别再盲目追求98%准确率了!RAG架构选择血泪教训,大模型开发者必看
文章分析了RAG架构三大类型(向量、LLM推理、知识图谱)在准确率与效率上的权衡,指出当前评估体系过度关注准确率而忽视成本与延迟。详细比较了各架构的适用场景、成本结构和性能特点,提出从延迟需求出发的决策框架,强调应计算总拥有成本而非仅追求准确率提升。最后给出针对不同场景的架构推荐和渐进式优化路径,帮助开发者构建高效经济的RAG系统。
RAG 领域已经分化为几种不同的架构设计:基于向量的 RAG (如:VectorRAG)、基于知识图谱的 RAG(如:GraphRAG)以及基于 LLM 推理的 RAG(如:PageIndex)。每种设计的成本结构都截然不同。然而,像FinanceBench、MTEB和BEIR这样的基准测试几乎完全专注于检索质量。对于构建生产系统的开发人员来说,这种过度追求准确率的评估方法会造成一个危险的盲点,即对真正决定生产部署成败的效率、成本因素的忽视。
本文将从成本的视角给出三类不同架构的差异,读完此篇相信能给你带来不一样的收获。

RAG 架构的冰山真相
VectifyAI的 PageIndex 最近声称在 FinanceBench [1] 上的准确率高达 98.7%,但查阅他们的 GitHub、官方文档以及所有公开资料后,却找不到任何关于延迟、吞吐量或单次查询成本的数据。这并非疏忽,而是当前 RAG 系统评估方法中一个令人担忧的趋势体现:过分强调准确率指标,却忽略了真正决定生产部署成败的因素。
01
—
RAG 架构全景与权衡图
在深入探讨细节之前,让我们先来分析一下每种设计在准确率和效率权衡中所处的位置:
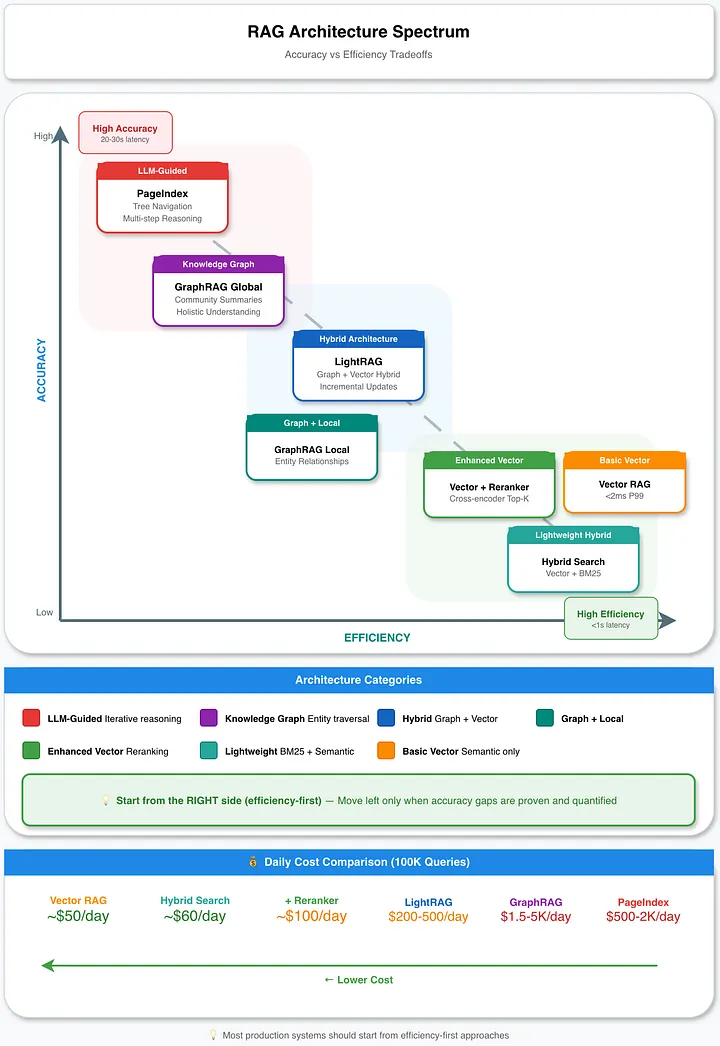
RAG 架构全景与权衡图:每种架构在准确率-效率曲线上占据不同的位置
在效率-准确率权衡中,没有“最佳”架构,只有符合你自身需求的架构。推荐大多数生产系统应该从图右侧(即效率优先)开始入手,只有在准确率差距被证实并量化之后,才考虑向左侧优化准确率。
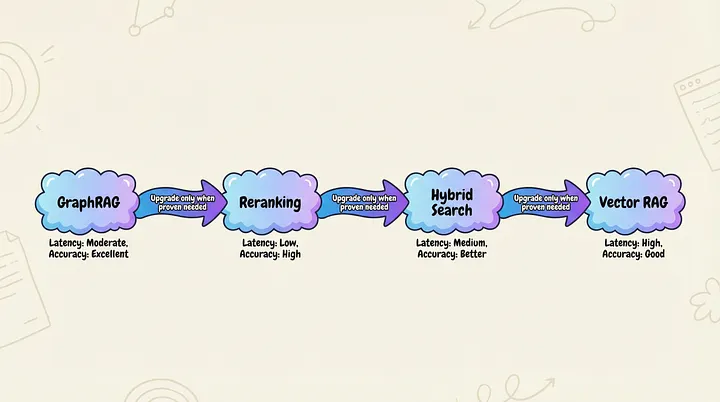
“效率优先”架构的演进路径
02
—
基于 LLM 推理的 PageIndex:追求准确率的首选
