基于Python和Pytorch的电池储能深度强化学习实践
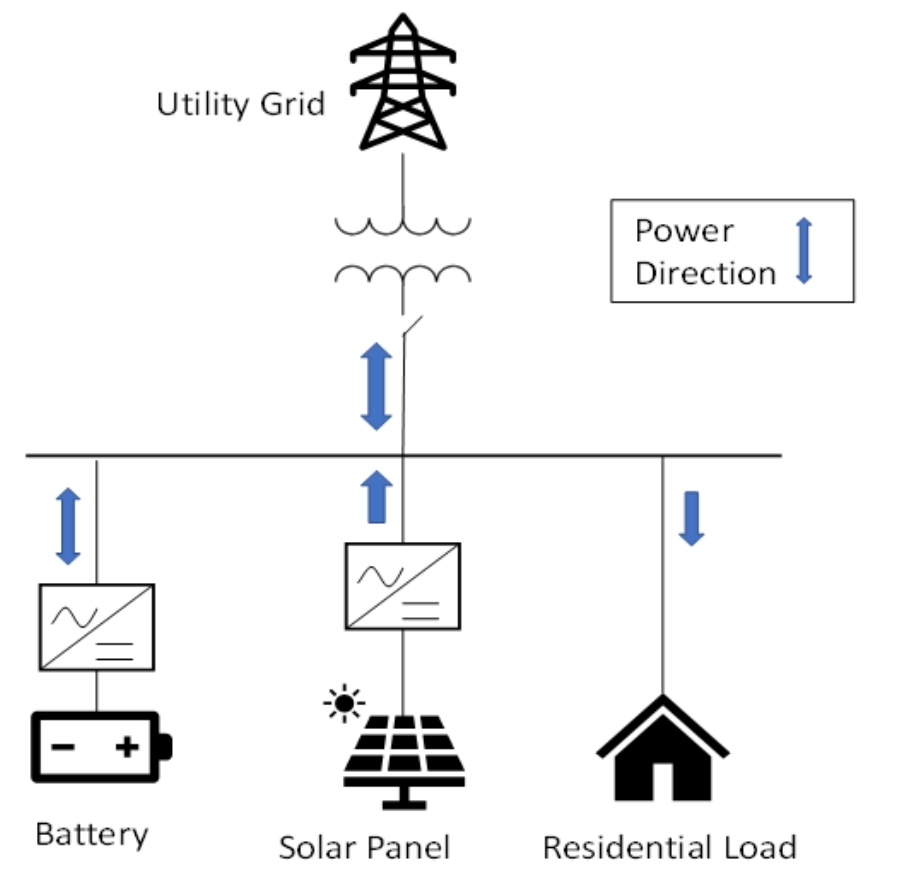
我们的系统主要包含电池、PV(光伏)、动态负载,它们通过PCC(公共连接点)连接到主电网。这就像一个复杂的能源网络,各个部分相互作用,而我们的目标就是通过控制电池的充放电,让整个系统的成本最优。通过Python和Pytorch搭建的这个仿真平台,利用深度强化学习训练Agent来控制电池的充放电,为优化能源成本提供了一种有效的解决方案。随着研究和实践的深入,相信这种方法能在实际的能源管理场景中发挥更
Python代码:电池储能 深度强化学习 关键词:BMS DRL 仿真平台:Python Pytorch 主要内容:电池,PV,动态负载,通过PCC连接到主电网。 我们需要控制电池充电/放电计划以降低成本。 DRL用于训练代理。 它是一种简单的无模型、基于策略的深度强化学习(DRL)方法。 策略被表示为行动的概率分布,这使得它非常类似于分类问题,类的数量等于我们可以执行的行动的数量。 Agent将观察值从传递到NN,获得动作的概率分布,并使用概率分布执行随机抽样,以获得要执行的动作。 这在开始时是随机的,但在训练后会有所改善。
在能源管理领域,电池储能系统(BESS)的优化控制至关重要。今天咱就聊聊通过深度强化学习(DRL)来控制电池充电/放电计划,以降低成本的事儿,这里面涉及到Python和Pytorch搭建的仿真平台,以及BMS(电池管理系统)相关知识。
系统架构概述
我们的系统主要包含电池、PV(光伏)、动态负载,它们通过PCC(公共连接点)连接到主电网。这就像一个复杂的能源网络,各个部分相互作用,而我们的目标就是通过控制电池的充放电,让整个系统的成本最优。
DRL在其中的角色
DRL用于训练代理(Agent),这里采用的是一种简单的无模型、基于策略的DRL方法。简单来说,策略被表示为行动的概率分布,这就好比是一个分类问题,类的数量等于我们可以执行的动作数量。比如说,我们的动作可能是充电、放电、不操作,那这就是3个“类”。
Python代码实现思路
下面咱来点代码示例,以帮助理解。首先,利用Pytorch搭建神经网络(NN)来作为Agent的大脑。
import torch
import torch.nn as nn
import torch.optim as optim
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, action_size)
def forward(self, state):
x = torch.relu(self.fc1(state))
action_probs = torch.softmax(self.fc2(x), dim=1)
return action_probs
在这段代码里,PolicyNetwork类定义了我们的策略网络。init方法初始化了网络的层,输入层大小是statesize(也就是观察值的维度),这里先经过一个有64个神经元的隐藏层,然后连接到输出层,输出层大小是actionsize,也就是动作的数量。forward方法定义了数据的前向传播,先通过ReLU激活函数处理隐藏层,然后对输出层使用Softmax函数,得到动作的概率分布。
