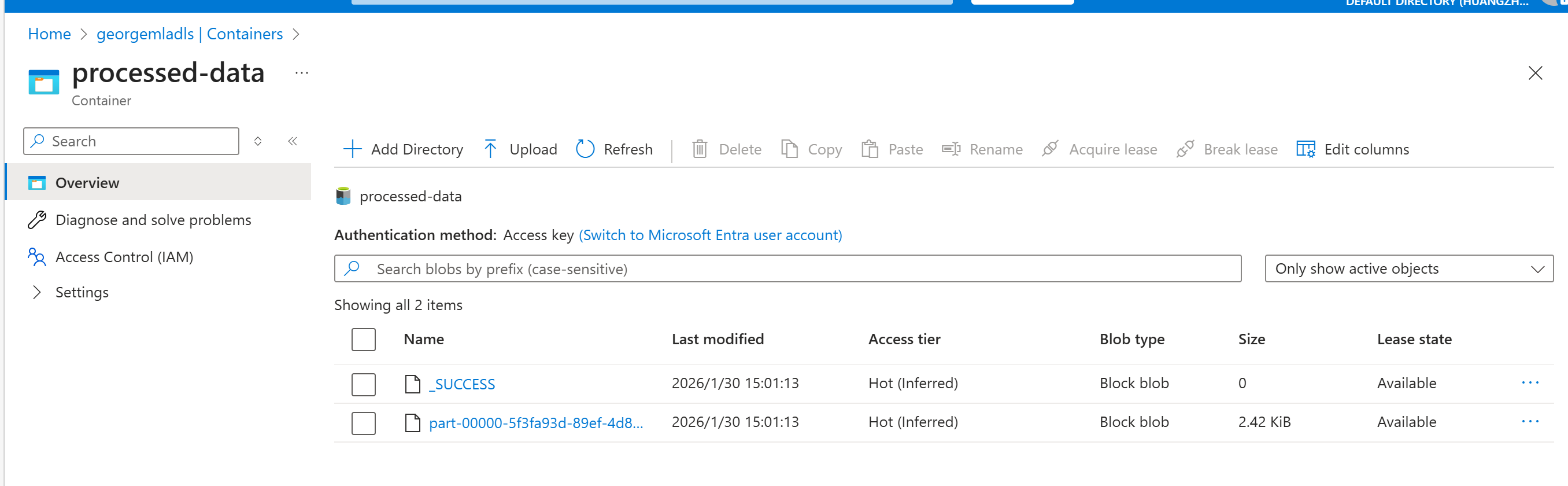
小结
本文主要用ADF+ADLS 展现数据工程的思想。接下来将融合Azure ML 进行进一步的实操。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)