PageIndex 代表了一种新的“基于推理的 RAG”架构,它通过分层文档树,用迭代的 LLM 推理取代了向量相似性搜索 [1]。该架构非常巧妙:文档变成了 JSON 结构的目录,LLM 通过多步骤循环(读取结构、选择章节、提取信息、评估充分性、必要时重复)来遍历这些树。
这种架构之所以能达到极高的准确率,是因为它保留了文档结构,并支持交叉引用,而这是向量搜索架构根本无法实现的。在 FinanceBench 数据集上,Mafin 2.5(基于 PageIndex)的准确率达到了 98.7% [2],而基于向量的 RAG 的准确率仅为 30%–50%。其技术原理很简单:例如财务文档包含层级关系、交叉引用和结构语义,PageIndex 处理时可以保留这些信息,而向量检索固定大小的分块会破坏这些信息。
但 PageIndex 自己的网站也承认:“树搜索优先考虑准确率而非速度,为特定领域的分析提供精确的结果。” [1] 与之形成鲜明对比的是,他们对向量数据库的描述是:“速度优化的向量搜索……非常适合对响应速度要求极高的应用。”
架构对效率的影响是非常显著的。PageIndex 每次查询都需要系统在树状结构中连续调用多次 LLM 推理,完整的目录结构必须加载到上下文窗口中,且目前没有明显的缓存机制,迭代推理循环也无法并行化,这些机制必然都会严重影响其效率。然而,在查找所有官方资源(GitHub 代码库、官方文档、博客文章和社区讨论)后,没有找到任何量化的效率数据。
对于一个旨在以效率换取准确率的系统而言,缺少效率数据并非无关紧要的文档缺陷,而是会使基于充分信息的架构选型决策成为不可能。
03
—
基于向量的 RAG :效率之王
基于向量的 RAG 提供可预测的效率数据且向量检索失败方式是已知的。传统的基于向量的 RAG 架构之所以成为默认架构,原因显而易见:它能够在大规模数据集上实现亚毫秒级的检索延迟,且成本结构清晰可辨。Pinecone 架构在中等规模数据集上实现了低于 2 毫秒的 P99 延迟;Milvus 架构可扩展至数十亿个向量;生产系统通常每秒处理数千次查询。
