【机械臂】【LLM】一、接入千问LLM实现自然语言指令解析
系列概述
临近本科毕业,考虑到未来读研的方向以及自己的兴趣方向,我选择的课题大致为“基于VLA结构的指令驱动式机械臂仿真系统的实现”。
为什么说是VLA(Vision-Language-Action)“结构”,因为就目前而言,我认为在目前剩下的几个月时间内从0实现一个正儿八经的VLA模型,所需要的时间、资金、模型资源的获取都是比较麻烦的。因此,我选择使用ROS1+LLM+视觉算法来实现一个“伪VLA”结构,就目前阶段(开题一个月)而言,我能给出的场景示意如下:
场景:指令输入“机械臂将蓝色方块夹起放到红色圆柱体上面”,系统接收指令后,先通过视觉模块确定当前系统中各个物体的坐标,再通过开源大模型,结合已知坐标信息,通过预设的prompt生成动作序列,作为参数送入ROS1架构下的启动文件中,实现动作行为在gazebo下的仿真。
当前阶段我能给出粗糙的逻辑示意图如下:
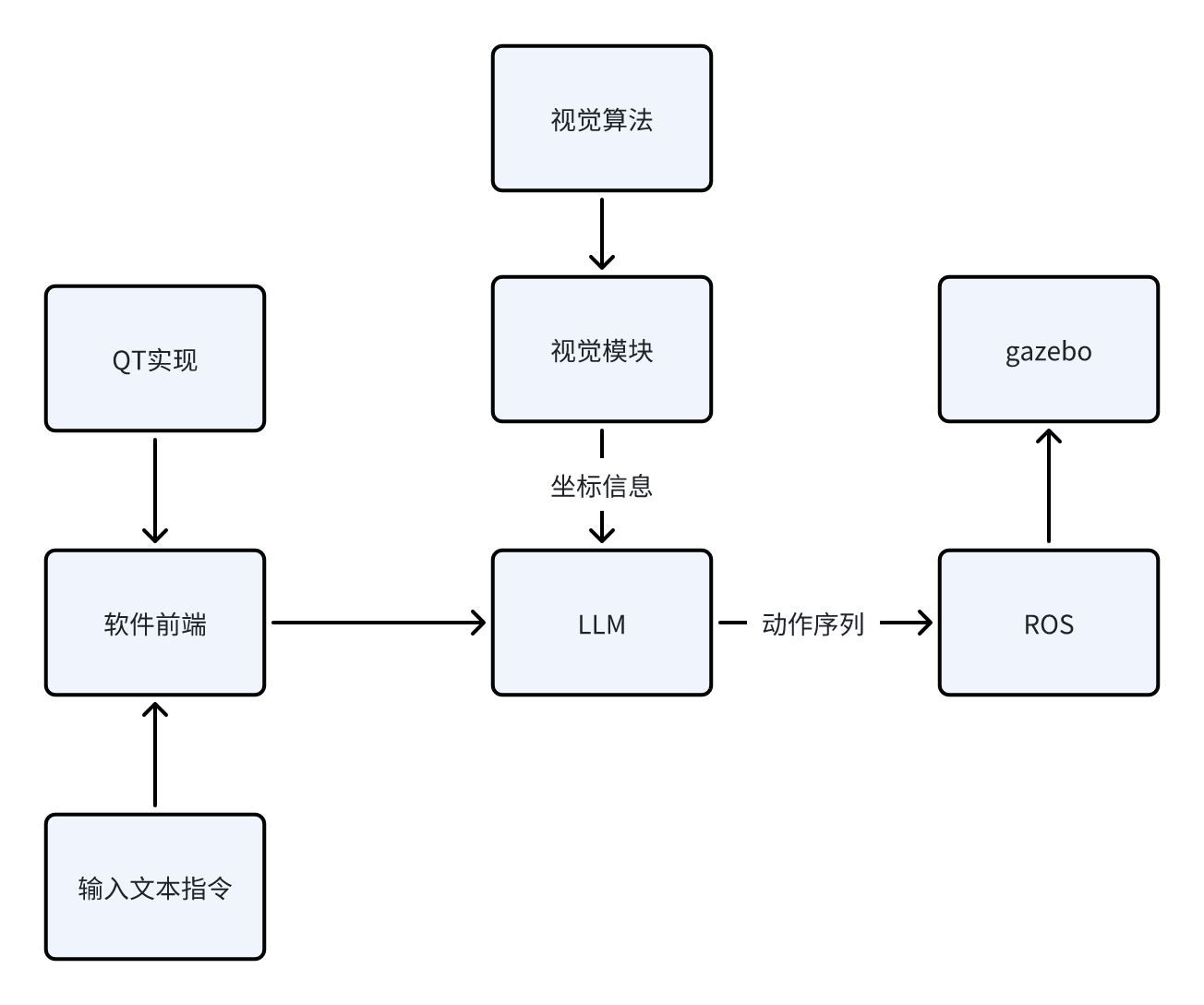
接下来,我将给出目前阶段我所计划的步骤实现,之后该系列的博客都会依照下面的框架进行更新。由于我也是初次入门ROS以及深度学习相关的内容,所以本系列博客更多的充当学习笔记的作用,在书写过程中难免会出现错误以及天真的理论理解,还请各位指正。
我将该项目的实现分成下面几个步骤(每个步骤下的博客会一步一步地更新):
1. 实现机械臂在ROS1+Gazebo环境下的控制、仿真。目标效果是给出任意坐标的方块,机械臂要能稳定的抓取,并放置到指定的坐标。
该步骤博客目录如下:
https://blog.csdn.net/m0_75114363/article/details/156164226?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75114363/article/details/156166592?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_75114363/article/details/156426200?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75114363/article/details/156544524?spm=1001.2014.3001.5502
2. 加入视觉模块与算法。目标效果是在仿真环境下,对于随意放置的方块,视觉系统需要计算出其真实坐标给予机械臂控制模块,使得机械臂能够实现对其的抓取与放置。
该步骤博客目录如下:
https://blog.csdn.net/m0_75114363/article/details/156641634?spm=1001.2014.3001.5502
3. 加入LLM(本地部署或使用API)。目标效果是对于输入的任意文本指令,LLM能根据预设的prompt,结合视觉系统给予的信息,给予执行模块对应的动作序列,使得机械臂正确地实现输入的文本指令想达到的效果,实现V-L-A的完整交互。
该步骤博客目录如下:
4. 实现整体系统的优化与完善,包括基于QT搭建软件前端、优化模型外观、加入更复杂的机械臂、实现更复杂的指令解析与运行。
该步骤博客目录如下:
我所使用的环境如下:
1. 系统:Ubuntu20.04
2. ROS1:Noetic
项目地址:
https://github.com/Dukiyaaa/Cmd2Action_ROS1
此外,额外说明一下为什么这个项目会选择ROS1做框架而不是更现代的ROS2。其实我在初期也是用的ROS2的框架,但发现机械臂夹爪始终无法夹起物体,网上相关的机械臂开源资料基本都是基于ROS1的,加上ROS1提供了grasp_fix插件可防止物体掉落,所以最终我选择了ROS1做项目框架,同时也希望自己在后期能够在ROS2上成功迁移项目。
章节概述
在之前Agent部分的工作中,我成功实现了agent、planner、controller等模块,能够做到向agent发送指定格式的msg后,系统能够正确地执行动作。
而在本章中,我将接入LLM,通过提示词工程,将用户输入的自然语言指令解析为符合格式要求的json语句,再通过字符解析构造msg,向agent发送话题信息,之后实现整个链路的操作。
1.LLM模块的实现
arm_application/llm/llm.py
import json
import os
import rospy
import textwrap
from arm_application.msg import LLMCommands
from std_msgs.msg import String
from typing import Dict, Any, Optional
import dashscope
class TongyiQianwenLLM:
"""通义千问LLM集成类"""
def __init__(self, api_key: Optional[str] = None):
"""初始化通义千问LLM
Args:
api_key: 通义千问API密钥,如果为None则从环境变量DASHSCOPE_API_KEY获取
"""
self.api_key = api_key or os.environ.get("DASHSCOPE_API_KEY")
if not self.api_key:
raise ValueError("API key is required. Please set DASHSCOPE_API_KEY environment variable or provide it as parameter.")
dashscope.api_key = self.api_key
self.model = "qwen-max" # 可以根据需要选择其他模型
# 初始化ROS发布器
self.pub = rospy.Publisher('/llm_commands', LLMCommands, queue_size=10)
self.sub = rospy.Subscriber('/llm_user_input', String, self._user_input_callback)
rospy.loginfo("LLM 节点已启动,等待用户输入...")