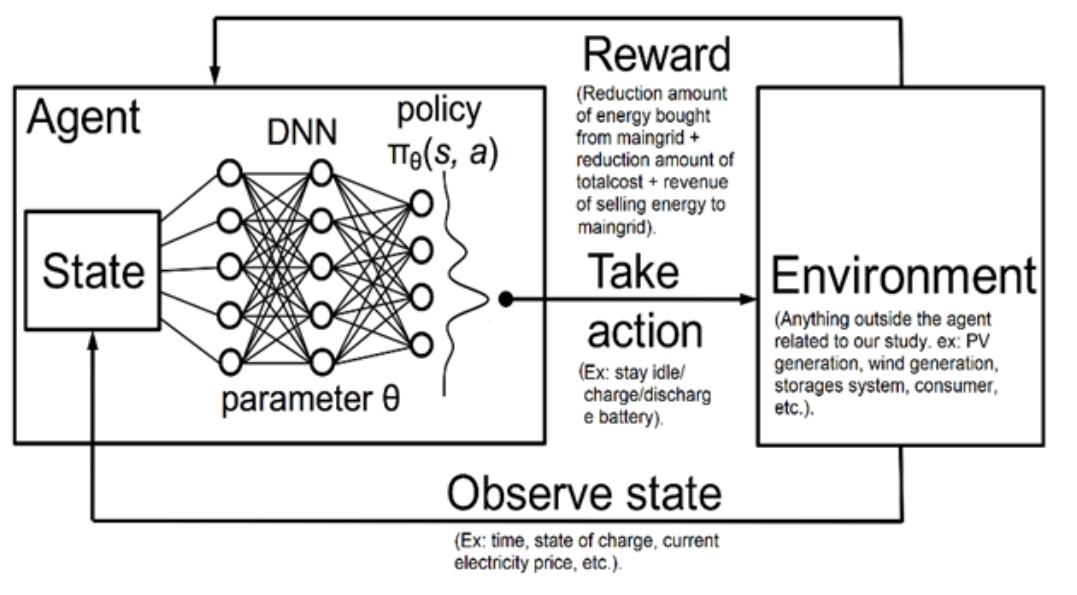
Python代码:电池储能 深度强化学习 关键词:BMS DRL 仿真平台:Python Pytorch 主要内容:电池,PV,动态负载,通过PCC连接到主电网。 我们需要控制电池充电/放电计划以降低成本。 DRL用于训练代理。 它是一种简单的无模型、基于策略的深度强化学习(DRL)方法。 策略被表示为行动的概率分布,这使得它非常类似于分类问题,类的数量等于我们可以执行的行动的数量。 Agent将观察值从传递到NN,获得动作的概率分布,并使用概率分布执行随机抽样,以获得要执行的动作。 这在开始时是随机的,但在训练后会有所改善。
接着,我们看看Agent是如何利用这个网络来选择动作的。
class Agent:
def __init__(self, state_size, action_size, learning_rate=0.001):
self.state_size = state_size
self.action_size = action_size
self.policy_network = PolicyNetwork(state_size, action_size)
self.optimizer = optim.Adam(self.policy_network.parameters(), lr=learning_rate)
def act(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
action_probs = self.policy_network(state)
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
return action.item()
在Agent类里,init方法初始化了Agent的一些参数,包括状态大小、动作大小,还创建了策略网络和优化器。act方法则是Agent选择动作的关键。它先把状态数据转化为适合输入网络的格式,然后通过策略网络得到动作概率分布,接着使用Categorical分布进行随机抽样,最后返回抽样得到的动作。刚开始训练的时候,由于策略还没优化好,动作基本是随机的,但随着训练进行,Agent会逐渐学会更好的动作选择,以达到降低成本的目的。
总结
通过Python和Pytorch搭建的这个仿真平台,利用深度强化学习训练Agent来控制电池的充放电,为优化能源成本提供了一种有效的解决方案。随着研究和实践的深入,相信这种方法能在实际的能源管理场景中发挥更大作用。
希望这篇博文能让大家对基于Python和Pytorch的电池储能深度强化学习有更清晰的认识,一起探索更多能源优化的可能性!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)