成本模型是可预测计算的。像 Pinecone 这样的无服务器方案,存储加上读写操作的费用约为 0.33 美元/GB/月;在通用硬件上部署的自托管方案成本更低。Embedding 生成(例如使用 text-embedding-3-small 模型)会增加约 0.02 美元/M tokens 的成本。一个每天处理 10 万次查询的生产部署每月可能只需花费数百美元,与依赖大量 LLM 调用的方案相比这只是九牛一毛。
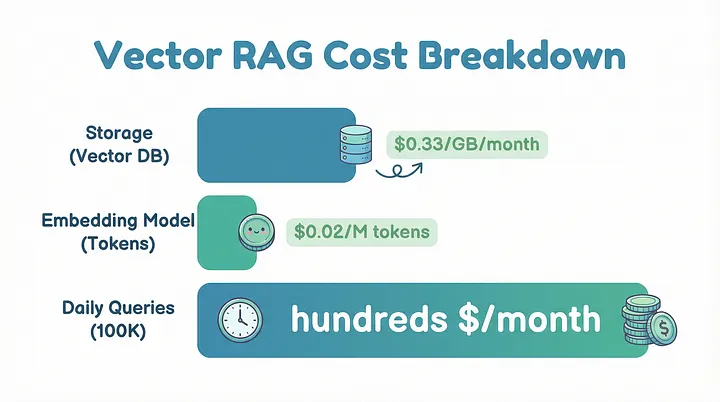
Vector RAG 成本结构概览
基于向量检索不适合的场景
向量搜索会以一些特定的、有据可查的已知方式失败[3],如下:
-
否定查询:“查找不提及定价的文档”会返回提及定价相关的文档,因为词嵌入能够捕捉主题相似性,而与逻辑运算符无关。
-
精确匹配:诸如“错误码 TS-999”之类的技术标识符在语义空间中容易丢失;系统返回的是关于错误码的一般信息。
-
多跳推理:需要跨文档边界关联事实的问题,与黄金上下文(即由人工精心标注的、包含回答特定问题所需全部关键事实且无噪声的理想上下文)基线相比,准确率下降了 25-35 个百分点。
-
实体密集查询:当查询涉及超过五个不同的实体时,性能会显著下降[4]。
Barnett 等人的研究指出了 RAG 流水线中的七个具体失败方式 [3],其中“错失最佳排名”(即答案存在但未出现在前 K 个结果中)尤其隐蔽,因为如果不进行系统评估,它就难以被发现。在不采用混合检索方法的情况下,生产级 RAG 系统在处理复杂的检索任务时,有 40% 到 60% 的概率会失败。
以上问题的解决方案并非放弃向量检索,而是对其进行策略性增强。Anthropic 的上下文检索研究表明,与仅使用向量检索的简单方法相比,混合检索(hybrid search)加上重排序(rerank)可以将检索失败率降低 67% [5]。
04
—
基于知识图谱的 RAG:高价值静态数据的拍档
基于知识图谱的 RAG 如微软的 GraphRAG 在处理关联数据方面准确率出色但成本较高。该系统通过 LLM 支持的实体和关系抽取构建知识图谱,使用Leiden社区检测算法进行层次聚类,然后生成多个粒度级别的预计算摘要 [6]。