def _user_input_callback(self, msg):
"""处理用户输入话题的回调函数
Args:
msg: 包含用户自然语言指令的String消息
"""
user_input = msg.data
rospy.loginfo(f"收到用户输入: {user_input}")
self.process_user_input(user_input)
def generate(self, prompt: str, max_tokens: int = 1024, temperature: float = 0.7) -> str:
"""调用通义千问API生成文本
Args:
prompt: 提示词
max_tokens: 最大生成token数
temperature: 生成温度,值越大越随机
Returns:
生成的文本
"""
try:
response = dashscope.Generation.call(
model=self.model,
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=0.95,
)
if response.status_code == 200:
return response.output.text
else:
raise Exception(f"API call failed: {response.message}")
except Exception as e:
rospy.loginfo(f"Error calling Tongyi Qianwen API: {e}")
return ""
def process_user_input(self, user_input: str):
"""处理用户输入并发布LLMCommands消息
Args:
user_input: 用户输入的自然语言指令
"""
# 预设的prompt模板,引导模型输出指定格式
prompt_template = textwrap.dedent("""
你是一个机械臂控制助手,需要将用户的自然语言指令转换为机械臂可执行的命令格式。
请根据用户输入,生成以下格式的JSON响应:
{
"action_type": "pick" | "place" | "pick_place" | "reset" | "open_gripper" | "close_gripper" | "create" | "delete",
"object_class_id": int,
"object_name": "string",
"object_x": float,
"object_y": float,
"object_z": float,
"target_class_id": int,
"target_name": "string",
"target_x": float,
"target_y": float,
"target_z": float
}
说明:
1. action_type 必须是以下之一:pick(抓取)、place(放置)、pick_place(抓取并放置)、reset(复位)、open_gripper(打开夹爪)、close_gripper(关闭夹爪)、create(创建物体)、delete(删除物体)
2. 对于 pick 动作,可以使用object_class_id或(object_x, object_y, object_z),当显示指定抓取位置时,只用(object_x, object_y, object_z);未显示指定时,使用object_class_id
3. 对于 place 动作,可以使用target_class_id或(target_x, target_y, target_z),当显示指定放置位置时,只用(target_x, target_y, target_z);未显示指定时,使用target_class_id
4. 对于 pick_place 动作,结合2、3点即可,先抓取object,再放置到target
5. 当用户要求创建或者放置物体时,使用 create 动作, 用(object_x, object_y, object_z)来代表生成的位置,用object_class_id 0 表示创建蓝色方块,1 表示创建绿色圆柱体,在创建物体时要起个名字,用object_name来指定,
6. 当用户要求删除物体时,使用 delete 动作, 使用object_name指定要删除的物体的名字
7. 对于不需要的字段,请设置为默认值:class_id 为 -1,坐标为 0.0,名称为 ""
8. 请确保生成的是有效的JSON格式,不要包含任何额外的文本
9. 请直接输出JSON,不要包含任何前缀或后缀文本,所有的内容用英文
用户输入:
{user_input}
请生成符合上述格式的JSON响应:
""").strip()
# 填充用户输入
prompt = prompt_template.replace("{user_input}", user_input)
# 调用LLM生成响应
response = self.generate(prompt)
# 解析响应并发布消息
try:
# 提取JSON部分
import re
json_match = re.search(r'\{.*\}', response, re.DOTALL)
if json_match:
json_str = json_match.group(0)
command_dict = json.loads(json_str)
# 创建并填充LLMCommands消息
msg = LLMCommands()
msg.action_type = command_dict.get("action_type", "reset")
msg.object_class_id = command_dict.get("object_class_id", -1)
msg.object_name = command_dict.get("object_name", "")
msg.object_x = command_dict.get("object_x", 0.0)
msg.object_y = command_dict.get("object_y", 0.0)
msg.object_z = command_dict.get("object_z", 0.0)
msg.target_class_id = command_dict.get("target_class_id", -1)
msg.target_name = command_dict.get("target_name", "")
msg.target_x = command_dict.get("target_x", 0.0)
msg.target_y = command_dict.get("target_y", 0.0)
msg.target_z = command_dict.get("target_z", 0.0)
# 发布消息
self.pub.publish(msg)
rospy.loginfo(f"发布LLM指令: {msg}")
return msg
else:
rospy.logerr("无法从LLM响应中提取JSON")
return None
except Exception as e:
rospy.logerr(f"解析LLM响应时出错: {e}")
return None整个模块的构造实际非常简单,只需要去千问官网申请拿到api_key后,自己构造好prompt,比便可以通过dashscope.Generation.call请求一次千问大模型,得到其返回的格式化的json内容,再通过字符解析为符合msg要求的格式,通过话题发布到Agent模块,对应的动作便可以得到执行。
目前采用的模型是qwen-max,最开始使用的是qwen-turbo,其速度非常快,但解析能力不如max。
2.后续规划
目前的模块设计已经能完成整个项目的demo,但对于llm模块仍旧有一些地方可以考虑优化:
1.加入上下文,通过字符串存储模型的输出,加入到下一次请求的prompt中,但这样会造成思考时间的加长以及token的消耗。
2.加入反馈机制。
总结
完成了LLM模块的设计与实现,整个系统已经能实现用户的自然语言指令到动作执行的完整闭环。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)