GraphRAG 准确率的提升是真实且显著的。独立基准测试表明,在需要理解实体关系的查询中,GraphRAG 的准确率比基于向量的 RAG 提高了 3.4 倍 [4]。在数值推理任务中,GraphRAG 的正确率达到了 100%,而基于向量的 RAG 的正确率仅为 0%。在时间推理任务中,GraphRAG 的准确率达到了 83%,而基于向量的 RAG 的准确率仅为 50%。
但这些收益是以相当大的成本换来的。使用 2025 年的模型定价构建知识图谱,可以计算其成本结构:
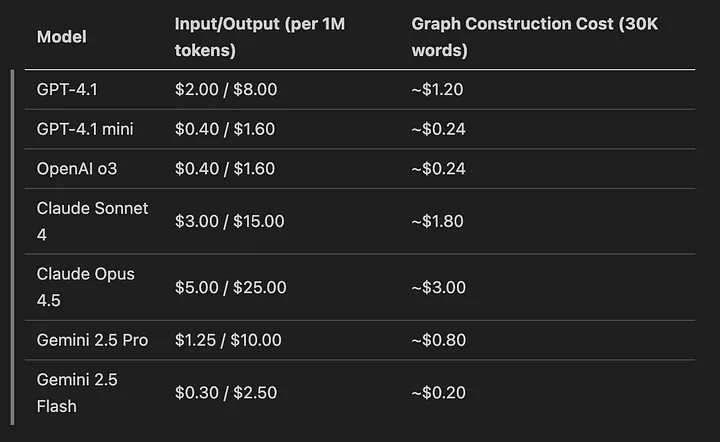
对于较大的数据集,实际测试表明,使用 GPT-4.1 索引 800KB 的文本数据大约需要 10-15 美元。使用 GPT-4.1 mini 或 Gemini 2.5 Flash 可以将成本降低 90% 以上,但可能会出现质量方面的妥协,需要针对特定领域数据进行测试。
查询时,GraphRAG 的平均延迟比其他架构高 2.3 倍。响应时间通常为 20-24 秒,其中需要 10-15 秒才能开始流式输出。一项研究发现,GraphRAG每次检索消耗 61 万个 token,而 LightRAG 仅消耗约 100 个 token [8],两者相差 6000 倍。
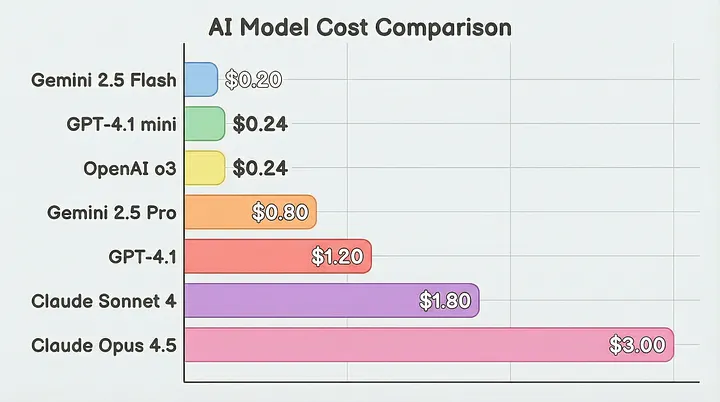
2025 年 GraphRAG 各模型成本
GraphRAG 不适合的场景
对于生产系统而言,GraphRAG 最关键的限制在于不支持增量更新。当更新时,系统必须“拆除其现有的社区结构”[8] 并重建整个图谱。这个架构上的限制,使得 GraphRAG 不适用于以下场景:
-
动态知识库,频繁更新
-
大规模文档集(重建时间呈线性增长)
-
成本敏感型部署(每次重建都会消耗大量 Tokens)
GraphRAG 为静态、高价值数据集提供了无与伦比的价值,尤其适用于需要整体摘要或跨越 3 个以上逻辑步骤的多跳推理的查询。但对于频繁更新的文档库,则需要另寻他法。
05
—
LightRAG:向量检索与Graph的结合
LightRAG [8] 的出现正是为了解决 GraphRAG 的可扩展性难题,同时保留基于图的推理能力。其关键架构差异在于:LightRAG 采用双层检索架构,结合了向量检索和轻量级图遍历检索,并且至关重要的是,它支持真正的增量更新。LightRAG 的增量更新工作原理:
-
新文档使用相同的实体/关系抽取进行处理。
-
新节点和边通过简单的并集操作合并。
-
无需重组社区结构
-
现有图结构保持完整不变
LightRAG 相较于 GraphRAG 成本节省非常显著。GraphRAG在接收新数据时需要约 1399 × 2 × 5000 个 Tokens 来重建社区结构 [8],而 LightRAG 无需修改现有图结构即可集成新实体。在基准测试中,LightRAG 的准确率与 GraphRAG 相当,但检索数据所需的 Tokens 却不到 100 个(而 GraphRAG 每次查询需要数百次 API 调用)[8]。
| 维度 | GraphRAG | LightRAG |
|---|---|---|
| 增量更新 | 不支持,需要全部重建 | 支持,并集操作 |
| 每次查询的API调用次数 | 数百次(社区遍历) | 单次调用 |
| 查询延迟 | 20-24秒 | 约20-30毫秒 |
| 多跳推理能力 | 支持,优秀 | 支持,良好 |
| 最适合场景 | 静态、复杂的数据集 | 动态、不断演化的数据 |
对于大多数需要图增强检索的生产场景,LightRAG 比 GraphRAG 具有更高的投资回报率。GraphRAG 仅适用于具有静态数据和复杂全局摘要需求的特殊用例。
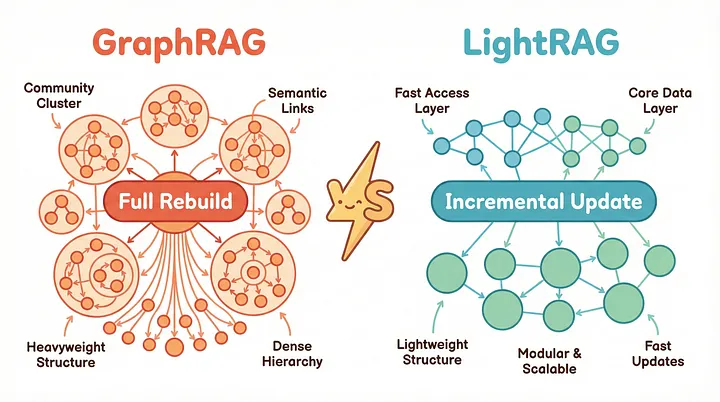
GraphRAG 与 LightRAG:两种基于图的 RAG 方法
06
—
RAG 架构决策框架:成本、延迟和准确率
选择 RAG 架构需要对三个维度进行明确的权衡分析,而目前的基准测试在很大程度上忽略了这三个维度:
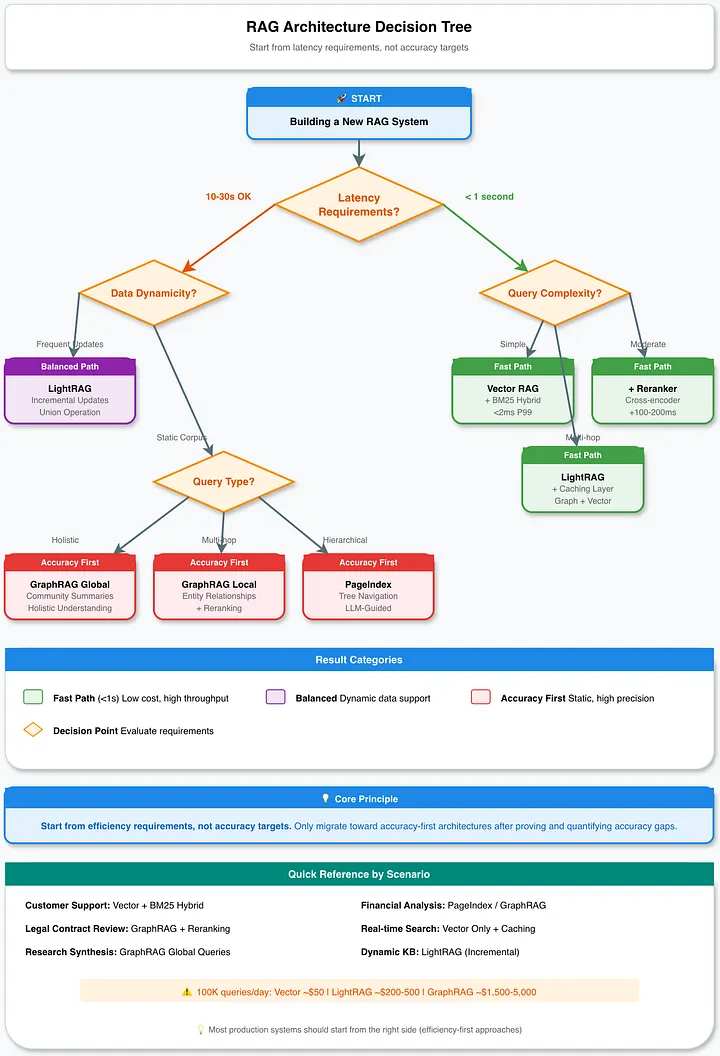
RAG 架构选型决策树:从延迟要求而非准确率目标出发
架构选型应以延迟要求为先,而非准确率目标。若应用需实现次秒级响应,则无论 GraphRAG 与多数智能体驱动方法在准确率上具备何种优势,均已被排除在考量范围之外;此时,支持可选重排序的向量搜索即成为可行方案的上限。
将查询复杂度与架构精准匹配:简单的事实检索(如“第三季度营收是多少?”)仅需基础向量 RAG;而复杂的多跳推理(如“合同 A 中的保修条款如何影响合同 B 中的责任条款?”)则可能需要 GraphRAG 且承担其带来的额外开销。多数生产环境的工作负载同时包含上述两类查询,因此建议采用基于路由的混合架构。
应计算总拥有成本(TCO),而非仅关注准确率提升。一个单次查询成本为 0.50 美元、准确率达 98% 的系统,可能不如单次成本仅 0.02 美元、准确率 85% 的系统——具体取决于业务对错误的容忍度与查询规模。以日均 10 万次查询为例,两者日成本分别为 2000 美元与 5 万美元,差距悬殊。
架构设计选型推荐清单
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 高并发客户服务支持 | 向量 + BM25 混合检索 | 亚秒级延迟,成本可预测 |
| 财务文档分析 | PageIndex 或 GraphRAG | 精准度要求高,数据量较小可接受 |
| 法律合同审查 | 带重排序的 GraphRAG | 支持多跳推理,能追踪实体关系 |
| 实时搜索 | 仅向量检索 + 缓存 | 延迟是核心约束条件 |
| 研究综述合成 | GraphRAG 全局查询 | 具备整体性摘要能力 |
| 动态知识库 | 向量 RAG | 需要支持增量更新 |
最有效的生产RAG系统通常采用逐步改进优化的方式:
-
基线:采用经过良好调优的分块(Chunk)和高质量Embedding的向量检索
-
添加混合搜索:将 BM25 关键词搜索与语义向量检索相结合(性能提升 10-30%,延迟影响极小)
-
添加重排序:对前 50 个候选结果进行交叉编码器重排序,得到前 5 个(增加 100-200 毫秒延迟,显著提高精度)
-
考虑专业化策略:GraphRAG 用于处理关系密集型查询,并基于查询分类路由
至关重要的是,在优化 RAG 系统之前先构建评估基础设施。大多数 RAG 失败都源于检索环节,而非生成环节。在修改提示或模型之前,务必确保检索到的文档是相关的。同时测试异常路径:当查询的答案不存在于语料库中时,应该返回恰当的“我不知道”响应,而不是出现莫名其妙的错误信息。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献617条内容
已为社区贡献617条内容

所有评论(0)